L'utilizzo del runner interattivo Apache Beam con i notebook JupyterLab ti consente di sviluppare le pipeline in modo iterativo, ispezionare il grafico della pipeline e analizzare le singole PCollection in un flusso di lavoro Read–Eval–Print Loop (REPL). Per un tutorial che mostra come utilizzare il runner interattivo Apache Beam con i notebook JupyterLab, consulta Sviluppare con i notebook Apache Beam.
Questa pagina fornisce dettagli sulle funzionalità avanzate che puoi utilizzare con il tuo notebook Apache Beam.
FlinkRunner interattivo su cluster gestiti da notebook
Per lavorare in modo interattivo con dati di produzione dal notebook, puoi utilizzare FlinkRunner con alcune opzioni di pipeline generiche per indicare alla sessione del notebook di gestire un cluster Dataproc permanente ed eseguire le pipeline Apache Beam in modo distribuito.
Prerequisiti
Per utilizzare questa funzionalità:
- Abilitare l'API Dataproc.
- Concedi un ruolo di amministratore o editor all'account di servizio che esegue l'istanza del notebook per Dataproc.
- Utilizza un kernel del notebook con la versione 2.40.0 o successiva dell'SDK Apache Beam.
Configurazione
Come minimo, devi avere la seguente configurazione:
# Set a Cloud Storage bucket to cache source recording and PCollections.
# By default, the cache is on the notebook instance itself, but that does not
# apply to the distributed execution scenario.
ib.options.cache_root = 'gs://<BUCKET_NAME>/flink'
# Define an InteractiveRunner that uses the FlinkRunner under the hood.
interactive_flink_runner = InteractiveRunner(underlying_runner=FlinkRunner())
options = PipelineOptions()
# Instruct the notebook that Google Cloud is used to run the FlinkRunner.
cloud_options = options.view_as(GoogleCloudOptions)
cloud_options.project = 'PROJECT_ID'
Disposizione esplicita (facoltativa)
Puoi aggiungere le seguenti opzioni.
# Change this if the pipeline needs to run in a different region
# than the default, 'us-central1'. For example, to set it to 'us-west1':
cloud_options.region = 'us-west1'
# Explicitly provision the notebook-managed cluster.
worker_options = options.view_as(WorkerOptions)
# Provision 40 workers to run the pipeline.
worker_options.num_workers=40
# Use the default subnetwork.
worker_options.subnetwork='default'
# Choose the machine type for the workers.
worker_options.machine_type='n1-highmem-8'
# When working with non-official Apache Beam releases, such as Apache Beam built from source
# code, configure the environment to use a compatible released SDK container.
# If needed, build a custom container and use it. For more information, see:
# https://beam.apache.org/documentation/runtime/environments/
options.view_as(PortableOptions).environment_config = 'apache/beam_python3.7_sdk:2.41.0 or LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/your_custom_container'
Utilizzo
# The parallelism is applied to each step, so if your pipeline has 10 steps, you
# end up having 10 * 10 = 100 tasks scheduled, which can be run in parallel.
options.view_as(FlinkRunnerOptions).parallelism = 10
p_word_count = beam.Pipeline(interactive_flink_runner, options=options)
word_counts = (
p_word_count
| 'read' >> ReadWordsFromText('gs://apache-beam-samples/shakespeare/kinglear.txt')
| 'count' >> beam.combiners.Count.PerElement())
# The notebook session automatically starts and manages a cluster to run
# your pipelines with the FlinkRunner.
ib.show(word_counts)
# Interactively adjust the parallelism.
options.view_as(FlinkRunnerOptions).parallelism = 150
# The BigQuery read needs a Cloud Storage bucket as a temporary location.
options.view_as(GoogleCloudOptions).temp_location = ib.options.cache_root
p_bq = beam.Pipeline(runner=interactive_flink_runner, options=options)
delays_by_airline = (
p_bq
| 'Read Dataset from BigQuery' >> beam.io.ReadFromBigQuery(
project=project, use_standard_sql=True,
query=('SELECT airline, arrival_delay '
'FROM `bigquery-samples.airline_ontime_data.flights` '
'WHERE date >= "2010-01-01"'))
| 'Rebalance Data to TM Slots' >> beam.Reshuffle(num_buckets=1000)
| 'Extract Delay Info' >> beam.Map(
lambda e: (e['airline'], e['arrival_delay'] > 0))
| 'Filter Delayed' >> beam.Filter(lambda e: e[1])
| 'Count Delayed Flights Per Airline' >> beam.combiners.Count.PerKey())
# This step reuses the existing cluster.
ib.collect(delays_by_airline)
