JupyterLab 노트북에서 Apache Beam 대화형 실행자를 사용하면 REPL(Read-eval-print-loop) 워크플로에서 반복적으로 파이프라인을 개발하고 파이프라인 그래프를 검사하고 개별 PCollection을 파싱할 수 있습니다. JupyterLab 노트북에서 Apache Beam 대화형 실행기를 사용하는 방법을 보여주는 튜토리얼은 Apache Beam 노트북으로 개발하기를 참고하세요.
이 페이지에서는 Apache Beam 노트북에서 사용할 수 있는 고급 기능에 관한 세부정보를 제공합니다.
노트북 관리형 클러스터의 대화형 FlinkRunner
노트북에서 프로덕션 크기의 데이터를 대화형으로 작업하려면 몇 가지 일반 파이프라인 옵션과 함께 FlinkRunner를 사용하여 노트북 세션에 장기 지속 Dataproc 클러스터를 관리하고 Apache Beam 파이프라인을 분산 실행하도록 지시하면 됩니다.
기본 요건
이 기능을 사용하려면 다음 안내를 따르세요.
- Dataproc API를 사용 설정합니다.
- Dataproc의 노트북 인스턴스를 실행하는 서비스 계정에 관리자 또는 편집자 역할을 부여합니다.
- Apache Beam SDK 버전 2.40.0 이상의 노트북 커널을 사용합니다.
구성
최소한 다음 설정이 필요합니다.
# Set a Cloud Storage bucket to cache source recording and PCollections.
# By default, the cache is on the notebook instance itself, but that does not
# apply to the distributed execution scenario.
ib.options.cache_root = 'gs://<BUCKET_NAME>/flink'
# Define an InteractiveRunner that uses the FlinkRunner under the hood.
interactive_flink_runner = InteractiveRunner(underlying_runner=FlinkRunner())
options = PipelineOptions()
# Instruct the notebook that Google Cloud is used to run the FlinkRunner.
cloud_options = options.view_as(GoogleCloudOptions)
cloud_options.project = 'PROJECT_ID'
명시적 프로비저닝(선택사항)
다음 옵션을 추가할 수 있습니다.
# Change this if the pipeline needs to run in a different region
# than the default, 'us-central1'. For example, to set it to 'us-west1':
cloud_options.region = 'us-west1'
# Explicitly provision the notebook-managed cluster.
worker_options = options.view_as(WorkerOptions)
# Provision 40 workers to run the pipeline.
worker_options.num_workers=40
# Use the default subnetwork.
worker_options.subnetwork='default'
# Choose the machine type for the workers.
worker_options.machine_type='n1-highmem-8'
# When working with non-official Apache Beam releases, such as Apache Beam built from source
# code, configure the environment to use a compatible released SDK container.
# If needed, build a custom container and use it. For more information, see:
# https://beam.apache.org/documentation/runtime/environments/
options.view_as(PortableOptions).environment_config = 'apache/beam_python3.7_sdk:2.41.0 or LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/your_custom_container'
사용
# The parallelism is applied to each step, so if your pipeline has 10 steps, you
# end up having 10 * 10 = 100 tasks scheduled, which can be run in parallel.
options.view_as(FlinkRunnerOptions).parallelism = 10
p_word_count = beam.Pipeline(interactive_flink_runner, options=options)
word_counts = (
p_word_count
| 'read' >> ReadWordsFromText('gs://apache-beam-samples/shakespeare/kinglear.txt')
| 'count' >> beam.combiners.Count.PerElement())
# The notebook session automatically starts and manages a cluster to run
# your pipelines with the FlinkRunner.
ib.show(word_counts)
