Cloud Profiler è un profiler statistico a basso overhead che raccoglie continuamente informazioni sull'utilizzo della CPU e sull'allocazione della memoria dalle tue applicazioni di produzione. Per maggiori dettagli, consulta Concetti di profilazione. Per risolvere i problemi o monitorare le prestazioni della pipeline, utilizza l'integrazione di Dataflow con Cloud Profiler per identificare le parti del codice della pipeline che consumano la maggior parte delle risorse.
Per suggerimenti per la risoluzione dei problemi e strategie di debug per la creazione o l'esecuzione della pipeline Dataflow, consulta Risoluzione dei problemi e debug delle pipeline.
Prima di iniziare
Comprendi i concetti di profilazione e familiarizza con l'interfaccia di Profiler. Per informazioni su come iniziare a utilizzare l'interfaccia di Profiler, vedi Selezionare i profili da analizzare.
L'API Cloud Profiler deve essere abilitata per il tuo progetto prima dell'avvio del job.
Viene attivato automaticamente la prima volta che visiti la pagina
Profiler.
In alternativa, puoi abilitare l'API Cloud Profiler utilizzando lo strumento a riga di comando Google Cloud CLI gcloud o la console Google Cloud .
Per utilizzare Cloud Profiler, il tuo progetto deve disporre di una quota sufficiente.
Inoltre, il
service account worker
per il job Dataflow deve disporre
delle autorizzazioni appropriate per Profiler. Ad esempio, per creare profili, il account di servizio worker deve disporre dell'autorizzazione cloudprofiler.profiles.create, inclusa nel ruolo IAM Cloud Profiler Agent (roles/cloudprofiler.agent).
Per saperne di più, consulta Controllo dell'accesso con IAM.
Abilita Cloud Profiler per le pipeline Dataflow
Cloud Profiler è disponibile per le pipeline Dataflow scritte in SDK Apache Beam per Java e Python, versione 2.33.0 o successive. Le pipeline Python devono utilizzare Dataflow Runner v2. Cloud Profiler può essere attivato all'avvio della pipeline. L'overhead ammortizzato di CPU e memoria dovrebbe essere inferiore all'1% per le pipeline.
Java
Per abilitare la profilazione della CPU, avvia la pipeline con la seguente opzione.
--dataflowServiceOptions=enable_google_cloud_profiler
Per abilitare la profilazione dell'heap, avvia la pipeline con le seguenti opzioni. La profilazione dell'heap richiede Java 11 o versioni successive.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Per utilizzare Cloud Profiler, la pipeline Python deve essere eseguita con Runner v2 di Dataflow.
Per abilitare la profilazione della CPU, avvia la pipeline con la seguente opzione. La profilazione dell'heap non è ancora supportata per Python.
--dataflow_service_options=enable_google_cloud_profiler
Vai
Per abilitare la profilazione di CPU e heap, avvia la pipeline con la seguente opzione.
--dataflow_service_options=enable_google_cloud_profiler
Se esegui il deployment delle pipeline dai modelli Dataflow e vuoi attivare Cloud Profiler,
specifica i flag enable_google_cloud_profiler e
enable_google_cloud_heap_sampling come esperimenti aggiuntivi.
Console
Se utilizzi un modello fornito da Google, puoi specificare i flag nella pagina Crea job da modello di Dataflow nel campo Esperimenti aggiuntivi.
gcloud
Se utilizzi Google Cloud CLI per eseguire
modelli, gcloud
dataflow jobs run o gcloud dataflow flex-template run, a seconda
del tipo di modello, utilizza l'opzione --additional-experiments
per specificare i flag.
API
Se utilizzi l'API REST
per eseguire i modelli, a seconda del tipo di modello, specifica i flag utilizzando il
campo additionalExperiments dell'ambiente di runtime, RuntimeEnvironment o FlexTemplateRuntimeEnvironment.
Visualizzare i dati di profilazione
Se Cloud Profiler è abilitato, nella pagina del job viene visualizzato un link alla pagina Profiler.
