Dengan menggunakan runner interaktif Apache Beam dengan notebook JupyterLab, Anda dapat mengembangkan pipeline secara iteratif, memeriksa grafik pipeline, dan mengurai setiap PCollection dalam alur kerja read-eval-print-loop (REPL). Untuk tutorial yang menunjukkan cara menggunakan runner interaktif Apache Beam dengan notebook JupyterLab, lihat Mengembangkan dengan notebook Apache Beam.
Halaman ini memberikan detail tentang fitur lanjutan yang dapat Anda gunakan dengan notebook Apache Beam.
FlinkRunner interaktif di cluster yang dikelola notebook
Untuk menggunakan data berukuran produksi secara interaktif dari notebook, Anda dapat menggunakan FlinkRunner dengan beberapa opsi pipeline generik untuk memberi tahu sesi notebook mengelola cluster Dataproc yang tahan lama dan menjalankan pipeline Apache Beam secara terdistribusi.
Prasyarat
Untuk menggunakan fitur ini:
- Mengaktifkan Dataproc API.
- Berikan peran admin atau editor ke akun layanan yang menjalankan instance notebook untuk Dataproc.
- Gunakan kernel notebook dengan Apache Beam SDK versi 2.40.0 atau yang lebih baru.
Konfigurasi
Minimal, Anda memerlukan penyiapan berikut:
# Set a Cloud Storage bucket to cache source recording and PCollections.
# By default, the cache is on the notebook instance itself, but that does not
# apply to the distributed execution scenario.
ib.options.cache_root = 'gs://<BUCKET_NAME>/flink'
# Define an InteractiveRunner that uses the FlinkRunner under the hood.
interactive_flink_runner = InteractiveRunner(underlying_runner=FlinkRunner())
options = PipelineOptions()
# Instruct the notebook that Google Cloud is used to run the FlinkRunner.
cloud_options = options.view_as(GoogleCloudOptions)
cloud_options.project = 'PROJECT_ID'
Penyediaan eksplisit (opsional)
Anda dapat menambahkan opsi berikut.
# Change this if the pipeline needs to run in a different region
# than the default, 'us-central1'. For example, to set it to 'us-west1':
cloud_options.region = 'us-west1'
# Explicitly provision the notebook-managed cluster.
worker_options = options.view_as(WorkerOptions)
# Provision 40 workers to run the pipeline.
worker_options.num_workers=40
# Use the default subnetwork.
worker_options.subnetwork='default'
# Choose the machine type for the workers.
worker_options.machine_type='n1-highmem-8'
# When working with non-official Apache Beam releases, such as Apache Beam built from source
# code, configure the environment to use a compatible released SDK container.
# If needed, build a custom container and use it. For more information, see:
# https://beam.apache.org/documentation/runtime/environments/
options.view_as(PortableOptions).environment_config = 'apache/beam_python3.7_sdk:2.41.0 or LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/your_custom_container'
Penggunaan
# The parallelism is applied to each step, so if your pipeline has 10 steps, you
# end up having 10 * 10 = 100 tasks scheduled, which can be run in parallel.
options.view_as(FlinkRunnerOptions).parallelism = 10
p_word_count = beam.Pipeline(interactive_flink_runner, options=options)
word_counts = (
p_word_count
| 'read' >> ReadWordsFromText('gs://apache-beam-samples/shakespeare/kinglear.txt')
| 'count' >> beam.combiners.Count.PerElement())
# The notebook session automatically starts and manages a cluster to run
# your pipelines with the FlinkRunner.
ib.show(word_counts)
# Interactively adjust the parallelism.
options.view_as(FlinkRunnerOptions).parallelism = 150
# The BigQuery read needs a Cloud Storage bucket as a temporary location.
options.view_as(GoogleCloudOptions).temp_location = ib.options.cache_root
p_bq = beam.Pipeline(runner=interactive_flink_runner, options=options)
delays_by_airline = (
p_bq
| 'Read Dataset from BigQuery' >> beam.io.ReadFromBigQuery(
project=project, use_standard_sql=True,
query=('SELECT airline, arrival_delay '
'FROM `bigquery-samples.airline_ontime_data.flights` '
'WHERE date >= "2010-01-01"'))
| 'Rebalance Data to TM Slots' >> beam.Reshuffle(num_buckets=1000)
| 'Extract Delay Info' >> beam.Map(
lambda e: (e['airline'], e['arrival_delay'] > 0))
| 'Filter Delayed' >> beam.Filter(lambda e: e[1])
| 'Count Delayed Flights Per Airline' >> beam.combiners.Count.PerKey())
# This step reuses the existing cluster.
ib.collect(delays_by_airline)