# Interactively adjust the parallelism.
options.view_as(FlinkRunnerOptions).parallelism = 150
# The BigQuery read needs a Cloud Storage bucket as a temporary location.
options.view_as(GoogleCloudOptions).temp_location = ib.options.cache_root
p_bq = beam.Pipeline(runner=interactive_flink_runner, options=options)
delays_by_airline = (
p_bq
| 'Read Dataset from BigQuery' >> beam.io.ReadFromBigQuery(
project=project, use_standard_sql=True,
query=('SELECT airline, arrival_delay '
'FROM `bigquery-samples.airline_ontime_data.flights` '
'WHERE date >= "2010-01-01"'))
| 'Rebalance Data to TM Slots' >> beam.Reshuffle(num_buckets=1000)
| 'Extract Delay Info' >> beam.Map(
lambda e: (e['airline'], e['arrival_delay'] > 0))
| 'Filter Delayed' >> beam.Filter(lambda e: e[1])
| 'Count Delayed Flights Per Airline' >> beam.combiners.Count.PerKey())
# This step reuses the existing cluster.
ib.collect(delays_by_airline)
# Describe the cluster running the pipelines.
# You can access the Flink dashboard from the printed link.
ib.clusters.describe()
# Cleans up all long-lasting clusters managed by the notebook session.
ib.clusters.cleanup(force=True)
노트북 관리형 클러스터
- 기본적으로 파이프라인 옵션을 제공하지 않으면 대화형 Apache Beam은 가장 최근에 사용한 클러스터를 항상 재사용하여
FlinkRunner로 파이프라인을 실행합니다.- 예를 들어 이 동작을 방지하려면 노트북에서 호스팅하지 않는 FlinkRunner로 동일한 노트북 세션의 다른 파이프라인을 실행하려면
ib.clusters.set_default_cluster(None)를 실행합니다.
- 예를 들어 이 동작을 방지하려면 노트북에서 호스팅하지 않는 FlinkRunner로 동일한 노트북 세션의 다른 파이프라인을 실행하려면
- 기존 Dataproc 클러스터에 매핑되는 프로젝트, 리전, 프로비저닝 구성을 사용하는 새 파이프라인을 인스턴스화할 때도 Dataflow는 클러스터를 재사용합니다(가장 최근에 사용된 클러스터를 사용하지않을 수 있음).
- 하지만 프로비저닝 변경(예: 클러스터 크기 조정)이 제공되면 새 클러스터가 생성되어 원하는 변경사항을 활성화합니다. 클러스터 크기를 조절하려면 Cloud 리소스가 소진되지 않도록
ib.clusters.cleanup(pipeline)을 사용하여 불필요한 클러스터를 삭제합니다. - Flink
master_url가 지정되고 노트북 세션에서 관리되는 클러스터에 속하는 경우 Dataflow는 관리형 클러스터를 재사용합니다.- 노트북 세션에서
master_url을 알 수 없는 경우 사용자가 자체 호스팅하는FlinkRunner가 필요합니다. 노트북은 암시적으로 아무것도 수행하지 않습니다.
- 노트북 세션에서
문제 해결
이 섹션에서는 노트북 관리형 클러스터에서 대화형 FlinkRunner의 문제를 해결하고 디버그하는 데 도움이 되는 정보를 제공합니다.
Flink IOException: 네트워크 버퍼 수가 부족함
편의상 Flink 네트워크 버퍼 구성은 구성에 노출되지 않습니다.
작업 그래프가 너무 복잡하거나 병렬 처리가 너무 높게 설정되면 단계 카디널리티 동시 로드 처리가 너무 커져 여러 태스크가 병렬로 예약되지 않고 실행되지 않을 수 있습니다.
다음 팁을 사용하면 대화형 실행 속도를 높일 수 있습니다.
- 검사할
PCollection만 변수에 할당합니다. PCollections를 하나씩 검사합니다.- 높은 팬아웃 변환 후 다시 셔플을 사용합니다.
- 데이터 크기에 따라 동시 로드를 조정합니다(작을수록 빠른 경우도 있음).
데이터를 검사하는 데 시간이 너무 오래 걸림
Flink 대시보드에서 실행 중인 작업을 확인합니다. 이동 중인 데이터가 단일 머신에 있고 셔플되지 않았으므로 태스크 수백 개가 완료되었고 한 개만 남아 있는 단계가 있을 수 있습니다.
다음과 같은 높은 팬아웃 변환 후에는 항상 다시 셔플을 사용합니다.
