Führen Sie die folgenden Aufgaben mit dem interaktiven Apache Beam-Runner mit JupyterLab-Notebooks aus:
- Pipelines iterativ entwickeln.
- Pipelinegraph überprüfen.
- Einzelne
PCollectionsin einem REPL-Workflow (Read-Eval-Print-Loop) parsen.
Apache Beam-Notebooks werden über von Nutzern verwaltete Vertex AI Workbench-Notebooks bereitgestellt. Mit diesem Dienst werden virtuelle Notebooks gehostet, die in den neuesten Data-Science-Frameworks und Frameworks für maschinelles Lernen vorinstalliert sind. Dataflow unterstützt nur nutzerverwaltete Notebookinstanzen.
Dieser Leitfaden konzentriert sich auf die von Apache Beam-Notebooks eingeführten Features, zeigt jedoch nicht, wie ein Notebook erstellt wird. Weitere Informationen über Apache Beam finden Sie im Apache Beam-Programmierhandbuch.
Unterstützung und Einschränkungen
- Apache Beam-Notebooks unterstützen nur Python.
- Auf diesen Notebooks ausgeführte Apache Beam-Pipelinesegmente werden in einer Testumgebung und nicht mit einem Apache Beam-Produktions-Runner ausgeführt. Zum Starten der Notebooks im Dataflow-Dienst exportieren Sie die in Ihrem Apache Beam-Notebook erstellten Pipelines. Weitere Informationen finden Sie unter Dataflow-Jobs aus einer in Ihrem Notebook erstellten Pipeline starten.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Bevor Sie Ihre Apache Beam-Notebookinstanz erstellen, aktivieren Sie zusätzliche APIs für Pipelines, die andere Dienste wie Pub/Sub verwenden.
Wenn nicht angegeben, wird die Notebookinstanz vom Compute Engine-Standarddienstkonto mit der IAM-Projektbearbeiterrolle ausgeführt. Wenn das Projekt explizit die Rollen des Dienstkontos beschränkt, müssen Sie dafür sorgen, dass es weiter ausreichende Berechtigungen zum Ausführen der Notebooks hat. Wenn Sie beispielsweise aus einem Pub/Sub-Thema lesen, wird implizit ein Abo erstellt und Ihr Dienstkonto muss eine IAM-Pub/Sub-Bearbeiterrolle haben. Im Gegensatz dazu ist für das Lesen aus einem Pub/Sub-Abo nur eine IAM-Rolle als Pub/Sub-Abonnent erforderlich.
Löschen Sie die erstellten Ressourcen nach Abschluss dieses Leitfadens, um weitere Kosten zu vermeiden. Weitere Informationen finden Sie unter Bereinigen.
Apache Beam-Notebookinstanz starten
Rufen Sie in der Google Cloud Console die Dataflow-Seite Workbench auf.
Achten Sie darauf, dass Sie sich auf dem Tab Nutzerverwaltete Notebooks befinden.
Klicken Sie in der Symbolleiste auf Neu erstellen.
Wählen Sie im Bereich Umgebung unter Umgebung die Option Apache Beam aus.
Optional: Wenn Sie Notebooks auf einer GPU ausführen möchten, wählen Sie im Bereich Maschinentyp einen Maschinentyp aus, der GPUs unterstützt, und wählen Sie dann NVIDIA GPU-Treiber automatisch installieren aus. Weitere Informationen finden Sie unter GPU-Plattformen.
Wählen Sie im Bereich Netzwerk ein Subnetzwerk für die Notebook-VM aus.
Optional: Wenn Sie eine benutzerdefinierte Notebookinstanz einrichten möchten, finden Sie weitere Informationen unter Nutzerverwaltete Notebookinstanz mit bestimmten Attributen erstellen.
Klicken Sie auf Erstellen. Dataflow Workbench erstellt eine neue Apache Beam-Notebookinstanz.
Nachdem die Notebookinstanz erstellt wurde, wird der Link JupyterLab öffnen aktiviert. Klicken Sie auf OPEN JUPYTERLAB (JUPYTERLAB ÖFFNEN).
Optional: Abhängigkeiten installieren
Apache Beam-Notebooks enthalten bereits Connector-Abhängigkeiten für Apache Beam und Google Cloud. Wenn Ihre Pipeline benutzerdefinierte Connectors oder benutzerdefinierte PTransforms enthält, die von Drittanbieterbibliotheken abhängen, installieren Sie diese nach dem Erstellen einer Notebookinstanz. Weitere Informationen finden Sie unter Abhängigkeiten installieren in der Dokumentation zu nutzerverwalteten Notebooks.
Beispiel-Apache Beam-Notebooks
Nachdem Sie eine nutzerverwaltete Notebookinstanz erstellt haben, öffnen Sie sie in JupyterLab. Auf dem Tab Dateien in der JupyterLab-Seitenleiste enthält der Ordner Beispiele Beispielnotebooks. Weitere Informationen zur Arbeit mit JupyterLab-Dateien finden Sie im JupyterLab-Nutzerhandbuch unter Dateien verwenden.
Folgende Notebooks sind verfügbar:
- Word Count
- Streaming Word Count
- Streaming NYC Taxi Ride Data
- Apache Beam SQL in Notebooks mit Vergleichen zu Pipelines
- Apache Beam SQL in Notebooks mit dem Dataflow Runner
- Apache Beam SQL in Notebooks
- Dataflow Word Count
- Interaktives Flink im großen Maßstab
- RunInference
- GPUs mit Apache Beam verwenden
- Daten visualisieren
Der Ordner Anleitungen enthält weitere Anleitungen zu den Grundlagen von Apache Beam. Folgende Anleitungen sind verfügbar:
- Grundlegende Vorgänge
- Elementartige Vorgänge
- Zusammenfassungen
- Windows
- E/A-Vorgänge
- Streaming
- Abschließende Übungen
Diese Notebooks enthalten erläuternden Text und kommentierte Codeblöcke, damit Sie die Konzepte und die API-Nutzung von Apache Beam besser verstehen. Die Anleitungen enthalten auch Übungen, mit denen Sie die Konzepte üben können.
In den folgenden Abschnitten wird Beispielcode aus dem Notebook „Streaming Word Count“ verwendet. Die Code-Snippets in diesem Leitfaden und die Angaben im Notebook „Streaming Word Count“ können geringfügige Diskrepanzen aufweisen.
Eine Notebook-Instanz erstellen
Wählen Sie unter Datei > Neu > Notebook den Kernel Apache Beam 2.22 oder höher aus.
Apache Beam-Notebooks basieren auf dem Masterzweig des Apache Beam SDK. Dies bedeutet, dass die neueste Version des Kernels, die auf der Notebook-Benutzeroberfläche angezeigt wird, möglicherweise der neuesten Releaseversion des SDK voraus ist.
Apache Beam ist auf Ihrer Notebookinstanz installiert. Fügen Sie daher die Module interactive_runner und interactive_beam bei Ihrem Notebook ein.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Wenn Ihr Notebook andere Google APIs verwendet, fügen Sie die folgenden Importanweisungen hinzu:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Interaktivitätsoptionen festlegen
Mit dem folgenden Befehl wird festgelegt, wie lange der InteractiveRunner Daten aus einer unbegrenzten Quelle erfasst. In diesem Beispiel ist die Dauer auf 10 Minuten eingestellt.
ib.options.recording_duration = '10m'
Sie können das Limit der Aufzeichnungsgröße (in Byte) für eine unbegrenzte Quelle auch mit dem Attribut recording_size_limit ändern.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
Weitere Interaktivitätsoptionen finden Sie in der interactive_beam.options-Klasse.
