Los PCollections no delimitados, o colecciones no delimitadas, representan datos en flujos de procesamiento. Una colección ilimitada contiene datos de una fuente de datos que se actualiza continuamente, como Pub/Sub.
No puedes usar solo una clave para agrupar elementos en una colección ilimitada. Puede haber infinitos elementos para una clave determinada en los datos de streaming, ya que la fuente de datos añade constantemente elementos nuevos. Puedes usar ventanas, marcas de agua y activadores para agregar elementos en colecciones ilimitadas.
El concepto de ventanas también se aplica a las PCollections acotadas que representan datos en flujos de procesamiento por lotes. Para obtener información sobre las ventanas en flujos de procesamiento por lotes, consulta la documentación de Apache Beam sobre ventanas con PCollections acotadas.
Si una canalización de Dataflow tiene una fuente de datos limitada, es decir, una fuente que no contiene datos que se actualizan continuamente, y la canalización se cambia al modo de streaming mediante la marca --streaming, cuando se consuma por completo la fuente limitada, la canalización dejará de ejecutarse.
Usar el modo Streaming
Para ejecutar un flujo de procesamiento en modo de streaming, define la marca --streaming en la línea de comandos cuando ejecutes el flujo. También puedes definir el modo de streaming mediante programación al crear tu canal.
Las fuentes por lotes no se admiten en el modo de streaming.
Si actualizas tu flujo de procesamiento con un mayor número de trabajadores, es posible que tu trabajo de streaming no aumente de escala como esperabas. En las tareas de streaming que no usan Streaming Engine, no puedes superar el número original de trabajadores y recursos de disco persistente asignados al inicio de la tarea original. Cuando actualizas una tarea de Dataflow y especificas un número mayor de trabajadores en la nueva tarea, solo puedes especificar un número de trabajadores igual al número máximo de trabajadores que especificaste en la tarea original.
Especifica el número máximo de trabajadores mediante las siguientes marcas:
Java
--maxNumWorkers
Python
--max_num_workers
Go
--max_num_workers
Ventanas y funciones de ventana
Las funciones de ventana dividen las colecciones ilimitadas en componentes lógicos o ventanas. Las funciones de ventana agrupan colecciones ilimitadas por las marcas de tiempo de los elementos individuales. Cada ventana contiene un número finito de elementos.
Puedes definir las siguientes ventanas con el SDK de Apache Beam:
- Ventanas de saltos de tamaño constante (llamadas ventanas fijas en Apache Beam)
- Ventanas de salto (llamadas ventanas deslizantes en Apache Beam)
- Ventanas de sesión
Ventanas de saltos de tamaño constante
Una ventana de tiempo representa un intervalo de tiempo coherente y disjunto en el flujo de datos.
Por ejemplo, si define una ventana de 30 segundos, los elementos con valores de marca de tiempo [0:00:00-0:00:30) estarán en la primera ventana. Los elementos con valores de marca de tiempo [0:00:30-0:01:00) se encuentran en la segunda ventana.
En la siguiente imagen se muestra cómo se dividen los elementos en ventanas de 30 segundos.
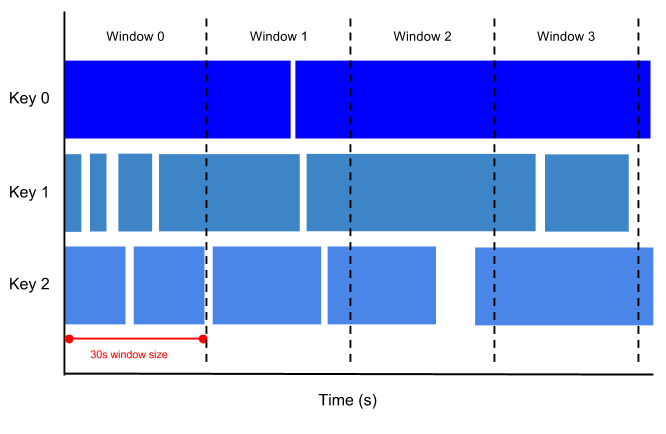
Ventanas de salto
Una ventana de salto representa un intervalo de tiempo coherente en el flujo de datos. Las ventanas de salto pueden superponerse, mientras que las ventanas de tumbling no se superponen.
Por ejemplo, una ventana de salto puede iniciarse cada 30 segundos y capturar un minuto de datos. La frecuencia con la que empiezan las ventanas de salto se denomina periodo. En este ejemplo, la ventana es de un minuto y el periodo, de treinta segundos.
En la siguiente imagen se muestra cómo se dividen los elementos en ventanas de un minuto con un periodo de 30 segundos.
