Use o executor interativo do Apache Beam com blocos de notas do JupyterLab para concluir as seguintes tarefas:
- Desenvolva pipelines de forma iterativa.
- Inspecione o gráfico do pipeline.
- Analisar
PCollectionsindividuais num fluxo de trabalho de leitura-avaliação-impressão (REPL).
Estes blocos de notas do Apache Beam são disponibilizados através do Vertex AI Workbench, um serviço que alberga máquinas virtuais de blocos de notas pré-instaladas com a ciência de dados e as frameworks de aprendizagem automática mais recentes. O Dataflow só suporta instâncias do Workbench que usam o contentor do Apache Beam.
Este guia centra-se nas funcionalidades introduzidas pelos blocos de notas do Apache Beam, mas não mostra como criar um bloco de notas. Para mais informações sobre o Apache Beam, consulte o guia de programação do Apache Beam.
Apoio técnico e limitações
- Os blocos de notas do Apache Beam só suportam Python.
- Os segmentos do pipeline do Apache Beam executados nestes blocos de notas são executados num ambiente de teste e não num executor do Apache Beam de produção. Para iniciar os blocos de notas no serviço Dataflow, exporte os pipelines criados no bloco de notas do Apache Beam. Para mais detalhes, consulte o artigo Inicie tarefas do Dataflow a partir de um pipeline criado no seu bloco de notas.
Antes de começar
- Sign in to your Google Cloud Platform account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Na Google Cloud consola, aceda à página Workbench do Dataflow.