Pipeline erstellen
Initialisieren Sie die Pipeline mit einem InteractiveRunner-Objekt.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
Daten lesen und visualisieren
Das folgende Beispiel zeigt eine Apache Beam-Pipeline, die ein Abo für das angegebene Pub/Sub-Thema erstellt und aus dem Abo liest.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
Die Pipeline zählt die Wörter nach Fenstern aus der Quelle. Sie erstellt feste Fensteraufrufe mit einer Dauer von jeweils 10 Sekunden pro Fenster.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Nachdem die Daten im Fenstermodus angezeigt werden, werden die Wörter pro Fenster gezählt.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
Die Methode show() visualisiert die resultierende PCollection im Notebook.
ib.show(windowed_word_counts, include_window_info=True)
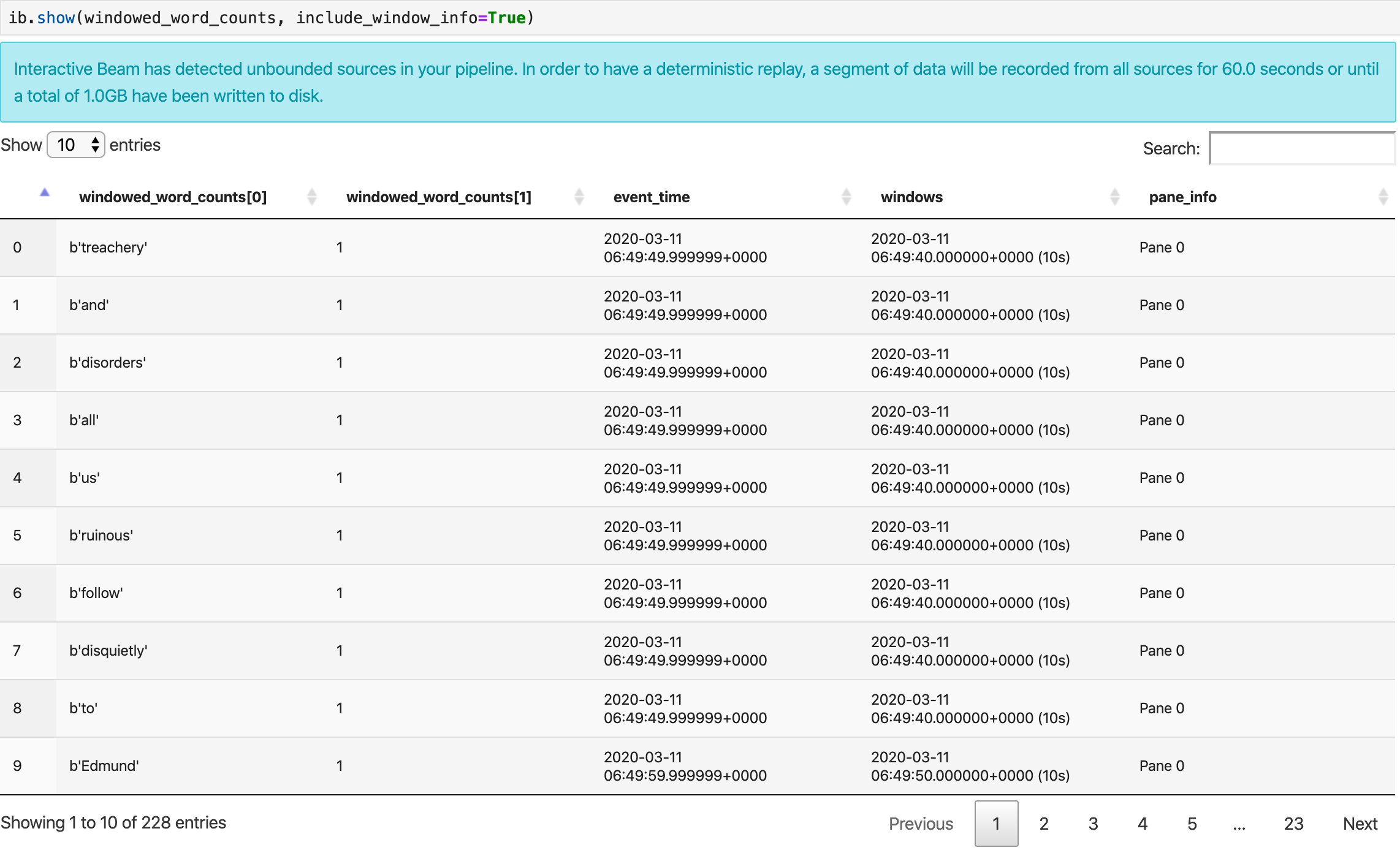
Sie können die Ergebnismenge von show() beschränken, indem Sie zwei optionale Parameter festlegen: n und duration.
- Legen Sie
nfest, um die Ergebnismenge auf maximalnElemente zu beschränken, z. B. 20. Wennnnicht festgelegt ist, werden standardmäßig die neuesten Elemente aufgelistet, die bis zum Ende der Quellaufzeichnung erfasst wurden. - Legen Sie
durationfest, um die Ergebnismenge auf eine bestimmte Anzahl von Sekunden zu begrenzen, beginnend ab dem Start der Quellaufzeichnung. Wenndurationnicht festgelegt ist, werden standardmäßig alle Elemente bis zum Ende der Aufzeichnung aufgelistet.
Wenn beide optionalen Parameter festgelegt sind, wird show() gestoppt, wenn einer der beiden Grenzwerte erreicht ist. Im folgenden Beispiel gibt show() höchstens 20 Elemente zurück, die auf Grundlage der ersten 30 Sekunden Daten aus den aufgezeichneten Quellen berechnet werden.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
Zum Aufrufen von Visualisierungen Ihrer Daten übergeben Sie visualize_data=True an die show()-Methode. Sie können mehrere Filter auf Ihre Visualisierungen anwenden. Mit der folgenden Visualisierung können Sie nach Label und Achse filtern:
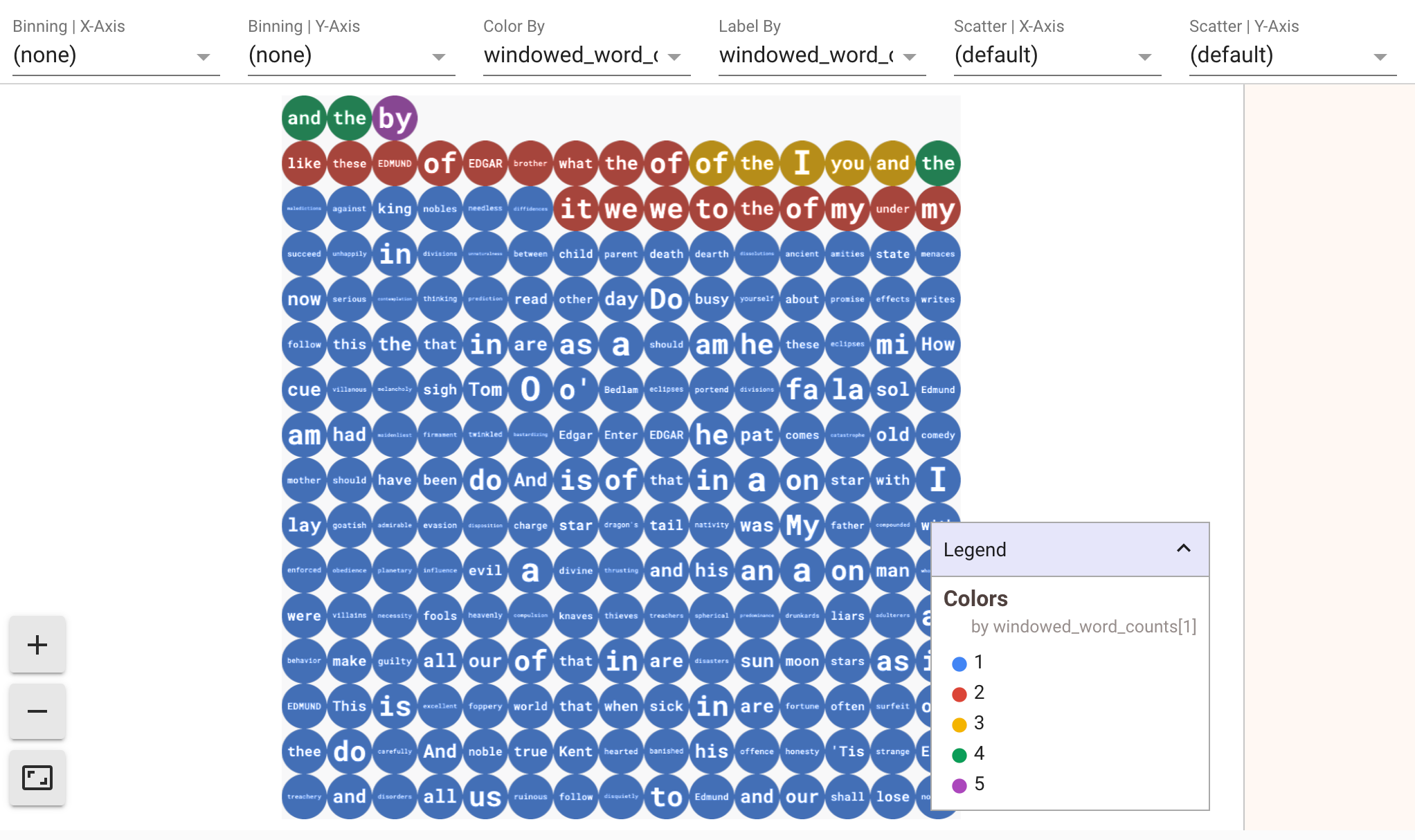