# Describe the cluster running the pipelines.
# You can access the Flink dashboard from the printed link.
ib.clusters.describe()
# Cleans up all long-lasting clusters managed by the notebook session.
ib.clusters.cleanup(force=True)
Cluster gestiti da Notebook
- Per impostazione predefinita, se non fornisci opzioni di pipeline, Apache Beam Interactive riutilizza sempre il cluster utilizzato più di recente per eseguire una pipeline con
FlinkRunner.- Per evitare questo comportamento, ad esempio per eseguire un'altra pipeline nella stessa
sessione del notebook con un FlinkRunner non ospitato dal notebook, esegui
ib.clusters.set_default_cluster(None).
- Per evitare questo comportamento, ad esempio per eseguire un'altra pipeline nella stessa
sessione del notebook con un FlinkRunner non ospitato dal notebook, esegui
- Quando viene creata un'istanza di una nuova pipeline che utilizza un progetto, una regione e una configurazione di provisioning che mappano a un cluster Dataproc esistente, anche Dataflow riutilizza il cluster, anche se potrebbe non utilizzare il cluster utilizzato più di recente.
- Tuttavia, ogni volta che viene apportata una modifica al provisioning, ad esempio quando viene modificato il ridimensionamento di un cluster, viene creato un nuovo cluster per applicare la modifica desiderata. Se intendi ridimensionare un cluster, per evitare di esaurire le risorse cloud, elimina i cluster non necessari utilizzando
ib.clusters.cleanup(pipeline). - Quando viene specificato un
master_urlFlink, se appartiene a un cluster gestito dalla sessione del notebook, Dataflow riutilizza il cluster gestito.- Se
master_urlè sconosciuto alla sessione del notebook, significa che è necessario unFlinkRunnerospitato dall'utente. Il notebook non fa nulla implicitamente.
- Se
Risoluzione dei problemi
Questa sezione fornisce informazioni utili per la risoluzione dei problemi e il debug di FlinkRunner interattivo sui cluster gestiti da notebook.
Flink IOException: numero insufficiente di buffer di rete
Per semplicità, la configurazione del buffer di rete di Flink non è esposta per la configurazione.
Se il grafico del job è troppo complicato o il parallelismo è impostato su un valore troppo alto, la cardinalità dei passaggi moltiplicata per il parallelismo potrebbe essere troppo grande, causare la pianificazione di troppe attività in parallelo e causare l'errore di esecuzione.
Utilizza i seguenti suggerimenti per migliorare la velocità delle esecuzioni interattive:
- Assegna a una variabile solo il
PCollectionche vuoi ispezionare. - Controlla
PCollectionsuno alla volta. - Utilizza il rimescolamento dopo le trasformazioni con un fanout elevato.
- Modifica il parallelismo in base alle dimensioni dei dati. A volte, più piccolo è più veloce.
L'ispezione dei dati richiede troppo tempo
Controlla la dashboard di Flink per il job in esecuzione. Potresti visualizzare un passaggio in cui sono state completate centinaia di attività e ne rimane solo una, perché i dati in transito risiedono su una singola macchina e non vengono rimescolati.
Utilizza sempre il rimescolamento dopo una trasformazione con un fanout elevato, ad esempio quando:
- Lettura delle righe da un file
- Lettura delle righe da una tabella BigQuery
Senza il rimescolamento, i dati di fanout vengono sempre eseguiti sullo stesso worker e non puoi sfruttare il parallelismo.
Di quanti lavoratori ho bisogno?
Come regola generale, il cluster Flink ha circa il numero di vCPU moltiplicato per il numero di slot worker. Ad esempio, se hai 40 worker n1-highmem-8, il cluster Flink ha al massimo 320 slot, ovvero 8 moltiplicati per 40.