Certifique-se de que está no separador INSTÂNCIAS.
Na barra de ferramentas, clique em Criar novo.
Na secção Ambiente, para Ambiente, o Contentor deve ser Apache Beam. Apenas o JupyterLab 3.x é suportado para blocos de notas do Apache Beam.
Opcional: se quiser executar blocos de notas numa GPU, na secção Tipo de máquina, selecione um tipo de máquina que suporte GPUs. Para mais informações, consulte o artigo Plataformas de GPU.
Na secção Rede, selecione uma sub-rede para a VM do bloco de notas.
Opcional: se quiser configurar uma instância de bloco de notas personalizada, consulte o artigo Crie uma instância com um contentor personalizado.
Clique em Criar. O Dataflow Workbench cria uma nova instância do bloco de notas do Apache Beam.
Depois de criar a instância do notebook, o link Abrir JupyterLab fica ativo. Clique em Abrir JupyterLab.
- Contagem de palavras
- Contagem de palavras no streaming
- Streaming de dados de viagens de táxi em Nova Iorque
- SQL do Apache Beam em blocos de notas com comparações a pipelines
- SQL do Apache Beam em blocos de notas com o Dataflow Runner
- SQL do Apache Beam em blocos de notas
- Contagem de palavras do Dataflow
- Flink interativo à escala
- RunInference
- Use GPUs com o Apache Beam
- Visualize dados
- Operações básicas
- Operações ao nível do elemento
- Agregações
- Windows
- Operações de I/O
- Streaming
- Exercícios finais
- Defina
