本页面概述了开发 Dataflow 流水线时可以使用的最佳做法。使用这些最佳做法具有以下优势:
- 提高流水线可观测性和性能
- 提高开发者生产力
- 增强流水线的可测试性
本页面中的 Apache Beam 代码示例使用的是 Java,但内容适用于 Apache Beam Java SDK、Python SDK 和 Go SDK。
需要思考的问题
设计流水线时,请考虑以下问题:
- 流水线的输入数据存储在什么位置?您有多少组输入数据?
- 您的数据是什么样的?
- 您希望如何处理数据?
- 流水线的输出数据应位于何处?
- 您的 Dataflow 作业是否使用 Assured Workloads?
使用模板
如需加速流水线开发,请尽可能使用 Dataflow 模板,而不是通过编写 Apache Beam 代码来构建流水线。模板具有以下优点:
- 模板可以重复使用。
- 模板可让您通过更改特定的流水线参数来自定义每项作业。
- 获得您所提供权限的任何人都可以使用模板来部署流水线。例如,开发者可以通过模板创建作业,之后组织中的数据科学家可以部署该模板。
您可以使用 Google 提供的模板,也可以创建自己的模板。某些 Google 提供的模板让您能够添加自定义逻辑添来作为流水线步骤。例如,Pub/Sub to BigQuery 模板提供了一个参数,用于运行存储在 Cloud Storage 中的 JavaScript 用户定义的函数 (UDF)。
由于 Google 提供的模板是开源的,采用 Apache License 2.0 许可,因此您可以将其用作新流水线的基础。模板也可用作代码示例。请在 GitHub 代码库中查看模板代码。
Assured Workloads
Assured Workloads 有助于强制执行Google Cloud 客户的安全性和合规性要求。例如,欧盟区域以及对主权控制的支持有助于为欧盟客户强制执行数据驻留和数据主权保证。为了提供这些功能,某些 Dataflow 功能会受到限制。如果您将 Assured Workloads 与 Dataflow 搭配使用,则流水线访问的所有资源都必须位于组织的 Assured Workloads 项目或文件夹中。这些资源包括:
- Cloud Storage 存储桶
- BigQuery 数据集
- Pub/Sub 主题和订阅
- Firestore 数据集
- I/O 连接器
在 Dataflow 中,对于 2024 年 3 月 7 日之后创建的流处理作业,所有用户数据都使用 CMEK 进行加密。
对于在 2024 年 3 月 7 日之前创建的流处理作业,基于密钥的操作(例如数据选取、分组和联接)中使用的数据密钥不受 CMEK 加密保护。如需为作业启用此加密,请排空或取消作业,然后重启作业。如需了解详情,请参阅流水线状态制品加密。
在流水线之间共享数据
我们并未提供可在流水线之间共享数据或处理上下文的 Dataflow 专用跨流水线通信机制。您可以使用 Cloud Storage 等持久性存储服务或 App Engine 等内存缓存,在流水线实例之间共享数据。
安排作业
您可以通过以下方式自动执行流水线:
- 使用 Cloud Scheduler。
- 在 Cloud Composer 工作流中使用 Apache Airflow Dataflow 运算符(多种 Google Cloud 运算符中的一种)。
- 在 Compute Engine 上运行自定义 (Cron) 作业流程。
编写流水线代码的最佳做法
以下部分介绍在通过编写 Apache Beam 代码创建流水线时可采取的最佳做法。
设计 Apache Beam 代码的结构
如需创建流水线,通常使用通用 ParDo 并行处理 Apache Beam 转换。应用 ParDo 转换时,您需要以 DoFn 对象的形式提供代码。DoFn 是一个用于定义分布式处理函数的 Apache Beam SDK 类。
您可以将 DoFn 代码视为若干独立的小型实体,也就是说,可能有许多实例在不同机器中运行,且各实例之间对彼此一无所知。因此,我们建议创建纯函数,它们非常适合 DoFn 元素的并行和分布性质。纯函数具有以下特征:
- 纯函数不依赖于隐藏或外部状态。
- 没有明显的副作用。
- 具有确定性。
纯函数模型并不严格。如果您的代码不依赖于 Dataflow 服务无法保证的内容,则状态信息或外部初始化数据可能对 DoFn 和其他函数对象有效。