Um die Wiedergabefähigkeit beim Prototyping von Streamingpipelines zu gewährleisten, verwenden die Aufrufe der show()-Methode die erfassten Daten standardmäßig wieder. Wenn Sie dieses Verhalten ändern und die Methode show() immer neue Daten abrufen lassen möchten, legen Sie interactive_beam.options.enable_capture_replay = False fest. Wenn Sie Ihrem Notebook eine zweite unbegrenzte Quelle hinzufügen, werden die Daten der vorherigen unbegrenzten Quelle verworfen.
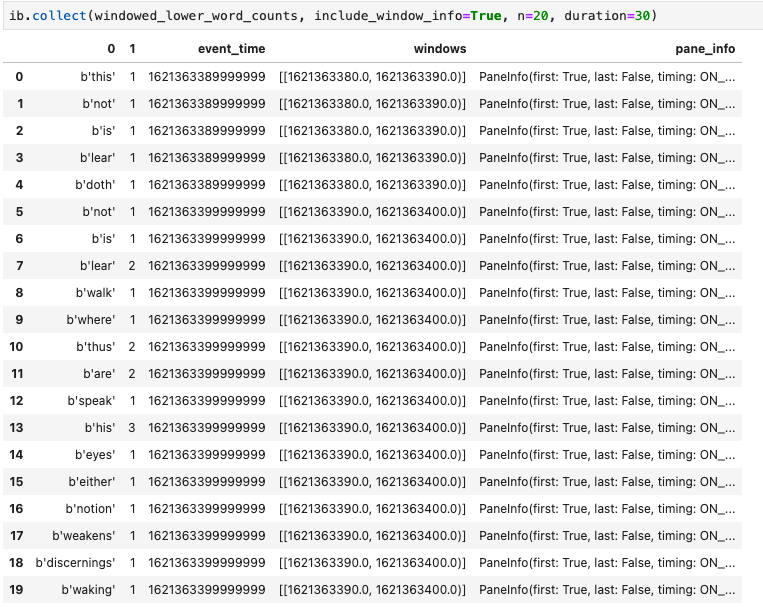
Eine weitere hilfreiche Visualisierung in Apache Beam-Notebooks ist ein Pandas DataFrame. Im folgenden Beispiel werden die Wörter zuerst in Kleinbuchstaben umgewandelt und dann die Häufigkeit jedes Worts berechnet.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
Die collect()-Methode stellt die Ausgabe in einem Pandas-DataFrame bereit.
ib.collect(windowed_lower_word_counts, include_window_info=True)
Das Bearbeiten und wiederholte Ausführen einer Zelle ist eine gängige Praxis in der Notebookentwicklung. Wenn Sie eine Zelle in einem Apache Beam-Notebook bearbeiten und neu ausführen, macht die Zelle die beabsichtigte Aktion des Codes in der ursprünglichen Zelle nicht rückgängig. Wenn eine Zelle beispielsweise einer Pipeline ein PTransform hinzufügt, wird durch das wiederholte Ausführen dieser Zelle der Pipeline ein zusätzliches PTransform hinzugefügt. Wenn Sie den Status löschen möchten, starten Sie den Kernel neu und führen Sie die Zellen noch einmal aus.
Daten mit dem interaktiven Beam-Inspektor visualisieren
Es kann ein Störfaktor sein, die Daten einer PCollection zu untersuchen, indem Sie show() und collect() kontinuierlich aufrufen, insbesondere wenn die Ausgabe einen Großteil des Speicherplatzes auf Ihrem Bildschirm belegt und die Suche im Notebook erschwert. Eventuell möchten Sie auch mehrere PCollections nebeneinander vergleichen, um zu prüfen, ob eine Transformation wie beabsichtigt funktioniert. Beispiel: Ein PCollection durchläuft eine Transformation und erzeugt die andere. Für diese Anwendungsfälle ist der interaktive Beam-Inspektor eine gute Lösung.
Der interaktive Beam-Inspektor wird als JupyterLab-Erweiterung apache-beam-jupyterlab-sidepanel bereitgestellt, die im Apache Beam-Notebook vorinstalliert ist. Mit der Erweiterung können Sie den Status der mit jeder PCollection verknüpften Pipelines und Daten interaktiv prüfen, ohne explizit show() oder collect() aufzurufen.
