A funcionalidade de ajuste adequado usa sugestões de recursos do Apache Beam para personalizar os recursos do trabalhador para um pipeline. A capacidade de segmentar vários recursos diferentes para passos específicos do pipeline oferece flexibilidade e capacidade adicionais ao pipeline, bem como potenciais poupanças de custos. Pode aplicar recursos mais caros a passos do pipeline que os exijam e recursos menos caros a outros passos do pipeline. Use o ajuste à direita para especificar os requisitos de recursos para um pipeline completo ou para passos específicos do pipeline.
Apoio técnico e limitações
- As sugestões de recursos são suportadas com os SDKs Java e Python do Apache Beam, versões 2.31.0 e posteriores.
- O ajuste correto é suportado com pipelines em lote.
O ajuste adequado é suportado com pipelines de streaming com a escalabilidade automática horizontal ativada.
- Pode ativá-lo definindo a opção de pipeline
--experiments=enable_streaming_rightfitting.
- Pode ativá-lo definindo a opção de pipeline
O ajuste certo suporta o Dataflow Prime.
O ajuste certo não suporta o FlexRS.
Quando usar o ajuste correto, não use a
worker_acceleratoropção de serviço.
Ative o ajuste à direita
Para ativar o ajuste correto, use uma ou mais das sugestões de recursos disponíveis no seu pipeline. Quando usa uma dica de recurso no seu pipeline, o ajuste correto é ativado automaticamente. Para mais informações, consulte a secção Use sugestões de recursos deste documento.
Sugestões de recursos disponíveis
Estão disponíveis as seguintes sugestões de recursos.
| Sugestão de recurso | Descrição |
|---|---|
min_ram |
A quantidade mínima de RAM em gigabytes a atribuir aos trabalhadores. O Dataflow usa este valor como um limite inferior ao atribuir memória a novos trabalhadores (escalabilidade horizontal) ou a trabalhadores existentes (escalabilidade vertical). Por exemplo: min_ram=NUMBERGB
|
accelerator |
Uma atribuição de GPUs fornecida pelo utilizador que lhe permite controlar a utilização e o custo das GPUs no seu pipeline e respetivas etapas. Especifique o tipo e o número de GPUs a anexar aos trabalhadores do Dataflow como parâmetros da flag. Por exemplo: accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
Para mais informações sobre a utilização de GPUs, consulte o artigo GPUs com o Dataflow. |
Aninhamento de sugestões de recursos
As sugestões de recursos são aplicadas à hierarquia de transformação do pipeline da seguinte forma:
min_ram: O valor numa transformação é avaliado como o maior valor de sugestão entre os valores definidos na própria transformação e todos os respetivos elementos principais na hierarquia da transformação.min_ram- Exemplo: se uma sugestão de transformação interna definir
min_ramcomo 16 GB e a sugestão de transformação externa na hierarquia definirmin_ramcomo 32 GB, é usada uma sugestão de 32 GB para todos os passos em toda a transformação. - Exemplo: se uma sugestão de transformação interna definir
min_ramcomo 16 GB e a sugestão de transformação externa na hierarquia definirmin_ramcomo 8 GB, é usada uma sugestão de 8 GB para todos os passos na transformação externa que não estão na transformação interna, e é usada uma sugestão de 16 GB para todos os passos na transformação interna.
- Exemplo: se uma sugestão de transformação interna definir
accelerator: o valor mais interno na hierarquia da transformação tem precedência.- Exemplo: se uma sugestão de transformação interna
acceleratorfor diferente de uma sugestão de transformação externaacceleratornuma hierarquia, a sugestão de transformação internaacceleratoré usada para a transformação interna.
- Exemplo: se uma sugestão de transformação interna
As sugestões definidas para todo o pipeline são tratadas como se fossem definidas numa transformação mais externa separada.
Use sugestões de recursos
Pode definir sugestões de recursos em todo o pipeline ou em passos do pipeline.
Instruções de recursos de pipeline
Pode definir sugestões de recursos em todo o pipeline quando o executa a partir da linha de comandos.
Para configurar o seu ambiente Python, consulte o tutorial do Python.
Exemplo:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
Sugestões de recursos de passos do pipeline
Pode definir sugestões de recursos em passos do pipeline (transformações) de forma programática.
Java
Para instalar o SDK do Apache Beam para Java, consulte o artigo Instale o SDK do Apache Beam.