# Describe the cluster running the pipelines.
# You can access the Flink dashboard from the printed link.
ib.clusters.describe()
# Cleans up all long-lasting clusters managed by the notebook session.
ib.clusters.cleanup(force=True)
Cluster yang dikelola notebook
- Secara default, jika Anda tidak memberikan opsi pipeline apa pun, Interactive
Apache Beam selalu menggunakan kembali cluster yang paling baru digunakan
untuk menjalankan pipeline dengan
FlinkRunner.- Untuk menghindari perilaku ini, misalnya, untuk menjalankan pipeline lain dalam sesi notebook yang sama dengan FlinkRunner yang tidak dihosting oleh notebook, jalankan
ib.clusters.set_default_cluster(None).
- Untuk menghindari perilaku ini, misalnya, untuk menjalankan pipeline lain dalam sesi notebook yang sama dengan FlinkRunner yang tidak dihosting oleh notebook, jalankan
- Saat membuat instance pipeline baru yang menggunakan konfigurasi penyediaan, region, dan project yang dipetakan ke cluster Dataproc yang ada, Dataflow juga menggunakan kembali cluster tersebut, meskipun mungkin tidak menggunakan cluster yang paling baru digunakan.
- Namun, setiap kali perubahan penyediaan diberikan, seperti saat mengubah ukuran
cluster, cluster baru akan dibuat untuk menjalankan perubahan yang diinginkan. Jika Anda ingin mengubah ukuran
cluster, untuk menghindari kehabisan resource cloud, bersihkan cluster yang tidak diperlukan
menggunakan
ib.clusters.cleanup(pipeline). - Saat
master_urlFlink ditentukan, jika termasuk dalam cluster yang dikelola oleh sesi notebook, Dataflow akan menggunakan kembali cluster terkelola.- Jika
master_urltidak diketahui oleh sesi notebook, berartiFlinkRunneryang dihosting sendiri oleh pengguna diinginkan. Notebook tidak melakukan apa pun secara implisit.
- Jika
Pemecahan masalah
Bagian ini memberikan informasi untuk membantu Anda memecahkan masalah dan men-debug FlinkRunner Interaktif di cluster yang dikelola notebook.
Flink IOException: Jumlah buffering jaringan tidak memadai
Untuk memudahkan, konfigurasi buffering jaringan Flink tidak diekspos untuk konfigurasi.
Jika grafik tugas terlalu rumit atau paralelisme ditetapkan terlalu tinggi, kardinalitas langkah yang dikalikan dengan paralelisme mungkin terlalu besar, menyebabkan terlalu banyak tugas dijadwalkan secara paralel, dan gagal dieksekusi.
Gunakan tips berikut untuk meningkatkan kecepatan operasi interaktif:
- Hanya tetapkan
PCollectionyang ingin Anda periksa ke variabel. - Periksa
PCollectionssatu per satu. - Gunakan pengurutan ulang setelah transformasi fanout tinggi.
- Sesuaikan paralelisme berdasarkan ukuran data. Terkadang, lebih kecil lebih cepat.
Perlu waktu terlalu lama untuk memeriksa data
Periksa dasbor Flink untuk tugas yang sedang berjalan. Anda mungkin melihat langkah saat ratusan tugas telah selesai dan hanya satu yang tersisa, karena data yang sedang diproses berada di satu mesin dan tidak diacak.
Selalu gunakan pengurutan ulang setelah transformasi fanout tinggi, seperti saat:
- Membaca baris dari file
- Membaca baris dari tabel BigQuery
Tanpa pengurutan ulang, data fanout selalu dijalankan pada pekerja yang sama, dan Anda tidak dapat memanfaatkan paralelisme.
Berapa banyak pekerja yang saya butuhkan?
Sebagai aturan umum, cluster Flink memiliki jumlah vCPU yang dikalikan dengan jumlah slot pekerja. Misalnya, jika Anda memiliki 40 pekerja n1-highmem-8, cluster Flink memiliki maksimal 320 slot, atau 8 dikalikan dengan 40.