Es gibt drei Möglichkeiten, den Inspektor zu öffnen:
Klicken Sie in der oberen Menüleiste von JupyterLab auf
Interactive Beam. Suchen Sie im Drop-down-MenüOpen Inspectorund klicken Sie darauf, um den Inspektor zu öffnen.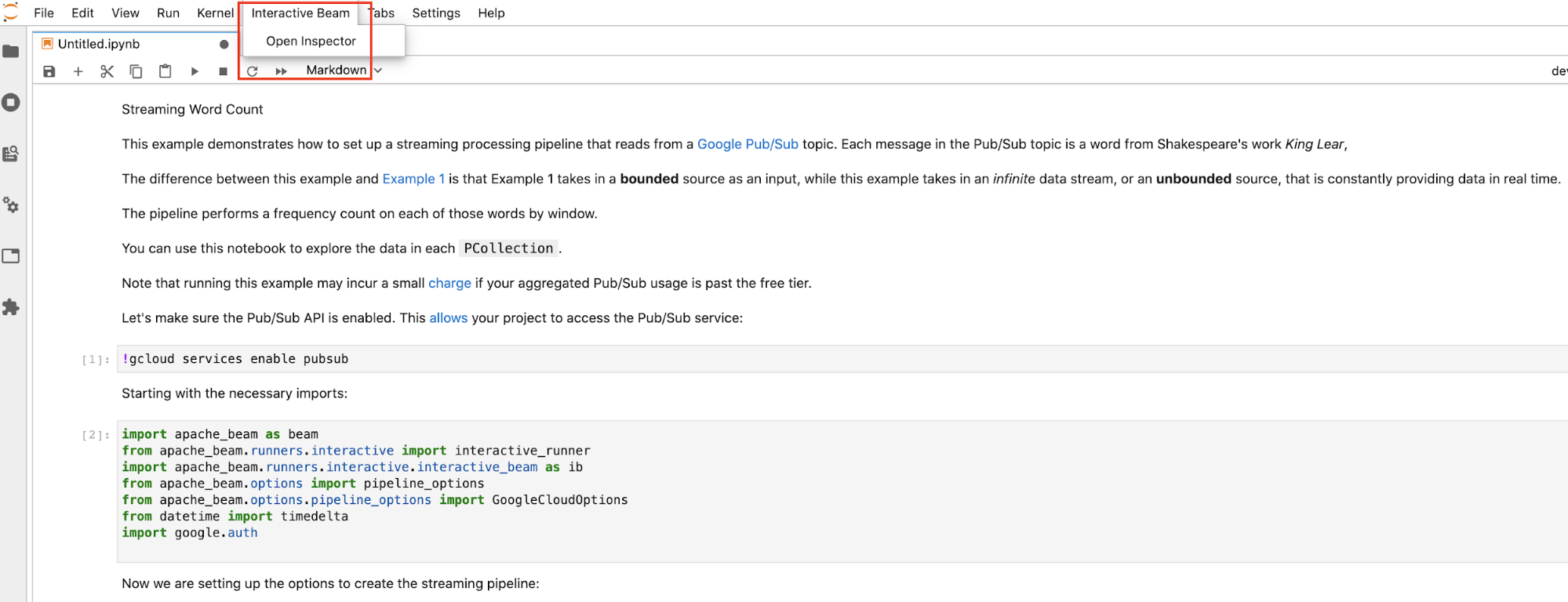
Verwenden Sie die Launcher-Seite. Wenn keine Launcher-Seite geöffnet ist, klicken Sie auf
File->New Launcher, um sie zu öffnen. Suchen Sie auf der Launcher-Seite nachInteractive Beamund klicken Sie aufOpen Inspector, um den Inspektor zu öffnen.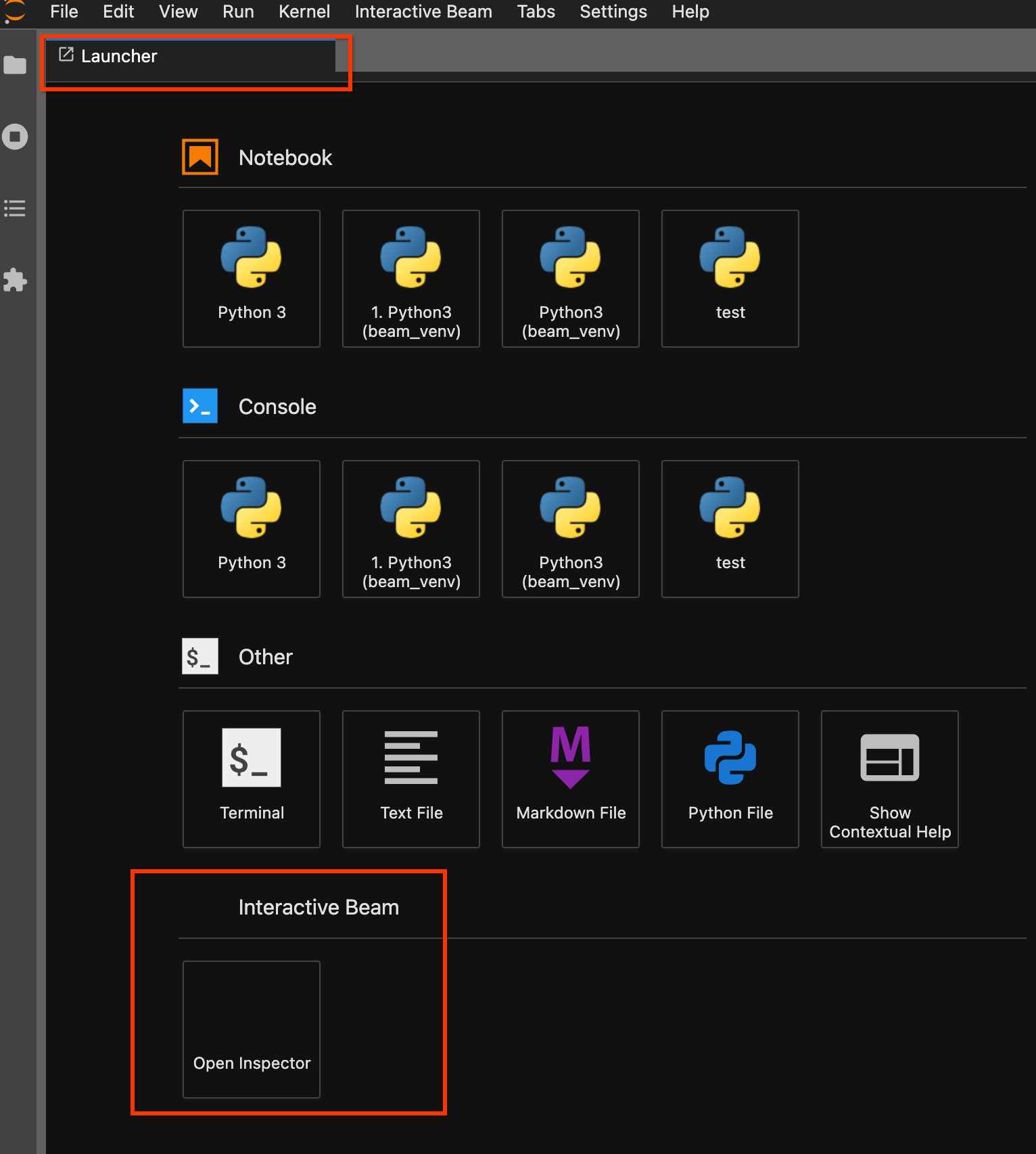
Verwenden Sie die Befehlspalette. Klicken Sie in der JupyterLab-Menüleiste auf
View>Activate Command Palette. Suchen Sie im Dialogfeld nachInteractive Beam, um alle Optionen der Erweiterung aufzulisten. Klicken Sie aufOpen Inspector, um den Inspektor zu öffnen.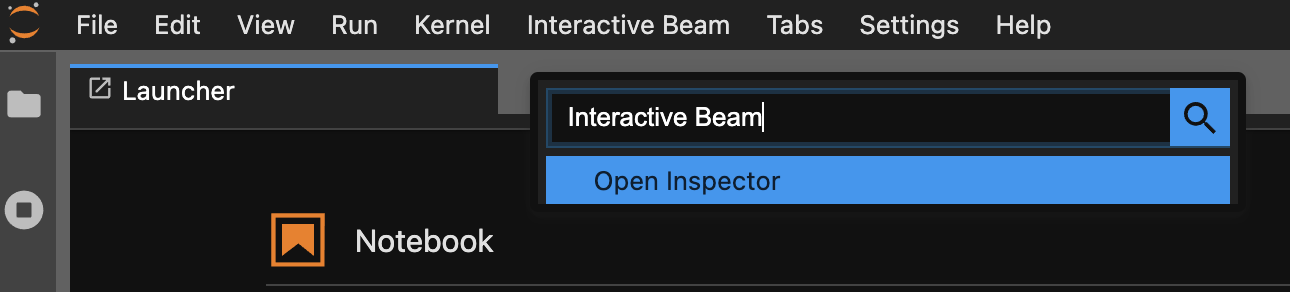
Wenn der Inspektor geöffnet werden soll, gehen Sie so vor:
Wenn genau ein Notebook geöffnet ist, stellt der Inspektor automatisch eine Verbindung zu diesem her.
