As PCollections ilimitadas ou as coleções ilimitadas representam dados em pipelines de streaming. Uma coleção não limitada contém dados de uma origem de dados em atualização contínua, como o Pub/Sub.
Não pode usar apenas uma chave para agrupar elementos numa coleção não limitada. Pode haver um número infinito de elementos para uma determinada chave nos dados de streaming, porque a origem de dados adiciona constantemente novos elementos. Pode usar janelas, marcas de água e acionadores para agregar elementos em coleções ilimitadas.
O conceito de janelas também se aplica a PCollections delimitadas que representam dados em pipelines de processamento em lote. Para obter informações sobre a criação de janelas em pipelines de lotes, consulte a documentação do Apache Beam para Criação de janelas com PCollections delimitados.
Se um pipeline do Dataflow tiver uma origem de dados limitada, ou seja, uma origem que não contenha dados atualizados continuamente, e o pipeline for comutado para o modo de streaming através da flag --streaming, quando a origem limitada for totalmente consumida, o pipeline deixa de ser executado.
Use o modo de streaming
Para executar um pipeline no modo de streaming, defina a flag --streaming na
linha de comandos
quando executar o pipeline. Também pode definir o modo de streaming
programaticamente
quando cria o pipeline.
As origens de lotes não são suportadas no modo de streaming.
Quando atualiza o pipeline com um conjunto maior de trabalhadores, a tarefa de streaming pode não ser dimensionada como esperado. Para tarefas de streaming que não usam o Streaming Engine, não pode escalar para além do número original de trabalhadores e recursos de disco persistente alocados no início da tarefa original. Quando atualiza uma tarefa do Dataflow e especifica um número maior de trabalhadores na nova tarefa, só pode especificar um número de trabalhadores igual ao número máximo de trabalhadores que especificou para a tarefa original.
Especifique o número máximo de trabalhadores através das seguintes flags:
Java
--maxNumWorkers
Python
--max_num_workers
Go
--max_num_workers
Janelas e funções de janelas
As funções de janelas dividem coleções ilimitadas em componentes lógicos ou janelas. As funções de janelas agrupam coleções ilimitadas pelas indicações de data/hora dos elementos individuais. Cada janela contém um número finito de elementos.
Defina as seguintes janelas com o SDK do Apache Beam:
- Janelas de deslocamento (denominadas janelas fixas no Apache Beam)
- Janelas de salto (denominadas janelas deslizantes no Apache Beam)
- Períodos de sessão
Janelas de tombo
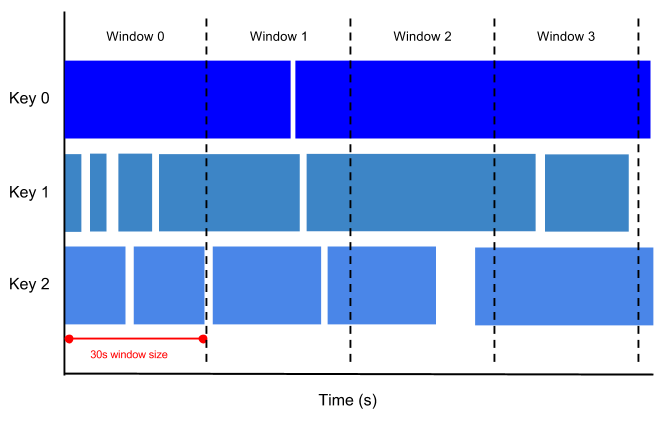
Uma janela de rolamento representa um intervalo de tempo consistente e disjunto no fluxo de dados.
Por exemplo, se definir um intervalo de tempo de 30 segundos, os elementos com valores de data/hora [0:00:00-0:00:30) estão no primeiro intervalo de tempo. Os elementos com valores de indicação de tempo [0:00:30-0:01:00) estão na segunda janela.
A imagem seguinte ilustra como os elementos são divididos em janelas de 30 segundos.
Janelas de salto
Uma janela de salto representa um intervalo de tempo consistente no fluxo de dados. As janelas de salto podem sobrepor-se, enquanto as janelas de rotação são disjuntas.
Por exemplo, uma janela de salto pode começar a cada trinta segundos e capturar um minuto de dados. A frequência com que os períodos de salto começam chama-se período. Este exemplo tem uma janela de um minuto e um período de trinta segundos.
A imagem seguinte ilustra como os elementos são divididos em intervalos de um minuto com um período de trinta segundos.
