Cloud Profiler est un profileur statistique peu gourmand en ressources, qui recueille en permanence des informations sur l'utilisation du processeur et l'allocation de mémoire, à partir de vos applications de production. Pour en savoir plus, consultez la page Concepts du profilage. Pour dépanner ou surveiller les performances du pipeline, utilisez l'intégration de Dataflow avec Cloud Profiler pour identifier les parties du code du pipeline qui consomment le plus de ressources.
Pour obtenir des conseils de dépannage et des stratégies de débogage pour la création ou l'exécution de votre pipeline Dataflow, consultez la page Dépanner et déboguer les pipelines.
Avant de commencer
Explorez les concepts du profilage et familiarisez-vous avec l'interface de Profiler. Pour vous familiariser avec l'interface de Profiler, consultez la page Sélectionner les profils à analyser.
L'API Cloud Profiler doit être activée pour votre projet avant le démarrage de votre tâche.
Elle est activée automatiquement la première fois que vous accédez à la page de Profiler.
Vous pouvez également activer l'API Cloud Profiler à l'aide de l'outil de ligne de commande gcloud de Google Cloud CLI ou de la console Google Cloud.
Pour utiliser Cloud Profiler, votre projet doit disposer d'un quota suffisant.
En outre, le compte de service du nœud de calcul de la tâche Dataflow doit disposer des autorisations appropriées pour Profiler. Par exemple, pour créer des profils, le compte de service du nœud de calcul doit disposer de l'autorisation cloudprofiler.profiles.create, qui est incluse dans le rôle IAM Agent Cloud Profiler (roles/cloudprofiler.agent).
Pour en savoir plus, consultez la page Contrôle des accès avec IAM.
Activer Cloud Profiler pour les pipelines Dataflow
Cloud Profiler est disponible pour les pipelines Dataflow écrits dans le SDK Apache Beam pour Java et Python, version 2.33.0 ou ultérieure. Les pipelines Python doivent utiliser l'exécuteur Dataflow v2. Cloud Profiler peut être activé au moment du démarrage du pipeline. La surcharge de mémoire et de processeur amortie devrait être inférieure à 1 % pour vos pipelines.
Java
Pour activer le profilage du processeur, démarrez le pipeline avec l'option suivante.
--dataflowServiceOptions=enable_google_cloud_profiler
Pour activer le profilage du tas, démarrez le pipeline avec les options suivantes. Le profilage du tas nécessite Java 11 ou une version ultérieure.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Pour utiliser Cloud Profiler, votre pipeline Python doit s'exécuter avec l'exécuteur v2 de Dataflow.
Pour activer le profilage du processeur, démarrez le pipeline avec l'option suivante. Le profilage du tas de mémoire n'est pas encore compatible avec Python.
--dataflow_service_options=enable_google_cloud_profiler
Accéder
Pour activer le profilage de processeur et de tas de mémoire, démarrez le pipeline avec l'option suivante.
--dataflow_service_options=enable_google_cloud_profiler
Si vous déployez vos pipelines à partir de modèles Dataflow et que vous souhaitez activer Cloud Profiler, spécifiez comme tests supplémentaires les options enable_google_cloud_profiler et enable_google_cloud_heap_sampling.
Console
Si vous utilisez un modèle fourni par Google, vous pouvez spécifier les options sur la page Créer une tâche à partir d'un modèle de Dataflow, dans le champ Tests supplémentaires.
gcloud
Si vous utilisez Google Cloud CLI pour exécuter des modèles (gcloud
dataflow jobs run ou gcloud dataflow flex-template run, selon le type de modèle), utilisez l'option --additional-experiments pour spécifier les options.
API
Si vous utilisez l'API REST pour exécuter des modèles, selon le type de modèle, spécifiez les indicateurs à l'aide du champ additionalExperiments de l'environnement d'exécution, soit RuntimeEnvironment, soit FlexTemplateRuntimeEnvironment.
Afficher les données de profilage
Si Cloud Profiler est activé, un lien vers la page de Profiler s'affiche sur la page de la tâche.