Wenn kein Notebook geöffnet ist, wird ein Dialogfeld angezeigt, in dem Sie einen Kernel auswählen können.
Wenn mehrere Notebooks geöffnet sind, wird ein Dialogfeld angezeigt, in dem Sie die Notebooksitzung auswählen können.
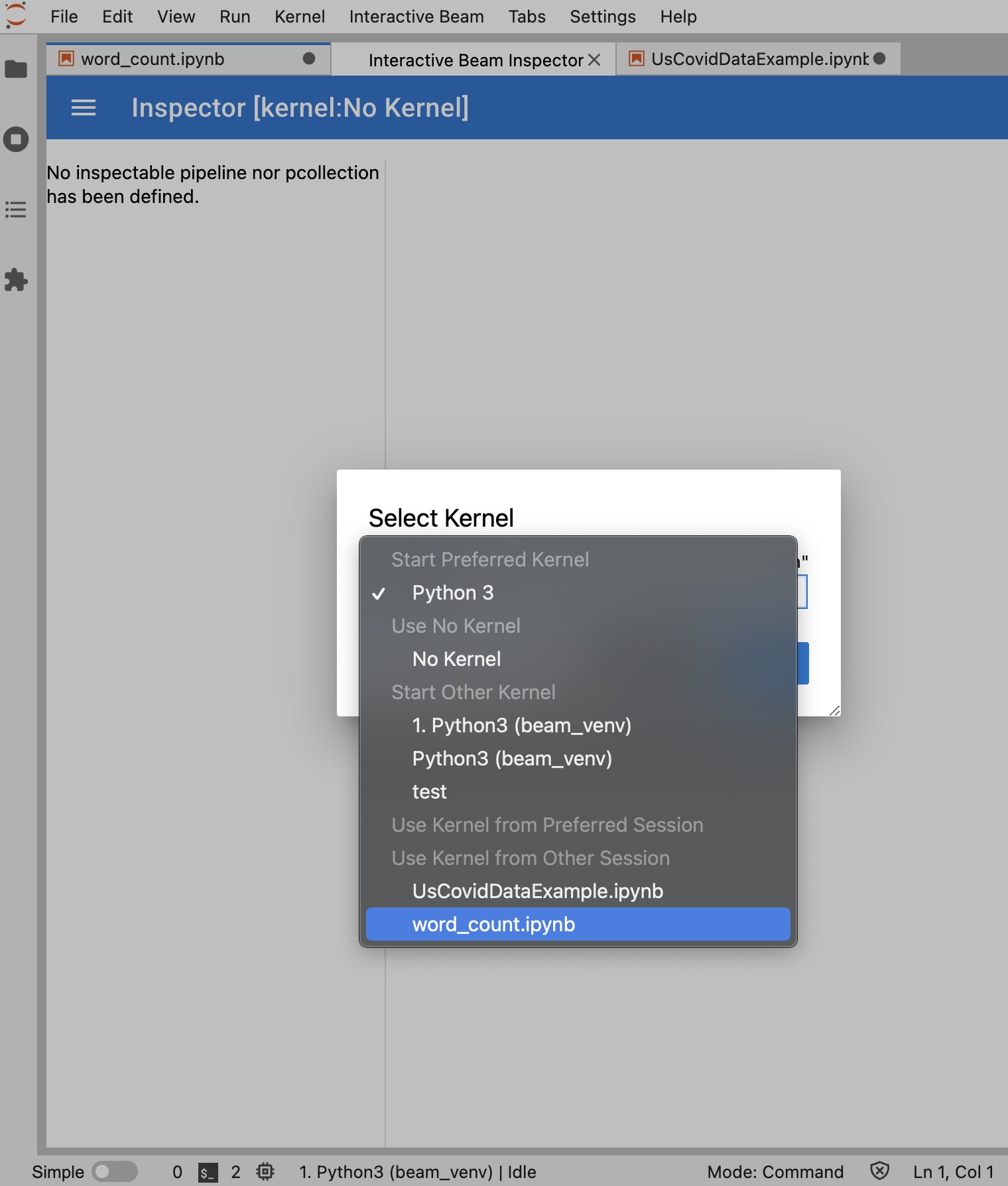
Es wird empfohlen, mindestens ein Notebook zu öffnen und einen Kernel dafür auszuwählen, bevor Sie den Inspektor öffnen. Wenn Sie einen Inspektor mit einem Kernel öffnen, bevor Sie ein Notebook öffnen, müssen Sie später beim Öffnen eines Notebooks zum Herstellen einer Verbindung zum Inspektor eine Interactive Beam Inspector Session unter Use
Kernel from Preferred Session auswählen. Ein Inspektor und ein Notebook sind verbunden, wenn sie dieselbe Sitzung verwenden, nicht verschiedene Sitzungen, die vom selben Kernel erstellt wurden. Wenn Sie denselben Kernel aus Start Preferred Kernel auswählen, wird eine neue Sitzung erstellt, die unabhängig von vorhandenen Sitzungen geöffneter Notebooks oder Inspektoren ist.
Sie können mehrere Inspektoren für ein geöffnetes Notebook öffnen und die Inspektoren anordnen. Dazu ziehen Sie deren Tabs und legen sie frei im Arbeitsbereich ab.
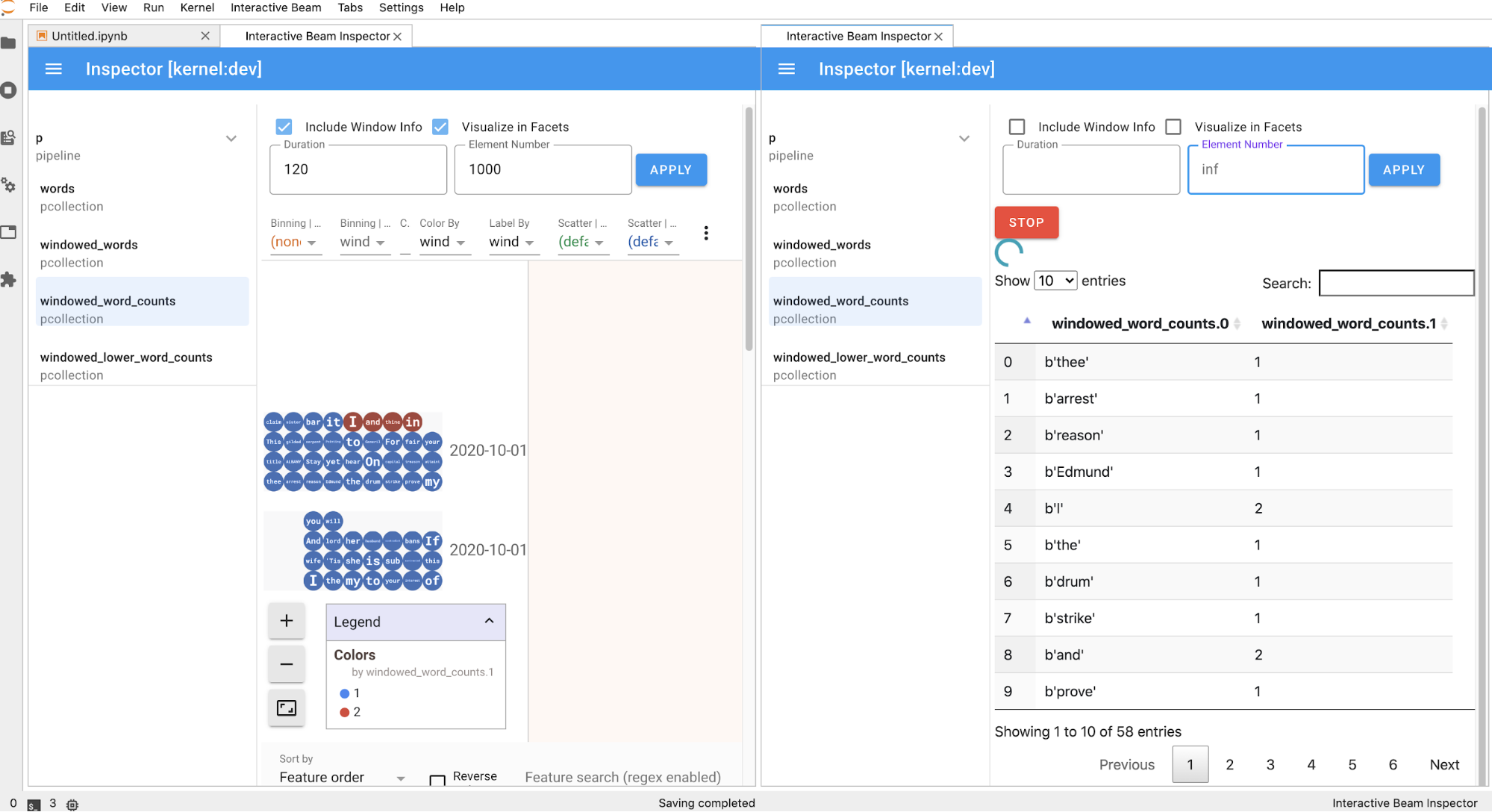
Die Seite „Inspector“ wird automatisch aktualisiert, wenn Sie Zellen im Notebook ausführen. Auf der Seite werden Pipelines und im verbundenen Notebook definierte PCollections aufgelistet. PCollections sind nach den Pipelines organisiert, zu denen sie gehören, und Sie können sie minimieren, indem Sie auf die Headerpipeline klicken.