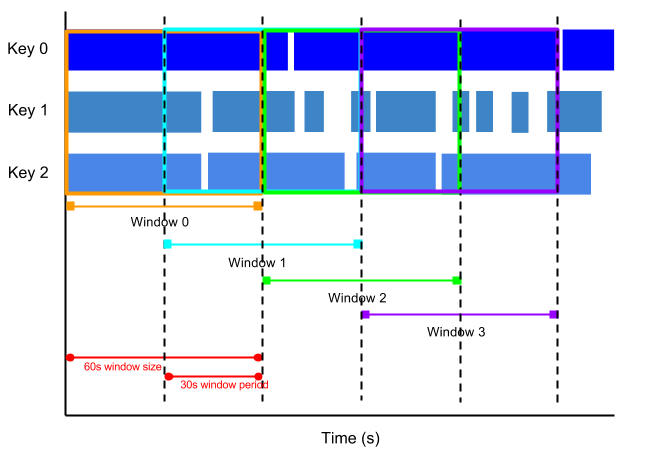
Para calcular médias móveis de dados, use janelas de salto. Pode usar janelas de salto de um minuto com um período de trinta segundos para calcular uma média móvel de um minuto a cada trinta segundos.
Períodos das sessões
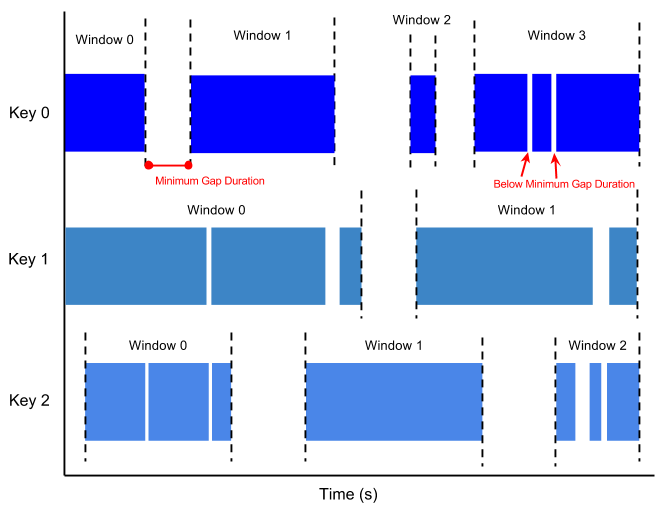
Uma janela de sessão contém elementos dentro de uma duração do intervalo de outro elemento. A duração da lacuna é um intervalo entre novos dados numa stream de dados. Se os dados chegarem após a duração da lacuna, são atribuídos a uma nova janela.
Por exemplo, as janelas de sessão podem dividir um fluxo de dados que representa a atividade do rato do utilizador. Esta stream de dados pode ter longos períodos de tempo de inatividade intercalados com muitos cliques. Uma janela de sessão pode conter os dados gerados pelos cliques.
A segmentação por períodos de sessões atribui períodos diferentes a cada chave de dados. As janelas de deslocamento e salto contêm todos os elementos no intervalo de tempo especificado, independentemente das chaves de dados.
A imagem seguinte visualiza como os elementos são divididos em janelas de sessão.
Marcas de água
Uma marca de água é um limite que indica quando o Dataflow espera que todos os dados numa janela tenham chegado. Se a marca cronológica tiver progredido para além do fim da janela e chegarem novos dados com uma data/hora dentro da janela, os dados são considerados dados atrasados. Para mais informações, consulte o artigo Marcas de água e dados atrasados na documentação do Apache Beam.
O Dataflow acompanha as marcas de água pelos seguintes motivos:
- Não é garantido que os dados cheguem por ordem cronológica ou a intervalos previsíveis.
- Não é garantido que os eventos de dados apareçam nos pipelines pela mesma ordem em que foram gerados.
A origem de dados determina a marca de água. Pode permitir dados tardios com o SDK Apache Beam.
Acionadores
Os acionadores determinam quando emitir resultados agregados à medida que os dados chegam. Por predefinição, os resultados são emitidos quando a marca de água passa o fim da janela.
Pode usar o SDK Apache Beam para criar ou modificar acionadores para cada coleção num pipeline de streaming.
O SDK Apache Beam pode definir acionadores que funcionam em qualquer combinação das seguintes condições:
- Hora do evento, conforme indicado pela data/hora em cada elemento de dados.
- Tempo de processamento, que é o tempo durante o qual o elemento de dados é processado em qualquer fase do pipeline.
- O número de elementos de dados numa coleção.
O que se segue?
- Streaming 101: The world beyond batch (blogue)
- Streaming 102: o mundo além do processamento em lote (blogue)