L'interfaccia di monitoraggio di Dataflow fornisce una rappresentazione grafica di ogni job: il grafico del job. Il grafico dei job fornisce anche un riepilogo del job, un log del job e informazioni su ogni passaggio della pipeline.
Per visualizzare il grafico dei job per un job:
Nella console Google Cloud , vai alla pagina Dataflow > Job.
Seleziona un lavoro.
Fai clic sulla scheda Grafico dei job.
Per impostazione predefinita, la pagina del grafico del job mostra la visualizzazione Grafico. Per visualizzare il grafico del job come tabella, nella visualizzazione Passaggi del job, seleziona Visualizzazione tabella. La visualizzazione tabella contiene le stesse informazioni in un formato diverso. La visualizzazione tabella è utile nei seguenti scenari:
- Il tuo job ha molte fasi, il che rende difficile la navigazione nel grafico del job.
- Vuoi ordinare i passaggi del job in base a una proprietà specifica. Ad esempio, puoi ordinare la tabella in base al tempo reale per identificare i passaggi lenti.
Visualizzazione grafico
Il grafico del job rappresenta ogni trasformazione nella pipeline come una casella. L'immagine
seguente mostra un grafico del job con tre trasformazioni: Read PubSub Events,
5m Window e Write File(s).
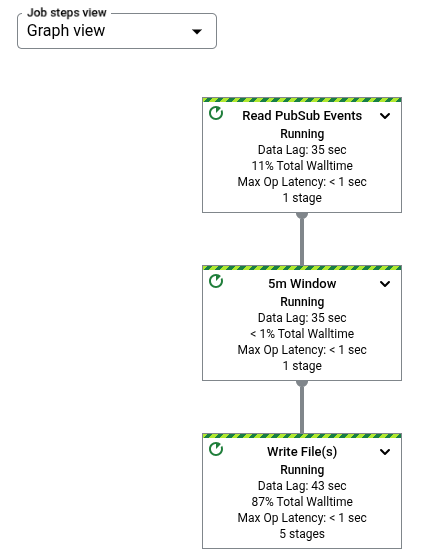
Ogni casella contiene le seguenti informazioni:
Stato; uno dei seguenti:
- In esecuzione: il passaggio è in esecuzione
- In coda: il passaggio di un job FlexRS è in coda
- Riuscito: il passaggio è stato completato correttamente
- Interrotto: il passaggio è stato interrotto perché il job è stato interrotto
- Sconosciuto: il passaggio non è riuscito a segnalare lo stato
- Non riuscito: il passaggio non è stato completato
Il numero di fasi del job che eseguono questo passaggio
Se un passaggio rappresenta una trasformazione composita, puoi espanderlo per visualizzare le trasformazioni secondarie. Per espandere il passaggio, fai clic sulla freccia Espandi nodo.
Nomi delle trasformazioni
Dataflow offre diversi modi per ottenere il nome della trasformazione mostrato nel grafico dei job di monitoraggio. I nomi delle trasformazioni vengono utilizzati in posizioni visibili pubblicamente, tra cui l'interfaccia di monitoraggio Dataflow, i file di log e gli strumenti di debug. Non utilizzare nomi di trasformazione che includono informazioni personali, come nomi utente o nomi di organizzazioni.
Java
- Dataflow può utilizzare un nome che assegni quando applichi la trasformazione. Il primo
argomento che fornisci al metodo
applyè il nome della trasformazione. - Dataflow può dedurre il nome della trasformazione dal nome della classe, se crei una
trasformazione personalizzata, o dal nome dell'oggetto funzione
DoFn, se utilizzi una trasformazione di base comeParDo.
Python
- Dataflow può utilizzare un nome che assegni quando applichi la trasformazione. Puoi impostare il nome della trasformazione specificando l'argomento
labeldella trasformazione. - Dataflow può dedurre il nome della trasformazione dal nome della classe, se crei una
trasformazione personalizzata, o dal nome dell'oggetto funzione
DoFn, se utilizzi una trasformazione di base comeParDo.
Vai
- Dataflow può utilizzare un nome che assegni quando applichi la trasformazione. Puoi impostare il
nome della trasformazione specificando
Scope. - Dataflow può dedurre il nome della trasformazione, dal nome della struttura se utilizzi un
DoFnstrutturale o dal nome della funzione se utilizzi unDoFnfunzionale.
Visualizzare le informazioni sul passo
Quando fai clic su un passaggio nel grafico del job, il riquadro Informazioni passaggio mostra ulteriori dettagli sul passaggio. Per saperne di più, consulta Informazioni sul passaggio del job.
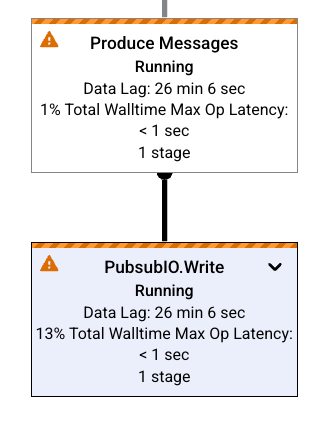
Colli di bottiglia
Se Dataflow rileva un collo di bottiglia, il grafico del job mostra un simbolo di avviso nei passaggi interessati. Per visualizzare la causa del collo di bottiglia, fai clic sul passaggio per aprire il riquadro Informazioni passaggio. Per saperne di più, vedi Risolvere i problemi relativi ai colli di bottiglia.
Esempi di grafici dei job
Questa sezione mostra alcuni esempi di codice della pipeline e i grafici dei job corrispondenti.
Grafico del job di base
Pipeline Code:
Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Vai// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
Grafico del job:
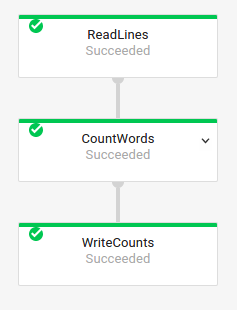
|
Grafico del job con trasformazioni composite
Le trasformazioni composite sono trasformazioni che contengono più trasformazioni secondarie nidificate. Nel grafico dei job, le trasformazioni composite sono espandibili. Per espandere la trasformazione e visualizzare le trasformazioni secondarie, fai clic sulla freccia.
Pipeline Code:
Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Vai// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
Grafico del job:
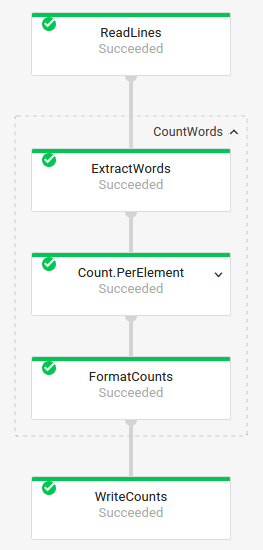
|
Nel codice della pipeline, potresti utilizzare il seguente codice per richiamare la trasformazione composita:
result = transform.apply(input);
Le trasformazioni composite richiamate in questo modo omettono l'annidamento previsto e potrebbero apparire espanse nell'interfaccia di monitoraggio di Dataflow. La pipeline potrebbe anche generare avvisi o errori relativi a nomi unici stabili al momento dell'esecuzione della pipeline.
Per evitare questi problemi, richiama le trasformazioni utilizzando il formato consigliato:
result = input.apply(transform);
Passaggi successivi
- Visualizzare informazioni dettagliate sui passaggi del job
- Visualizzare le fasi del job nella scheda Dettagli esecuzione
- Risolvi i problemi della pipeline