Sur la page de Profiler, vous trouverez également les données de profilage de votre pipeline Dataflow. Le champ Service correspond au nom de votre tâche et le champ Version à votre ID de tâche.

Utiliser Cloud Profiler
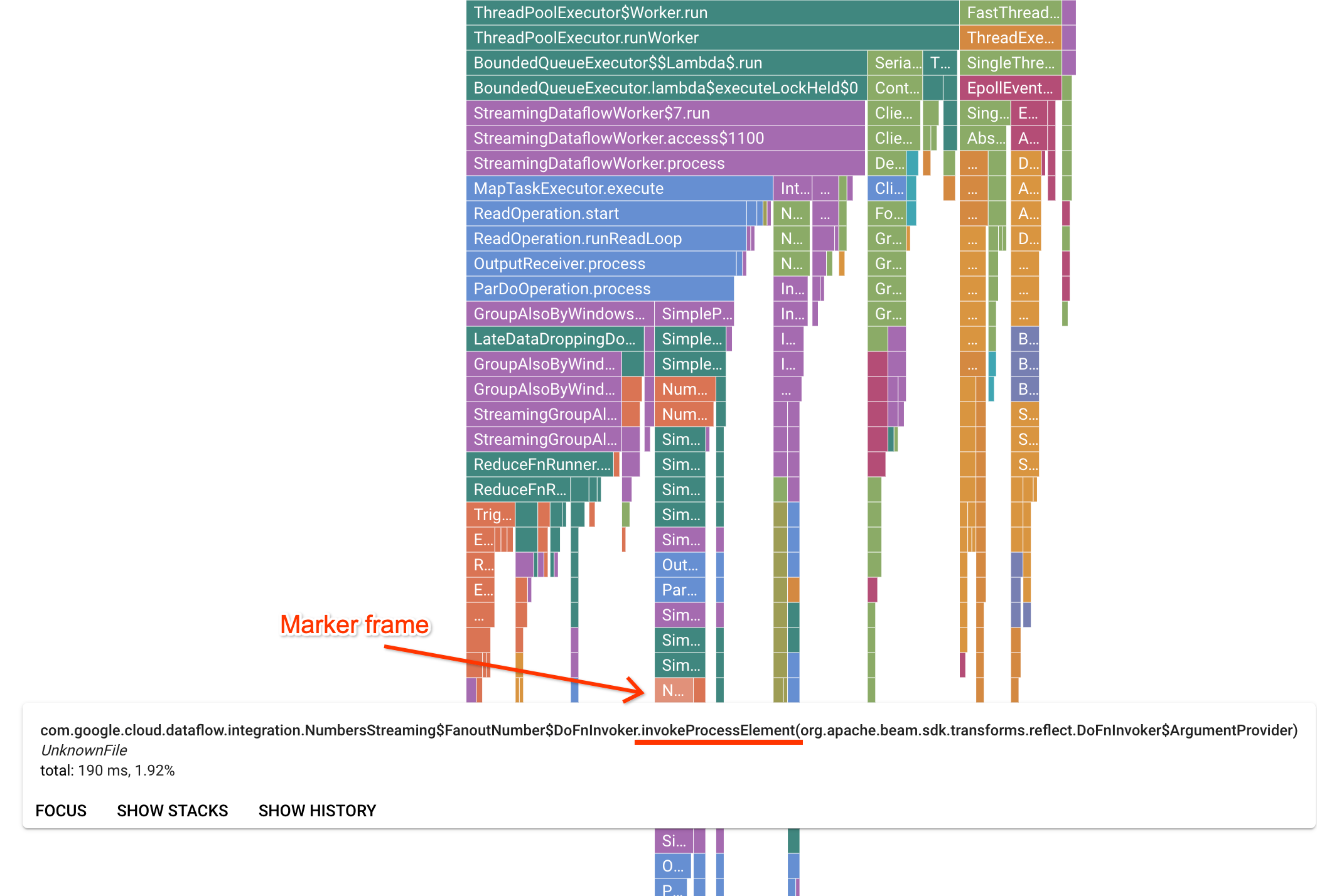
La page de Profiler contient un graphique de type "flamme" qui affiche des statistiques pour chaque cadre exécuté sur un nœud de calcul. Dans la direction horizontale, vous pouvez voir le temps nécessaire à chaque cadre pour l'exécution en temps CPU. Dans la direction verticale, vous pouvez voir les traces de pile et le code s'exécutant en parallèle. Les traces de la pile sont dominées par le code d'infrastructure de l'exécuteur. À des fins de débogage, nous sommes généralement intéressés par l'exécution du code utilisateur, qui se trouve généralement près des conseils en bas du graphique. Vous pouvez identifier le code utilisateur en recherchant des cadres de repère, qui représentent le code d'exécution connu pour n'appeler que le code utilisateur. Dans le cas de l'exécuteur Beam ParDo, une couche d'adaptateur dynamique est créée pour appeler la signature de la méthode DoFn fournie par l'utilisateur. Cette couche peut être identifiée comme un cadre avec le suffixe invokeProcessElement. L'image suivante montre une façon de trouver un cadre de repère.
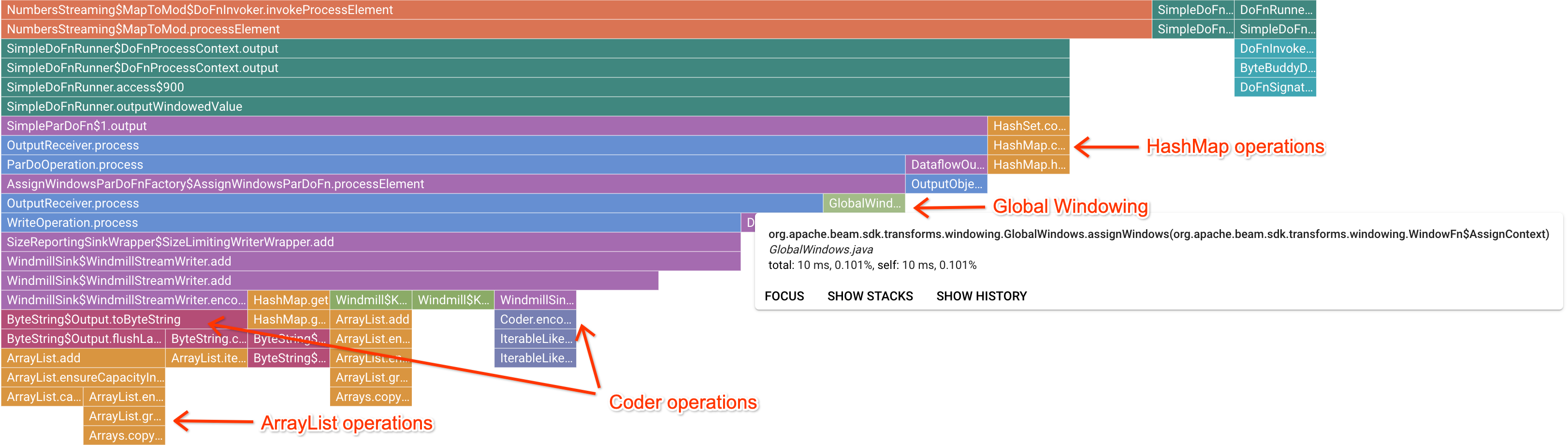
Après avoir cliqué sur un cadre de repère intéressant, le graphique de type "flamme" se concentre sur cette trace de la pile, offrant ainsi une bonne idée du code utilisateur de longue durée. Les opérations les plus lentes peuvent indiquer l'origine des goulots d'étranglement et offrent des possibilités d'optimisation. Dans l'exemple suivant, il est possible de constater que le fenêtrage global est utilisé avec un objet ByteArrayCoder. Dans ce cas, le codeur peut constituer un bon point d'optimisation, car il prend beaucoup de temps CPU par rapport aux opérations ArrayList et HashMap.
Résoudre les problèmes liés à Cloud Profiler
Si vous activez Cloud Profiler et que votre pipeline ne génère pas de données de profilage, cela peut être dû à l'une des conditions suivantes.
Votre pipeline utilise une ancienne version du SDK Apache Beam. Pour utiliser Cloud Profiler, vous devez utiliser le SDK Apache Beam version 2.33.0 ou ultérieure. Vous pouvez consulter la version du SDK Apache Beam de votre pipeline via la page de la tâche. Si votre tâche est créée à partir de modèles Dataflow, ces modèles doivent utiliser les versions compatibles du SDK.
Votre projet dépasse le quota Cloud Profiler. Vous pouvez consulter les informations d'utilisation du quota depuis la page des quotas de votre projet. Une erreur telle que
Failed to collect and upload profile whose profile type is WALLpeut se produire si le quota de Cloud Profiler est dépassé. Si vous avez atteint votre quota, le service Cloud Profiler rejette les données de profilage. Pour en savoir plus sur les quotas de Cloud Profiler, consultez la page Quotas et limites.Votre job n'a pas été exécuté assez longtemps pour générer des données pour Cloud Profiler. Les jobs exécutés pendant de courtes durées, par exemple moins de cinq minutes, peuvent ne pas fournir suffisamment de données de profilage pour que Cloud Profiler génère des résultats.
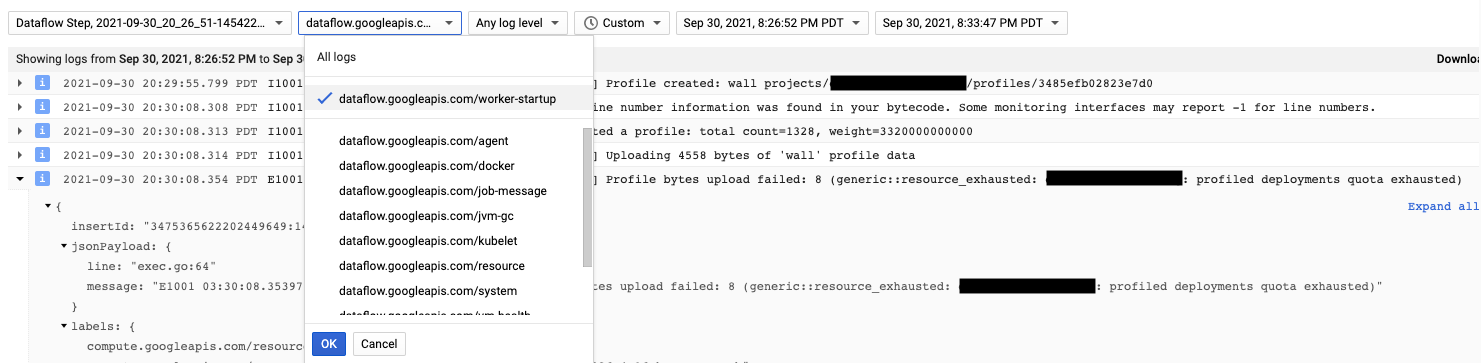
L'agent Cloud Profiler est installé lors du démarrage du nœud de calcul Dataflow. Les messages de journal générés par Cloud Profiler sont disponibles dans le type de journal dataflow.googleapis.com/worker-startup.
Parfois, des données de profilage existent, mais Cloud Profiler n'affiche aucun résultat. Profiler affiche un message semblable à celui-ci : There were
profiles collected for the specified time range, but none match the current
filters.
Essayez les solutions suivantes pour résoudre ce problème.
Assurez-vous que la période et l'heure de fin dans Profiler sont incluses dans le temps écoulé.
Vérifiez que le bon job est sélectionné dans Profiler. Le champ Service correspond au nom de votre job.
Vérifiez que l'option de pipeline
job_namea la même valeur que le nom du job sur la page du job Dataflow.Si vous avez spécifié un argument de nom de service lors du chargement de l'agent Profiler, vérifiez que le nom de service est correctement configuré.