관리형 I/O를 사용하면 Dataflow에서 Apache Beam 파이프라인에 사용되는 특정 I/O 커넥터를 관리할 수 있습니다. 관리형 I/O를 사용하면 지원되는 소스 및 싱크와 통합되는 파이프라인을 간편하게 관리할 수 있습니다.
관리형 I/O는 함께 작동하는 다음 두 가지 구성요소로 구성됩니다.
I/O 커넥터(소스 및 싱크)를 만들기 위한 공통 API를 제공하는 Apache Beam 변환입니다.
Apache Beam 버전과 별개로 업그레이드하는 기능을 비롯해 사용자를 대신하여 이러한 I/O 커넥터를 관리하는 Dataflow 서비스입니다.
관리 I/O의 장점은 다음과 같습니다.
자동 업그레이드. Dataflow는 파이프라인의 관리형 I/O 커넥터를 자동으로 업그레이드합니다. 즉, 코드를 변경하지 않아도 파이프라인은 이러한 커넥터의 보안 수정, 성능 개선, 버그 수정을 수신합니다. 자세한 내용은 자동 업그레이드를 참고하세요.
일관된 API 기존에는 Apache Beam의 I/O 커넥터에는 고유한 API가 있고 각 커넥터는 다른 방식으로 구성되었습니다. 관리형 I/O는 키-값 속성을 사용하는 단일 구성 API를 제공하므로 더 간단하고 일관된 파이프라인 코드가 생성됩니다. 자세한 내용은 구성 API를 참고하세요.
요구사항
다음 SDK는 관리형 I/O를 지원합니다.
- Java용 Apache Beam SDK 버전 2.58.0 이상
- Python용 Apache Beam SDK 버전 2.61.0 이상
백엔드 서비스에는 Dataflow Runner v2가 필요합니다. Runner v2가 사용 설정되지 않은 경우 파이프라인은 계속 실행되지만 관리형 I/O 서비스의 이점을 얻지 못합니다.
자동 업그레이드
관리형 I/O 커넥터가 있는 Dataflow 파이프라인은 다음과 같이 최신 안정 버전의 커넥터를 자동으로 사용합니다.
작업을 제출하면 Dataflow는 테스트를 거쳐 제대로 작동하는 최신 버전의 커넥터를 사용합니다.
스트리밍 작업의 경우 Dataflow는 대체 작업을 실행할 때마다 업데이트를 확인하고 알려진 최신 버전을 자동으로 사용합니다. Dataflow는 대체 작업에서 코드를 변경하지 않더라도 이 검사를 실행합니다.
커넥터나 파이프라인의 Apache Beam 버전을 수동으로 업데이트하는 것에 대해 걱정할 필요가 없습니다.
다음 다이어그램은 업그레이드 프로세스를 보여줍니다. 사용자가 SDK 버전 X를 사용하여 Apache Beam 파이프라인을 만듭니다. 사용자가 작업을 제출하면 Dataflow는 관리형 I/O의 버전을 확인하고 버전 Y로 업그레이드합니다.
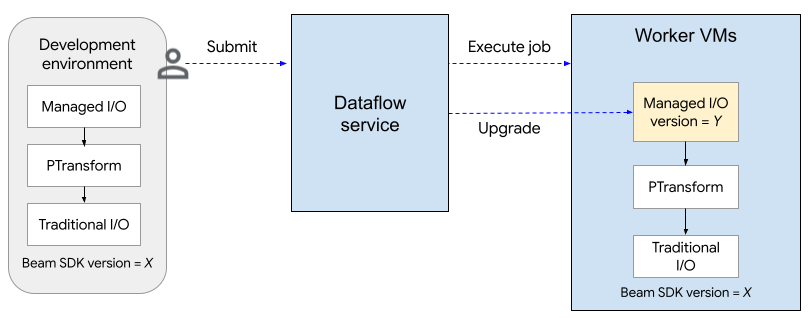
업그레이드 프로세스는 작업 시작 시간을 약 2분 정도 추가합니다. 관리형 I/O 작업의 상태를 확인하려면 'Managed Transform(s)'라는 문자열이 포함된 로그 항목을 찾습니다.
구성 API
관리형 I/O는 소스와 싱크를 구성하기 위한 일관된 API를 제공하는 턴키 Apache Beam 변환입니다.
Java
관리형 I/O에서 지원하는 소스 또는 싱크를 만들려면 Managed 클래스를 사용합니다. 인스턴스화할 소스 또는 싱크를 지정하고 다음과 같이 구성 매개변수 집합을 전달합니다.
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
구성 매개변수를 YAML 파일로 전달할 수도 있습니다. 전체 코드 예시는 Apache Iceberg에서 읽기를 참조하세요.
Python
apache_beam.transforms.managed 모듈을 가져오고 managed.Read 또는 managed.Write 메서드를 호출합니다. 인스턴스화할 소스 또는 싱크를 지정하고 다음과 같이 구성 매개변수 집합을 전달합니다.
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
구성 매개변수를 YAML 파일로 전달할 수도 있습니다. 전체 코드 예시는 Apache Kafka에서 읽기를 참조하세요.
동적 대상
일부 싱크의 경우 관리형 I/O 커넥터는 수신 레코드의 필드 값을 기반으로 대상을 동적으로 선택할 수 있습니다.
동적 대상을 사용하려면 대상에 대한 템플릿 문자열을 제공합니다. 템플릿 문자열에는 중괄호 안에 필드 이름(예: "tables.{field1}")을 포함할 수 있습니다. 런타임 시 커넥터는 수신되는 각 레코드에 대한 필드 값을 대체하여 해당 레코드의 대상을 결정합니다.
예를 들어 데이터에 airport라는 필드가 있다고 가정해 보겠습니다. 대상을 "flights.{airport}"로 설정할 수 있습니다. airport=SFO인 경우 레코드는 flights.SFO에 쓰여집니다. 중첩된 필드의 경우 점 표기법을 사용합니다. 예를 들면 다음과 같습니다. {top.middle.nested}
동적 대상을 사용하는 방법을 보여주는 예시 코드는 동적 대상으로 쓰기를 참조하세요.
필터링
특정 필드가 대상 테이블에 쓰여지기 전에 필터링할 수 있습니다. 동적 대상을 지원하는 싱크의 경우 이 목적으로 drop, keep 또는 only 매개변수를 사용할 수 있습니다. 이러한 매개변수를 사용하면 메타데이터를 대상에 쓰지 않고도 입력 레코드에 대상 메타데이터를 포함할 수 있습니다.
특정 싱크에 이러한 매개변수 중 최대 하나를 설정할 수 있습니다.
| 구성 매개변수 | 데이터 유형 | 설명 |
|---|---|---|
drop |
문자열 목록 | 대상에 쓰기 전에 삭제할 필드 이름 목록입니다. |
keep |
문자열 목록 | 대상에 쓸 때 유지할 필드 이름 목록입니다. 다른 필드는 삭제됩니다. |
only |
문자열 | 대상에 쓸 때 기록할 최상위 레코드로 사용할 필드의 이름입니다(하나만 사용). 다른 모든 필드는 삭제됩니다. 이 필드는 행 유형이어야 합니다. |
지원되는 소스 및 싱크
관리형 I/O는 다음 소스와 싱크를 지원합니다.