- 파일에서 행 읽기
- BigQuery 테이블에서 행 읽기
셔플이 없으면 팬아웃 데이터는 항상 동일한 작업자에서 실행되므로 동시 로드를 활용할 수 없습니다.
얼마나 많은 작업자가 필요한가요?
일반적으로 Flink 클러스터에는 vCPU 수에 작업자 슬롯 수를 곱한 값이 있습니다. 40개의 n1-highmem-8 작업자가 있는 경우 Flink 클러스터에 슬롯이 최대 320개(또는 8 * 40) 있습니다.
이상적으로 작업자는 수천 개의 태스크를 병렬로 예약하여 수백 개의 병렬 조합으로 읽고, 매핑하고, 결합하는 작업을 관리할 수 있습니다.
스트리밍과 호환되나요?
스트리밍 파이프라인은 현재 노트북 관리형 클러스터 기능의 대화형 Flink와 호환되지 않습니다.
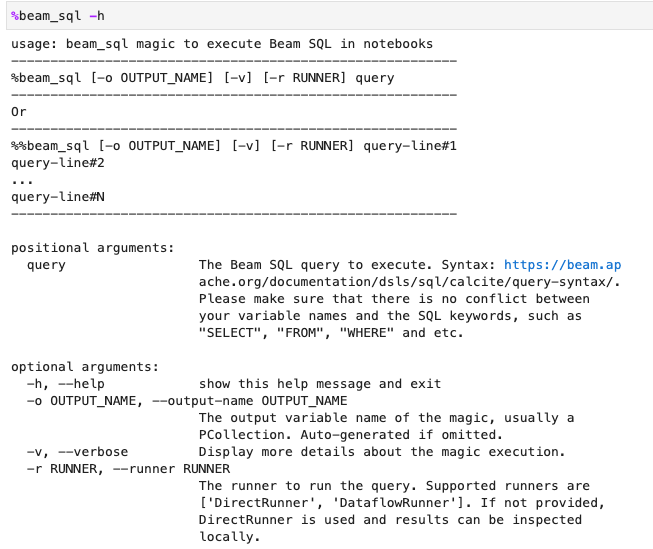
Beam SQL 및 beam_sql 매직
Beam SQL을 사용하면 SQL 문을 사용하여 bounded 및 unbounded PCollections을 쿼리할 수 있습니다. Apache Beam 노트북에서 작업하는 경우 IPython 커스텀 매직 beam_sql을 사용하여 파이프라인 개발 속도를 높일 수 있습니다.
-h 또는 --help 옵션을 사용하여 beam_sql 매직 사용을 확인할 수 있습니다.
상수 값으로 PCollection을 만들 수 있습니다.

여러 PCollections를 조인할 수 있습니다.

-r DataflowRunner 또는 --runner DataflowRunner 옵션을 사용하여 Dataflow 작업을 시작할 수 있습니다.