Idealmente, il worker può gestire un job che legge, mappa e combina con un parallelismo impostato su centinaia, che pianifica migliaia di attività in parallelo.
Funziona con lo streaming?
Al momento, le pipeline di streaming non sono compatibili con la funzionalità Flink interattivo su cluster gestito da notebook.
Beam SQL e la magia di beam_sql
Beam SQL ti consente di eseguire query su PCollections con limiti e senza limiti con istruzioni SQL. Se stai lavorando in un notebook Apache Beam, puoi utilizzare il comando IPython
magic personalizzato
beam_sql per velocizzare lo sviluppo della pipeline.
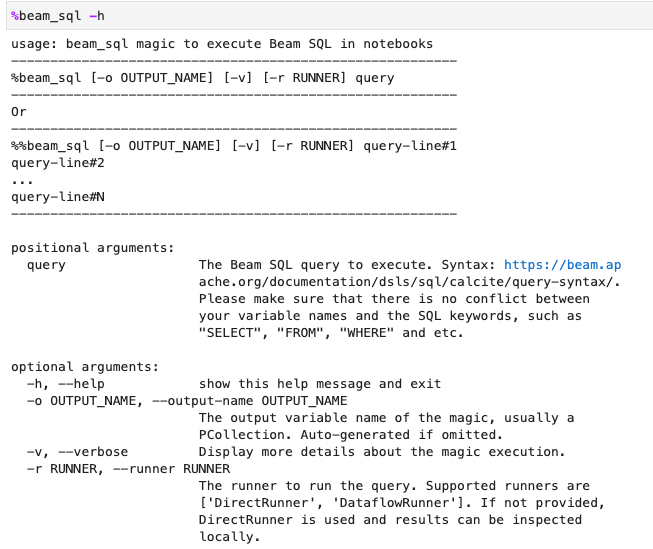
Puoi controllare l'utilizzo della magia beam_sql con l'opzione -h o --help:
Puoi creare un PCollection da valori costanti:

Puoi partecipare a più PCollections:

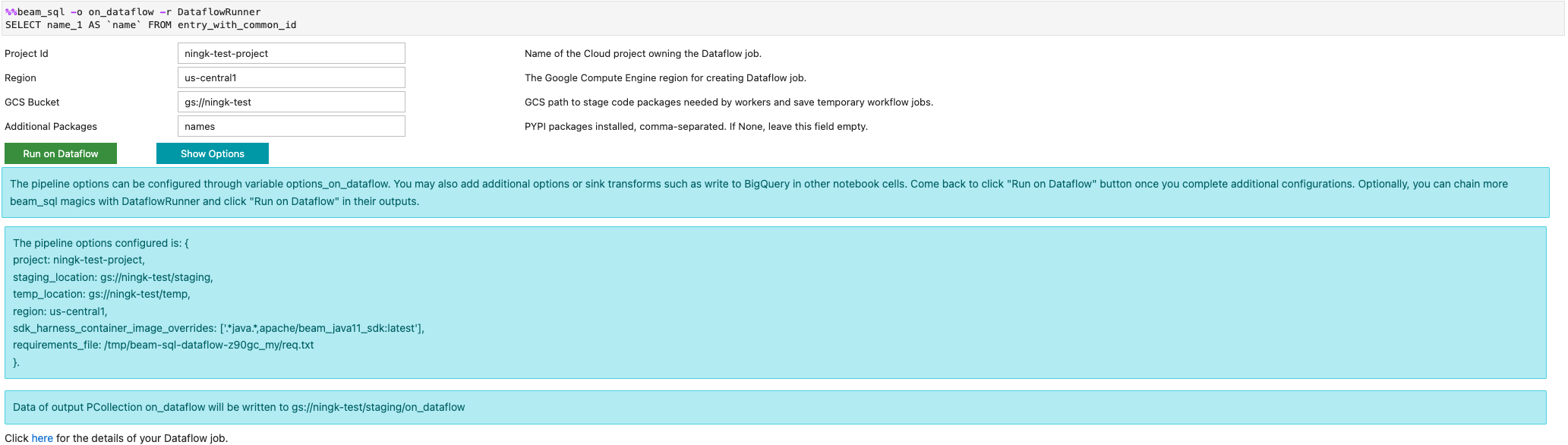
Puoi avviare un job Dataflow con l'opzione -r DataflowRunner o
--runner DataflowRunner:
Per saperne di più, consulta il notebook di esempio Apache Beam SQL nei notebook.
