관리형 I/O를 사용하면 Dataflow에서 Apache Beam 파이프라인에 사용되는 특정 I/O 커넥터를 관리할 수 있습니다. 관리형 I/O를 사용하면 지원되는 소스 및 싱크와 통합되는 파이프라인을 간편하게 관리할 수 있습니다.
관리형 I/O는 함께 작동하는 다음 두 가지 구성요소로 구성됩니다.
I/O 커넥터(소스 및 싱크)를 만들기 위한 공통 API를 제공하는 Apache Beam 변환입니다.
Apache Beam 버전과 별개로 업그레이드하는 기능을 비롯해 사용자를 대신하여 이러한 I/O 커넥터를 관리하는 Dataflow 서비스입니다.
관리 I/O의 장점은 다음과 같습니다.
자동 업그레이드. Dataflow는 파이프라인의 관리형 I/O 커넥터를 자동으로 업그레이드합니다. 즉, 코드를 변경하지 않아도 파이프라인은 이러한 커넥터의 보안 수정, 성능 개선, 버그 수정을 수신합니다. 자세한 내용은 자동 업그레이드를 참고하세요.
일관된 API 기존에는 Apache Beam의 I/O 커넥터에는 고유한 API가 있고 각 커넥터는 다른 방식으로 구성되었습니다. 관리형 I/O는 키-값 속성을 사용하는 단일 구성 API를 제공하므로 더 간단하고 일관된 파이프라인 코드가 생성됩니다. 자세한 내용은 구성 API를 참고하세요.
요구사항
다음 SDK는 관리형 I/O를 지원합니다.
Java용 Apache Beam SDK 버전 2.58.0 이상
Python용 Apache Beam SDK 버전 2.61.0 이상
백엔드 서비스에는 Dataflow Runner v2가 필요합니다. Runner v2가 사용 설정되지 않은 경우 파이프라인은 계속 실행되지만 관리형 I/O 서비스의 이점을 얻지 못합니다.
자동 업그레이드
관리형 I/O 커넥터가 있는 Dataflow 파이프라인은 다음과 같이 최신 안정 버전의 커넥터를 자동으로 사용합니다.
작업을 제출하면 Dataflow는 테스트를 거쳐 제대로 작동하는 최신 버전의 커넥터를 사용합니다.
스트리밍 작업의 경우 Dataflow는 대체 작업을 실행할 때마다 업데이트를 확인하고 알려진 최신 버전을 자동으로 사용합니다. Dataflow는 대체 작업에서 코드를 변경하지 않더라도 이 검사를 실행합니다.
커넥터나 파이프라인의 Apache Beam 버전을 수동으로 업데이트하는 것에 대해 걱정할 필요가 없습니다.
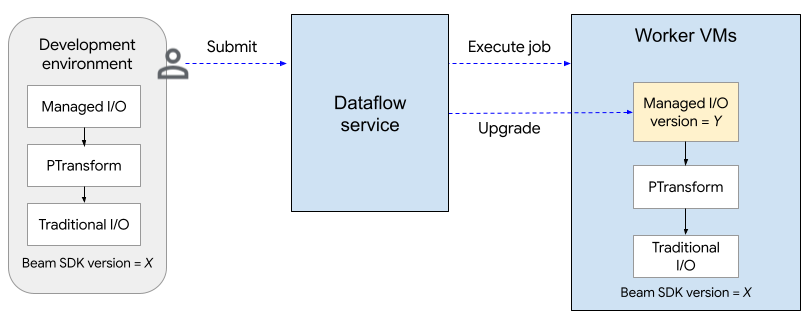
다음 다이어그램은 업그레이드 프로세스를 보여줍니다. 사용자가 SDK 버전 X를 사용하여 Apache Beam 파이프라인을 만듭니다. 사용자가 작업을 제출하면 Dataflow는 관리형 I/O의 버전을 확인하고 버전 Y로 업그레이드합니다.
업그레이드 프로세스는 작업 시작 시간을 약 2분 정도 추가합니다. 관리형 I/O 작업의 상태를 확인하려면 'Managed Transform(s)'라는 문자열이 포함된 로그 항목을 찾습니다.
구성 API
관리형 I/O는 소스와 싱크를 구성하기 위한 일관된 API를 제공하는 턴키 Apache Beam 변환입니다.
Java
관리형 I/O에서 지원하는 소스 또는 싱크를 만들려면 Managed 클래스를 사용합니다. 인스턴스화할 소스 또는 싱크를 지정하고 다음과 같이 구성 매개변수 집합을 전달합니다.
Mapconfig=ImmutableMap.<String,Object>builder().put("config1","abc").put("config2",1);pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config)).getSinglePCollection();
일부 싱크의 경우 관리형 I/O 커넥터는 수신 레코드의 필드 값을 기반으로 대상을 동적으로 선택할 수 있습니다.