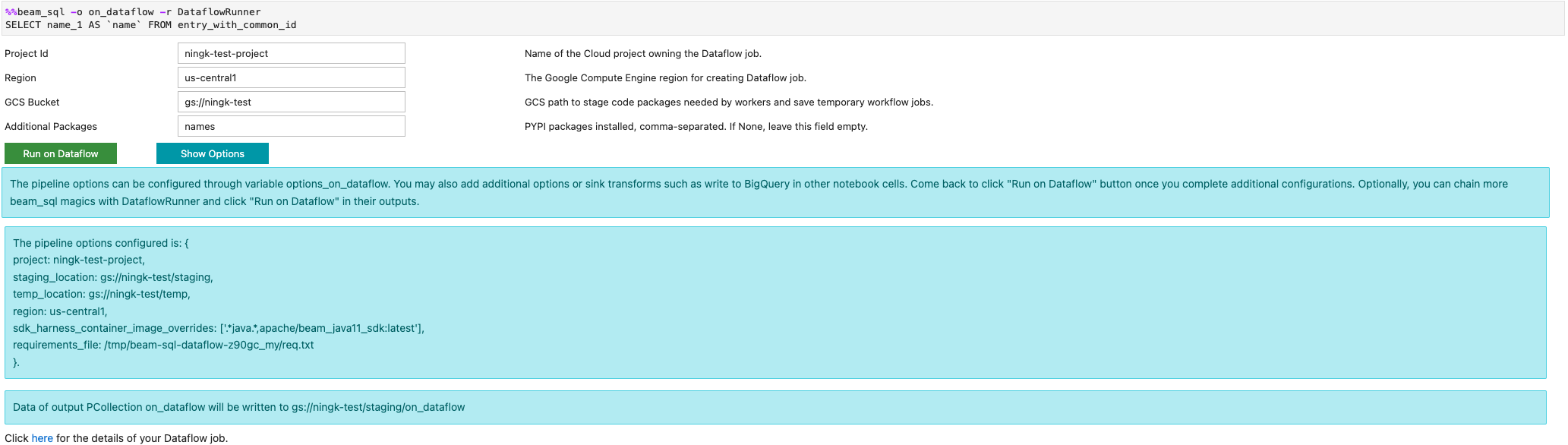
자세한 내용은 노트북의 Apache Beam SQL 예시 노트북을 참조하세요.
JIT 컴파일러 및 GPU를 사용한 가속화
numba 및 GPU와 같은 라이브러리를 사용하여 Python 코드 및 Apache Beam 파이프라인을 가속화할 수 있습니다. nvidia-tesla-t4 GPU로 생성된 Apache Beam 노트북 인스턴스에서 GPU에서 실행하려면 numba.cuda.jit으로 Python 코드를 컴파일합니다. 원하는 경우 CPU에서 실행 속도를 높이려면 Python 코드를 numba.jit 또는 numba.njit을 사용하여 기계어 코드로 컴파일합니다.
다음 예시에서는 GPU에서 처리하는 DoFn을 만듭니다.
class Sampler(beam.DoFn):
def __init__(self, blocks=80, threads_per_block=64):
# Uses only 1 cuda grid with below config.
self.blocks = blocks
self.threads_per_block = threads_per_block
def setup(self):
import numpy as np
# An array on host as the prototype of arrays on GPU to
# hold accumulated sub count of points in the circle.
self.h_acc = np.zeros(
self.threads_per_block * self.blocks, dtype=np.float32)
def process(self, element: Tuple[int, int]):
from numba import cuda
from numba.cuda.random import create_xoroshiro128p_states
from numba.cuda.random import xoroshiro128p_uniform_float32
@cuda.jit
def gpu_monte_carlo_pi_sampler(rng_states, sub_sample_size, acc):
"""Uses GPU to sample random values and accumulates the sub count
of values within a circle of radius 1.
"""
pos = cuda.grid(1)
if pos < acc.shape[0]:
sub_acc = 0
for i in range(sub_sample_size):
x = xoroshiro128p_uniform_float32(rng_states, pos)
y = xoroshiro128p_uniform_float32(rng_states, pos)
if (x * x + y * y) <= 1.0:
sub_acc += 1
acc[pos] = sub_acc
rng_seed, sample_size = element
d_acc = cuda.to_device(self.h_acc)
sample_size_per_thread = sample_size // self.h_acc.shape[0]
rng_states = create_xoroshiro128p_states(self.h_acc.shape[0], seed=rng_seed)
gpu_monte_carlo_pi_sampler[self.blocks, self.threads_per_block](
rng_states, sample_size_per_thread, d_acc)
yield d_acc.copy_to_host()
다음 이미지는 GPU에서 실행되는 노트북을 보여줍니다.