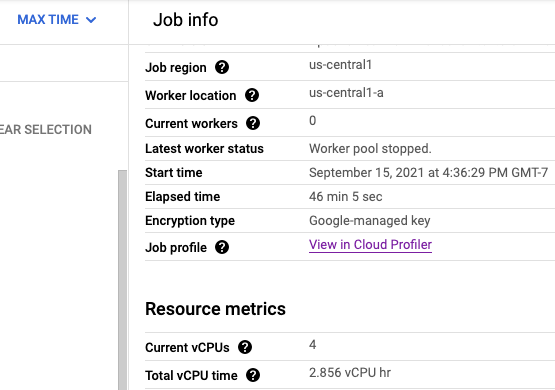
Nella pagina Profiler puoi trovare anche i dati di profilazione per la tua pipeline Dataflow. Il servizio è il nome del tuo job e la versione è l'ID del tuo job.

Utilizzo di Cloud Profiler
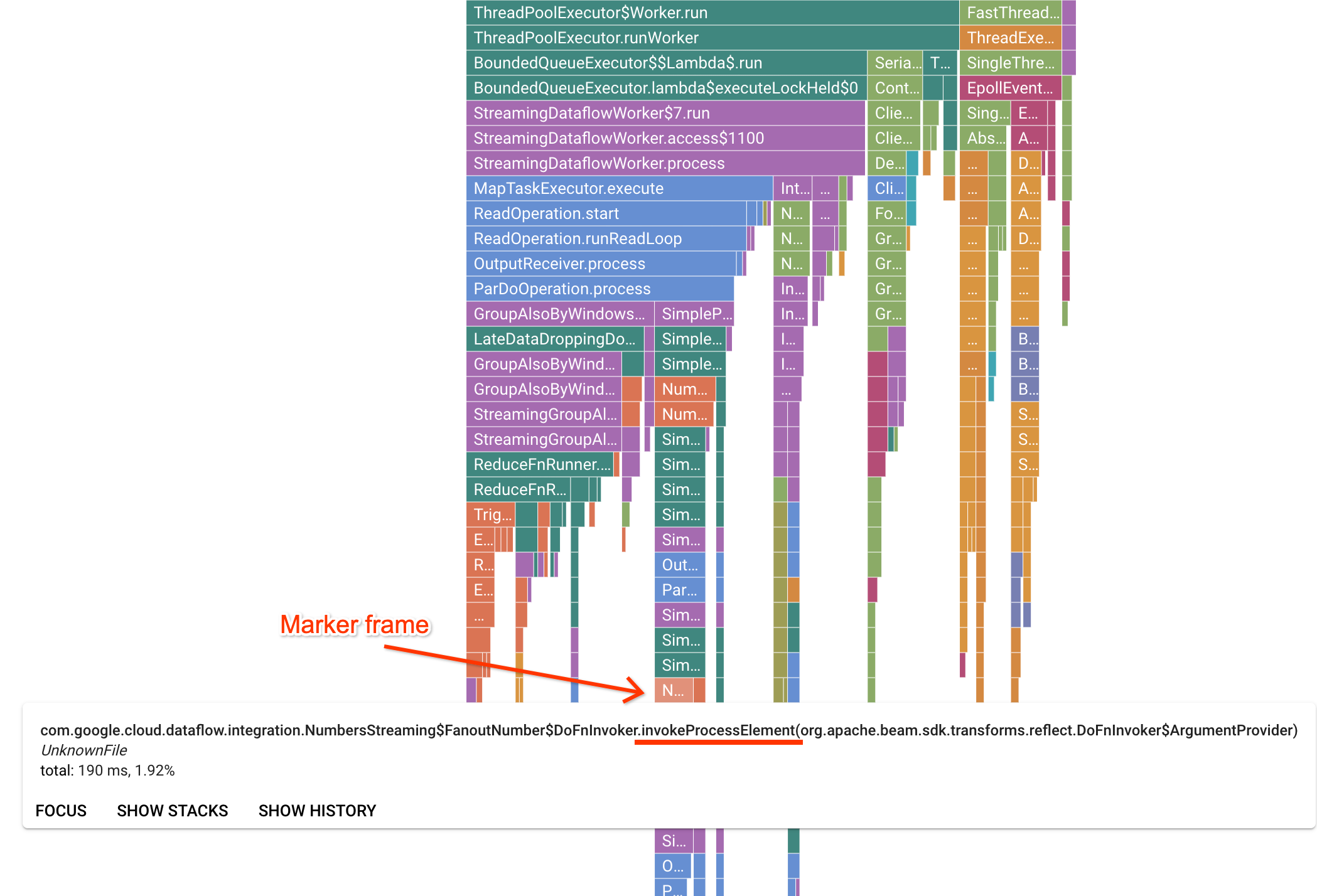
La pagina Profiler contiene un grafico a fiamma che mostra le statistiche per ogni frame in esecuzione su un worker. In direzione orizzontale, puoi vedere quanto tempo ha impiegato ogni frame per essere eseguito in termini di tempo di CPU. In direzione verticale, puoi vedere le analisi dello stack e il codice in esecuzione in parallelo. Gli stack trace sono dominati dal codice dell'infrastruttura del runner. Ai fini del debug, di solito ci interessa l'esecuzione del codice utente, che in genere si trova vicino ai suggerimenti in basso del grafico. Il codice utente può essere identificato cercando i frame di marcatore, che rappresentano il codice runner noto per chiamare solo il codice utente. Nel