借助 Apache Beam 交互式运行程序和 JruyterLab 笔记本,您可以迭代地开发流水线、检查流水线图,并在“读取-求值-输出”循环 (REPL) 工作流中解析独立的 PCollection。如需查看演示如何将 Apache Beam 交互式运行程序与 JupyterLab 笔记本搭配使用的教程,请参阅使用 Apache Beam 笔记本进行开发。
本页详细介绍了可与 Apache Beam Notebook 搭配使用的高级功能。
笔记本管理的集群上的交互式 FlinkRunner
如需从笔记本以交互方式处理生产规模的数据,您可以将 FlinkRunner 与一些通用流水线选项搭配使用,以指示笔记本会话管理长期有效的 Dataproc 集群并以分布式方式运行 Apache Beam 流水线。
前提条件
要使用此功能,需要满足以下前提条件:
- 启用 Dataproc API。
- 为运行笔记本实例的服务账号授予 Dataproc 的管理员或编辑者角色。
- 使用具有 Apache Beam SDK 2.40.0 版或更高版本的笔记本内核。
配置
您至少需要进行以下设置:
# Set a Cloud Storage bucket to cache source recording and PCollections.
# By default, the cache is on the notebook instance itself, but that does not
# apply to the distributed execution scenario.
ib.options.cache_root = 'gs://<BUCKET_NAME>/flink'
# Define an InteractiveRunner that uses the FlinkRunner under the hood.
interactive_flink_runner = InteractiveRunner(underlying_runner=FlinkRunner())
options = PipelineOptions()
# Instruct the notebook that Google Cloud is used to run the FlinkRunner.
cloud_options = options.view_as(GoogleCloudOptions)
cloud_options.project = 'PROJECT_ID'
显式预配(可选)
您可以添加以下选项。
# Change this if the pipeline needs to run in a different region
# than the default, 'us-central1'. For example, to set it to 'us-west1':
cloud_options.region = 'us-west1'
# Explicitly provision the notebook-managed cluster.
worker_options = options.view_as(WorkerOptions)
# Provision 40 workers to run the pipeline.
worker_options.num_workers=40
# Use the default subnetwork.
worker_options.subnetwork='default'
# Choose the machine type for the workers.
worker_options.machine_type='n1-highmem-8'
# When working with non-official Apache Beam releases, such as Apache Beam built from source
# code, configure the environment to use a compatible released SDK container.
# If needed, build a custom container and use it. For more information, see:
# https://beam.apache.org/documentation/runtime/environments/
options.view_as(PortableOptions).environment_config = 'apache/beam_python3.7_sdk:2.41.0 or LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/your_custom_container'
用量
# The parallelism is applied to each step, so if your pipeline has 10 steps, you
# end up having 10 * 10 = 100 tasks scheduled, which can be run in parallel.
options.view_as(FlinkRunnerOptions).parallelism = 10
p_word_count = beam.Pipeline(interactive_flink_runner, options=options)
word_counts = (
p_word_count
| 'read' >> ReadWordsFromText('gs://apache-beam-samples/shakespeare/kinglear.txt')
| 'count' >> beam.combiners.Count.PerElement())
# The notebook session automatically starts and manages a cluster to run
# your pipelines with the FlinkRunner.
ib.show(word_counts)
# Interactively adjust the parallelism.
options.view_as(FlinkRunnerOptions).parallelism = 150
# The BigQuery read needs a Cloud Storage bucket as a temporary location.
options.view_as(GoogleCloudOptions).temp_location = ib.options.cache_root
p_bq = beam.Pipeline(runner=interactive_flink_runner, options=options)
delays_by_airline = (
p_bq
| 'Read Dataset from BigQuery' >> beam.io.ReadFromBigQuery(
project=project, use_standard_sql=True,
query=('SELECT airline, arrival_delay '
'FROM `bigquery-samples.airline_ontime_data.flights` '
'WHERE date >= "2010-01-01"'))
| 'Rebalance Data to TM Slots' >> beam.Reshuffle(num_buckets=1000)
| 'Extract Delay Info' >> beam.Map(
lambda e: (e['airline'], e['arrival_delay'] > 0))
| 'Filter Delayed' >> beam.Filter(lambda e: e[1])
| 'Count Delayed Flights Per Airline' >> beam.combiners.Count.PerKey())
# This step reuses the existing cluster.
ib.collect(delays_by_airline)
