Dataflow 监控界面可提供每个作业的图形表示:即作业图。作业图还可提供作业摘要、作业日志以及流水线中每个步骤的相关信息。
如需查看作业的作业图,请执行以下步骤:
在 Google Cloud 控制台中,依次前往 Dataflow > 作业页面。
选择一个作业。
点击作业图标签页。
默认情况下,作业图页面会显示图表视图。如需以表形式查看作业图,请在作业步骤视图中选择表视图。表视图以不同的格式包含相同的信息。表视图在以下场景中非常有用:
- 您的作业有许多阶段,使作业图难以浏览。
- 您希望按特定属性对作业步骤进行排序。例如,您可以按实际用时对表进行排序,以识别速度缓慢的步骤。
图表视图
在作业图中,流水线中的每个转换以方框的形式进行表示。下图显示了一个包含三个转换的作业图:Read PubSub Events、5m Window 和 Write File(s)。
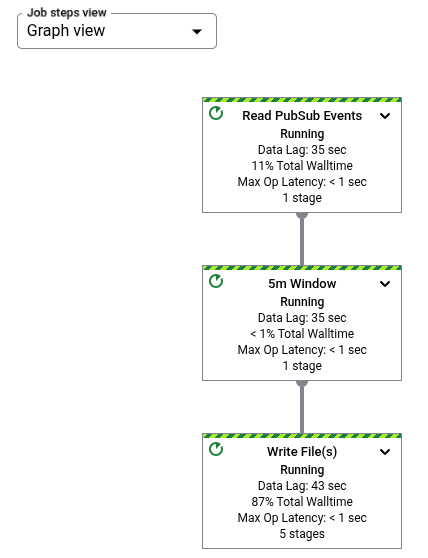
每个方框都包含以下信息:
状态;以下各项之一:
- 正在运行:该步骤正在运行
- 已加入队列:FlexRS 作业中的步骤已加入队列
- 成功:该步骤已成功完成
- 已停止:由于作业停止,该步骤已停止
- 未知:该步骤未能报告状态
- 失败:该步骤未能完成
执行此步骤的作业阶段数量
如果某个步骤表示复合转换,您可以展开该步骤以查看子转换。如需展开相应步骤,请点击 展开节点箭头。
转换名称
Dataflow 可通过几种不同的方式来获取监控作业图中显示的转换名称。 转换名称用于公开可见的位置,包括 Dataflow 监控界面、日志文件和调试工具。请勿使用包含个人身份信息(例如用户名或组织名称)的转换名称。
Java
- Dataflow 可以使用您在应用转换时分配的名称。您为
apply方法提供的第一个参数将作为转换名称。 - Dataflow 可以推断转换名称:根据类名称(如果您构建自定义转换)或
DoFn函数对象的名称(如果您使用ParDo等核心转换)进行推断。
Python
- Dataflow 可以使用您在应用转换时分配的名称。您可以通过指定转换的
label参数设置转换名称。 - Dataflow 可以推断转换名称:根据类名称(如果您构建自定义转换)或
DoFn函数对象的名称(如果您使用ParDo等核心转换)进行推断。
Go
- Dataflow 可以使用您在应用转换时分配的名称。您可以通过指定
Scope来设置转换名称。 - Dataflow 可以推断转换名称:根据结构体名称(如果您使用结构体
DoFn)或函数名称(如果您使用函数DoFn)进行推断。
查看步骤信息
点击作业图中的某个步骤时,步骤信息面板会显示有关该步骤的更多详细信息。如需了解详情,请参阅作业步骤信息。
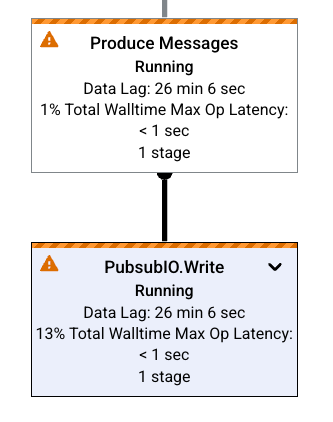
瓶颈
如果 Dataflow 检测到瓶颈,作业图会在受影响的步骤上显示 提醒符号。如需查看瓶颈的原因,请点击相应步骤以打开步骤信息面板。如需了解详情,请参阅排查瓶颈问题。
作业图示例
本部分展示了一些示例流水线代码和相应的作业图。
基本作业图
流水线代码:
Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
作业图:
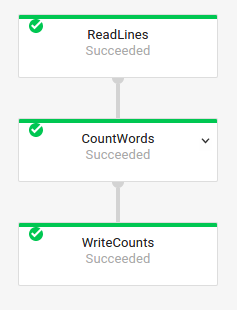
|
包含复合转换的作业图
复合转换是指包含多个嵌套子转换的转换。在作业图中,您可以展开复合转换。如需展开转换并查看子转换,请点击箭头。
流水线代码:
Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
作业图:
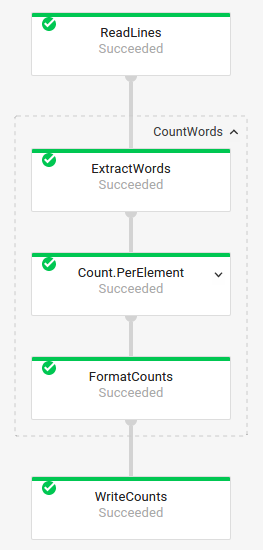
|
在流水线代码中,您可以使用以下代码来调用复合转换:
result = transform.apply(input);
以这种方式调用的复合转换会省略预期的嵌套,可能会在 Dataflow 监控界面中显示为展开状态。您的流水线在执行时,也可能会产生与固定的唯一名称有关的警告或错误。
如需避免这些问题,请使用建议的格式调用转换:
result = input.apply(transform);