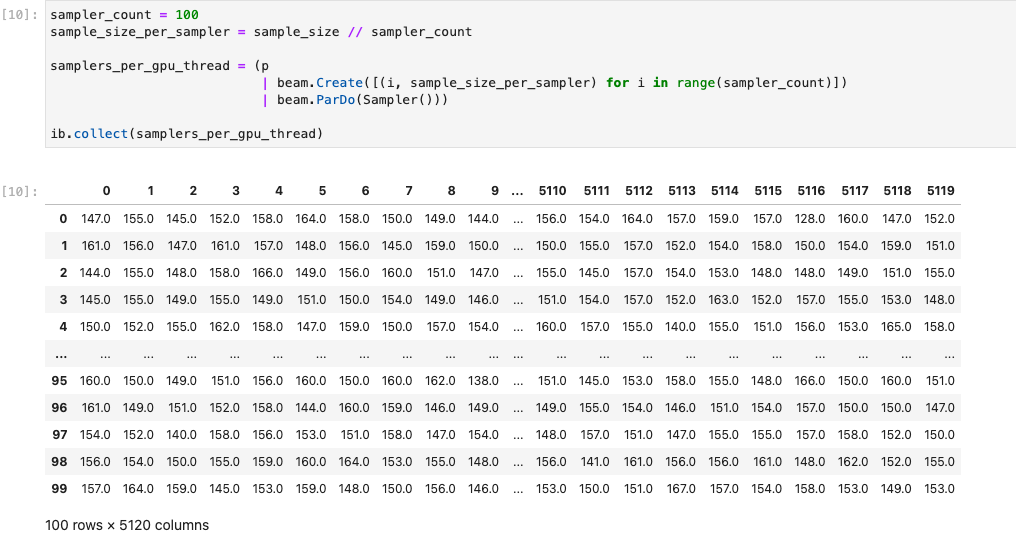
자세한 내용은 Apache Beam에서 GPU 사용 예시 노트북에서 확인할 수 있습니다.
커스텀 컨테이너 빌드
대부분의 경우 파이프라인에 추가 Python 종속 항목이나 실행 파일이 필요하지 않으면 Apache Beam에서 자동으로 공식 컨테이너 이미지를 사용하여 사용자 정의 코드를 실행할 수 있습니다. 이러한 이미지에는 일반적인 Python 모듈이 여러 개 포함되어 있으므로 빌드하거나 명시적으로 지정할 필요가 없습니다.
경우에 따라 추가 Python 종속 항목이나 Python이 아닌 종속 항목이 있을 수 있습니다. 이러한 시나리오에서는 커스텀 컨테이너를 빌드하고 이를 실행할 수 있도록 Flink 클러스터에 제공할 수 있습니다. 다음 목록은 커스텀 컨테이너를 사용할 때의 이점을 제공합니다.
- 연속 및 대화형 실행 설정 시간 단축
- 안정적인 구성 및 종속 항목
- 유연성 향상: Python 종속 항목보다 더 많이 설정할 수 있음
컨테이너 빌드 프로세스는 지루할 수 있지만 다음 사용 패턴을 사용하여 노트북에서 모든 작업을 수행할 수 있습니다.
로컬 작업공간 만들기
먼저 Jupyter 홈 디렉터리에 로컬 작업 디렉터리를 만듭니다.
!mkdir -p /home/jupyter/.flink
Python 종속 항목 준비
그런 다음 사용할 수 있는 모든 추가 Python 종속 항목을 설치하고 요구사항 파일로 내보냅니다.
%pip install dep_a
%pip install dep_b
...
%%writefile 노트북 매직을 사용하여 요구사항 파일을 명시적으로 만들 수 있습니다.
%%writefile /home/jupyter/.flink/requirements.txt
dep_a
dep_b
...
또는 모든 로컬 종속 항목을 요구사항 파일에 고정할 수 있습니다. 이 옵션을 사용하면 의도하지 않은 종속 항목이 도입될 수 있습니다.
%pip freeze > /home/jupyter/.flink/requirements.txt
Python 이외의 종속 항목 준비
Python 이외의 모든 종속 항목을 작업공간에 복사합니다. Python 이외의 종속 항목이 없으면 이 단계를 건너뜁니다.
!cp /path/to/your-dep /home/jupyter/.flink/your-dep
...
Dockerfile 만들기
%%writefile 노트북 매직으로 Dockerfile을 만듭니다. 예를 들면 다음과 같습니다.
