작업 빌더는 Google Cloud 콘솔에서 코드를 작성하지 않고 Dataflow 파이프라인을 빌드하고 실행할 수 있는 시각적 UI입니다.
다음 이미지에서는 작업 빌더 UI의 세부정보를 보여줍니다. 이 이미지에서 사용자는 Pub/Sub에서 BigQuery로 읽을 파이프라인을 만들고 있습니다.

개요
작업 빌더는 다음 유형의 데이터를 읽고 쓸 수 있습니다.
- Pub/Sub 메시지
- BigQuery 테이블 데이터
- Cloud Storage의 CSV 파일, JSON 파일, 텍스트 파일
- PostgreSQL, MySQL, Oracle, SQL Server 테이블 데이터
필터, 매핑, SQL, 그룹화, 조인, 분할(배열 평탄화)을 포함한 파이프라인 변환을 지원합니다.
작업 빌더를 사용하면 다음을 수행할 수 있습니다.
- 변환 및 기간 지정 집계를 사용하여 Pub/Sub에서 BigQuery로 스트리밍
- Cloud Storage에서 BigQuery로 데이터 쓰기
- 오류 처리를 사용하여 오류 데이터 필터링(데드 레터 큐)
- SQL 변환을 사용하여 SQL로 데이터 조작 또는 집계
- 매핑 변환을 사용하여 데이터에서 필드 추가, 수정 또는 삭제
- 반복 일괄 작업 예약
작업 빌더는 파이프라인을 Apache Beam YAML 파일로 저장하고 Beam YAML 파일에서 파이프라인 정의를 로드할 수도 있습니다. 이 기능을 사용하면 작업 빌더에서 파이프라인을 설계한 후 재사용할 수 있도록 YAML 파일을 Cloud Storage 또는 소스 제어 저장소에 저장할 수 있습니다. YAML 작업 정의를 사용하여 gcloud CLI를 통해 작업을 실행할 수도 있습니다.
다음과 같은 사용 사례에 작업 빌더를 사용하는 것이 좋습니다.
- 코드를 작성하지 않고도 파이프라인을 빠르게 빌드하려는 경우
- 재사용할 수 있도록 파이프라인을 YAML에 저장하려는 경우
- 지원되는 소스, 싱크, 변환을 사용하여 파이프라인을 표현할 수 있는 경우
- 사용 사례에 맞는 Google 제공 템플릿이 없는 경우
샘플 작업 실행
단어 수 예시는 Cloud Storage에서 텍스트를 읽고, 텍스트 줄을 개별 단어로 토큰화하고, 각 단어의 출현 빈도를 세는 일괄 파이프라인입니다.
Cloud Storage 버킷이 서비스 경계 외부에 있으면 버킷에 대한 액세스를 허용하는 이그레스 규칙을 만듭니다.
단어 수 파이프라인을 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 작업 페이지로 이동합니다.
템플릿에서 작업 만들기를 클릭합니다.
측면 창에서 작업 빌더를 클릭합니다.
청사진 로드를 클릭합니다.
단어 수를 클릭합니다. 작업 빌더가 파이프라인의 그래픽 표현으로 채워집니다.
각 파이프라인 단계에서 작업 빌더는 해당 단계의 구성 파라미터를 지정하는 카드를 표시합니다. 예를 들어 첫 번째 단계에서는 Cloud Storage에서 텍스트 파일을 읽습니다. 소스 데이터의 위치는 텍스트 위치 상자에 자동 입력됩니다.
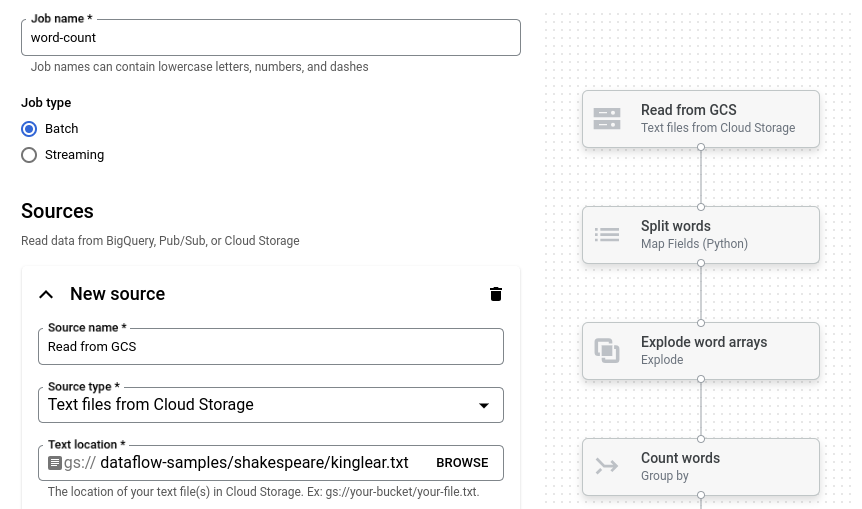
새 싱크라고 제목이 지정된 카드를 찾습니다. 스크롤해야 할 수도 있습니다.
텍스트 위치 상자에 출력 텍스트 파일의 Cloud Storage 위치 경로 프리픽스를 입력합니다.
작업 실행을 클릭합니다. 작업 빌더에서 Dataflow 작업을 만든 후 작업 그래프로 이동합니다. 작업이 시작되면 작업 그래프에 파이프라인의 그래픽 표현이 표시됩니다. 이 그래프 표현은 작업 빌더에 표시된 그래프 표현과 유사합니다. 파이프라인의 각 단계가 실행되면 작업 그래프에서 상태가 업데이트됩니다.
작업 정보 패널에는 작업의 전체 상태가 표시됩니다. 작업이 성공적으로 완료되면 작업 상태 필드가 Succeeded로 업데이트됩니다.
다음 단계
- Dataflow 작업 모니터링 인터페이스 사용
- 작업 빌더에서 커스텀 작업 만들기
- 작업 빌더에서 YAML 작업 정의 저장 및 로드
- Beam YAML 자세히 알아보기