동적 대상을 사용하려면 대상에 대한 템플릿 문자열을 제공합니다. 템플릿 문자열에는 중괄호 안에 필드 이름(예: "tables.{field1}")을 포함할 수 있습니다. 런타임 시 커넥터는 수신되는 각 레코드에 대한 필드 값을 대체하여 해당 레코드의 대상을 결정합니다.
예를 들어 데이터에 airport라는 필드가 있다고 가정해 보겠습니다. 대상을 "flights.{airport}"로 설정할 수 있습니다. airport=SFO인 경우 레코드는 flights.SFO에 쓰여집니다. 중첩된 필드의 경우 점 표기법을 사용합니다. 예를 들면 다음과 같습니다. {top.middle.nested}
특정 필드가 대상 테이블에 쓰여지기 전에 필터링할 수 있습니다. 동적 대상을 지원하는 싱크의 경우 이 목적으로 drop, keep 또는 only 매개변수를 사용할 수 있습니다. 이러한 매개변수를 사용하면 메타데이터를 대상에 쓰지 않고도 입력 레코드에 대상 메타데이터를 포함할 수 있습니다.
특정 싱크에 이러한 매개변수 중 최대 하나를 설정할 수 있습니다.
구성 매개변수
데이터 유형
설명
drop
문자열 목록
대상에 쓰기 전에 삭제할 필드 이름 목록입니다.
keep
문자열 목록
대상에 쓸 때 유지할 필드 이름 목록입니다. 다른 필드는 삭제됩니다.
only
문자열
대상에 쓸 때 기록할 최상위 레코드로 사용할 필드의 이름입니다(하나만 사용).
다른 모든 필드는 삭제됩니다. 이 필드는 행 유형이어야 합니다.
[[["이해하기 쉬움","easyToUnderstand","thumb-up"],["문제가 해결됨","solvedMyProblem","thumb-up"],["기타","otherUp","thumb-up"]],[["이해하기 어려움","hardToUnderstand","thumb-down"],["잘못된 정보 또는 샘플 코드","incorrectInformationOrSampleCode","thumb-down"],["필요한 정보/샘플이 없음","missingTheInformationSamplesINeed","thumb-down"],["번역 문제","translationIssue","thumb-down"],["기타","otherDown","thumb-down"]],["최종 업데이트: 2025-08-08(UTC)"],[[["\u003cp\u003eManaged I/O simplifies the management of Apache Beam pipelines by providing a common API for I/O connectors (sources and sinks) and a Dataflow service to manage them.\u003c/p\u003e\n"],["\u003cp\u003eDataflow automatically upgrades managed I/O connectors, ensuring pipelines receive security fixes, performance improvements, and bug fixes without requiring code changes.\u003c/p\u003e\n"],["\u003cp\u003eManaged I/O offers a consistent configuration API using key-value properties, resulting in simpler and more uniform pipeline code compared to traditional Apache Beam connectors.\u003c/p\u003e\n"],["\u003cp\u003eFor sinks, managed I/O supports dynamic destinations, enabling the selection of a destination at runtime based on field values in the incoming records, using template strings.\u003c/p\u003e\n"],["\u003cp\u003eManaged I/O includes filtering options like \u003ccode\u003edrop\u003c/code\u003e, \u003ccode\u003ekeep\u003c/code\u003e, and \u003ccode\u003eonly\u003c/code\u003e to specify which fields to include or exclude when writing to the destination.\u003c/p\u003e\n"]]],[],null,["Managed I/O enables Dataflow to manage specific I/O connectors\nused in Apache Beam pipelines. Managed I/O simplifies the management of\npipelines that integrate with supported sources and sinks.\n\nManaged I/O consists of two components that work together:\n\n- An Apache Beam transform that provides a common API for creating I/O\n connectors (sources and sinks).\n\n- A Dataflow service that manages these I/O connectors on your\n behalf, including the ability to upgrade them independently of the\n Apache Beam version.\n\nAdvantages of managed I/O include the following:\n\n- **Automatic upgrades** . Dataflow automatically upgrades the\n managed I/O connectors in your pipeline. That means your pipeline\n receives security fixes, performance improvements, and bug fixes for these\n connectors, without requiring any code changes. For more information, see\n [Automatic upgrades](#upgrades).\n\n- **Consistent API** . Traditionally, I/O connectors in Apache Beam have\n distinct APIs, and each connector is configured in a different way. Managed\n I/O provides a single configuration API that uses key-value properties,\n resulting in simpler and more consistent pipeline code. For more\n information, see [Configuration API](#configuration).\n\nRequirements\n\n- The following SDKs support managed I/O:\n\n - Apache Beam SDK for Java version 2.58.0 or later.\n - Apache Beam SDK for Python version 2.61.0 or later.\n- The backend service requires\n [Dataflow Runner v2](/dataflow/docs/runner-v2). If Runner v2\n is not enabled, your pipeline still runs, but it doesn't get the benefits of\n the managed I/O service.\n\nAutomatic upgrades\n\nDataflow pipelines with managed I/O connectors automatically use\nthe latest reliable version of the connector, as follows:\n\n- When you submit a job, Dataflow uses the newest version of the\n connector that has been tested and works well.\n\n- For streaming jobs, Dataflow checks for updates whenever you\n [launch a replacement job](/dataflow/docs/guides/updating-a-pipeline#Launching),\n and automatically uses the latest known-good version. Dataflow\n performs this check even if you don't change any code in the replacement job.