在设计 ParDo 转换结构并创建 DoFn 元素时,请考虑以下准则:
- 当您使用“正好一次”处理时,Dataflow 服务可确保输入
PCollection中的每一种元素都由DoFn实例处理正好一次。 - Dataflow 服务无法保证
DoFn的调用次数。 - Dataflow 服务无法保证分布式元素的确切分组方式。它无法保证系统会一起处理哪些元素(如果有)。
- Dataflow 服务无法保证流水线执行过程中会创建的
DoFn实例的确切数量。 - Dataflow 服务具有容错功能;如果工作器遇到问题,该服务可能会多次重试您的代码。
- Dataflow 服务可能会创建代码的备份副本。还可能会出现增加人工处理负面影响的问题,例如在您的代码依赖或创建的临时文件使用了重复名称这种情况下。
- Dataflow 服务会按
DoFn实例序列化元素的处理。您的代码不必是严格的线程安全代码,但多个DoFn实例之间共用的任何状态必须是线程安全的。
创建可重复使用的转换库
Apache Beam 编程模型支持您重复使用转换。通过创建常见转换的共享库,您可以提高不同团队具备的可重用性、可测试性和代码所有权。
请考虑以下两个 Java 代码示例,两者都读取付款事件。假设两个流水线执行相同的处理,则它们可以通过共享库将相同的转换用于其余处理步骤。
第一个示例来自无界限 Pub/Sub 来源:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
第二个示例来自有界限关系型数据库来源:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
如何实现代码可重用性最佳做法因编程语言和构建工具而异。例如,如果您使用 Maven,则可以将转换代码拆分到它自己的模块中。然后,您可以将此模块作为子模块添加到更大流水线的多模块项目中,如以下代码示例所示:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
如需了解详情,请参阅以下 Apache Beam 文档页面:
- 编写 Apache Beam 转换用户代码的要求
PTransform风格指南:面向新的可重复使用的PTransform集合的编写者的风格指南
使用死信队列处理错误
有时,您的流水线无法处理元素。数据问题是一种常见原因。例如,包含格式错误的 JSON 的元素可能会导致解析失败。
虽然您可以在 DoFn.ProcessElement 方法中捕获异常、记录错误并删除元素,但这种方法既会丢失数据,又会在后面妨碍数据检查(以进行手动处理或问题排查)。
请改为使用名为“死信队列”(未处理的消息队列)的模式。
您可以在 DoFn.ProcessElement 方法中捕获异常并记录错误。您可以使用分支输出将失败的元素写入单独的 PCollection 对象中,而不是丢弃失败的元素。然后,系统会将这些元素写入数据接收器,以便日后使用单独的转换进行检查和处理。
以下 Java 代码示例展示了如何实现死信队列模式。
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
使用 Cloud Monitoring 为流水线的死信队列应用不同的监控和提醒政策。例如,您可以直观呈现死信转换处理的元素数量和大小,并将提醒配置为在满足特定阈值时触发。
处理架构变更
您可以使用死信模式处理具有意外但有效的架构的数据,并仅将失败的元素写入独立的 PCollection 对象。在某些情况下,您希望自动将反映已更改架构的元素作为有效元素来处理。例如,如果某个元素的架构反映添加新字段等更改,您可以调整数据接收器的架构以适应变更。
自动架构更改依赖于死信模式使用的分支输出方法。不过,在这种情况下,它会触发一个转换,每当添加架构时,都会更改目标架构。如需查看此方法的示例,请参阅 Google Cloud 博客中的如何使用 Square Enix 处理流式流水线中的变更 JSON 架构。
确定如何联接数据集
联接数据集是数据流水线的一个常见用例。 您可以使用辅助输入或 CoGroupByKey 转换在流水线中执行联接操作。每种方案都有其优点和缺点。