Idealnya, pekerja dapat mengelola tugas yang membaca, memetakan, dan menggabungkan dengan paralelisme yang ditetapkan dalam ratusan, yang menjadwalkan ribuan tugas secara paralel.
Apakah fitur ini berfungsi dengan streaming?
Pipeline streaming saat ini tidak kompatibel dengan fitur cluster yang dikelola notebook pada Flink interaktif.
Beam SQL dan keajaiban beam_sql
Beam SQL memungkinkan Anda
mengkueri PCollections terbatas dan tidak terbatas dengan pernyataan SQL. Jika Anda
bekerja di notebook Apache Beam, Anda dapat menggunakan magic kustom
IPython
beam_sql untuk mempercepat pengembangan pipeline.
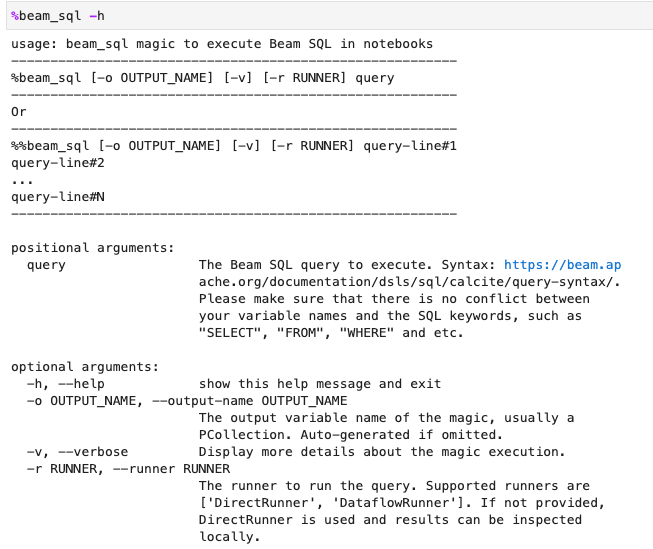
Anda dapat memeriksa penggunaan magic beam_sql dengan opsi -h atau --help:
Anda dapat membuat PCollection dari nilai konstan:

Anda dapat bergabung ke beberapa PCollections:

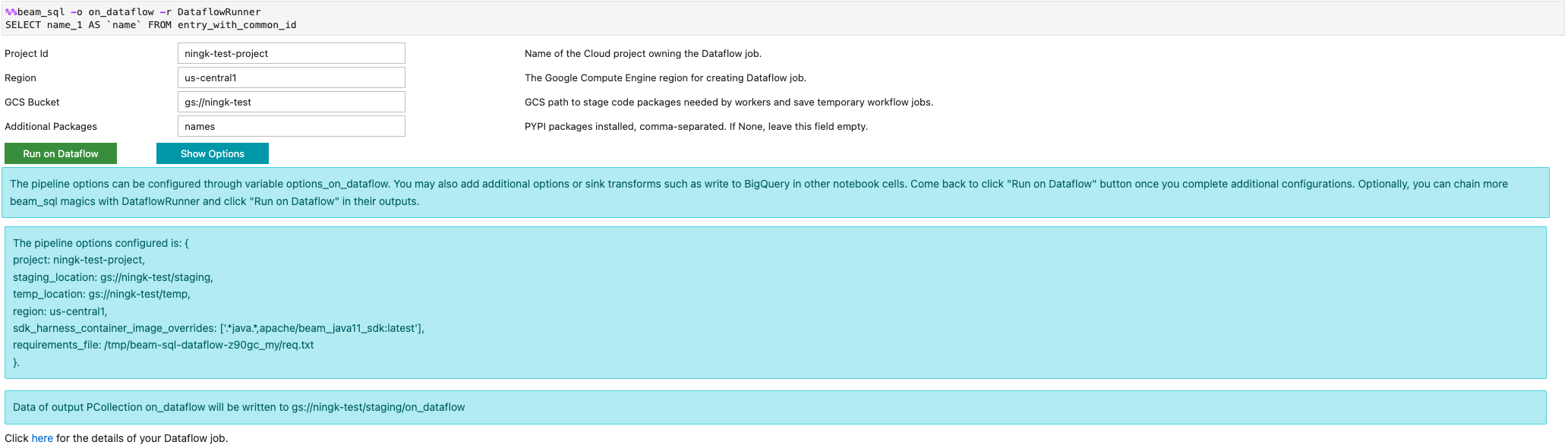
Anda dapat meluncurkan tugas Dataflow dengan opsi -r DataflowRunner atau
--runner DataflowRunner:
Untuk mempelajari lebih lanjut, lihat contoh notebook Apache Beam SQL di notebook.