# Describe the cluster running the pipelines.
# You can access the Flink dashboard from the printed link.
ib.clusters.describe()
# Cleans up all long-lasting clusters managed by the notebook session.
ib.clusters.cleanup(force=True)
笔记本管理的集群
- 默认情况下,如果您不提供任何流水线选项,则交互式 Apache Beam 将始终重复使用最近使用的集群来通过
FlinkRunner运行流水线。- 为避免此行为(例如,使用未由笔记本托管的 FlinkRunner 在同一笔记本会话中运行其他流水线),请运行
ib.clusters.set_default_cluster(None)。
- 为避免此行为(例如,使用未由笔记本托管的 FlinkRunner 在同一笔记本会话中运行其他流水线),请运行
- 实例化使用映射到现有 Dataproc 集群的项目、区域和预配配置的新流水线时,Dataflow 也会重复使用该集群,但可能不会使用最近用过的集群。
- 但是,每当进行预配更改时(例如调整集群大小时),系统都会创建一个新集群来使所需的更改生效。如果您打算调整集群大小,请使用
ib.clusters.cleanup(pipeline)清理不必要的集群,以避免耗尽云资源。 - 指定 Flink
master_url时,如果它属于由笔记本会话管理的集群,则 Dataflow 会重复使用该集群。- 如果
master_url对于笔记本会话是未知的,则表示需要用户自托管的FlinkRunner。笔记本不会隐式执行任何操作。
- 如果
问题排查
本部分提供的信息可帮助您排查和调试笔记本管理的集群上的交互式 FlinkRunner 问题。
Flink IOException:网络缓冲区数量不足
为简单起见,Flink 网络缓冲区配置未公开。
如果您的作业图过于复杂或您的并行性设置得过高,则步骤的基数乘以并行数可能会太大,从而导致并行安排太多任务以及无法执行。
您可以参考以下提示来提高交互式运行的速度:
- 仅将要检查的
PCollection分配给变量。 - 逐一检查
PCollections。 - 在高扇出转换后使用重排。
- 根据数据大小调整并行性。有时,数据越小,速度越快。
检查数据所需的时间太长
检查 Flink 信息中心是否有正在运行的作业。您可能会看到一个步骤,其中数百个任务已完成,并且只有一个任务仍在运行,因为运行中数据位于单台机器上,并且不会重排。
始终在高扇出转换后使用重排,例如:
- 从文件中读取行
- 从 BigQuery 表中读取行
如果没有重排,扇出数据将始终在同一工作器上运行,并且您无法利用并行性。
我需要多少个工作器?
根据经验,Flink 集群的 vCPU 数量约为工作器槽数量的倍数。例如,如果您有 40 个 n1-highmem-8 工作器,则 Flink 集群最多有 320(8 乘以 40)个槽。
理想情况下,工作器可以管理一个作业,该作业以数百的并行性读取、映射和合并,并并行调度数千个任务。
是否支持流式传输?
流处理流水线目前与笔记本管理的集群上的交互式 Flink 功能不兼容。
Beam SQL 和 beam_sql 魔法命令
Beam SQL 允许您使用 SQL 语句查询有界限和无界限 PCollections。如果您在使用 Apache Beam 笔记本,则可以使用 IPython 自定义魔法命令
beam_sql 来加速流水线开发。
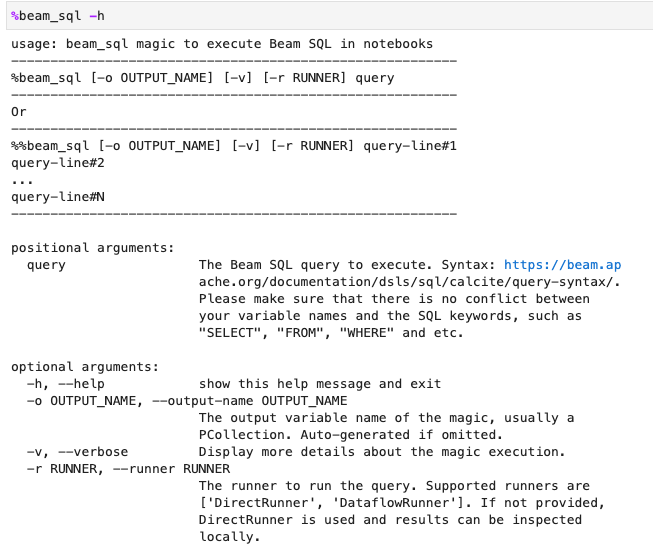
您可以使用 -h 或 --help 选项检查 beam_sql 魔法命令用法:
您可以根据常量值创建 PCollection:

您可以联接多个 PCollections:

您可以使用 -r DataflowRunner 或 --runner DataflowRunner 选项启动 Dataflow 作业:
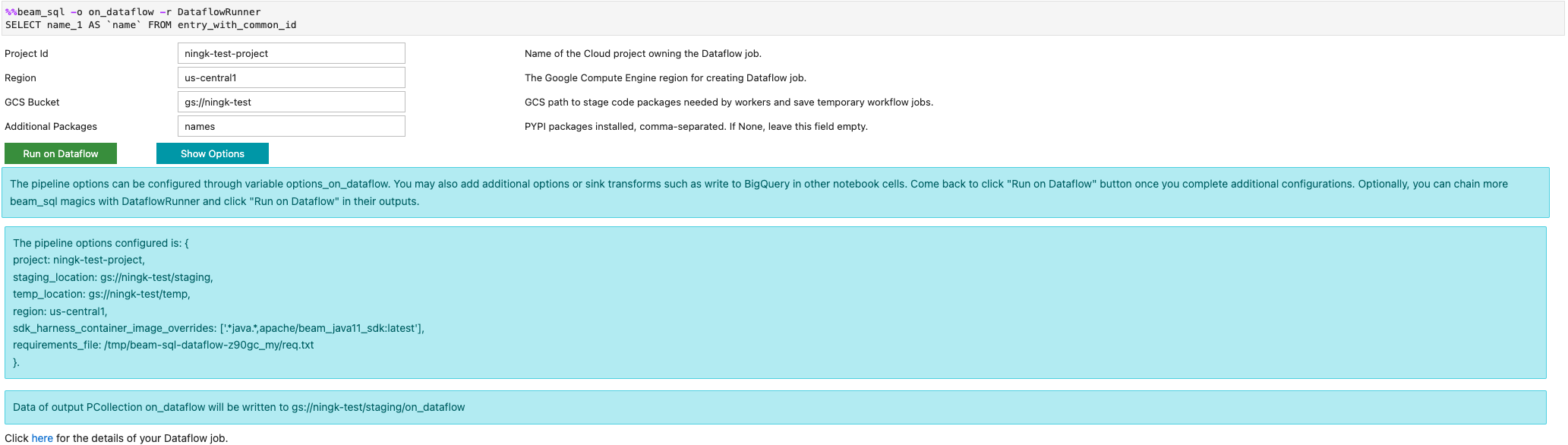
如需了解详情,请参阅笔记本中的示例笔记本 Apache Beam SQL。
使用 JIT 编译器和 GPU 加快速度
您可以使用 numba 和 GPU 等库来加速 Python 代码和 Apache Beam 流水线。在使用 nvidia-tesla-t4 GPU 创建的 Apache Beam 笔记本实例中,如需在 GPU 上运行,请使用 numba.cuda.jit 编译 Python 代码。(可选)如需加快在 CPU 上的执行速度,请使用 numba.jit 或 numba.njit 将 Python 代码编译为机器代码。
