Cloud Profiler는 오버헤드가 낮은 통계 프로파일러로, 프로덕션 애플리케이션에서 CPU 사용량과 메모리 할당 정보를 지속적으로 수집합니다. 자세한 내용은 프로파일링 개념을 참조하세요. 파이프라인 성능 문제를 해결하거나 모니터링하려면 Cloud Profiler와 Dataflow 통합을 사용하여 가장 많은 리소스를 소비하는 파이프라인 코드 부분을 식별합니다.
Dataflow 파이프라인을 빌드하거나 실행하기 위한 문제해결 팁과 디버깅 전략은 파이프라인 문제해결 및 디버깅을 참조하세요.
시작하기 전에
프로파일링 개념을 이해하고 Profiler 인터페이스를 숙지해야 합니다. Profiler 인터페이스를 시작하는 방법은 분석할 프로필 선택을 참조하세요.
작업이 시작되기 전에 프로젝트에 Cloud Profiler API를 사용 설정해야 합니다.
처음 Profiler 페이지를 방문할 때 자동으로 사용 설정됩니다.
또는 Google Cloud CLI gcloud 명령줄 도구 또는 Google Cloud 콘솔을 사용하여 Cloud Profiler API를 사용 설정할 수 있습니다.
Cloud Profiler를 사용하려면 프로젝트에 있는 할당량이 충분해야 합니다.
또한 Dataflow 작업의 작업자 서비스 계정에는 Profiler에 대한 적절한 권한이 있어야 합니다. 예를 들어 프로필을 만들려면 작업자 서비스 계정에 Cloud Profiler Agent(roles/cloudprofiler.agent) IAM 역할에 포함된 cloudprofiler.profiles.create 권한이 있어야 합니다.
자세한 내용은 IAM으로 액세스 제어를 참조하세요.
Dataflow 파이프라인에 Cloud Profiler 사용 설정
Cloud Profiler는 Java 및 Python용 Apache Beam SDK 버전 2.33.0 이상으로 작성된 Dataflow 파이프라인에 사용할 수 있으며, Python 파이프라인에서는 Dataflow Runner v2를 사용해야 합니다. Cloud Profiler는 파이프라인 시작 시 사용 설정할 수 있습니다. 분할 상쇄된 CPU와 메모리 오버헤드는 파이프라인의 1% 미만일 것으로 예상됩니다.
자바
CPU 프로파일링을 사용 설정하려면 다음 옵션을 사용하여 파이프라인을 시작합니다.
--dataflowServiceOptions=enable_google_cloud_profiler
힙 프로파일링을 사용 설정하려면 다음 옵션을 사용하여 파이프라인을 시작합니다. 힙 프로파일링에는 Java 11 이상이 필요합니다.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Cloud Profiler를 사용하려면 Python 파이프라인이 Dataflow Runner v2로 실행되어야 합니다.
CPU 프로파일링을 사용 설정하려면 다음 옵션을 사용하여 파이프라인을 시작합니다. 힙 프로파일링은 아직 Python에서 지원되지 않습니다.
--dataflow_service_options=enable_google_cloud_profiler
Go
CPU 및 힙 프로파일링을 사용 설정하려면 다음 옵션을 사용하여 파이프라인을 시작합니다.
--dataflow_service_options=enable_google_cloud_profiler
Dataflow 템플릿에서 파이프라인을 배포할 때 Cloud Profiler를 사용 설정하려면 enable_google_cloud_profiler 및 enable_google_cloud_heap_sampling 플래그를 추가 실험으로 지정합니다.
콘솔
Google 제공 템플릿을 사용하는 경우 Dataflow 템플릿에서 작업 만들기 페이지에서 추가 실험 필드에 플래그를 지정할 수 있습니다.
gcloud
Google Cloud CLI를 사용하여 gcloud
dataflow jobs run 또는 gcloud dataflow flex-template run의 템플릿을 실행하는 경우 템플릿 유형에 따라 --additional-experiments 옵션을 사용해서 플래그를 지정합니다.
API
REST API를 사용해서 템플릿을 실행하는 경우 템플릿 유형에 따라 RuntimeEnvironment 또는 FlexTemplateRuntimeEnvironment에 해당하는 런타임 환경의 additionalExperiments 필드를 사용해서 플래그를 지정합니다.
프로파일링 데이터 보기
Cloud Profiler가 사용 설정되면 작업 페이지에 Profiler 페이지 링크가 표시됩니다.
