La función Ajuste adecuado usa sugerencias de recursos de Apache Beam para personalizar los recursos de los trabajadores de una canalización. La posibilidad de orientar varios recursos diferentes a pasos específicos de la canalización proporciona flexibilidad y capacidad adicionales a la canalización, así como posibles ahorros de costes. Puedes aplicar recursos más costosos a los pasos de la canalización que los requieran y recursos menos costosos a otros pasos. Usa el ajuste a la derecha para especificar los requisitos de recursos de una canalización completa o de pasos específicos de la canalización.
Compatibilidad y limitaciones
- Las sugerencias de recursos se admiten en las versiones 2.31.0 y posteriores de los SDKs de Java y Python de Apache Beam.
- El ajuste adecuado es compatible con los flujos de procesamiento por lotes.
El ajuste adecuado se admite en las canalizaciones de streaming con el autoescalado horizontal habilitado.
- Para habilitarlo, define la
--experiments=enable_streaming_rightfittingopción de canalización.
- Para habilitarlo, define la
La adaptación adecuada es compatible con Dataflow Prime.
Right fitting no admite FlexRS.
Cuando uses la opción de ajuste correcto, no uses la
worker_acceleratoropción de servicio.
Habilitar el ajuste adecuado
Para activar el ajuste correcto, usa una o varias pistas de recursos disponibles en tu canalización. Cuando usas una sugerencia de recurso en tu canalización, se habilita automáticamente el ajuste correcto. Para obtener más información, consulta la sección Usar sugerencias de recursos de este documento.
Sugerencias de recursos disponibles
Están disponibles las siguientes sugerencias de recursos.
| Pista de recursos | Descripción |
|---|---|
min_ram |
Cantidad mínima de RAM en gigabytes que se asignará a los trabajadores. Dataflow usa este valor como límite inferior al asignar memoria a nuevos trabajadores (escalado horizontal) o a trabajadores ya existentes (escalado vertical). Por ejemplo: min_ram=NUMBERGB
|
accelerator |
Una asignación de GPUs proporcionada por el usuario que te permite controlar el uso y el coste de las GPUs en tu canalización y sus pasos. Especifica el tipo y el número de GPUs que se van a asociar a los trabajadores de Dataflow como parámetros de la marca. Por ejemplo: accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
Para obtener más información sobre el uso de GPUs, consulta GPUs con Dataflow. |
Anidación de sugerencias de recursos
Las sugerencias de recursos se aplican a la jerarquía de transformación de la siguiente manera:
min_ram: El valor de una transformación se evalúa como el valor de sugerenciamin_rammás alto entre los valores que se definen en la propia transformación y en todos sus elementos superiores en la jerarquía de la transformación.- Por ejemplo, si una sugerencia de transformación interna define
min_ramen 16 GB y la sugerencia de transformación externa de la jerarquía definemin_ramen 32 GB, se utilizará una sugerencia de 32 GB para todos los pasos de la transformación. - Por ejemplo, si una sugerencia de transformación interna establece
min_ramen 16 GB y la sugerencia de transformación externa de la jerarquía establecemin_ramen 8 GB, se usará una sugerencia de 8 GB para todos los pasos de la transformación externa que no estén en la transformación interna, y se usará una sugerencia de 16 GB para todos los pasos de la transformación interna.
- Por ejemplo, si una sugerencia de transformación interna define
accelerator: El valor más interno de la jerarquía de la transformación tiene prioridad.- Por ejemplo, si una sugerencia de transformación interna
acceleratores diferente de una sugerencia de transformación externaacceleratoren una jerarquía, se usará la sugerencia de transformación internaacceleratorpara la transformación interna.
- Por ejemplo, si una sugerencia de transformación interna
Las sugerencias que se definen para toda la canalización se tratan como si se definieran en una transformación externa independiente.
Usar sugerencias de recursos
Puedes definir sugerencias de recursos en toda la canalización o en pasos concretos de la canalización.