辅助输入提供了一种灵活的方式来解决常见的数据处理问题,例如数据丰富和密钥查询。与 PCollection 对象不同,辅助输入是可变的,并且可以在运行时确定。例如,辅助输入中的值可能由流水线中的另一个分支计算,或通过调用远程服务确定。
Dataflow 通过将数据持久保存到永久性存储空间(类似于共享磁盘)中支持辅助输入。这种配置使所有工作器都能够使用完整的辅助输入。
但是,辅助输入的量可能非常大,可能无法放入工作器内存中。如果工作器需要不断从永久性存储空间读取,从大型辅助输入读取可能会导致性能问题。
CoGroupByKey 转换是一种核心 Apache Beam 转换,可合并(展平)多个 PCollection 对象,并对具有公共键的元素进行分组。与可让每个工作器使用整个辅助输入数据的辅助输入不同,CoGroupByKey 会执行重排(分组)操作,以在多个工作器之间分配数据。因此,当要联接的 PCollection 对象非常大且不适合工作器内存时,CoGroupByKey 是理想之选。
请遵循以下准则,以确定是使用辅助输入还是使用 CoGroupByKey:
- 如果您要联接的
PCollection对象比其他的要小得多,而较小的PCollection对象适合工作器内存,则使用辅助输入。将辅助输入完全缓存到内存中后,提取元素的速度和效率会更高。 - 如果您的
PCollection对象必须在流水线中多次联接,请使用辅助输入。您可以创建一个可供多个ParDo转换重复使用的辅助输入,而无需使用多个CoGroupByKey转换。 - 如果您需要提取大量超出工作器内存的
PCollection对象,请使用CoGroupByKey。
如需了解详情,请参阅排查 Dataflow 内存不足错误。
每个元素操作的最大开销
一个 DoFn 实例处理多批名为软件包的元素,即由零个或以上元素组成的工作的原子单元。各个元素随后由 DoFn.ProcessElement 方法处理,该方法会针对每个元素运行。由于 DoFn.ProcessElement 方法是针对每个元素调用的,因此由该方法调用的任何耗时或计算开销大的操作都会针对该方法处理的每个元素运行。
如果您需要对一批元素仅仅执行一次费用高昂的操作,请在 DoFn.Setup 方法或 DoFn.StartBundle 方法(而不是 DoFn.ProcessElement 元素中)中添加这些操作。例如以下操作:
解析用于控制
DoFn实例行为的某些方面的配置文件。仅在初始化DoFn实例时使用DoFn.Setup方法调用此操作一次。实例化在软件包中的所有元素中重复使用的短期客户端,例如,在软件包中的所有元素都通过单个网络连接发送时。使用
DoFn.StartBundle方法为每个软件包调用一次此操作。
限制批次大小和同时调用外部服务
调用外部服务时,您可以使用 GroupIntoBatches 转换来减少每次调用的开销。此转换会创建指定大小的元素批次。批处理将元素作为一个载荷发送到外部服务,而不是单独发送各元素。
结合批处理,通过选择适当的键来对传入数据进行分区,从而限制对外部服务的并行(并发)调用数量上限。分区数量决定了最大并行处理数量。例如,如果为每个元素指定相同的键,则用于调用外部服务的下游转换不会并行运行。
请考虑使用以下某种方法为元素生成密钥:
- 选择数据集属性作为数据密钥(例如用户 ID)。
- 生成数据键,以便按固定数量的分区随机拆分元素,其中可能的键值对数量决定了分区的数量。您需要创建足够的分区来提高并行性。每个分区都需要有足够的元素来支持
GroupIntoBatches转换发挥作用。
以下 Java 代码示例展示了如何随机拆分 10 个分区中的元素:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
找出由融合步骤导致的性能问题
Dataflow 会根据您用于构造流水线的转换和数据,构建一个步骤图来表示您的流水线。此图称为流水线执行图。
部署流水线时,Dataflow 可能会修改流水线的执行图以提高性能。例如,Dataflow 可能会融合一些操作(该流程也称为融合优化),以免在流水线中写入每个中间 PCollection 对象时产生性能和费用影响。
在某些情况下,Dataflow 可能会错误地确定融合流水线中各操作的最佳方式,而使得您的作业无法充分利用所有可用的工作器。在这些情况下,您可以防止操作融合。
