After you create and stage your Dataflow template, run the template with the Google Cloud console, REST API, or the Google Cloud CLI. You can deploy Dataflow template jobs from many environments, including App Engine standard environment, Cloud Run functions, and other constrained environments.
Use the Google Cloud console
You can use the Google Cloud console to run Google-provided and custom Dataflow templates.
Google-provided templates
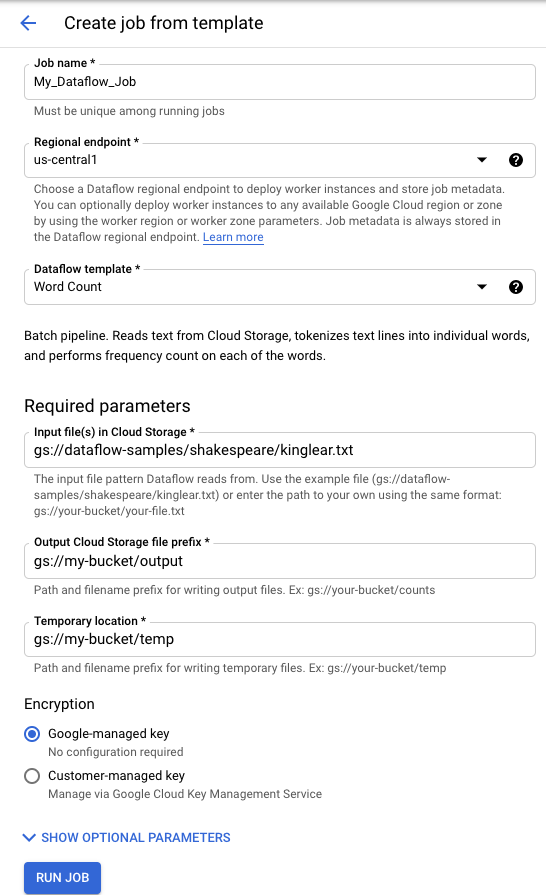
To run a Google-provided template:
- Go to the Dataflow page in the Google Cloud console. Go to the Dataflow page
- Click add_boxCREATE JOB FROM TEMPLATE.
- Select the Google-provided template that you want to run from the Dataflow template drop-down menu.
- Enter a job name in the Job Name field.
- Enter your parameter values in the provided parameter fields. You don't need the Additional Parameters section when you use a Google-provided template.
- Click Run Job.

Custom templates
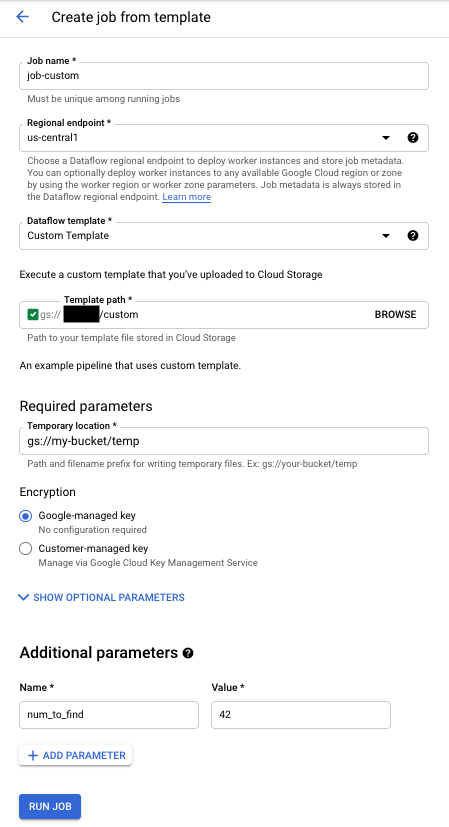
To run a custom template:
- Go to the Dataflow page in the Google Cloud console. Go to the Dataflow page
- Click CREATE JOB FROM TEMPLATE.
- Select Custom Template from the Dataflow template drop-down menu.
- Enter a job name in the Job Name field.
- Enter the Cloud Storage path to your template file in the template Cloud Storage path field.
- If your template needs parameters, click addADD PARAMETER in the Additional parameters section. Enter in the Name and Value of the parameter. Repeat this step for each needed parameter.
- Click Run Job.
Use the REST API
To run a template with a REST API request, send an HTTP POST request with your project ID. This request requires authorization.
See the REST API reference for projects.locations.templates.launch to learn more about the available parameters.
Create a custom template batch job
This example projects.locations.templates.launch request creates a batch job from a template that reads a text file and writes an output text file. If the request is successful, the response body contains an instance of LaunchTemplateResponse.
Modify the following values:
- Replace
YOUR_PROJECT_IDwith your project ID. - Replace
LOCATIONwith the Dataflow region of your choice. - Replace
JOB_NAMEwith a job name of your choice. - Replace
YOUR_BUCKET_NAMEwith the name of your Cloud Storage bucket. - Set
gcsPathto the Cloud Storage location of the template file. - Set
parametersto your list of key-value pairs. - Set
tempLocationto a location where you have write permission. This value is required to run Google-provided templates.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=gs://YOUR_BUCKET_NAME/templates/TemplateName
{
"jobName": "JOB_NAME",
"parameters": {
"inputFile" : "gs://YOUR_BUCKET_NAME/input/my_input.txt",
"output": "gs://YOUR_BUCKET_NAME/output/my_output"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Create a custom template streaming job
This example projects.locations.templates.launch request creates a streaming job from a classic template that reads from a Pub/Sub subscription and writes to a BigQuery table. If you want to launch a Flex Template, use projects.locations.flexTemplates.launch instead. The example template is a Google-provided template. You can modify the path in the template to point to a custom template. The same logic is used to launch Google-provided and custom templates. In this example, the BigQuery table must already exist with the appropriate schema. If successful, the response body contains an instance of LaunchTemplateResponse.