Sugerencias de recursos de flujo de procesamiento
Puedes definir sugerencias de recursos en toda la canalización cuando la ejecutes desde la línea de comandos.
Para configurar tu entorno de Python, consulta el tutorial de Python.
Ejemplo:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
Sugerencias de recursos de pasos de flujos de procesamiento
Puedes definir sugerencias de recursos en los pasos de la canalización (transformaciones) de forma programática.
Java
Para instalar el SDK de Apache Beam para Java, consulta Instalar el SDK de Apache Beam.
Puedes definir sugerencias de recursos de forma programática en las transformaciones de la canalización mediante la clase ResourceHints.
En el siguiente ejemplo se muestra cómo definir sugerencias de recursos de forma programática en transformaciones de la canalización.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create().withMinRam("30GB")))
Para definir de forma programática las sugerencias de recursos en toda la canalización, usa la interfaz ResourceHintsOptions.
Python
Para instalar el SDK de Apache Beam para Python, consulta Instalar el SDK de Apache Beam.
Puedes definir sugerencias de recursos de forma programática en las transformaciones de la canalización mediante la clase PTransforms.with_resource_hints.
Para obtener más información, consulta la clase ResourceHint.
En el siguiente ejemplo se muestra cómo definir sugerencias de recursos de forma programática en transformaciones de la canalización.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB")
Para definir sugerencias de recursos en toda la canalización, usa la opción --resource_hints
pipeline al ejecutarla. Para ver un ejemplo, consulta Sugencias de recursos de la canalización.
Go
Las sugerencias de recursos no se admiten en Go.
Compatibilidad con varios aceleradores
En una canalización, las diferentes transformaciones pueden tener configuraciones de acelerador distintas. Esto incluye configuraciones que requieren diferentes tipos de máquina. Estas configuraciones de acelerador a nivel de transformación tienen prioridad sobre la configuración a nivel de canalización, si se ha proporcionado alguna.
Ajuste y fusión adecuados
En algunos casos, las transformaciones definidas con diferentes sugerencias de recursos se pueden ejecutar en workers del mismo grupo de workers como parte del proceso de optimización de fusión. Cuando se fusionan las transformaciones, Dataflow las ejecuta en un entorno que cumple la unión de las sugerencias de recursos definidas en las transformaciones. En algunos casos, esto incluye toda la canalización.
Si no se pueden combinar las sugerencias de recursos, no se produce la fusión. Por ejemplo, las sugerencias de recursos de diferentes GPUs no se pueden combinar, por lo que esas transformaciones no se fusionan.
También puedes evitar la fusión añadiendo una operación a tu canalización que fuerce a Dataflow a materializar un PCollection intermedio. Esto es especialmente útil cuando se intenta aislar recursos caros, como GPUs o máquinas con mucha memoria, de pasos lentos o que requieren muchos recursos de computación y que no necesitan esos recursos especiales. En esos casos, puede ser útil forzar una ruptura de la fusión entre los pasos lentos dependientes de la CPU y los pasos que necesitan GPUs caras o máquinas con mucha memoria, y pagar el coste de materialización asociado a la ruptura de la fusión. Para obtener más información, consulta Evitar la fusión.
Streaming right fitting
En los trabajos de streaming, puedes habilitar el ajuste a la derecha configurando la opción de canalización --experiments=enable_streaming_rightfitting.
Si se ajusta correctamente, puede mejorar el rendimiento de tu canalización si incluye fases con diferentes requisitos de recursos.
Ejemplo: una canalización con una fase que requiere mucha CPU y otra que requiere GPU
Un ejemplo de una canalización que puede beneficiarse de un ajuste adecuado es aquella que ejecuta una fase que requiere mucha CPU, seguida de una fase que requiere GPU. Si no se ajusta correctamente, se tendrá que configurar un único grupo de trabajadores de GPU para ejecutar todas las fases de la canalización, incluida la fase que requiere mucha CPU. Esto puede provocar una infrautilización de los recursos de la GPU cuando el grupo de trabajadores esté ejecutando la fase que requiere mucha CPU.