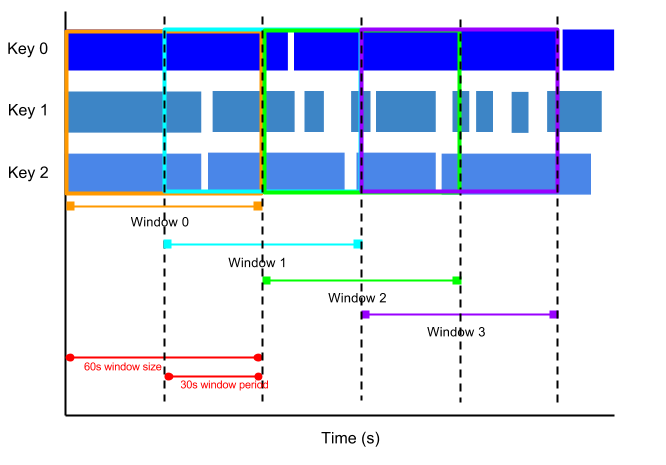
Para obtener medias móviles de los datos, usa ventanas de salto. Puedes usar ventanas de salto de un minuto con un periodo de treinta segundos para calcular una media continua de un minuto cada treinta segundos.
Ventanas de sesión
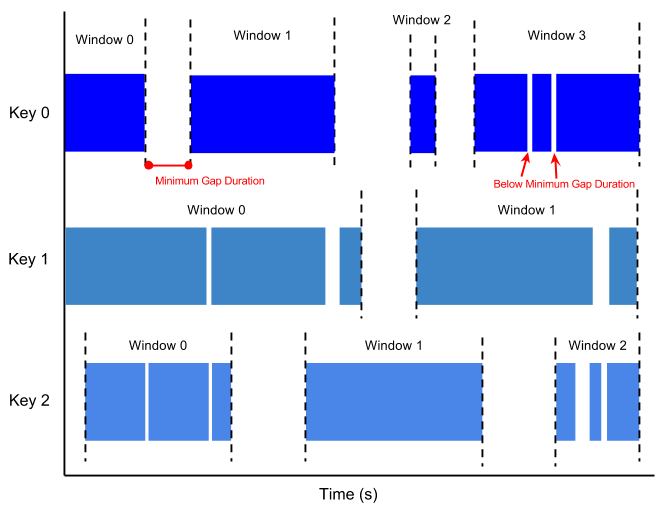
Una ventana de sesión contiene elementos que se encuentran a una duración de intervalo de otro elemento. La duración del intervalo es el tiempo que transcurre entre los datos nuevos de un flujo de datos. Si los datos llegan después de la duración del intervalo, se asignan a una nueva ventana.
Por ejemplo, las ventanas de sesión pueden dividir un flujo de datos que represente la actividad del ratón de un usuario. Este flujo de datos puede tener largos periodos de inactividad intercalados con muchos clics. Una ventana de sesión puede contener los datos generados por los clics.
La ventana de sesión asigna ventanas diferentes a cada clave de datos. Las ventanas de tiempo acumulativas y las ventanas de tiempo de salto contienen todos los elementos del intervalo de tiempo especificado, independientemente de las claves de datos.
En la siguiente imagen se muestra cómo se dividen los elementos en ventanas de sesión.
Marcas de agua
Una marca de agua es un umbral que indica cuándo espera Dataflow que hayan llegado todos los datos de una ventana. Si la marca de agua ha superado el final de la ventana y llegan datos nuevos con una marca de tiempo dentro de la ventana, se consideran datos tardíos. Para obtener más información, consulta Marcas de agua y datos tardíos en la documentación de Apache Beam.
Dataflow monitoriza las marcas de agua por los siguientes motivos:
- No se garantiza que los datos lleguen en orden cronológico o a intervalos predecibles.
- No se garantiza que los eventos de datos aparezcan en las canalizaciones en el mismo orden en el que se generaron.
La fuente de datos determina la marca de agua. Puedes permitir datos tardíos con el SDK de Apache Beam.
Activadores
Los activadores determinan cuándo se deben emitir los resultados agregados a medida que llegan los datos. De forma predeterminada, los resultados se emiten cuando la marca de agua supera el final de la ventana.
Puedes usar el SDK de Apache Beam para crear o modificar activadores de cada colección de un flujo de procesamiento de streaming.
El SDK de Apache Beam puede definir activadores que funcionen con cualquier combinación de las siguientes condiciones:
- Hora del evento, indicada por la marca de tiempo de cada elemento de datos.
- Tiempo de procesamiento, que es el tiempo que se tarda en procesar el elemento de datos en cualquier fase del flujo de procesamiento.
- Número de elementos de datos de una colección.
Siguientes pasos
- Introducción al streaming: el mundo más allá del procesamiento por lotes (blog)
- Streaming 102: el mundo más allá de los lotes (blog)