\n\nYou don't have to worry about manually updating the connector or your pipeline's\nApache Beam version.\n\nThe following diagram shows the upgrade process. The user creates an\nApache Beam pipeline using SDK version *X* . When the user submits the job,\nDataflow checks the version of the Managed I/O and upgrades it\nto version *Y*.\n\nThe upgrade process adds about two minutes to the startup time for a job. To\ncheck the status of managed I/O operations, look for\n[log entries](/dataflow/docs/guides/logging) that include the string\n\"`Managed Transform(s)`\".\n\nConfiguration API\n\nManaged I/O is a turnkey Apache Beam transform that provides a consistent\nAPI to configure sources and sinks. \n\nJava\n\nTo create any source or sink supported by Managed I/O, you use the\n[`Managed`](https://beam.apache.org/releases/javadoc/current/org/apache/beam/sdk/managed/Managed.html) class. Specify which source or sink to instantiate,\nand pass in a set of configuration parameters, similar to the following: \n\n Map config = ImmutableMap.\u003cString, Object\u003ebuilder()\n .put(\"config1\", \"abc\")\n .put(\"config2\", 1);\n\n pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))\n .getSinglePCollection();\n\nYou can also pass configuration parameters as a YAML file. For a complete code\nexample, see\n[Read from Apache Iceberg](/dataflow/docs/guides/read-from-iceberg#example).\n\nPython\n\nImport the [`apache_beam.transforms.managed`](https://beam.apache.org/releases/pydoc/current/apache_beam.transforms.managed.html) module\nand call the `managed.Read` or `managed.Write` method. Specify which source or\nsink to instantiate, and pass in a set of configuration parameters, similar to\nthe following: \n\n pipeline\n | beam.managed.Read(\n beam.managed.\u003cvar translate=\"no\"\u003e\u003cspan class=\"devsite-syntax-n\"\u003eSOURCE\u003c/span\u003e\u003c/var\u003e, # Example: beam.managed.KAFKA\n config={\n \"config1\": \"abc\",\n \"config2\": 1\n }\n )\n\nYou can also pass configuration parameters as a YAML file. For a complete code\nexample, see\n[Read from Apache Kafka](/dataflow/docs/guides/read-from-kafka#dataflow_kafka_read-python).\n\nDynamic destinations\n\nFor some sinks, the managed I/O connector can dynamically select a destination\nbased on field values in the incoming records.\n\nTo use dynamic destinations, provide a template string for the destination. The\ntemplate string can include field names within curly brackets, such as\n`\"tables.{field1}\"`. At runtime, the connector substitutes the value of the\nfield for each incoming record, to determine the destination for that record.\n\nFor example, suppose your data has a field named `airport`. You could set the\ndestination to `\"flights.{airport}\"`. If `airport`=`SFO`, the record is written\nto `flights.SFO`. For nested fields, use dot-notation. For example:\n`{top.middle.nested}`.\n\nFor example code that shows how to use dynamic destinations, see\n[Write with dynamic destinations](/dataflow/docs/guides/write-to-iceberg#dynamic-destinations-example).\n\nFiltering\n\nYou might want to filter out certain fields before they are written to the\ndestination table. For sinks that support dynamic destinations, you can use\nthe `drop`, `keep`, or `only` parameter for this purpose. These parameters let\nyou include destination metadata in the input records, without writing the\nmetadata to the destination.\n\nYou can set at most one of these parameters for a given sink.\n\n| Configuration parameter | Data type | Description |\n|-------------------------|-----------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n| `drop` | list of strings | A list of field names to drop before writing to the destination. |\n| `keep` | list of strings | A list of field names to keep when writing to the destination. Other fields are dropped. |\n| `only` | string | The name of exactly one field to use as the top-level record to write when writing to the destination. All other fields are dropped. This field must be of row type. |\n\nSupported sources and sinks\n\nManaged I/O supports the following sources and sinks.\n\n- [Apache Iceberg](/dataflow/docs/guides/managed-io-iceberg)\n- [Apache Kafka](/dataflow/docs/guides/managed-io-kafka)\n- [BigQuery](/dataflow/docs/guides/managed-io-bigquery)\n\nFor more information, see\n[Managed I/O Connectors](https://beam.apache.org/documentation/io/managed-io/)\nin the Apache Beam documentation."]]