caso del runner Beam ParDo, viene creato un livello di adattamento dinamico per richiamare la firma del metodo DoFn fornita dall'utente. Questo livello può essere identificato come frame con il suffisso invokeProcessElement. L'immagine seguente mostra una dimostrazione di come trovare un frame marcatore.
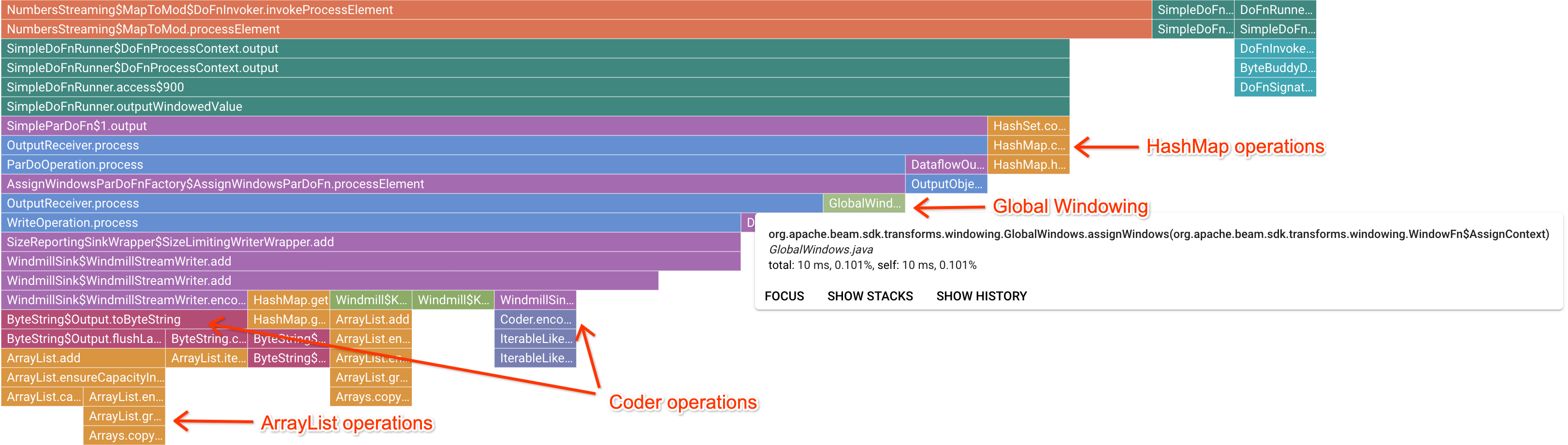
Dopo aver fatto clic su un frame di marcatore interessante, il grafico a fiamma si concentra su quella analisi dello stack, fornendo una buona idea del codice utente a esecuzione prolungata. Le operazioni più lente possono indicare dove si sono formati colli di bottiglia e presentare opportunità di ottimizzazione. Nell'esempio seguente, è possibile vedere che il raggruppamento in finestre globale viene utilizzato con un ByteArrayCoder. In questo caso, il codificatore potrebbe essere un'area adatta all'ottimizzazione perché occupa una quantità significativa di tempo della CPU rispetto alle operazioni ArrayList e HashMap.