Modify the following values:
- Replace
YOUR_PROJECT_IDwith your project ID. - Replace
LOCATIONwith the Dataflow region of your choice. - Replace
JOB_NAMEwith a job name of your choice. - Replace
YOUR_BUCKET_NAMEwith the name of your Cloud Storage bucket. - Replace
GCS_PATHwith the Cloud Storage location of the template file. The location should start with gs:// - Set
parametersto your list of key-value pairs. The parameters listed are specific to this template example. If you're using a custom template, modify the parameters as needed. If you're using the example template, replace the following variables.- Replace
YOUR_SUBSCRIPTION_NAMEwith your Pub/Sub subscription name. - Replace
YOUR_DATASETwith your BigQuery dataset, and replaceYOUR_TABLE_NAMEwith your BigQuery table name.
- Replace
- Set
tempLocationto a location where you have write permission. This value is required to run Google-provided templates.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH
{
"jobName": "JOB_NAME",
"parameters": {
"inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_SUBSCRIPTION_NAME",
"outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME"
},
"environment": {
"tempLocation": "gs://YOUR_BUCKET_NAME/temp",
"zone": "us-central1-f"
}
}
Update a custom template streaming job
This example projects.locations.templates.launch request shows you how to update a template streaming job. If you want to update a Flex Template, use projects.locations.flexTemplates.launch instead.
- Run Example 2: Creating a custom template streaming job to start a streaming template job.
- Send the following HTTP POST request, with the following modified values:
- Replace
YOUR_PROJECT_IDwith your project ID. - Replace
LOCATIONwith the Dataflow region of the job that you're updating. - Replace
JOB_NAMEwith the exact name of the job that you want to update. - Replace
GCS_PATHwith the Cloud Storage location of the template file. The location should start with gs:// - Set
parametersto your list of key-value pairs. The parameters listed are specific to this template example. If you're using a custom template, modify the parameters as needed. If you're using the example template, replace the following variables.- Replace
YOUR_SUBSCRIPTION_NAMEwith your Pub/Sub subscription name. - Replace
YOUR_DATASETwith your BigQuery dataset, and replaceYOUR_TABLE_NAMEwith your BigQuery table name.
- Replace
- Use the
environmentparameter to change environment settings, such as the machine type. This example uses the n2-highmem-2 machine type, which has more memory and CPU per worker than the default machine type.
POST https://dataflow.googleapis.com/v1b3/projects/YOUR_PROJECT_ID/locations/LOCATION/templates:launch?gcsPath=GCS_PATH { "jobName": "JOB_NAME", "parameters": { "inputSubscription": "projects/YOUR_PROJECT_ID/subscriptions/YOUR_TOPIC_NAME", "outputTableSpec": "YOUR_PROJECT_ID:YOUR_DATASET.YOUR_TABLE_NAME" }, "environment": { "machineType": "n2-highmem-2" }, "update": true } - Replace
- Access the Dataflow monitoring interface and verify that a new job with the same name was created. This job has the status Updated.
Use the Google API Client Libraries
Consider using the Google API Client Libraries to easily make calls to the Dataflow REST APIs. This sample script uses the Google API Client Library for Python.
In this example, you must set the following variables:
project: Set to your project ID.job: Set to a unique job name of your choice.template: Set to the Cloud Storage location of the template file.parameters: Set to a dictionary with the template parameters.
To set the
region,
include the
location
parameter.
For more information about the available options, see the
projects.locations.templates.launch method
in the Dataflow REST API reference.
Use gcloud CLI
The gcloud CLI can run either a custom or a
Google-provided
template using the gcloud dataflow jobs run command. Examples of
running Google-provided templates are documented in the
Google-provided templates page.
For the following custom template examples, set the following values:
- Replace
JOB_NAMEwith a job name of your choice. - Replace
YOUR_BUCKET_NAMEwith the name of your Cloud Storage bucket. - Set
--gcs-locationto the Cloud Storage location of the template file. - Set
--parametersto the comma-separated list of parameters to pass to the job. Spaces between commas and values are not allowed. - To prevent VMs from accepting SSH keys that are stored in project
metadata, use the
additional-experimentsflag with theblock_project_ssh_keysservice option:--additional-experiments=block_project_ssh_keys.
Create a custom template batch job
This example creates a batch job from a template that reads a text file and writes an output text file.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters inputFile=gs://YOUR_BUCKET_NAME/input/my_input.txt,output=gs://YOUR_BUCKET_NAME/output/my_output
The request returns a response with the following format.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_BATCH
Create a custom template streaming job
This example creates a streaming job from a template that reads from a Pub/Sub topic and writes to a BigQuery table. The BigQuery table must already exist with the appropriate schema.
gcloud dataflow jobs run JOB_NAME \
--gcs-location gs://YOUR_BUCKET_NAME/templates/MyTemplate \
--parameters topic=projects/project-identifier/topics/resource-name,table=my_project:my_dataset.my_table_name
The request returns a response with the following format.
id: 2016-10-11_17_10_59-1234530157620696789
projectId: YOUR_PROJECT_ID
type: JOB_TYPE_STREAMING
For a complete list of flags for the gcloud dataflow jobs run
command, see the gcloud CLI reference.
Monitoring and Troubleshooting
The Dataflow monitoring interface lets you to monitor your Dataflow jobs. If a job fails, you can find troubleshooting tips, debugging strategies, and a catalog of common errors in the Troubleshooting Your Pipeline guide.