Accelerare l'utilizzo del compilatore JIT e della GPU
Puoi utilizzare librerie come numba e
GPU per accelerare il codice Python e
le pipeline Apache Beam. Nell'istanza del notebook Apache Beam creata con una GPU nvidia-tesla-t4, per l'esecuzione su GPU, compila il codice Python con numba.cuda.jit. Se vuoi, per velocizzare l'esecuzione sulle CPU, compila il codice Python in codice macchina con numba.jit o numba.njit.
L'esempio seguente crea un DoFn che viene elaborato sulle GPU:
class Sampler(beam.DoFn):
def __init__(self, blocks=80, threads_per_block=64):
# Uses only 1 cuda grid with below config.
self.blocks = blocks
self.threads_per_block = threads_per_block
def setup(self):
import numpy as np
# An array on host as the prototype of arrays on GPU to
# hold accumulated sub count of points in the circle.
self.h_acc = np.zeros(
self.threads_per_block * self.blocks, dtype=np.float32)
def process(self, element: Tuple[int, int]):
from numba import cuda
from numba.cuda.random import create_xoroshiro128p_states
from numba.cuda.random import xoroshiro128p_uniform_float32
@cuda.jit
def gpu_monte_carlo_pi_sampler(rng_states, sub_sample_size, acc):
"""Uses GPU to sample random values and accumulates the sub count
of values within a circle of radius 1.
"""
pos = cuda.grid(1)
if pos < acc.shape[0]:
sub_acc = 0
for i in range(sub_sample_size):
x = xoroshiro128p_uniform_float32(rng_states, pos)
y = xoroshiro128p_uniform_float32(rng_states, pos)
if (x * x + y * y) <= 1.0:
sub_acc += 1
acc[pos] = sub_acc
rng_seed, sample_size = element
d_acc = cuda.to_device(self.h_acc)
sample_size_per_thread = sample_size // self.h_acc.shape[0]
rng_states = create_xoroshiro128p_states(self.h_acc.shape[0], seed=rng_seed)
gpu_monte_carlo_pi_sampler[self.blocks, self.threads_per_block](
rng_states, sample_size_per_thread, d_acc)
yield d_acc.copy_to_host()
L'immagine seguente mostra il notebook in esecuzione su una GPU:
Maggiori dettagli sono disponibili nel notebook di esempio Utilizzare le GPU con Apache Beam.
Creare un container personalizzato
Nella maggior parte dei casi, se la pipeline non richiede dipendenze o eseguibili Python aggiuntivi, Apache Beam può utilizzare automaticamente le sue immagini contenitore ufficiali per eseguire il codice definito dall'utente. Queste immagini includono molti moduli Python comuni e non devi crearli o specificarli esplicitamente.
In alcuni casi, potresti avere dipendenze Python aggiuntive o persino dipendenze non Python. In questi scenari, puoi creare un container personalizzato e renderlo disponibile per l'esecuzione da parte del cluster Flink. Il seguente elenco fornisce i vantaggi dell'utilizzo di un contenitore personalizzato:
- Tempo di configurazione più rapido per le esecuzioni consecutive e interattive
- Dipendenze e configurazioni stabili
- Maggiore flessibilità: puoi configurare più dipendenze Python
Il processo di compilazione del contenitore potrebbe essere laborioso, ma puoi fare di tutto nel notebook utilizzando il seguente pattern di utilizzo.
Creare uno spazio di lavoro locale
Per prima cosa, crea una directory di lavoro locale nella home directory di Jupyter.
!mkdir -p /home/jupyter/.flink
Prepara le dipendenze Python
A questo punto, installa tutte le dipendenze Python aggiuntive che potresti utilizzare ed esportale in un file requirements.
%pip install dep_a
%pip install dep_b
...
Puoi creare esplicitamente un file dei requisiti utilizzando la magia del %%writefile
notebook.
%%writefile /home/jupyter/.flink/requirements.txt
dep_a
dep_b
...