Risolvi i problemi di Cloud Profiler
Se abiliti Cloud Profiler e la tua pipeline non genera dati di profilazione, la causa potrebbe essere una delle seguenti condizioni.
La pipeline utilizza una versione precedente dell'SDK Apache Beam. Per utilizzare Cloud Profiler, devi utilizzare l'SDK Apache Beam versione 2.33.0 o successive. Puoi visualizzare la versione dell'SDK Apache Beam della pipeline nella pagina del job. Se il job viene creato da modelli Dataflow, questi devono utilizzare le versioni dell'SDK supportate.
Il tuo progetto sta per esaurire la quota di Cloud Profiler. Puoi visualizzare l'utilizzo delle quote nella pagina delle quote del tuo progetto. Se la quota di Cloud Profiler viene superata, può verificarsi un errore come
Failed to collect and upload profile whose profile type is WALL. Il servizio Cloud Profiler rifiuta i dati di profilazione se hai raggiunto la quota. Per ulteriori informazioni sulle quote di Cloud Profiler, consulta Quote e limiti.Il job non è stato eseguito abbastanza a lungo per generare dati per Cloud Profiler. I job eseguiti per periodi brevi, ad esempio meno di cinque minuti, potrebbero non fornire dati di profilazione sufficienti per consentire a Cloud Profiler di generare risultati.
L'agente Cloud Profiler viene installato durante l'avvio del worker Dataflow. I messaggi di log generati da Cloud Profiler sono disponibili nel tipo di log dataflow.googleapis.com/worker-startup.
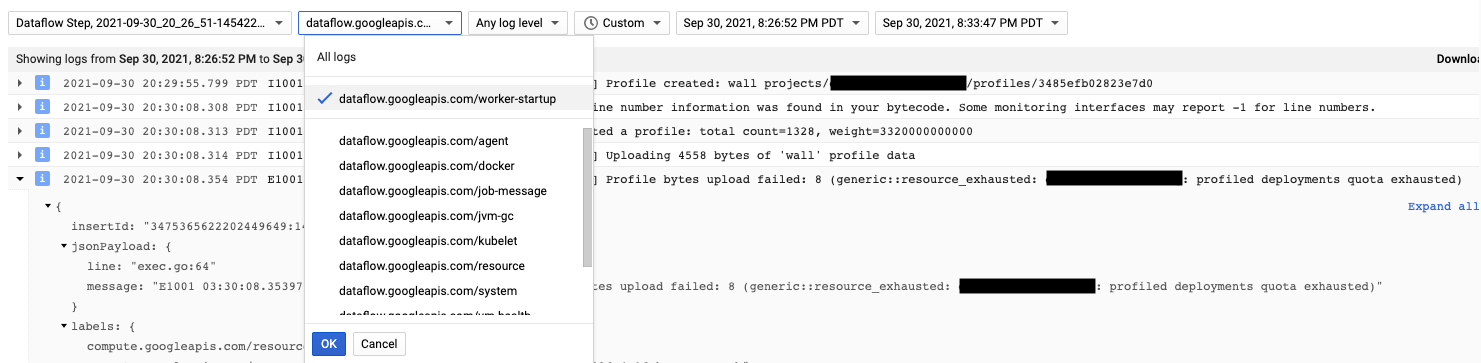
A volte i dati di profilazione esistono, ma Cloud Profiler non mostra alcun
output. Profiler mostra un messaggio simile a There were
profiles collected for the specified time range, but none match the current
filters.
Per risolvere il problema, prova i seguenti passaggi per la risoluzione dei problemi.
Assicurati che l'intervallo di tempo e l'ora di fine in Profiler includano il tempo trascorso del job.
Verifica che nel Profiler sia selezionato il job corretto. Il servizio è il nome del tuo job.
Verifica che l'opzione della pipeline
job_nameabbia lo stesso valore del nome del job nella pagina dei job Dataflow.Se hai specificato un argomento service-name durante il caricamento dell'agente Profiler, verifica che il nome del servizio sia configurato correttamente.