npara limitar o conjunto de resultados a apresentar, no máximo,nelementos, como 20. Sennão estiver definido, o comportamento predefinido é apresentar os elementos capturados mais recentes até a gravação de origem terminar. - Defina
durationpara limitar o conjunto de resultados a um número especificado de segundos de dados a partir do início da gravação de origem. Sedurationnão estiver definido, o comportamento predefinido é listar todos os elementos até a gravação terminar. Clique em
Interactive Beamna barra de menu superior do JupyterLab. No menu pendente, localizeOpen Inspectore clique nele para abrir o inspetor.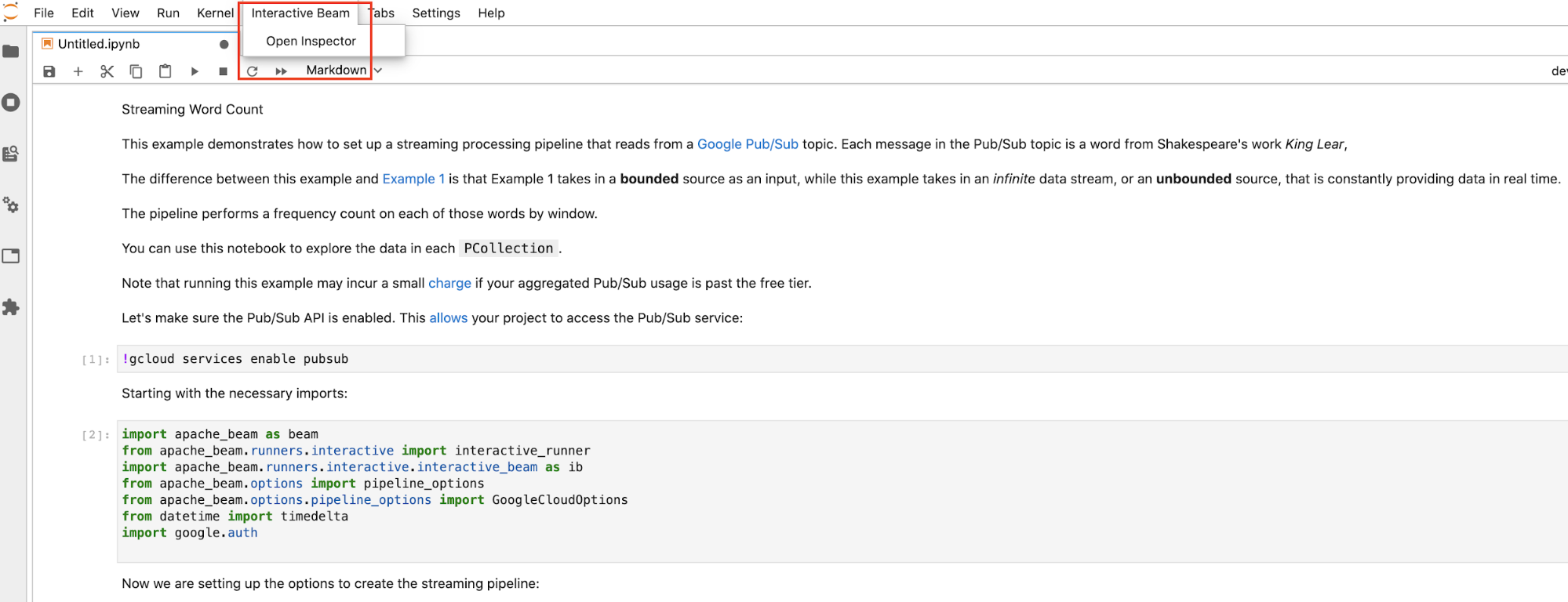
Use a página do Launcher. Se não for aberta nenhuma página do Launcher, clique em
File->New Launcherpara a abrir. Na página do Launcher, localizeInteractive Beame clique emOpen Inspectorpara abrir o inspetor.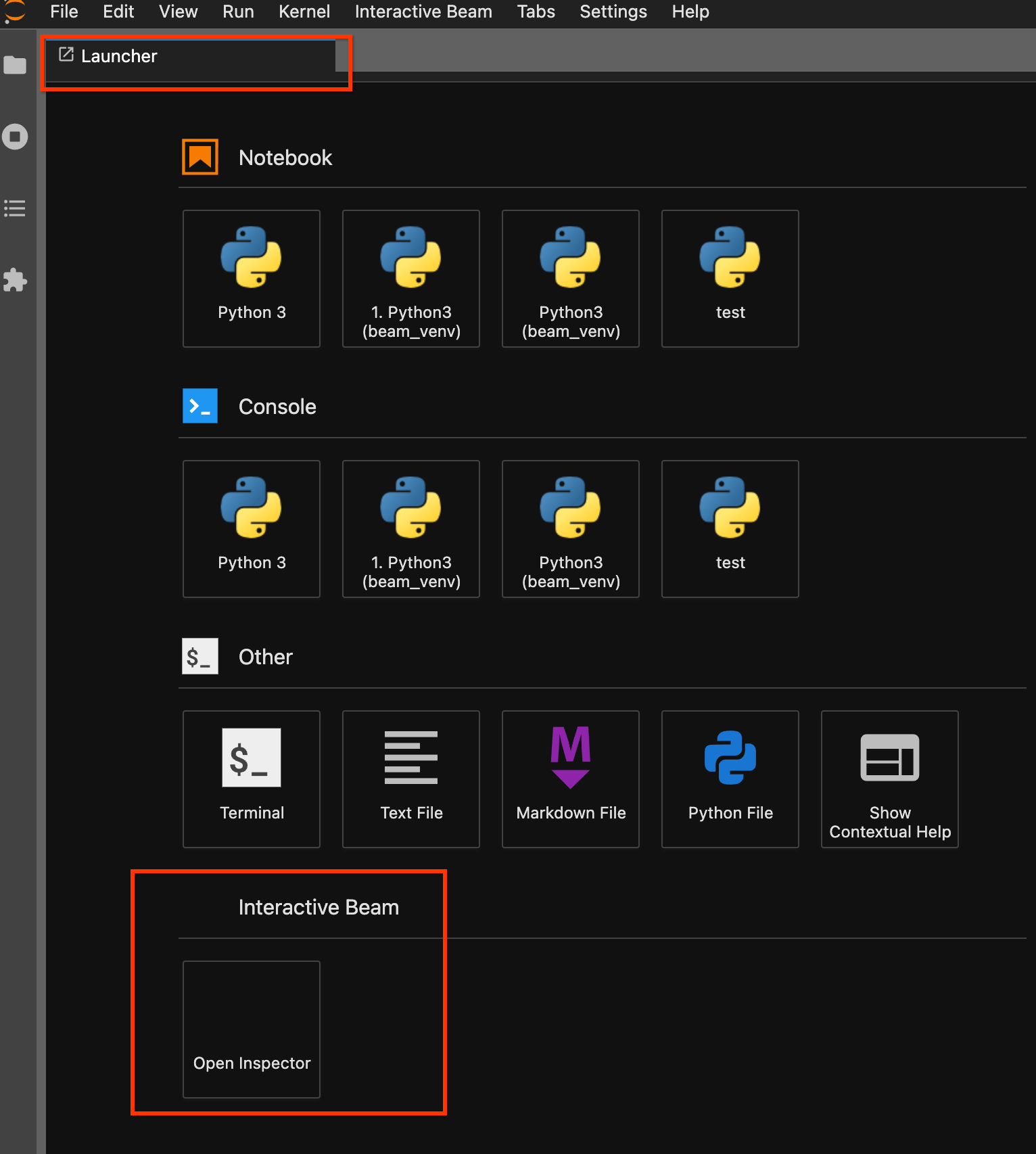
Use a paleta de comandos. Na barra de menu do JupyterLab, clique em
View>Activate Command Palette. Na caixa de diálogo, pesquiseInteractive Beampara listar todas as opções da extensão. Clique emOpen Inspectorpara abrir o inspetor.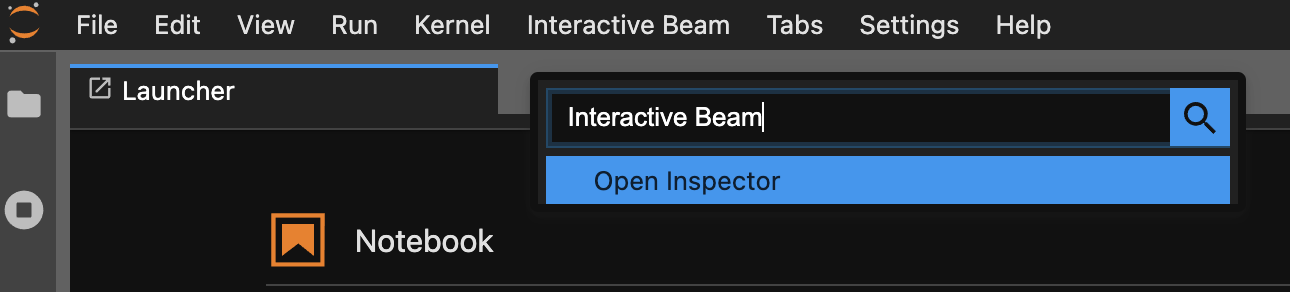
Se existir exatamente um bloco de notas aberto, o inspetor liga-se automaticamente a este.
Se não estiver nenhum bloco de notas aberto, é apresentada uma caixa de diálogo que lhe permite selecionar um kernel.
Se tiver vários blocos de notas abertos, é apresentada uma caixa de diálogo que lhe permite selecionar a sessão do bloco de notas.
