L'interface de surveillance Dataflow fournit une représentation graphique de chaque job : le graphique de job. Le graphique de job fournit également un résumé de job, un journal de job et des informations sur chaque étape du pipeline.
Pour afficher le graphique des tâches d'un job, procédez comme suit :
Dans la console Google Cloud , accédez à la page Dataflow > Tâches.
Sélectionnez une tâche.
Cliquez sur l'onglet Graphique des jobs.
Par défaut, la page du graphique de la tâche affiche la vue Graphique. Pour afficher le graphique de votre job sous forme de tableau, dans Vue des étapes du job, sélectionnez Vue Tableau. La vue Tableau contient les mêmes informations, mais dans un format différent. La vue Tableau est utile dans les scénarios suivants :
- Votre job comporte de nombreuses étapes, ce qui rend le graphique de job difficile à parcourir.
- Vous souhaitez trier les étapes du job selon une propriété spécifique. Par exemple, vous pouvez trier le tableau par temps écoulé pour identifier les étapes lentes.
Vue graphique
Sur le graphique de job d'un pipeline, chaque transformation est représentée sous la forme d'une case. L'image suivante montre un graphique de job avec trois transformations : Read PubSub Events, 5m Window et Write File(s).
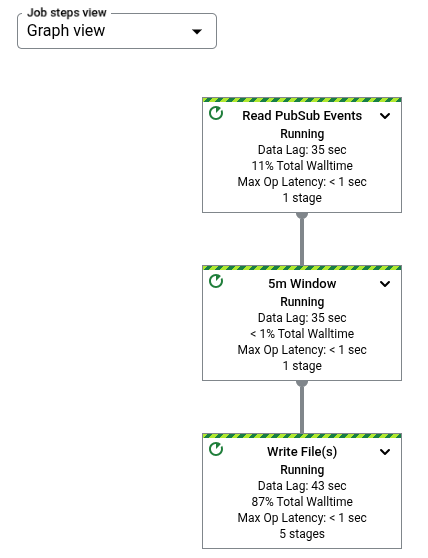
Chaque encadré contient les informations suivantes :
État : l'une des valeurs suivantes :
- Running (en cours d'exécution) : l'étape est en cours d'exécution.
- Queued (En file d'attente) : l'étape d'une tâche FlexRS est en file d'attente.
- Succeeded (Réussie) : l'étape s'est terminée avec succès.
- Stopped (Arrêtée) : l'étape a été arrêtée, car la tâche s'est arrêtée.
- Unknown (Inconnu) : l'étape n'a pas pu indiquer l'état.
- Failed (Échec) : l'étape n'a pas abouti.
Nombre d'étapes de job qui exécutent cette étape
Si une étape représente une transformation composite, vous pouvez la développer pour afficher les sous-transformations. Pour développer l'étape, cliquez sur la flèche Développer le nœud.
Noms de transformation
Dataflow propose plusieurs solutions pour obtenir le nom de la transformation apparaissant dans le graphique de tâche de surveillance : Les noms de transformation sont utilisés dans des emplacements visibles publiquement, y compris dans l'interface de surveillance de Dataflow, les fichiers journaux et les outils de débogage. N'utilisez pas de noms de transformation incluant des informations permettant d'identifier personnellement l'utilisateur, telles que des noms d'utilisateur ou des noms d'organisation.
Java
- Dataflow peut utiliser un nom que vous attribuez lorsque vous appliquez votre transformation. Le premier argument que vous fournissez à la méthode
applysert de nom à la transformation. - Dataflow peut déduire le nom de la transformation soit du nom de la classe (si vous créez une transformation personnalisée), soit du nom de votre objet fonction
DoFn(si vous utilisez une transformation de base telle queParDo).
Python
- Dataflow peut utiliser un nom que vous attribuez lorsque vous appliquez votre transformation. Vous pouvez définir le nom d'une transformation en spécifiant l'argument
labelde celle-ci. - Dataflow peut déduire le nom de la transformation soit du nom de la classe (si vous avez créé une transformation personnalisée), soit du nom de votre objet fonction
DoFn(si vous utilisez une transformation de base telle queParDo).
Go
- Dataflow peut utiliser un nom que vous attribuez lorsque vous appliquez votre transformation. Vous pouvez définir le nom d'une transformation en spécifiant le
Scope. - Dataflow peut déduire le nom de la transformation soit du nom de la structure, si vous utilisez un
DoFnde structure, soit du nom de la fonction, si vous utilisez unDoFn.
Afficher les informations sur les étapes
Lorsque vous cliquez sur une étape dans le graphique du job, le panneau Step Info (Informations sur l'étape) affiche plus de détails sur l'étape. Pour en savoir plus, consultez Informations sur les étapes du job.
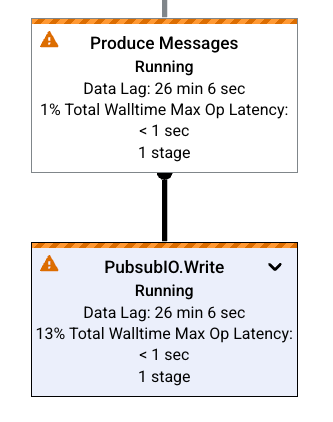
Goulots d'étranglement
Si Dataflow détecte un goulot d'étranglement, le graphique de job affiche un symbole d'alerte sur les étapes concernées. Pour identifier la cause du goulot d'étranglement, cliquez sur l'étape pour ouvrir le panneau Informations sur l'étape. Pour en savoir plus, consultez Résoudre les problèmes de goulots d'étranglement.
Exemples de graphiques de job
Cette section présente des exemples de code de pipeline et les graphiques de tâches correspondants.
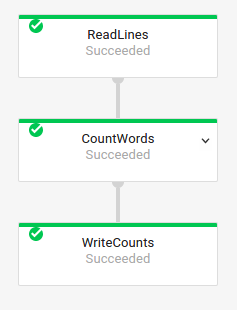
Graphique de la tâche de base
Code du pipeline :Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
Graphique de la tâche :
|
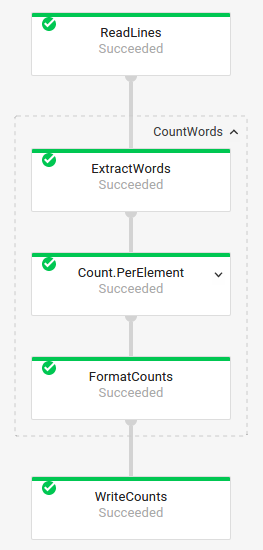
Graphique de tâche avec transformations composites
Les transformations composites sont des transformations qui contiennent plusieurs sous-transformations imbriquées. Dans le graphique de tâche, vous pouvez développer les transformations composites. Pour développer la transformation et afficher les sous-transformations, cliquez sur la flèche.
Code du pipeline :Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
Graphique de la tâche :
|
Dans votre code de pipeline, vous pouvez utiliser le code suivant pour appeler votre transformation composite :
result = transform.apply(input);
Les transformations composites appelées de cette façon omettent l'imbrication attendue et peuvent donc apparaître développées dans l'interface de surveillance de Dataflow. Votre pipeline peut également générer des erreurs ou des avertissements relatifs aux noms uniques stables au moment de l'exécution du pipeline.
Pour éviter ces problèmes, appelez vos transformations à l'aide du format recommandé :
result = input.apply(transform);
Étapes suivantes
- Afficher des informations détaillées sur les étapes du job
- Afficher les étapes du job dans l'onglet Détails de l'exécution
- Résoudre les problèmes liés à votre pipeline