Mempercepat menggunakan compiler JIT dan GPU
Anda dapat menggunakan library seperti numba dan
GPU untuk mempercepat kode Python dan
pipeline Apache Beam. Di instance notebook Apache Beam yang dibuat dengan
GPU nvidia-tesla-t4, untuk dijalankan di GPU, kompilasi kode Python Anda dengan
numba.cuda.jit. Atau, untuk mempercepat eksekusi di CPU, kompilasi kode
Python Anda menjadi kode mesin dengan numba.jit atau numba.njit.
Contoh berikut membuat DoFn yang diproses di GPU:
class Sampler(beam.DoFn):
def __init__(self, blocks=80, threads_per_block=64):
# Uses only 1 cuda grid with below config.
self.blocks = blocks
self.threads_per_block = threads_per_block
def setup(self):
import numpy as np
# An array on host as the prototype of arrays on GPU to
# hold accumulated sub count of points in the circle.
self.h_acc = np.zeros(
self.threads_per_block * self.blocks, dtype=np.float32)
def process(self, element: Tuple[int, int]):
from numba import cuda
from numba.cuda.random import create_xoroshiro128p_states
from numba.cuda.random import xoroshiro128p_uniform_float32
@cuda.jit
def gpu_monte_carlo_pi_sampler(rng_states, sub_sample_size, acc):
"""Uses GPU to sample random values and accumulates the sub count
of values within a circle of radius 1.
"""
pos = cuda.grid(1)
if pos < acc.shape[0]:
sub_acc = 0
for i in range(sub_sample_size):
x = xoroshiro128p_uniform_float32(rng_states, pos)
y = xoroshiro128p_uniform_float32(rng_states, pos)
if (x * x + y * y) <= 1.0:
sub_acc += 1
acc[pos] = sub_acc
rng_seed, sample_size = element
d_acc = cuda.to_device(self.h_acc)
sample_size_per_thread = sample_size // self.h_acc.shape[0]
rng_states = create_xoroshiro128p_states(self.h_acc.shape[0], seed=rng_seed)
gpu_monte_carlo_pi_sampler[self.blocks, self.threads_per_block](
rng_states, sample_size_per_thread, d_acc)
yield d_acc.copy_to_host()
Gambar berikut menunjukkan notebook yang berjalan di GPU:
Detail selengkapnya dapat ditemukan di contoh notebook Menggunakan GPU dengan Apache Beam.
Membuat container kustom
Pada umumnya, jika pipeline Anda tidak memerlukan dependensi atau file yang dapat dieksekusi Python tambahan, Apache Beam dapat otomatis menggunakan image penampung resminya untuk menjalankan kode yang ditentukan pengguna. Image ini dilengkapi dengan banyak modul Python umum, dan Anda tidak perlu mem-build atau menentukannya secara eksplisit.
Dalam beberapa kasus, Anda mungkin memiliki dependensi Python tambahan atau bahkan dependensi non-Python. Dalam skenario ini, Anda dapat mem-build penampung kustom dan menyediakannya untuk dijalankan oleh cluster Flink. Daftar berikut memberikan keuntungan menggunakan penampung kustom:
- Waktu penyiapan yang lebih cepat untuk eksekusi berturut-turut dan interaktif
- Konfigurasi dan dependensi yang stabil
- Fleksibilitas lebih besar: Anda dapat menyiapkan lebih dari dependensi Python
Proses build penampung mungkin merepotkan, tetapi Anda dapat melakukan semuanya di notebook menggunakan pola penggunaan berikut.
Membuat ruang kerja lokal
Pertama, buat direktori kerja lokal di direktori beranda Jupyter.
!mkdir -p /home/jupyter/.flink
Menyiapkan dependensi Python
Selanjutnya, instal semua dependensi Python tambahan yang mungkin Anda gunakan, dan ekspor ke dalam file persyaratan.
%pip install dep_a
%pip install dep_b
...
Anda dapat membuat file persyaratan secara eksplisit menggunakan magic notebook
%%writefile.
%%writefile /home/jupyter/.flink/requirements.txt
dep_a
dep_b
...