Pode definir sugestões de recursos de forma programática nas transformações de pipelines através da classe ResourceHints.
O exemplo seguinte demonstra como definir sugestões de recursos de forma programática em transformações de pipeline.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create().withMinRam("30GB")))
Para definir sugestões de recursos de forma programática em toda a pipeline, use a interface ResourceHintsOptions.
Python
Para instalar o SDK do Apache Beam para Python, consulte o artigo Instale o SDK do Apache Beam.
Pode definir sugestões de recursos de forma programática nas transformações de pipelines através da classe PTransforms.with_resource_hints.
Para mais informações, consulte a aula
ResourceHint.
O exemplo seguinte demonstra como definir sugestões de recursos de forma programática em transformações de pipeline.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB")
Para definir sugestões de recursos em todo o pipeline, use a opção --resource_hints
pipeline quando executar o pipeline. Para ver um exemplo, consulte o artigo
Sugestões de recursos de pipelines.
Go
As sugestões de recursos não são suportadas em Go.
Compatibilidade com vários aceleradores
Num pipeline, as diferentes transformações podem ter configurações de acelerador diferentes. Estas incluem configurações que requerem diferentes tipos de máquinas. Estas configurações do acelerador ao nível da transformação têm precedência sobre a configuração ao nível do pipeline, se tiver sido fornecida.
Encaixe e fusão à direita
Em alguns casos, as transformações definidas com sugestões de recursos diferentes podem ser executadas em trabalhadores no mesmo conjunto de trabalhadores, como parte do processo de otimização de fusão. Quando as transformações são unidas, o Dataflow executa-as num ambiente que satisfaz a união das sugestões de recursos definidas nas transformações. Em alguns casos, isto inclui todo o pipeline.
Quando não é possível unir sugestões de recursos, não ocorre a união. Por exemplo, as sugestões de recursos para diferentes GPUs não são uníveis, pelo que essas transformações não são fundidas.
Também pode impedir a união adicionando uma operação ao seu pipeline que force o Dataflow a materializar um PCollection intermédio. Isto é especialmente útil quando tenta isolar recursos dispendiosos, como GPUs ou máquinas com muita memória, de passos lentos ou computacionalmente dispendiosos que não precisam desses recursos especiais. Nesses casos, pode ser útil forçar uma interrupção da união entre os passos lentos dependentes da CPU e os passos que precisam de GPUs dispendiosas ou máquinas com muita memória, e pagar o custo da materialização associada à interrupção da união. Para saber mais, consulte o artigo
Evite a união.
Streaming right fitting
Para tarefas de streaming, pode ativar o ajuste à direita definindo a opção de pipeline --experiments=enable_streaming_rightfitting.
O ajuste adequado pode melhorar o desempenho do seu pipeline se envolver fases com diferentes requisitos de recursos.
Exemplo: pipeline com fase intensiva de CPU e fase que requer GPU
Um exemplo de pipeline que pode beneficiar do ajuste adequado é aquele que executa uma fase com utilização intensiva da CPU, seguida de uma fase que requer a GPU. Sem o ajuste adequado, tem de configurar um único conjunto de trabalhadores da GPU para executar todas as fases do pipeline, incluindo a fase com utilização intensiva da CPU. Isto pode levar à subutilização dos recursos da GPU quando o conjunto de trabalhadores está a executar a fase com utilização intensiva da CPU.