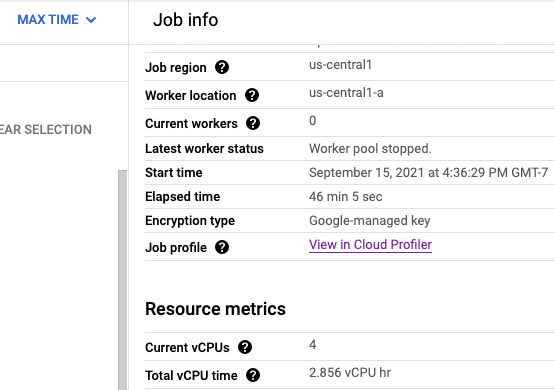
또한 프로파일러 페이지에서 Dataflow 파이프라인에 대한 프로파일링 데이터를 찾을 수도 있습니다. 서비스는 작업 이름이고 버전은 작업 ID입니다.

Cloud Profiler 사용
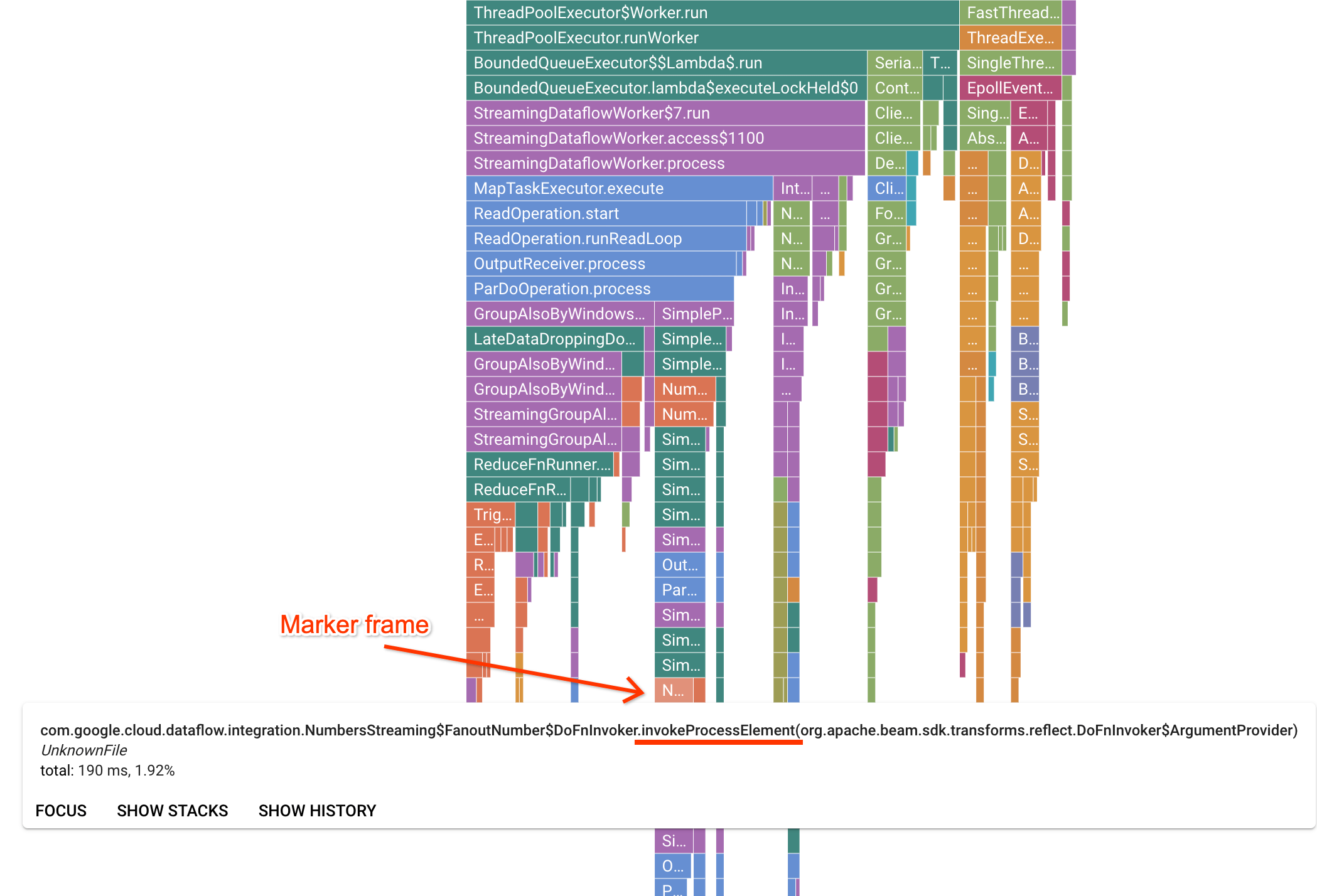
Profiler 페이지에는 작업자에서 실행 중인 각 프레임의 통계를 표시하는 Flame 그래프가 포함되어 있습니다. 가로 방향에서는 각 프레임을 실행하는 데 걸린 시간을 CPU 시간 관점에서 확인할 수 있습니다. 수직 방향으로는 스택 트레이스와 코드가 동시에 실행되는 것을 볼 수 있습니다. 스택 트레이스는 실행기 인프라 코드에서 사용됩니다. 디버깅을 위해 Google은 일반적으로 사용자 코드 실행에 관심이 있으며 사용자 코드는 보통 그래프 하단 팁 근처에 있습니다. 