In alternativa, puoi bloccare tutte le dipendenze locali in un file dei requisiti. Questa opzione potrebbe introdurre dipendenze indesiderate.
%pip freeze > /home/jupyter/.flink/requirements.txt
Prepara le dipendenze non Python
Copia tutte le dipendenze non Python nello spazio di lavoro. Se non hai dipendenze non Python, salta questo passaggio.
!cp /path/to/your-dep /home/jupyter/.flink/your-dep
...
Crea un Dockerfile
Crea un Dockerfile con la magia del blocco note %%writefile. Ad esempio:
%%writefile /home/jupyter/.flink/Dockerfile
FROM apache/beam_python3.7_sdk:2.40.0
COPY requirements.txt /tmp/requirements.txt
COPY your_dep /tmp/your_dep
...
RUN python -m pip install -r /tmp/requirements.txt
Il contenitore di esempio utilizza l'immagine dell'SDK Apache Beam versione 2.40.0
con Python 3.7 come base,
aggiunge un file your_dep e installa le dipendenze Python aggiuntive.
Utilizza questo Dockerfile come modello e modificalo in base al tuo caso d'uso.
Nelle pipeline Apache Beam, quando fai riferimento a dipendenze non Python, utilizza le relative destinazioni COPY. Ad esempio, /tmp/your_dep è il percorso del file your_dep.
Crea un'immagine container in Artifact Registry utilizzando Cloud Build
Attiva i servizi Cloud Build e Artifact Registry, se non sono già attivi.
!gcloud services enable cloudbuild.googleapis.com !gcloud services enable artifactregistry.googleapis.comCrea un repository Artifact Registry per poter caricare gli artefatti. Ogni repository può contenere elementi per un singolo formato supportato.
Tutti i contenuti del repository vengono criptati utilizzando Google-owned and Google-managed encryption keys o chiavi di crittografia gestite dal cliente. Artifact Registry utilizzaGoogle-owned and Google-managed encryption keys per impostazione predefinita e non è richiesta alcuna configurazione per questa opzione.
Devi disporre almeno del accesso come autore di Artifact Registry al repository.
Esegui questo comando per creare un nuovo repository. Il comando utilizza il flag
--asynce restituisce immediatamente il risultato, senza attendere il completamento dell'operazione in corso.gcloud artifacts repositories create REPOSITORY \ --repository-format=docker \ --location=LOCATION \ --asyncSostituisci i seguenti valori:
- REPOSITORY: un nome per il repository. Per ogni posizione del repository in un progetto, i nomi dei repository devono essere univoci.
- LOCATION: la posizione per il tuo repository.
Prima di eseguire il push o il pull delle immagini, configura Docker per autenticare le richieste per Artifact Registry. Per configurare l'autenticazione nei repository Docker, esegui il seguente comando:
gcloud auth configure-docker LOCATION-docker.pkg.devIl comando aggiorna la configurazione Docker. Ora puoi connetterti con Artifact Registry nel tuo Google Cloud progetto per eseguire il push delle immagini.
Utilizza Cloud Build per creare l'immagine del contenitore e salvarla in Artifact Registry.
!cd /home/jupyter/.flink \ && gcloud builds submit \ --tag LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/flink:latest \ --timeout=20mSostituisci
PROJECT_IDcon l'ID del tuo progetto.
Utilizzo di container personalizzati
A seconda del runner, puoi utilizzare i container personalizzati per scopi diversi.
Per l'utilizzo generale dei contenitori Apache Beam, consulta:
Per l'utilizzo dei container Dataflow, consulta:
Disattivare gli indirizzi IP esterni
Quando crei un'istanza del notebook Apache Beam, per aumentare la sicurezza, disattiva gli indirizzi IP esterni. Poiché le istanze di notebook devono scaricare alcune risorse di internet pubbliche, come Artifact Registry, devi prima creare una nuova rete VPC senza un indirizzo IP esterno. Quindi, crea un gateway Cloud NAT per questa rete VPC. Per ulteriori informazioni su Cloud NAT, consulta la documentazione di Cloud NAT. Utilizza la rete VPC e il gateway Cloud NAT per accedere alle risorse internet pubbliche necessarie senza attivare gli indirizzi IP esterni.