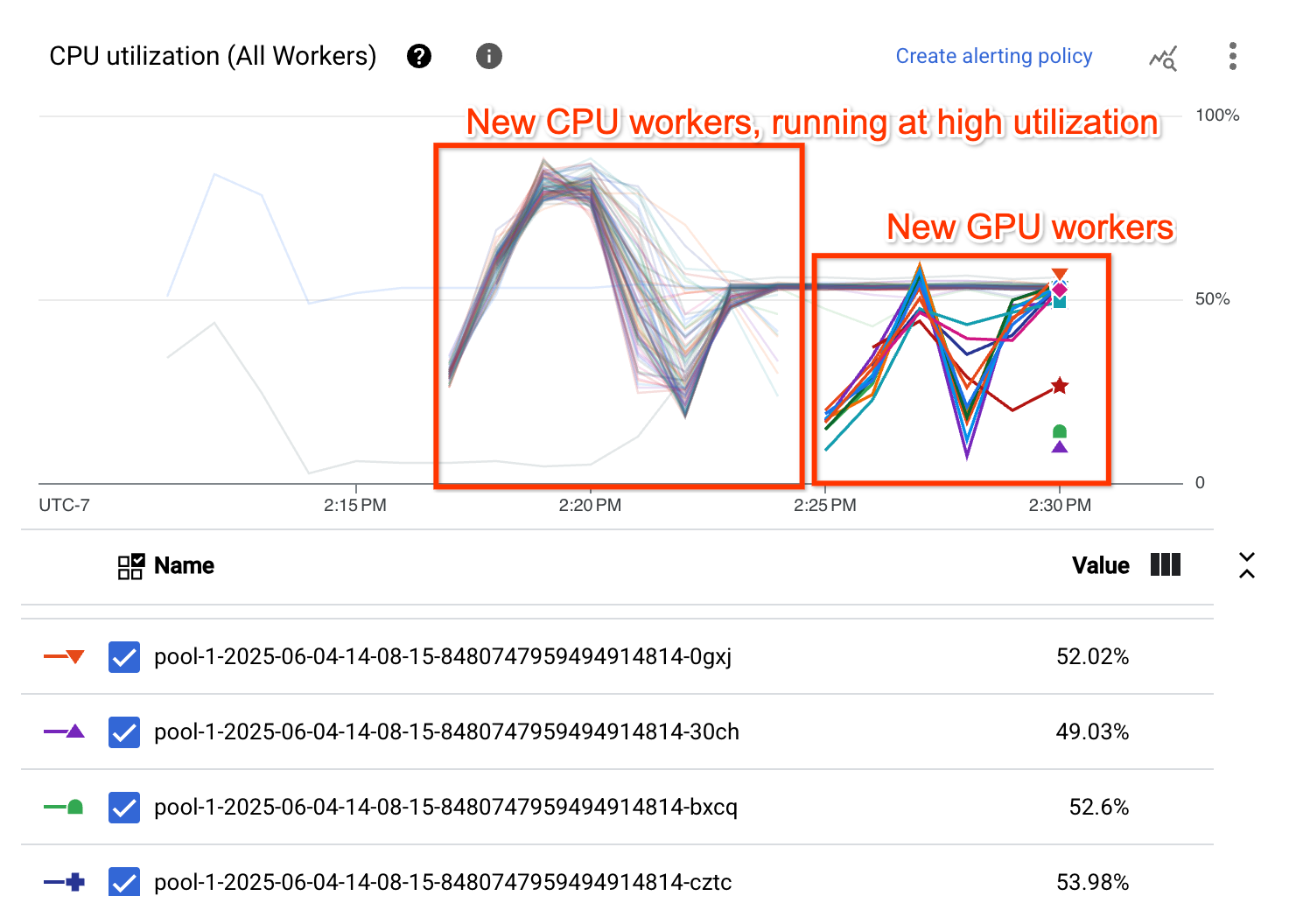
Se o ajuste adequado estiver ativado e for aplicada uma sugestão de recurso ao passo que requer a GPU, o pipeline cria dois conjuntos separados, para que a fase com utilização intensiva da CPU seja executada pelo conjunto de trabalhadores da CPU e a fase que requer a GPU seja executada pelo conjunto de trabalhadores da GPU.