Für die Elemente in der Pipeline und der PCollections-Liste rendert der Inspektor mit einem Klick die entsprechenden Visualisierungen auf der rechten Seite:
Wenn es sich um eine
PCollectionhandelt, werden die Daten des Inspektors (dynamisch, wenn die Daten noch für unbegrenztePCollectionseingehen) mit zusätzlichen Widgets gerendert, um die Visualisierung nach dem Klicken auf die SchaltflächeAPPLYzu optimieren.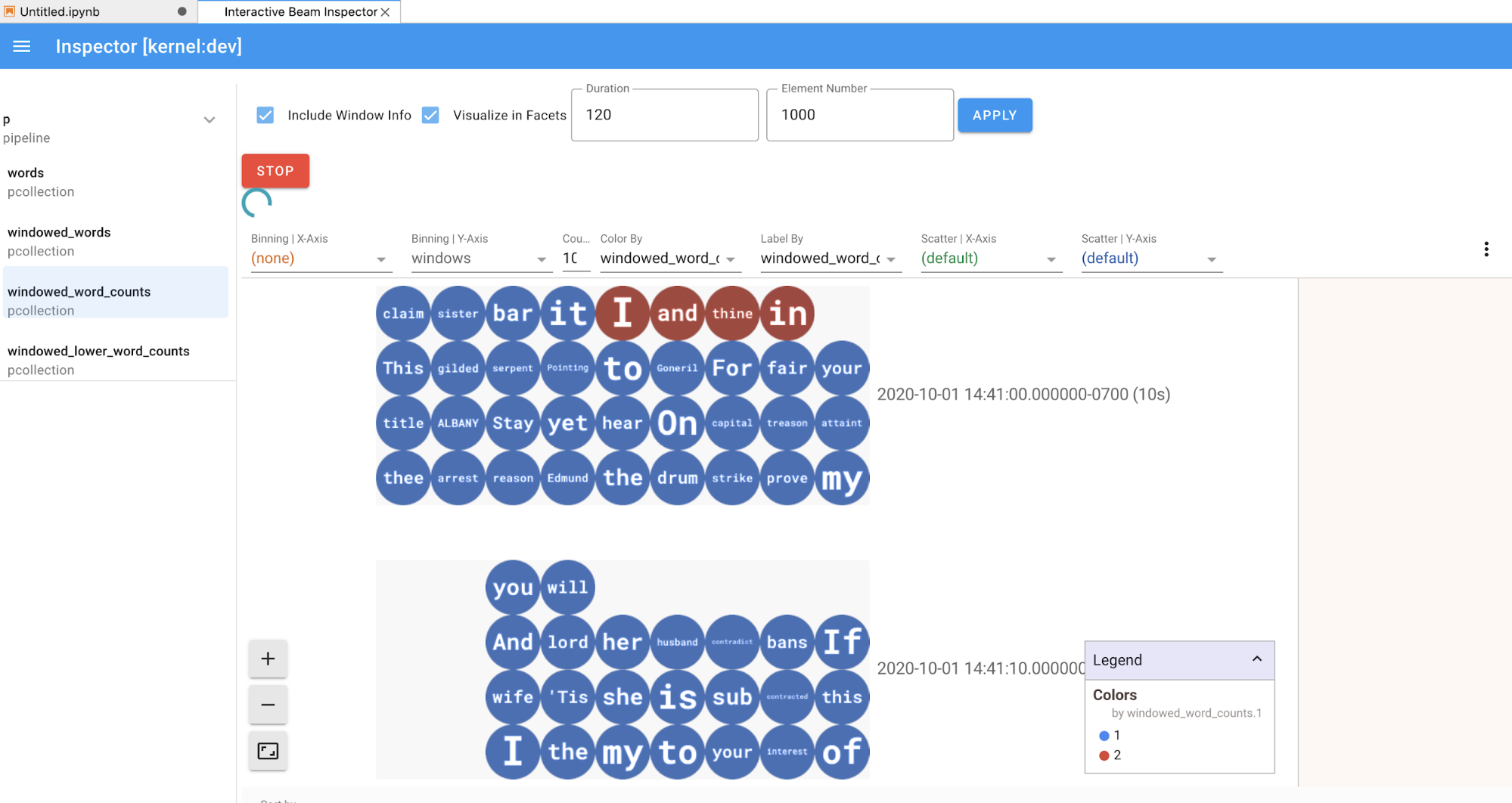
Da der Inspektor und das geöffnete Notebook dieselbe Kernel-Sitzung haben, blockieren sie sich gegenseitig. Wenn das Notebook beispielsweise mit der Ausführung von Code beschäftigt ist, wird der Inspektor erst aktualisiert, wenn das Notebook diese Ausführung abgeschlossen hat. Wenn Sie umgekehrt Code direkt in Ihrem Notebook ausführen möchten, während der Inspektor dynamisch eine
PCollectionvisualisiert, müssen Sie auf die SchaltflächeSTOPklicken, um die Visualisierung zu beenden und den Kernel vorzeitig für das Notebook freizugeben.Wenn es sich um eine Pipeline handelt, zeigt der Inspektor das Pipelinediagramm an.