以下示例创建了一个在 GPU 上处理的 DoFn:
class Sampler(beam.DoFn):
def __init__(self, blocks=80, threads_per_block=64):
# Uses only 1 cuda grid with below config.
self.blocks = blocks
self.threads_per_block = threads_per_block
def setup(self):
import numpy as np
# An array on host as the prototype of arrays on GPU to
# hold accumulated sub count of points in the circle.
self.h_acc = np.zeros(
self.threads_per_block * self.blocks, dtype=np.float32)
def process(self, element: Tuple[int, int]):
from numba import cuda
from numba.cuda.random import create_xoroshiro128p_states
from numba.cuda.random import xoroshiro128p_uniform_float32
@cuda.jit
def gpu_monte_carlo_pi_sampler(rng_states, sub_sample_size, acc):
"""Uses GPU to sample random values and accumulates the sub count
of values within a circle of radius 1.
"""
pos = cuda.grid(1)
if pos < acc.shape[0]:
sub_acc = 0
for i in range(sub_sample_size):
x = xoroshiro128p_uniform_float32(rng_states, pos)
y = xoroshiro128p_uniform_float32(rng_states, pos)
if (x * x + y * y) <= 1.0:
sub_acc += 1
acc[pos] = sub_acc
rng_seed, sample_size = element
d_acc = cuda.to_device(self.h_acc)
sample_size_per_thread = sample_size // self.h_acc.shape[0]
rng_states = create_xoroshiro128p_states(self.h_acc.shape[0], seed=rng_seed)
gpu_monte_carlo_pi_sampler[self.blocks, self.threads_per_block](
rng_states, sample_size_per_thread, d_acc)
yield d_acc.copy_to_host()
下图展示了在 GPU 上运行的笔记本:
如需了解详情,请参阅将 GPU 与 Apache Beam 搭配使用示例笔记本。
构建自定义容器
在大多数情况下,如果您的流水线不需要额外的 Python 依赖项或可执行文件,Apache Beam 可以自动使用其官方容器映像来运行用户定义的代码。这些映像附带许多常用的 Python 模块,您无需构建或明确指定这些模块。
在某些情况下,您可能具有额外的 Python 依赖项(甚至非 Python 依赖项)。在这些情况下,您可以构建自定义容器,并使其可供 Flink 集群运行。以下列表列出了使用自定义容器的优势:
- 加快持续执行和交互式执行的设置速度
- 稳定配置和依赖项
- 更灵活:您可以设置 Python 依赖项以外的其他依赖项
容器构建流程可能非常繁琐,但您可以按照以下使用模式在笔记本中执行所有操作。
创建本地工作区
首先,在 Jupyter 主目录下创建一个本地工作目录。
!mkdir -p /home/jupyter/.flink
准备 Python 依赖项
接下来,安装您可能会使用的所有额外的 Python 依赖项,并将它们导出到需求文件中。
%pip install dep_a
%pip install dep_b
...