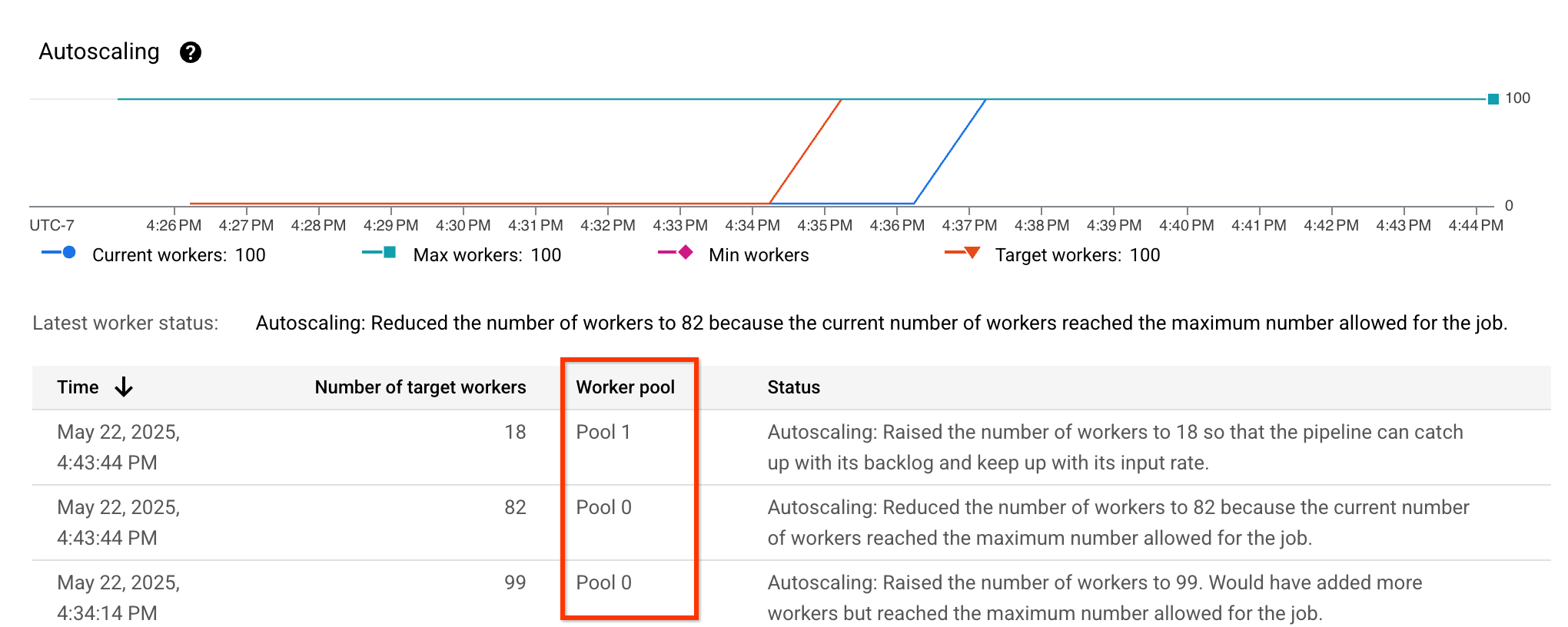
Para este pipeline de exemplo, a tabela de escalamento automático mostra que o conjunto de trabalhadores que executa a fase com utilização intensiva da CPU, Pool 0, é inicialmente aumentado para 99 trabalhadores e, posteriormente, reduzido para 87 trabalhadores. O conjunto de trabalhadores que executa a fase que requer a GPU, Pool 1, é aumentado para 13 trabalhadores:

O gráfico de utilização da CPU mostra que os trabalhadores em ambos os conjuntos de trabalhadores estão a demonstrar uma utilização da CPU globalmente elevada:
Resolva problemas de encaixe correto
Esta secção fornece instruções para resolver problemas comuns relacionados com o ajuste correto.
Configuração inválida
Quando tenta usar o ajuste à direita, ocorre o seguinte erro:
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
Este erro ocorre quando o tipo de GPU selecionado não é compatível com o tipo de máquina selecionado. Para resolver este erro, selecione um tipo de GPU e um tipo de máquina compatíveis. Para ver detalhes de compatibilidade, consulte Plataformas de GPU.
Verifique o ajuste correto
Pode verificar se o ajuste correto está ativado vendo as métricas de dimensionamento automático e verificando se a coluna Worker pool está visível e apresenta diferentes conjuntos:
Desempenho de streaming adequado
As pipelines de streaming com o ajuste adequado ativado nem sempre têm um melhor desempenho do que as pipelines sem o ajuste adequado ativado. Por exemplo:
- O pipeline está a usar mais trabalhadores
- A latência do sistema é superior ou o débito é inferior
- Os tamanhos dos grupos de trabalhadores estão a mudar com mais frequência ou não estão a estabilizar
Se observar este comportamento no seu pipeline, pode desativar o ajuste à direita removendo a --experiments=enable_streaming_rightfittingopção do pipeline. Além disso, os pipelines de streaming com o ajuste adequado ativado que usam sugestões de recursos do acelerador podem usar mais aceleradores do que o desejável. Se observar esta situação na sua pipeline, pode configurar um número máximo de aceleradores usados pela pipeline definindo a opção de pipeline --experiments=max_num_accelerators=NUM.