Mantieni tutto organizzato con le raccolte
Salva e classifica i contenuti in base alle tue preferenze.
Il generatore di job è una UI visiva per creare ed eseguire pipeline Dataflow nella console Google Cloud , senza scrivere codice.
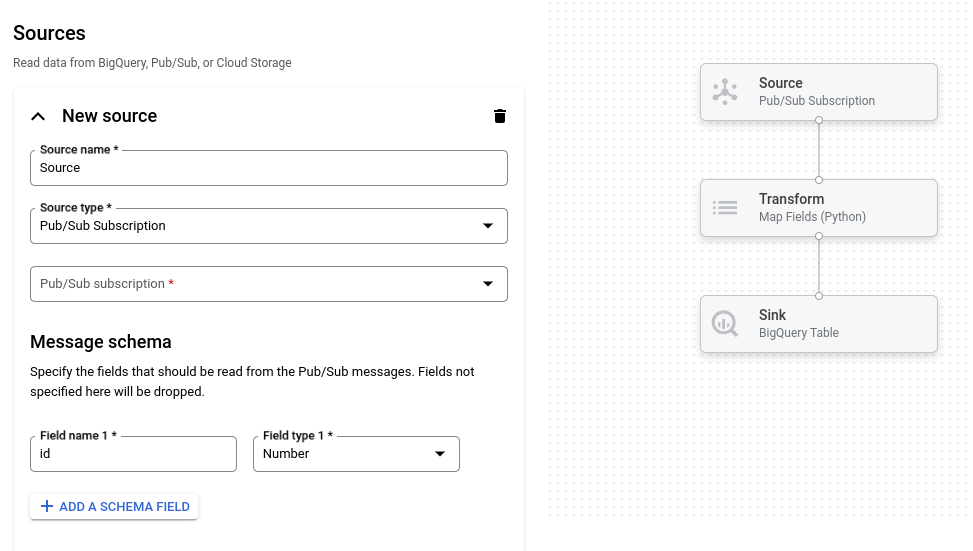
L'immagine seguente mostra un dettaglio della UI del generatore di job. In questa immagine, l'utente sta creando una pipeline per leggere da Pub/Sub a BigQuery:
Panoramica
Lo strumento per la creazione dei job supporta la lettura e la scrittura dei seguenti tipi di dati:
Messaggi Pub/Sub
Dati della tabella BigQuery
File CSV, file JSON e file di testo in Cloud Storage
Dati delle tabelle PostgreSQL, MySQL, Oracle e SQL Server
Supporta le trasformazioni della pipeline, tra cui filtro, mappa, SQL, raggruppamento, unione ed espansione (appiattimento dell'array).
Con il builder dedicato puoi:
Trasmetti flussi da Pub/Sub a BigQuery con trasformazioni e aggregazione in finestre
Scrivere dati da Cloud Storage a BigQuery
Utilizzare la gestione degli errori per filtrare i dati errati (coda dei messaggi non recapitabili)
Manipolare o aggregare i dati utilizzando SQL con la trasformazione SQL
Aggiungere, modificare o eliminare campi dai dati con le trasformazioni di mappatura
Pianificare job batch ricorrenti
Il builder dei job può anche salvare le pipeline come file Apache Beam YAML e caricare le definizioni delle pipeline dai file Beam YAML. Utilizzando questa funzionalità, puoi progettare la pipeline nel builder di job
e poi archiviare il file YAML in Cloud Storage o in un repository di controllo del codice sorgente
per riutilizzarlo. Le definizioni dei job YAML possono essere utilizzate anche per avviare i job utilizzando gcloud CLI.
Prendi in considerazione lo strumento di creazione dei job per i seguenti casi d'uso:
Vuoi creare una pipeline rapidamente senza scrivere codice.
Vuoi salvare una pipeline in YAML per riutilizzarla.
La pipeline può essere espressa utilizzando le origini, i sink e le trasformazioni supportati.
L'esempio di conteggio delle parole è una pipeline batch che legge il testo da Cloud Storage, tokenizza le righe di testo in parole singole ed esegue un conteggio della frequenza per ciascuna parola.