Atau, Anda dapat membekukan semua dependensi lokal ke dalam file persyaratan. Opsi ini dapat menyebabkan dependensi yang tidak diinginkan.
%pip freeze > /home/jupyter/.flink/requirements.txt
Menyiapkan dependensi non-Python
Salin semua dependensi non-Python ke ruang kerja. Jika Anda tidak memiliki dependensi non-Python, lewati langkah ini.
!cp /path/to/your-dep /home/jupyter/.flink/your-dep
...
Membuat Dockerfile
Buat Dockerfile dengan magic notebook %%writefile. Contoh:
%%writefile /home/jupyter/.flink/Dockerfile
FROM apache/beam_python3.7_sdk:2.40.0
COPY requirements.txt /tmp/requirements.txt
COPY your_dep /tmp/your_dep
...
RUN python -m pip install -r /tmp/requirements.txt
Contoh penampung menggunakan image Apache Beam SDK versi 2.40.0
dengan Python 3.7 sebagai dasar,
menambahkan file your_dep, dan menginstal dependensi Python tambahan.
Gunakan Dockerfile ini sebagai template, dan edit untuk kasus penggunaan Anda.
Dalam pipeline Apache Beam, saat merujuk ke dependensi non-Python, gunakan tujuan COPY-nya. Misalnya, /tmp/your_dep adalah jalur file dari file your_dep.
Mem-build image container di Artifact Registry menggunakan Cloud Build
Aktifkan layanan Cloud Build dan Artifact Registry, jika belum diaktifkan.
!gcloud services enable cloudbuild.googleapis.com !gcloud services enable artifactregistry.googleapis.comBuat repositori Artifact Registry agar Anda dapat mengupload artefak. Setiap repositori dapat berisi artefak untuk satu format yang didukung.
Semua konten repositori dienkripsi menggunakan Google-owned and Google-managed encryption keys atau kunci enkripsi yang dikelola pelanggan. Artifact Registry menggunakan Google-owned and Google-managed encryption keys secara default dan tidak diperlukan konfigurasi untuk opsi ini.
Anda harus memiliki setidaknya akses Artifact Registry Writer ke repositori.
Jalankan perintah berikut untuk membuat repositori baru. Perintah ini menggunakan flag
--asyncdan segera ditampilkan, tanpa menunggu operasi yang sedang berlangsung selesai.gcloud artifacts repositories create REPOSITORY \ --repository-format=docker \ --location=LOCATION \ --asyncGanti nilai berikut:
- REPOSITORY: nama untuk repositori Anda. Untuk setiap lokasi repositori dalam project, nama repositori harus unik.
- LOCATION: lokasi untuk repositori Anda.
Sebelum Anda dapat mengirim atau mengambil image, konfigurasikan Docker untuk mengautentikasi permintaan untuk Artifact Registry. Untuk menyiapkan autentikasi ke repositori Docker, jalankan perintah berikut:
gcloud auth configure-docker LOCATION-docker.pkg.devPerintah ini memperbarui konfigurasi Docker Anda. Sekarang Anda dapat terhubung dengan Artifact Registry di project Google Cloud untuk mengirim image.
Gunakan Cloud Build untuk mem-build image container, dan simpan ke Artifact Registry.
!cd /home/jupyter/.flink \ && gcloud builds submit \ --tag LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/flink:latest \ --timeout=20mGanti
PROJECT_IDdengan project ID project Anda.
Menggunakan container kustom
Bergantung pada runner, Anda dapat menggunakan penampung kustom untuk berbagai tujuan.
Untuk penggunaan penampung Apache Beam umum, lihat:
Untuk penggunaan penampung Dataflow, lihat:
Menonaktifkan alamat IP eksternal
Saat membuat instance notebook Apache Beam, untuk meningkatkan keamanan, nonaktifkan alamat IP eksternal. Karena instance notebook perlu mendownload beberapa resource internet publik, seperti Artifact Registry, Anda harus membuat jaringan VPC baru tanpa alamat IP eksternal terlebih dahulu. Kemudian, buat gateway Cloud NAT untuk jaringan VPC ini. Untuk mengetahui informasi selengkapnya tentang Cloud NAT, lihat dokumentasi Cloud NAT. Gunakan jaringan VPC dan gateway Cloud NAT untuk mengakses resource internet publik yang diperlukan tanpa mengaktifkan alamat IP eksternal.