%%writefile /home/jupyter/.flink/Dockerfile
FROM apache/beam_python3.7_sdk:2.40.0
COPY requirements.txt /tmp/requirements.txt
COPY your_dep /tmp/your_dep
...
RUN python -m pip install -r /tmp/requirements.txt
이 예시 컨테이너는 Python 3.7을 기준으로 사용하는 Apache Beam SDK 버전 2.40.0의 이미지를 사용하고 your_dep 파일을 추가하고 추가 Python 종속 항목을 설치합니다.
이 Dockerfile을 템플릿으로 사용하고 사용 사례에 맞게 수정합니다.
Apache Beam 파이프라인에서 Python 이외의 종속 항목을 참조할 때는 COPY 대상을 사용합니다. 예를 들어 /tmp/your_dep은 your_dep 파일의 파일 경로입니다.
Cloud Build를 사용하여 Artifact Registry에서 컨테이너 이미지 빌드
Cloud Build 및 Artifact Registry 서비스를 아직 사용 설정하지 않았으면 사용 설정하세요.
!gcloud services enable cloudbuild.googleapis.com !gcloud services enable artifactregistry.googleapis.com아티팩트를 업로드할 수 있도록 Artifact Registry 저장소를 만듭니다. 저장소마다 지원되는 단일 형식의 아티팩트가 포함될 수 있습니다.
모든 저장소 콘텐츠는 Google-owned and Google-managed encryption keys 또는 고객 관리 암호화 키를 통해 암호화됩니다. Artifact Registry는 기본적으로Google-owned and Google-managed encryption keys 를 사용하며 이 옵션을 구성할 필요가 없습니다.
저장소에 최소한 Artifact Registry 작성자 액세스 권한이 있어야 합니다.
다음 명령어를 실행하여 새 저장소를 만듭니다. 이 명령어는 진행 중인 작업이 완료될 때까지 기다리지 않고
--async플래그를 사용하여 즉시 반환합니다.gcloud artifacts repositories create REPOSITORY \ --repository-format=docker \ --location=LOCATION \ --async다음 값을 바꿉니다.
- REPOSITORY: 저장소 이름. 프로젝트의 저장소 위치마다 저장소 이름이 고유해야 합니다.
- LOCATION: 저장소의 위치
이미지를 내보내거나 가져오려면 먼저 Artifact Registry 요청을 인증하도록 Docker를 구성해야 합니다. Docker 저장소에 인증을 설정하려면 다음 명령어를 실행합니다.
gcloud auth configure-docker LOCATION-docker.pkg.dev이 명령어는 Docker 구성을 업데이트합니다. 이제 Google Cloud 프로젝트에서 Artifact Registry와 연결하여 이미지를 내보낼 수 있습니다.
Cloud Build를 사용하여 컨테이너 이미지를 빌드하고 Artifact Registry에 저장합니다.
!cd /home/jupyter/.flink \ && gcloud builds submit \ --tag LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/flink:latest \ --timeout=20mPROJECT_ID를 해당 프로젝트의 프로젝트 ID로 바꿉니다.
커스텀 컨테이너 사용
실행자에 따라 다양한 목적으로 커스텀 컨테이너를 사용할 수 있습니다.
일반적인 Apache Beam 컨테이너 사용은 다음을 참조하세요.
Dataflow 컨테이너 사용은 다음을 참조하세요.
외부 IP 주소 사용 중지
Apache Beam 노트북 인스턴스를 만들 때 보안을 강화하려면 외부 IP 주소를 사용 중지합니다. 노트북 인스턴스는 Artifact Registry와 같은 일부 공개 인터넷 리소스를 다운로드해야 하므로 먼저 외부 IP 주소 없이 새 VPC 네트워크를 만들어야 합니다. 그런 다음 이 VPC 네트워크에 대한 Cloud NAT 게이트웨이를 만듭니다. Cloud NAT에 대한 자세한 내용은 Cloud NAT 문서를 참조하세요. VPC 네트워크와 Cloud NAT 게이트웨이를 사용하여 외부 IP 주소를 사용 설정하지 않고도 필요한 공개 인터넷 리소스에 액세스할 수 있습니다.