Nel riquadro laterale, fai clic su editGeneratore di job.
Fai clic su Carica progettiexpand_more.
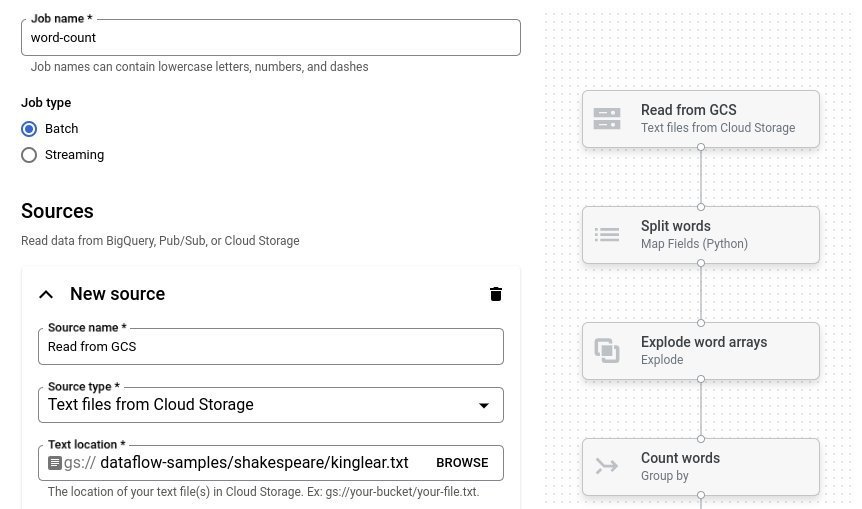
Fai clic su Conteggio parole. Il builder dedicato viene compilato con una rappresentazione
grafica della pipeline.
Per ogni passaggio della pipeline, il generatore di job mostra una scheda che specifica i
parametri di configurazione per quel passaggio. Ad esempio, il primo passaggio legge
i file di testo da Cloud Storage. La posizione dei dati di origine è
precompilata nella casella Posizione testo.
Individua la scheda intitolata Nuovo lavello. Potrebbe essere necessario scorrere.
Nella casella Posizione del testo, inserisci il prefisso del percorso della posizione di Cloud Storage per i file di testo di output.
Fai clic su Esegui job. Il generatore di job crea un job Dataflow e poi
passa al grafico del job. Quando il job
inizia, il grafico del job mostra una rappresentazione grafica della pipeline. Questa
rappresentazione del grafico è simile a quella mostrata nel generatore di job. Man mano che ogni
passaggio della pipeline viene eseguito, lo stato viene aggiornato nel grafico dei job.
Il riquadro Informazioni job mostra lo stato generale del job. Se il job viene completato
correttamente, il campo Stato job viene aggiornato a Succeeded.
[[["Facile da capire","easyToUnderstand","thumb-up"],["Il problema è stato risolto","solvedMyProblem","thumb-up"],["Altra","otherUp","thumb-up"]],[["Difficile da capire","hardToUnderstand","thumb-down"],["Informazioni o codice di esempio errati","incorrectInformationOrSampleCode","thumb-down"],["Mancano le informazioni o gli esempi di cui ho bisogno","missingTheInformationSamplesINeed","thumb-down"],["Problema di traduzione","translationIssue","thumb-down"],["Altra","otherDown","thumb-down"]],["Ultimo aggiornamento 2025-09-10 UTC."],[[["\u003cp\u003eThe Job Builder is a visual, code-free UI in the Google Cloud console for building and running Dataflow pipelines.\u003c/p\u003e\n"],["\u003cp\u003eThe Job Builder supports various data sources (Pub/Sub, BigQuery, Cloud Storage files), sinks, and transforms (filter, join, map, group-by, explode).\u003c/p\u003e\n"],["\u003cp\u003ePipelines built in the Job Builder can be saved as Apache Beam YAML files for reuse, storage, or modification.\u003c/p\u003e\n"],["\u003cp\u003eUsers can validate their pipelines for syntax errors before launching using the built-in validation feature, which will look for issues with Python filters or SQL expressions.\u003c/p\u003e\n"],["\u003cp\u003eUsers can create new batch or streaming pipelines, adding sources, transforms and sinks as desired, then run or save it for later.\u003c/p\u003e\n"]]],[],null,["The job builder is a visual UI for building and running Dataflow\npipelines in the Google Cloud console, without writing code.\n\nThe following image shows a detail from the job builder UI. In this image, the\nuser is creating a pipeline to read from Pub/Sub to BigQuery:\n\nOverview\n\nThe job builder supports reading and writing the following types of data:\n\n- Pub/Sub messages\n- BigQuery table data\n- CSV files, JSON files, and text files in Cloud Storage\n- PostgreSQL, MySQL, Oracle, and SQL Server table data\n\nIt supports pipeline transforms including filter, map, SQL, group-by, join, and explode (array flatten).