O criador de tarefas é uma IU visual para criar e executar pipelines do Dataflow na Google Cloud consola, sem escrever código.
A imagem seguinte mostra um detalhe da IU do criador de tarefas. Nesta imagem, o utilizador está a criar um pipeline para ler do Pub/Sub para o BigQuery:

Vista geral
O criador de tarefas suporta a leitura e a escrita dos seguintes tipos de dados:
- Mensagens do Pub/Sub
- Dados da tabela do BigQuery
- Ficheiros CSV, ficheiros JSON e ficheiros de texto no Cloud Storage
- Dados de tabelas do PostgreSQL, MySQL, Oracle e SQL Server
Suporta transformações de pipelines, incluindo filtro, mapa, SQL, agrupamento por, junção e expansão (aplanamento de matriz).
Com o criador de tarefas, pode:
- Faça streaming do Pub/Sub para o BigQuery com transformações e agregação em janelas
- Escreva dados do Cloud Storage para o BigQuery
- Use o processamento de erros para filtrar dados com erros (fila de mensagens rejeitadas)
- Manipule ou agregue dados através de SQL com a transformação SQL
- Adicione, modifique ou elimine campos de dados com transformações de mapeamento
- Agende tarefas em lote recorrentes
O criador de tarefas também pode guardar pipelines como ficheiros YAML do Apache Beam e carregar definições de pipelines a partir de ficheiros YAML do Beam. Ao usar esta funcionalidade, pode criar o seu pipeline no criador de tarefas e, em seguida, armazenar o ficheiro YAML no Cloud Storage ou num repositório de controlo de origem para reutilização. As definições de tarefas YAML também podem ser usadas para iniciar tarefas através da CLI gcloud.
Considere o criador de tarefas para os seguintes exemplos de utilização:
- Quiser criar um pipeline rapidamente sem escrever código.
- Quer guardar um pipeline em YAML para reutilização.
- O seu pipeline pode ser expresso através das origens, dos destinos e das transformações suportados.
- Não existe um modelo fornecido pela Google que corresponda ao seu exemplo de utilização.
Execute uma tarefa de exemplo
O exemplo de contagem de palavras é um pipeline em lote que lê texto do Cloud Storage, tokeniza as linhas de texto em palavras individuais e faz uma contagem de frequência em cada uma das palavras.
Se o contentor do Cloud Storage estiver fora do seu perímetro de serviço, crie uma regra de saída que permita o acesso ao contentor.
Para executar o pipeline de contagem de palavras, siga estes passos:
Aceda à página Tarefas na Google Cloud consola.
Clique em Criar tarefa a partir de um modelo.
No painel lateral, clique em Criador de tarefas.
Clique em Carregar plantas.
Clique em Contagem de palavras. O criador de tarefas é preenchido com uma representação gráfica do pipeline.
Para cada etapa do pipeline, o criador de tarefas apresenta um cartão que especifica os parâmetros de configuração dessa etapa. Por exemplo, o primeiro passo lê ficheiros de texto do Cloud Storage. A localização dos dados de origem é pré-preenchida na caixa Localização do texto.
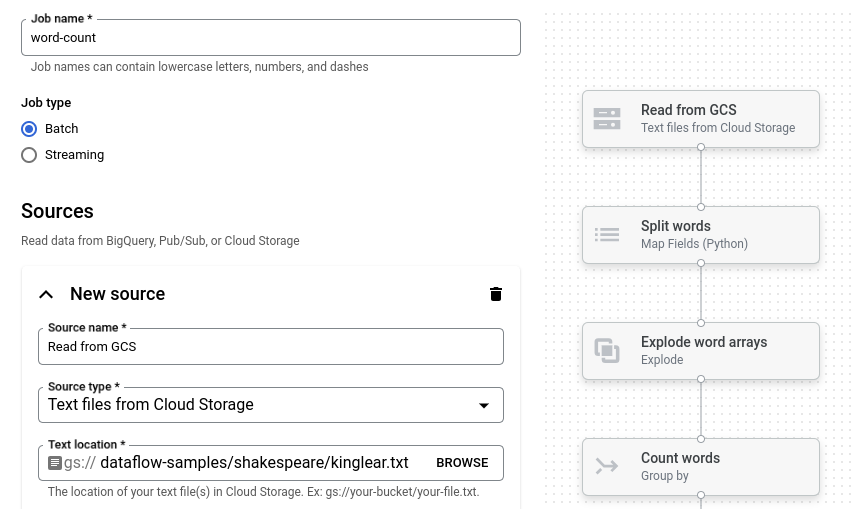
Localize o cartão com o título Novo lava-louça. Pode ter de deslocar a página.
Na caixa Localização do texto, introduza o prefixo do caminho da localização do Cloud Storage para os ficheiros de texto de saída.
Clique em Executar tarefa. O criador de tarefas cria uma tarefa do Dataflow e, em seguida, navega para o gráfico de tarefas. Quando a tarefa é iniciada, o gráfico de tarefas mostra uma representação gráfica do pipeline. Esta representação gráfica é semelhante à apresentada no criador de empregos. À medida que cada passo do pipeline é executado, o estado é atualizado no gráfico de tarefas.
O painel Informações do trabalho mostra o estado geral do trabalho. Se o trabalho for concluído com êxito, o campo Estado do trabalho é atualizado para Succeeded.
O que se segue?
- Use a interface de monitorização de tarefas do Dataflow.
- Crie uma tarefa personalizada no criador de tarefas.
- Guardar e carregar definições de tarefas YAML no criador de tarefas.
- Saiba mais sobre o YAML do Beam.