请参考以下 Apache Beam 代码示例。GenerateSequence 转换会创建一个小型有界限的 PCollection 对象,然后由两个下游 ParDo 转换进一步处理该对象。
Find Primes Less-than-N 转换的计算开销可能很大,并且对于大量数字来说,运行速度可能会很慢。相比之下,Increment Number 转换可能会快速完成。
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
下图显示了 Dataflow 监控界面中流水线的图形表示。
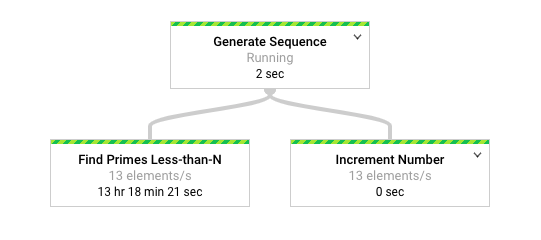
Dataflow 监控界面显示,两个转换的处理速度同样缓慢,特别是每秒 13 个元素。您期望 Increment Number 转换快速处理元素,但它似乎与 Find Primes Less-than-N 的处理速率相同。
原因在于 Dataflow 将这些步骤融合为单个阶段,从而防止它们独立运行。您可以使用 gcloud dataflow jobs describe 命令查找更多信息:
gcloud dataflow jobs describe --full job-id --format json
在生成的输出中,ComponentTransform 数组的 ExecutionStageSummary 对象中说明了融合步骤:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
在这种情况下,由于 Find Primes Less-than-N 转换是缓慢的步骤,因此在该步骤之前分解融合是适当的策略。取消融合步骤的一种方法是插入 GroupByKey 转换并在此步骤之前取消分组,如下面的 Java 代码示例所示。
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
您还可以将这些取消融合的步骤组合成可重复使用的复合转换。
取消融合这些步骤后,当您运行流水线时,Increment Number 只需几秒即可完成,而运行时间长得多的 Find Primes Less-than-N 转换将在单独的阶段运行。
此示例将分组和取消分组操作应用于取消融合步骤。您可以在其他情况下使用其他方法。在这种情况下,给定 GenerateSequence 转换的连续输出时,处理重复输出就不会成为问题。具有重复键的 KV 对象会进行去重,使其变成分组 (GroupByKey) 转换和取消分组 (Keys) 转换中的单个键。如需在分组和取消分组操作后保留重复项,请按照以下步骤创建键值对:
- 使用随机键和原始输入作为值。
- 使用随机键进行分组。
- 发出每个键的值作为输出。
您还可以使用 Reshuffle 转换来防止周围转换的融合。但是,Reshuffle 转换的副作用是无法在不同的 Apache Beam 运行程序之间移植。
如需详细了解并行性和融合优化,请参阅流水线生命周期。
使用 Apache Beam 指标收集流水线数据分析
Apache Beam 指标是一个实用程序类,可生成各种指标,用于报告运行流水线属性。使用 Cloud Monitoring 时,Apache Beam 指标可用作 Cloud Monitoring 自定义指标。
以下示例展示了 DoFn 子类中使用的 Apache Beam Counter 指标。
示例代码使用两个计数器。一个计数器跟踪 JSON 解析失败 (malformedCounter),另一个计数器跟踪 JSON 消息是否有效但包含空载荷 (emptyCounter)。在 Cloud Monitoring 中,自定义指标名称为 custom.googleapis.com/dataflow/malformedJson 和 custom.googleapis.com/dataflow/emptyPayload。您可以使用自定义指标在 Cloud Monitoring 中创建可视化和提醒政策。
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
了解详情
以下页面详细介绍了如何构建流水线、如何选择要应用到数据的转换,以及在选择流水线的输入和输出方法时要考虑的事项。
如需详细了解如何构建您的用户代码,请参阅用户提供的函数的要求。