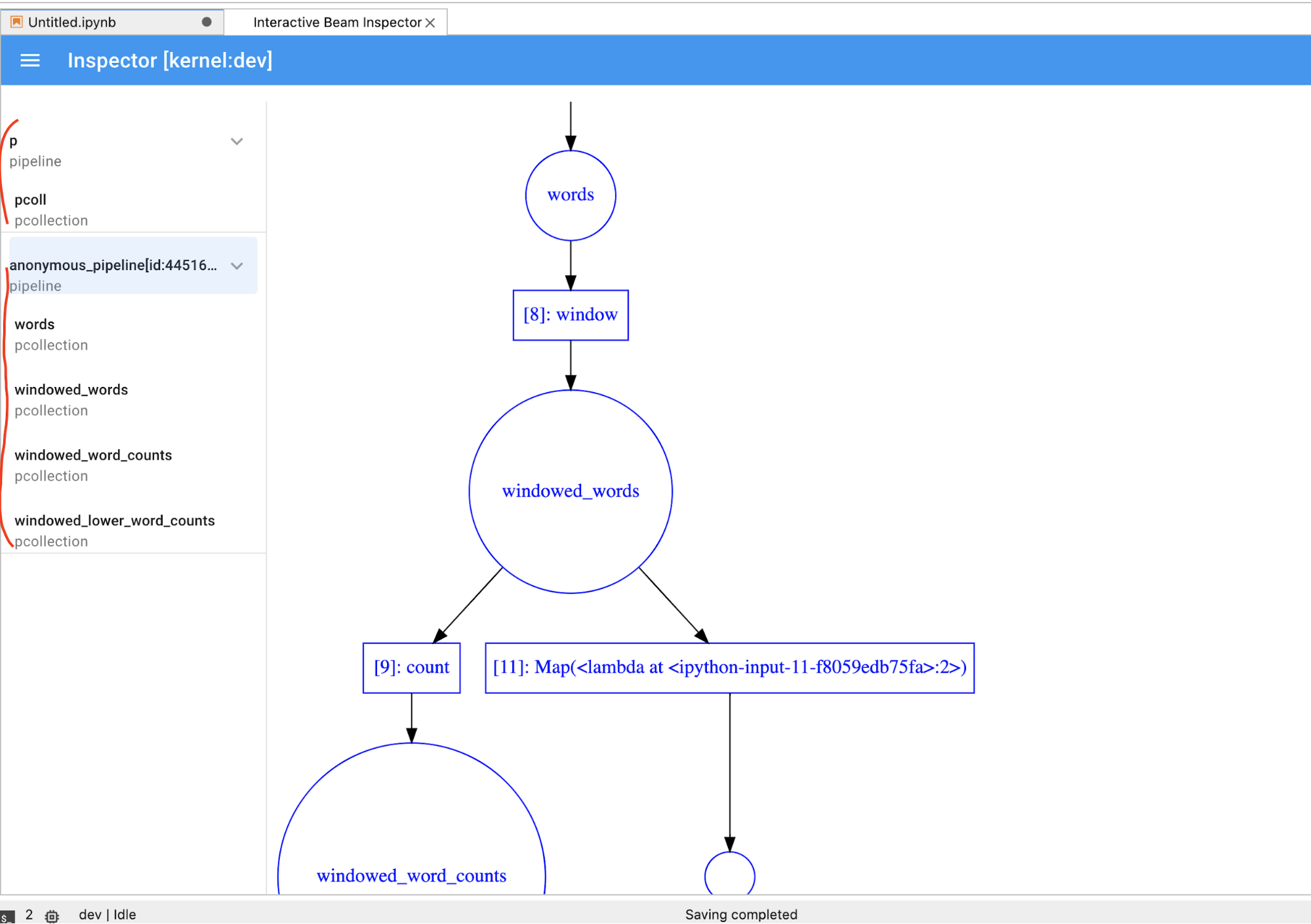
Möglicherweise sind anonyme Pipelines vorhanden. Diese Pipelines haben PCollections, auf die Sie zugreifen können, aber die Hauptsitzung verweist nicht mehr auf sie. Beispiel:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
Im vorherigen Beispiel werden eine leere Pipeline p und eine anonyme Pipeline erstellt, die eine PCollection pcoll enthält. Mit pcoll.pipeline können Sie auf die anonyme Pipeline zugreifen.
Sie können zwischen der Pipeline und der PCollection-Liste wechseln, um Speicherplatz für umfangreiche Visualisierungen zu sparen.
Aufzeichnungsstatus einer Pipeline verstehen
Neben Visualisierungen können Sie auch den Aufzeichnungsstatus für eine oder alle Pipelines in der Notebookinstanz prüfen. Rufen Sie dazu describe auf.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
Die Methode describe() enthält folgende Details:
- Gesamtgröße aller Aufzeichnungen für die Pipeline auf dem Laufwerk (in Byte)
- Startzeit des Hintergrundaufzeichnungsjobs (in Sekunden seit Unix-Epoche)
- Aktueller Pipelinestatus des Hintergrundaufzeichnungsjobs
- Python-Variable für die Pipeline
Dataflow-Jobs aus einer in Ihrem Notebook erstellten Pipeline starten
- Optional: Starten Sie den Kernel neu, starten Sie alle Zellen neu und prüfen Sie die Ausgabe, bevor Sie Ihr Notebook zum Ausführen von Dataflow-Jobs verwenden. Wenn Sie diesen Schritt überspringen, können sich verborgene Status im Notebook auf die Jobgrafik im Pipelineobjekt auswirken.
- Aktivieren Sie die Dataflow API.
Fügen Sie die folgende Importanweisung hinzu:
from apache_beam.runners import DataflowRunnerÜbergeben Sie Ihre Pipelineoptionen.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)Sie können die Parameterwerte anpassen. Sie können beispielsweise den Wert
regionvonus-central1ändern.Führen Sie die Pipeline mit
DataflowRunneraus. Mit diesem Schritt wird der Job im Dataflow-Dienst ausgeführt.runner = DataflowRunner() runner.run_pipeline(p, options=options)pist ein Pipelineobjekt aus dem Schritt Pipeline erstellen.
Ein Beispiel zur Durchführung dieser Konvertierung in einem interaktiven Notebook finden Sie im Dataflow-Notebook „Word Count“ in Ihrer Notebookinstanz.
Alternativ können Sie Ihr Notebook als ausführbares Skript exportieren, die generierte .py-Datei mithilfe der vorherigen Schritte ändern und dann Ihre Pipeline im Dataflow-Dienst bereitstellen.
Notebook speichern
Von Ihnen erstellte Notebooks werden lokal in Ihrer ausgeführten Notebookinstanz gespeichert. Wenn Sie die Notebookinstanz zurücksetzen oder während der Entwicklung herunterfahren, werden diese neuen Notebooks beibehalten, solange sie im Verzeichnis /home/jupyter erstellt werden.
Wenn eine Notebookinstanz jedoch gelöscht wird, werden diese Notebooks auch gelöscht.
Zur Beibehaltung der Notebooks für die zukünftige Verwendung laden Sie sie lokal auf Ihre Workstation herunter, speichern Sie sie in GitHub oder exportieren Sie sie in ein anderes Dateiformat.
Notebook auf zusätzlichen nichtflüchtigen Speichern speichern
Wenn Sie Ihre Arbeit, z. B. Notebooks und Scripts, auf verschiedenen Notebookinstanzen beibehalten möchten, können Sie sie auf einem nichtflüchtigen Speicher speichern.
Erstellen oder hängen Sie einen nichtflüchtigen Speicher an. Folgen Sie der Anleitung zur Verwendung von
ssh, um eine Verbindung zur VM der Notebookinstanz herzustellen und Befehle in der geöffneten Cloud Shell auszugeben.Beachten Sie das Verzeichnis, in dem der nichtflüchtige Speicher bereitgestellt ist, z. B.