Si el ajuste adecuado está habilitado y se aplica una sugerencia de recurso al paso que requiere la GPU, la canalización creará dos grupos independientes para que la fase que requiere mucha CPU se ejecute en el grupo de trabajadores de CPU y la fase que requiere la GPU se ejecute en el grupo de trabajadores de GPU.
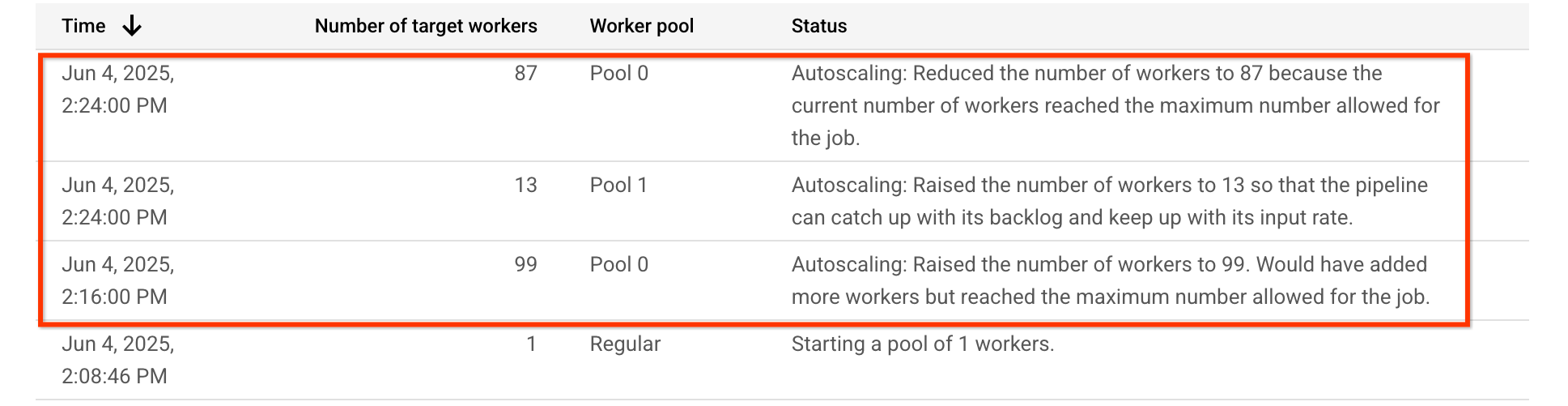
En esta canalización de ejemplo, la tabla de escalado automático muestra que el grupo de trabajadores que ejecuta la fase que requiere mucha CPU, Pool 0, se amplía inicialmente a 99 trabajadores y, más adelante, se reduce a 87. El grupo de trabajadores que ejecuta la fase que requiere GPU, Pool 1, se amplía a 13 trabajadores:
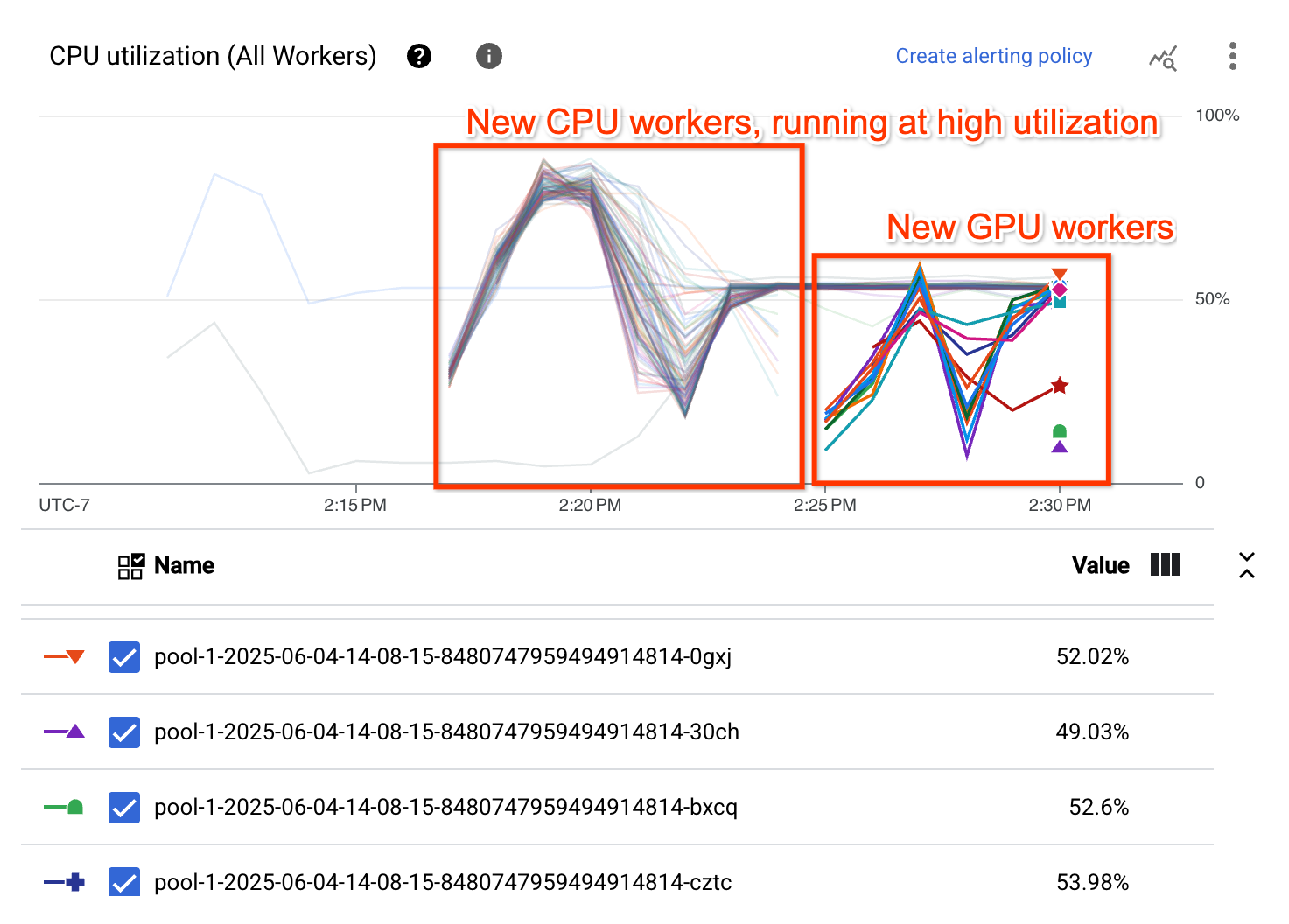
El gráfico Uso de CPU muestra que los trabajadores de ambos grupos de trabajadores tienen un uso de CPU alto en general:
Solucionar problemas de ajuste
En esta sección se ofrecen instrucciones para solucionar problemas habituales relacionados con el ajuste correcto.
Configuración no válida
Cuando intentas usar la opción de ajuste a la derecha, se produce el siguiente error:
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
Este error se produce cuando el tipo de GPU seleccionado no es compatible con el tipo de máquina seleccionado. Para resolver este error, selecciona un tipo de GPU y un tipo de máquina compatibles. Para obtener información sobre la compatibilidad, consulta las plataformas de GPU.
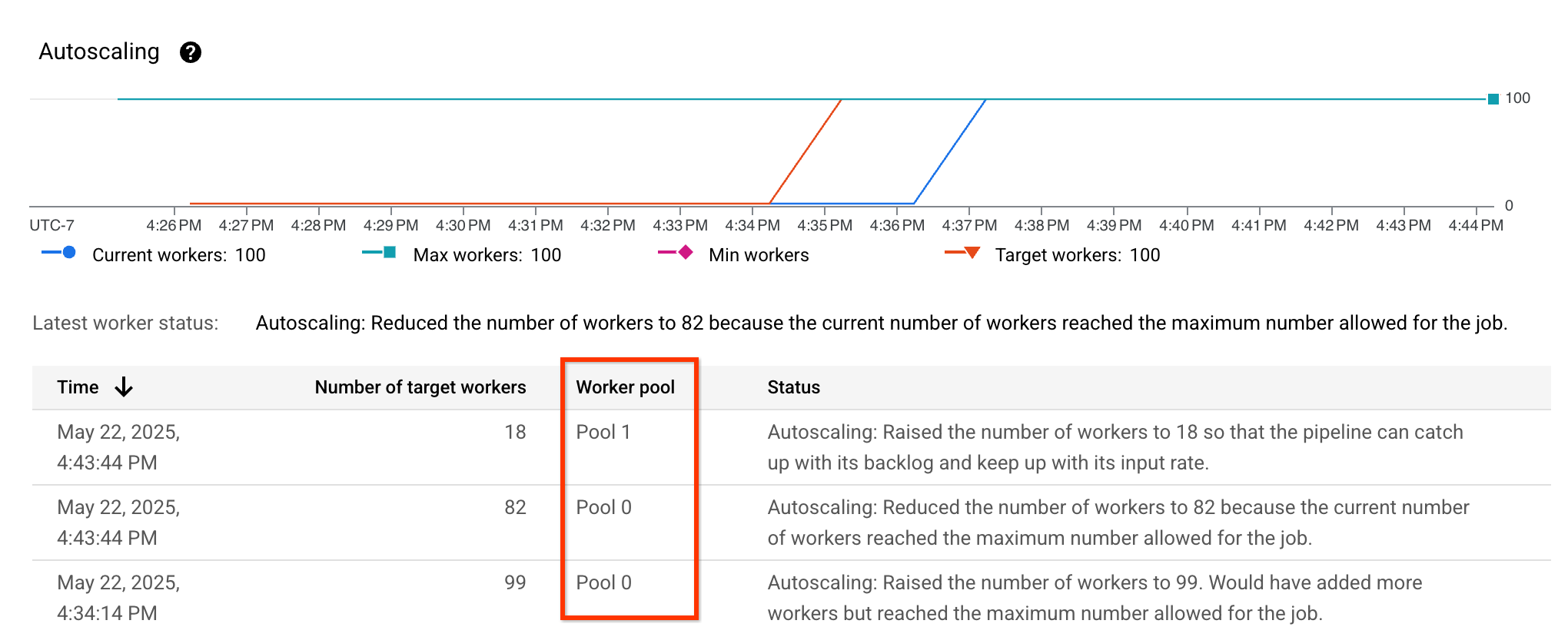
Verificar que se ajustan bien
Para comprobar que el ajuste adecuado está habilitado, consulte las métricas de autoescalado y verifique que la columna Worker pool esté visible y muestre diferentes grupos:
Streaming con un rendimiento adecuado
Es posible que las canalizaciones de streaming con la opción de ajuste adecuado habilitada no siempre tengan un mejor rendimiento que las canalizaciones sin esta opción. Por ejemplo:
- La canalización está usando más trabajadores
- La latencia del sistema es mayor o el rendimiento es menor
- Los tamaños de los grupos de trabajadores cambian con más frecuencia o no se estabilizan
Si observas este comportamiento en tu canal, puedes inhabilitar el ajuste a la derecha quitando la opción de canal --experiments=enable_streaming_rightfitting. Además, las canalizaciones de streaming con el ajuste correcto habilitado mediante sugerencias de recursos de acelerador pueden usar más aceleradores de lo deseable. Si observas este comportamiento en tu flujo de trabajo, puedes configurar el número máximo de aceleradores que usará el flujo de trabajo. Para ello, define la opción de flujo de trabajo --experiments=max_num_accelerators=NUM.