\n\nWith the job builder you can:\n\n- Stream from Pub/Sub to BigQuery with transforms and windowed aggregation\n- Write data from Cloud Storage to BigQuery\n- Use error handling to filter erroneous data (dead-letter queue)\n- Manipulate or aggregate data using SQL with the SQL transform\n- Add, modify, or drop fields from data with mapping transforms\n- Schedule recurring batch jobs\n\nThe job builder can also save pipelines as\n[Apache Beam YAML](https://beam.apache.org/documentation/sdks/yaml/)\nfiles and load pipeline definitions from Beam YAML files. By using this feature, you can design your pipeline in the job builder\nand then store the YAML file in Cloud Storage or a source control repository\nfor reuse. YAML job definitions can also be used to launch jobs using the gcloud CLI.\n\nConsider the job builder for the following use cases:\n\n- You want to build a pipeline quickly without writing code.\n- You want to save a pipeline to YAML for re-use.\n- Your pipeline can be expressed using the supported sources, sinks, and transforms.\n- There is no [Google-provided template](/dataflow/docs/guides/templates/provided-templates) that matches your use case.\n\nRun a sample job\n\nThe Word Count example is a batch pipeline that reads text from Cloud Storage, tokenizes the text lines into individual words, and performs a frequency count on each of the words.\n\nIf the Cloud Storage bucket is outside of your [service perimeter](/vpc-service-controls/docs/overview), create an [egress rule](/vpc-service-controls/docs/ingress-egress-rules) that allows access to the bucket.\n\nTo run the Word Count pipeline, follow these steps:\n\n1. Go to the **Jobs** page in the Google Cloud console.\n\n [Go to Jobs](https://console.cloud.google.com/dataflow)\n2. Click add_box**Create job from\n template**.\n\n3. In the side pane, click edit **Job builder**.\n\n4. Click **Load blueprints** expand_more.\n\n5. Click **Word Count**. The job builder is populated with a graphical\n representation of the pipeline.\n\n For each pipeline step, the job builder displays a card that specifies the\n configuration parameters for that step. For example, the first step reads\n text files from Cloud Storage. The location of the source data is\n pre-populated in the **Text location** box.\n\n1. Locate the card titled **New sink**. You might need to scroll.\n\n2. In the **Text location** box, enter the Cloud Storage location path prefix for the output text files.\n\n3. Click **Run job** . The job builder creates a Dataflow job and then\n navigates to the [job graph](/dataflow/docs/guides/job-graph). When the job\n starts, the job graph shows a graphical representation of the pipeline. This\n graph representation is similar to the one shown in the job builder. As each\n step of the pipeline runs, the status is updated in the job graph.\n\nThe **Job info** panel shows the overall status of the job. If the job completes\nsuccessfully, the **Job status** field updates to `Succeeded`.\n\nWhat's next\n\n- [Use the Dataflow job monitoring interface](/dataflow/docs/guides/monitoring-overview).\n- [Create a custom job](/dataflow/docs/guides/job-builder-custom-job) in the job builder.\n- [Save and load](/dataflow/docs/guides/job-builder-save-load-yaml) YAML job definitions in the job builder.\n- Learn more about [Beam YAML](https://beam.apache.org/documentation/sdks/yaml/)."]]