/mnt/myDisk.Bearbeiten Sie die VM-Details der Notebookinstanz, um einen Eintrag zum
Custom metadatahinzuzufügen: Schlüssel –container-custom-params. Wert:-v /mnt/myDisk:/mnt/myDisk.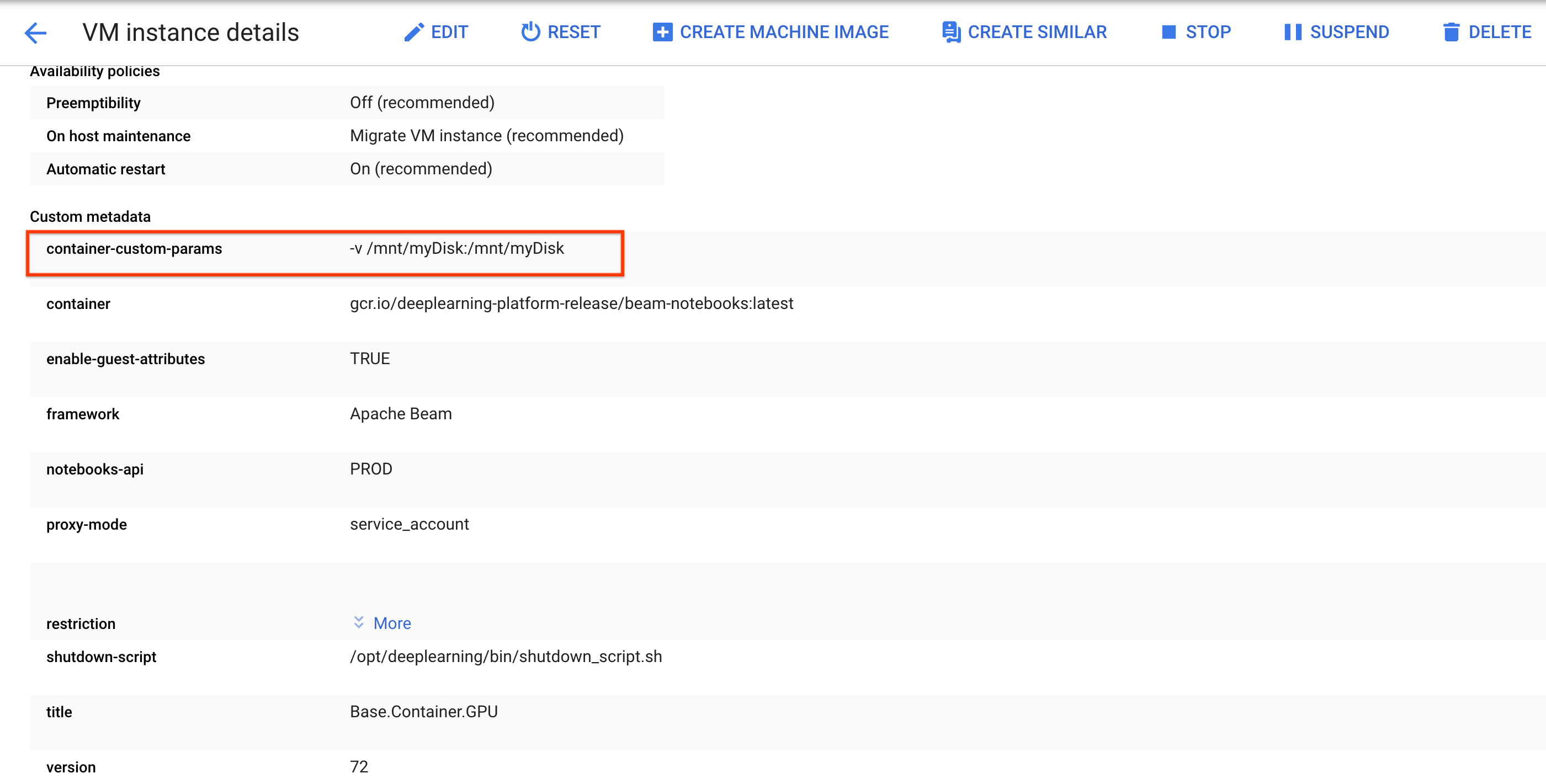
Klicken Sie auf Speichern.
Setzen Sie die Notebookinstanz zurück, um diese Änderungen zu aktualisieren.
Klicken Sie nach dem Zurücksetzen auf JupyterLab öffnen. Es kann einige Zeit dauern, bis die JupyterLab-Benutzeroberfläche verfügbar ist. Wenn die Benutzeroberfläche angezeigt wird, öffnen Sie ein Terminal und führen den folgenden Befehl aus:
ls -al /mnt. Das Verzeichnis/mnt/myDisksollte aufgelistet sein.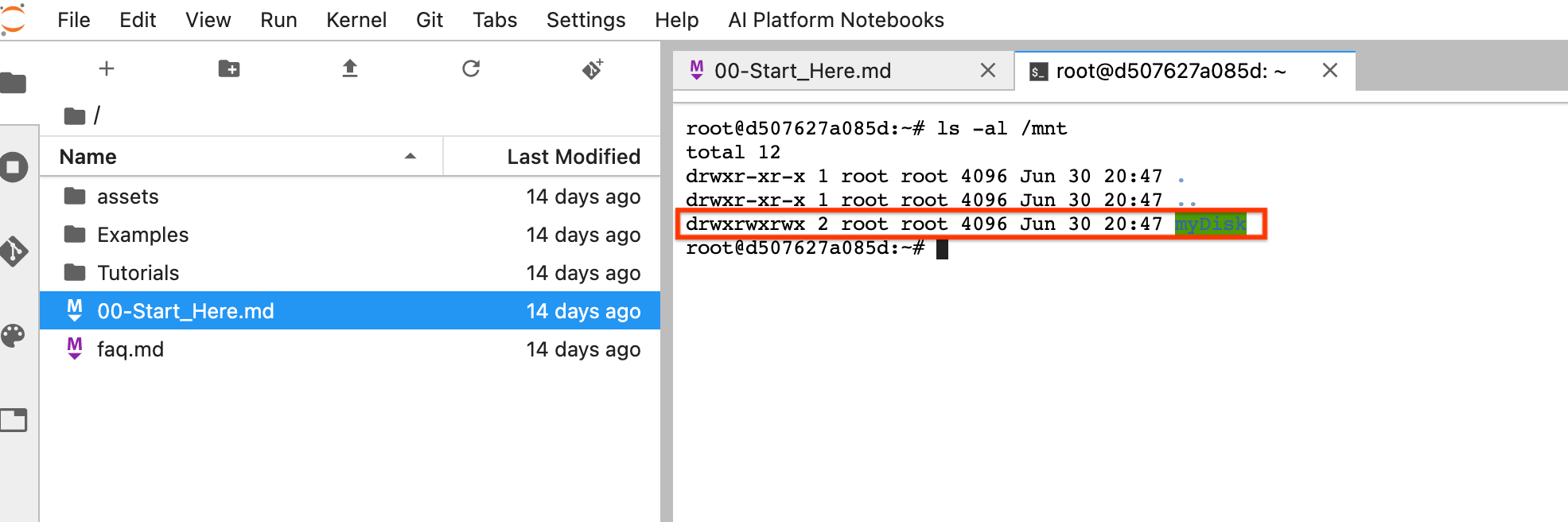
Jetzt können Sie Ihre Arbeit im Verzeichnis /mnt/myDisk speichern. Auch wenn die Notebookinstanz gelöscht wird, ist der nichtflüchtige Speicher unter Ihrem Projekt noch vorhanden. Sie können diesen nichtflüchtigen Speicher dann anderen Notebookinstanzen hinzufügen.
Bereinigen
Nachdem Sie die Verwendung der Apache Beam-Notebookinstanz abgeschlossen haben, bereinigen Sie die in Google Cloud erstellten Ressourcen, indem Sie die Notebookinstanz herunterfahren.
Nächste Schritte
- Weitere Informationen zu erweiterten Features, die Sie mit Ihren Apache Beam-Notebooks verwenden können. Zu den erweiterten Features gehören folgende Workflows: