La interfaz de supervisión de Dataflow proporciona una representación gráfica de cada trabajo: el gráfico de trabajo. El gráfico de trabajo también proporciona un resumen del trabajo, un registro de trabajo y la información sobre cada paso de la canalización.
Para ver el gráfico de un trabajo, sigue estos pasos:
En la consola de Google Cloud , ve a la página Trabajos de Dataflow >.
Selecciona un trabajo.
Haz clic en la pestaña Gráfico de trabajo.
De forma predeterminada, la página del gráfico del trabajo muestra la Vista de gráfico. Para ver el gráfico del trabajo como una tabla, en Vista de los pasos del trabajo, selecciona Vista de tabla. La vista de tabla contiene la misma información en un formato diferente. La vista de tabla es útil en las siguientes situaciones:
- Tu trabajo tiene muchas etapas, lo que dificulta navegar por el gráfico del trabajo.
- Quieres ordenar los pasos del trabajo por una propiedad específica. Por ejemplo, puedes ordenar la tabla por tiempo para identificar los pasos lentos.
Vista de gráfico
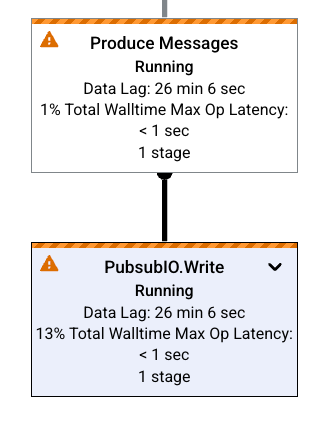
El gráfico de trabajo representa cada transformación de la canalización como un cuadro. En la siguiente imagen, se muestra un gráfico de trabajo con tres transformaciones: Read PubSub Events, 5m Window y Write File(s).

Cada cuadro contiene la siguiente información:
Estado, uno de los siguientes:
- En ejecución: El paso se está ejecutando.
- En cola: El paso en un trabajo de FlexRS está en cola.
- Finalizado de manera correcta: El paso finalizó correctamente.
- Detenido: El paso se detuvo porque el trabajo se detuvo.
- Desconocido: No se pudo informar el estado del paso.
- Con errores: No se pudo completar el paso.
Cantidad de etapas del trabajo que ejecutan este paso
Si un paso representa una transformación compuesta, puedes expandirlo para ver las subtransformaciones. Para expandir el paso, haz clic en la flecha Expandir nodo.
Transforma nombres
Dataflow tiene varias maneras de obtener el nombre de la transformación que se muestra en el gráfico de trabajo de supervisión. Los nombres de transformación se usan en lugares visibles de forma pública, incluida la interfaz de supervisión de Dataflow, los archivos de registro y las herramientas de depuración. No uses nombres de transformación que incluyan información de identificación personal, como nombres de usuario o de organizaciones.
Java
- Dataflow puede usar un nombre que asignas cuando aplicas tu transformación. El primer argumento que proporcionas al método
applyes el nombre de tu transformación. - Dataflow puede inferir el nombre de la transformación, ya sea a partir del nombre de la clase (si creaste una transformación personalizada) o del nombre de tu objeto de función
DoFn(si usas una transformación central comoParDo).
Python
- Dataflow puede usar un nombre que asignas cuando aplicas tu transformación. Para establecer el nombre de transformación, debes especificar el argumento
label. - Dataflow puede inferir el nombre de la transformación, ya sea a partir del nombre de la clase (si creaste una transformación personalizada) o del nombre de tu objeto de función
DoFn(si usas una transformación central comoParDo).
Go
- Dataflow puede usar un nombre que asignas cuando aplicas tu transformación. Para establecer el nombre de transformación, debes especificar el
Scope. - Dataflow puede inferir el nombre de la transformación, ya sea a partir del nombre de la estructura si usas una
DoFnestructural o del nombre de la función si usas una función funcionalDoFn.
Cómo ver la información del paso
Cuando haces clic en un paso del gráfico de trabajo, el panel Información del paso muestra más detalles sobre el paso. Para obtener más información, consulta Información del paso del trabajo.
Cuellos de botella
Si Dataflow detecta un cuello de botella, el gráfico del trabajo muestra un símbolo de alerta en los pasos afectados. Para ver la causa del cuello de botella, haz clic en el paso para abrir el panel Información del paso. Para obtener más información, consulta Cómo solucionar problemas de cuellos de botella.
Ejemplos de gráficos de trabajos
En esta sección, se muestran algunos ejemplos de código de canalización y los gráficos de trabajos correspondientes.
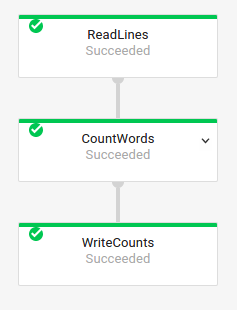
Gráfico de trabajo básico
Código de canalización:Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
Gráfico del trabajo:
|
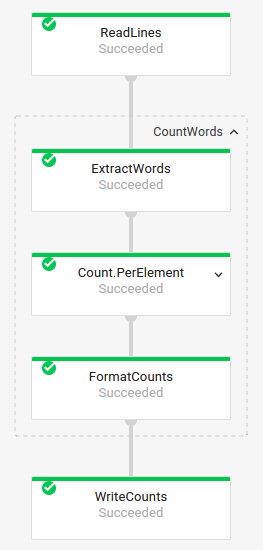
Gráfico de trabajo con transformaciones compuestas
Las transformaciones compuestas son transformaciones que contienen varias subtransformaciones anidadas. En el gráfico de trabajo, las transformaciones compuestas son expandibles. Para expandir la transformación y ver las subtransformaciones, haz clic en la flecha.
Código de canalización:Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
Gráfico del trabajo:
|
En el código de tu canalización, es posible que uses el siguiente código para invocar la transformación compuesta:
result = transform.apply(input);
Las transformaciones compuestas invocadas de esta manera omiten el anidamiento esperado y pueden aparecer expandidas en la interfaz de supervisión de Dataflow. Tu canalización también puede generar advertencias o errores sobre nombres de usuario únicos en el tiempo de ejecución de la canalización.
Para evitar estos problemas, invoca tus transformaciones con el formato recomendado:
result = input.apply(transform);
¿Qué sigue?
- Ver información detallada sobre los pasos del trabajo
- Cómo ver las etapas del trabajo en la pestaña Detalles de la ejecución
- Soluciona problemas de tu canalización