您可以使用 %%writefile notebook magic 显式创建 requirements 文件。
%%writefile /home/jupyter/.flink/requirements.txt
dep_a
dep_b
...
或者,您也可以将所有本地依赖项冻结到 requirements 文件中。 此选项可能会引入意外的依赖项。
%pip freeze > /home/jupyter/.flink/requirements.txt
准备非 Python 依赖项
将所有非 Python 依赖项复制到工作区。如果您没有任何非 Python 依赖项,请跳过此步骤。
!cp /path/to/your-dep /home/jupyter/.flink/your-dep
...
创建 Dockerfile
使用 %%writefile notebook magic 创建 Dockerfile。例如:
%%writefile /home/jupyter/.flink/Dockerfile
FROM apache/beam_python3.7_sdk:2.40.0
COPY requirements.txt /tmp/requirements.txt
COPY your_dep /tmp/your_dep
...
RUN python -m pip install -r /tmp/requirements.txt
示例容器使用 Apache Beam SDK 2.40.0 版的映像(以 Python 3.7 为基础),添加 your_dep 文件,并安装额外的 Python 依赖项。使用此 Dockerfile 作为模板,并根据您的使用情形对其进行修改。
在 Apache Beam 流水线中,引用非 Python 依赖项时,请使用其 COPY 目标。例如,/tmp/your_dep 是 your_dep 文件的路径。
使用 Cloud Build 在 Artifact Registry 中构建容器映像
启用 Cloud Build 和 Artifact Registry 服务(如果尚未启用)。
!gcloud services enable cloudbuild.googleapis.com !gcloud services enable artifactregistry.googleapis.com创建 Artifact Registry 制品库,以便上传制品。每个代码库可以包含一种受支持格式的工件。
所有制品库内容都已使用 Google-owned and Google-managed encryption keys 或客户管理的加密密钥进行加密。Artifact Registry 默认使用Google-owned and Google-managed encryption keys ,此选项无需进行任何配置。
您必须至少具有代码库的 Artifact Registry Writer 权限。
运行以下命令创建新代码库。该命令使用
--async标志并立即返回,无需等待正在进行的操作完成。gcloud artifacts repositories create REPOSITORY \ --repository-format=docker \ --location=LOCATION \ --async替换以下值:
- REPOSITORY:代码库的名称。对于项目中的每个代码库位置,代码库名称不得重复。
- LOCATION:代码库的位置。
请先配置 Docker 以对 Artifact Registry 的请求进行身份验证,然后再推送或拉取映像。如需为 Docker 代码库设置身份验证,请运行以下命令:
gcloud auth configure-docker LOCATION-docker.pkg.dev该命令将更新您的 Docker 配置。现在,您可以在 Google Cloud 项目中与 Artifact Registry 连接以推送映像。
使用 Cloud Build 构建容器映像,并将其保存到 Artifact Registry。
!cd /home/jupyter/.flink \ && gcloud builds submit \ --tag LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/flink:latest \ --timeout=20m将
PROJECT_ID替换为项目的项目 ID。
使用自定义容器
根据运行器的不同,您可以使用自定义容器实现不同的目的。
如需了解 Apache Beam 容器的一般用法,请参阅:
如需了解 Dataflow 容器的使用情况,请参阅:
停用外部 IP 地址
创建 Apache Beam 笔记本实例时,为了提高安全性,请停用外部 IP 地址。由于笔记本实例需要下载一些公共互联网资源(例如 Artifact Registry),因此您需要先创建一个没有外部 IP 地址的新 VPC 网络。然后,为此 VPC 网络创建 Cloud NAT 网关。如需详细了解 Cloud NAT,请参阅 Cloud NAT 文档。 使用 VPC 网络和 Cloud NAT 网关访问必要的公共互联网资源,而无需启用外部 IP 地址。