사용자 코드만 호출하는 것으로 알려진 실행기 코드를 나타내는 마커 프레임을 찾아서 사용자 코드를 식별할 수 있습니다. Beam ParDo 실행기의 경우 사용자가 제공한 DoFn 메서드 서명을 호출하도록 동적 어댑터 레이어가 생성됩니다. 이 레이어는 invokeProcessElement 서픽스가 있는 프레임으로 식별될 수 있습니다. 다음 이미지에서는 마커 프레임을 찾는 방법을 보여줍니다.
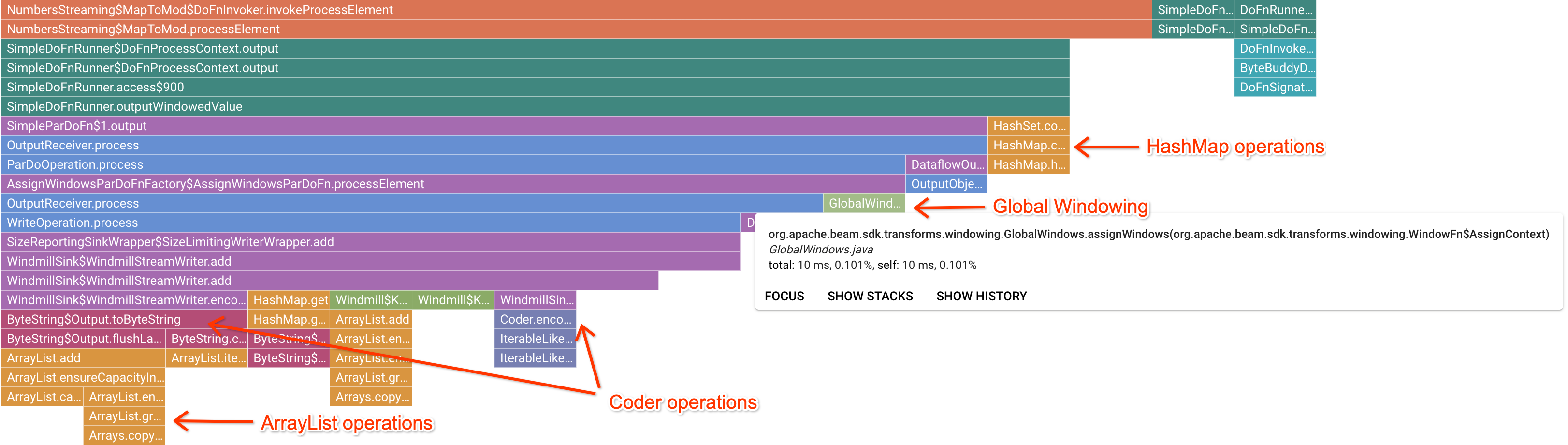
흥미로운 마커 프레임을 클릭하면 Flame 그래프에서 해당 스택 트레이스를 집중적으로 표시하므로 장기간 실행 중인 사용자 코드를 파악할 수 있습니다. 가장 느린 작업은 병목 현상이 발생한 지점과 현재의 최적화 기회를 나타낼 수 있습니다. 다음 예시에서는 ByteArrayCoder와 함께 전역 윈도우가 사용되고 있는 것을 확인할 수 있습니다. 이 경우 코더가 ArrayList 및 HashMap 작업에 비해 상당한 CPU 시간을 소모하므로 최적화용으로 적합할 수 있습니다.
Cloud Profiler 문제 해결
Cloud Profiler를 사용 설정해도 파이프라인이 프로파일링 데이터를 생성하지 않으면 다음 조건 중 하나가 원인일 수 있습니다.
파이프라인에서 이전 Apache Beam SDK 버전을 사용합니다. Cloud Profiler를 사용하려면 Apache Beam SDK 버전 2.33.0 이상을 사용해야 합니다. 작업 페이지에서 파이프라인의 Apache Beam SDK 버전을 볼 수 있습니다. 작업이 Dataflow 템플릿에서 생성된 경우에는 템플릿에 지원되는 SDK 버전이 사용되어야 합니다.
프로젝트의 Cloud Profiler 할당량이 부족합니다. 프로젝트의 할당량 페이지에서 할당량 사용량을 볼 수 있습니다. Cloud Profiler 할당량이 초과되면
Failed to collect and upload profile whose profile type is WALL과 같은 오류가 발생할 수 있습니다. 할당량에 도달하면 Cloud Profiler 서비스가 프로파일링 데이터를 거부합니다. Cloud Profiler 할당량에 대한 자세한 내용은 할당량 및 한도를 참고하세요.작업이 Cloud Profiler의 데이터를 생성하기에 충분히 오래 실행되지 않았습니다. 짧은 시간(예: 5분 미만) 동안 실행되는 작업은 Cloud Profiler에서 결과를 생성하는 데 충분한 프로파일링 데이터를 제공하지 못할 수 있습니다.
Cloud Profiler 에이전트는 Dataflow 작업자 시작 중에 설치됩니다. Cloud Profiler에서 생성한 로그 메시지는 dataflow.googleapis.com/worker-startup 로그 유형에서 확인할 수 있습니다.
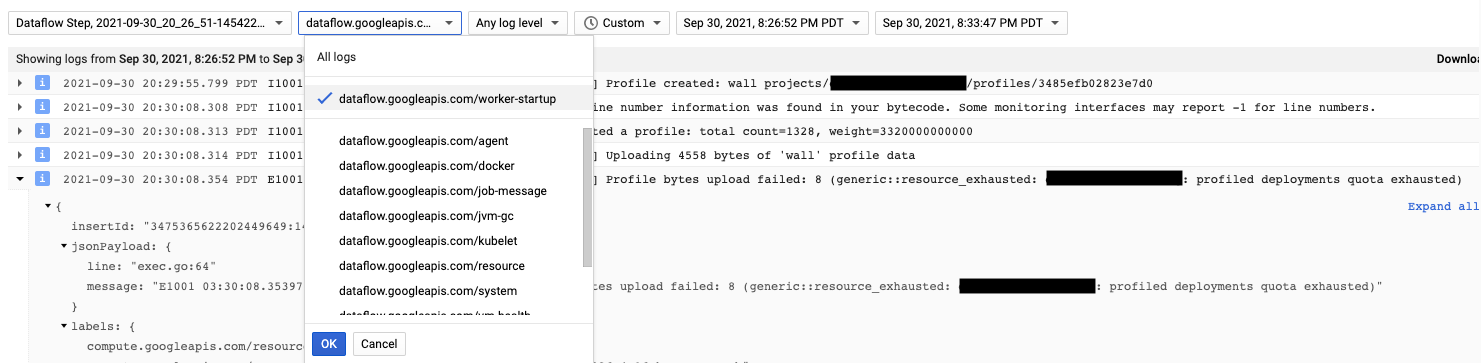
프로파일링 데이터가 있지만 Cloud Profiler에 출력이 표시되지 않는 경우가 있습니다. 프로파일러에 There were
profiles collected for the specified time range, but none match the current
filters와 유사한 메시지가 표시됩니다.
이 문제를 해결하려면 다음 문제 해결 단계를 시도해 보세요.
Profiler의 기간 및 종료 시간이 작업의 경과 시간을 포함하는지 확인합니다.
Profiler에서 올바른 작업이 선택되어 있는지 확인합니다. 서비스는 작업 이름입니다.
job_name파이프라인 옵션에 Dataflow 작업 페이지의 작업 이름과 동일한 값이 있는지 확인합니다.Profiler 에이전트를 로드할 때 service-name 인수를 지정한 경우 서비스 이름이 올바르게 구성되었는지 확인합니다.