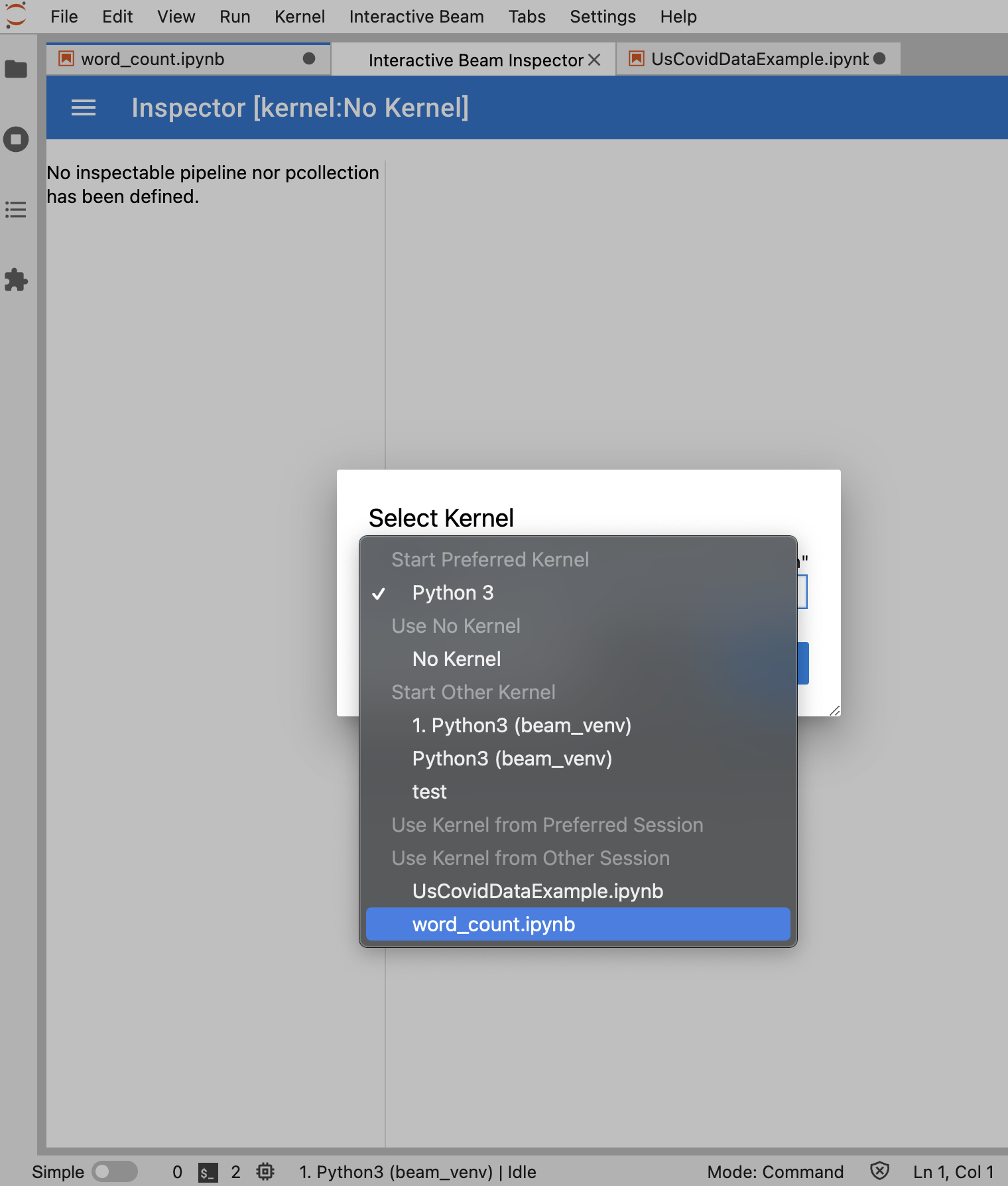
Se for um
PCollection, o inspetor renderiza os respetivos dados (dinamicamente se os dados ainda estiverem a ser recebidos paraPCollectionsilimitados) com widgets adicionais para ajustar a visualização depois de clicar no botãoAPPLY.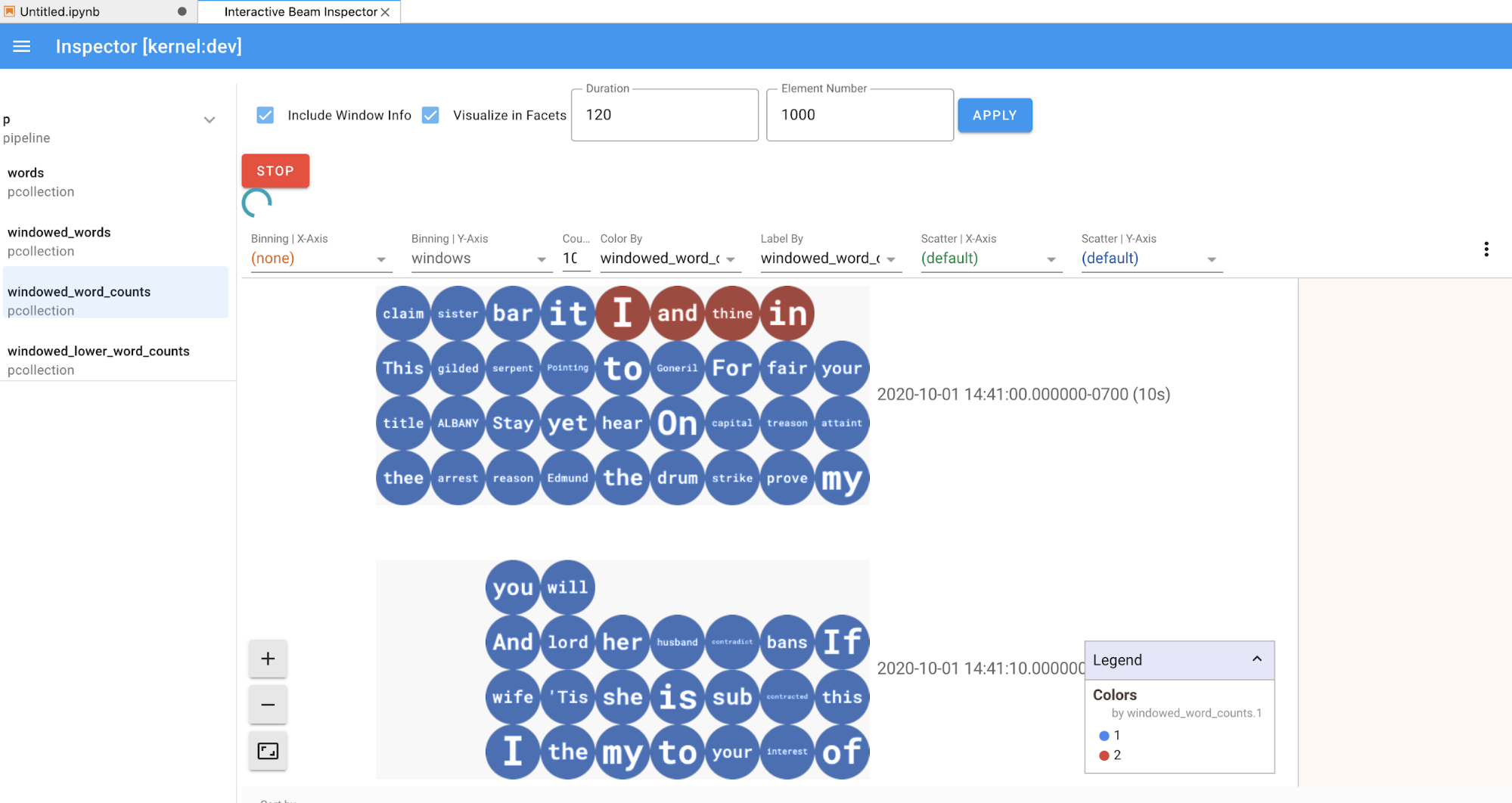
Uma vez que o inspetor e o notebook aberto partilham a mesma sessão do kernel, impedem-se mutuamente de serem executados. Por exemplo, se o bloco de notas estiver ocupado a executar código, o inspetor não é atualizado até que o bloco de notas conclua essa execução. Por outro lado, se quiser executar código imediatamente no seu bloco de notas enquanto o inspetor está a visualizar um
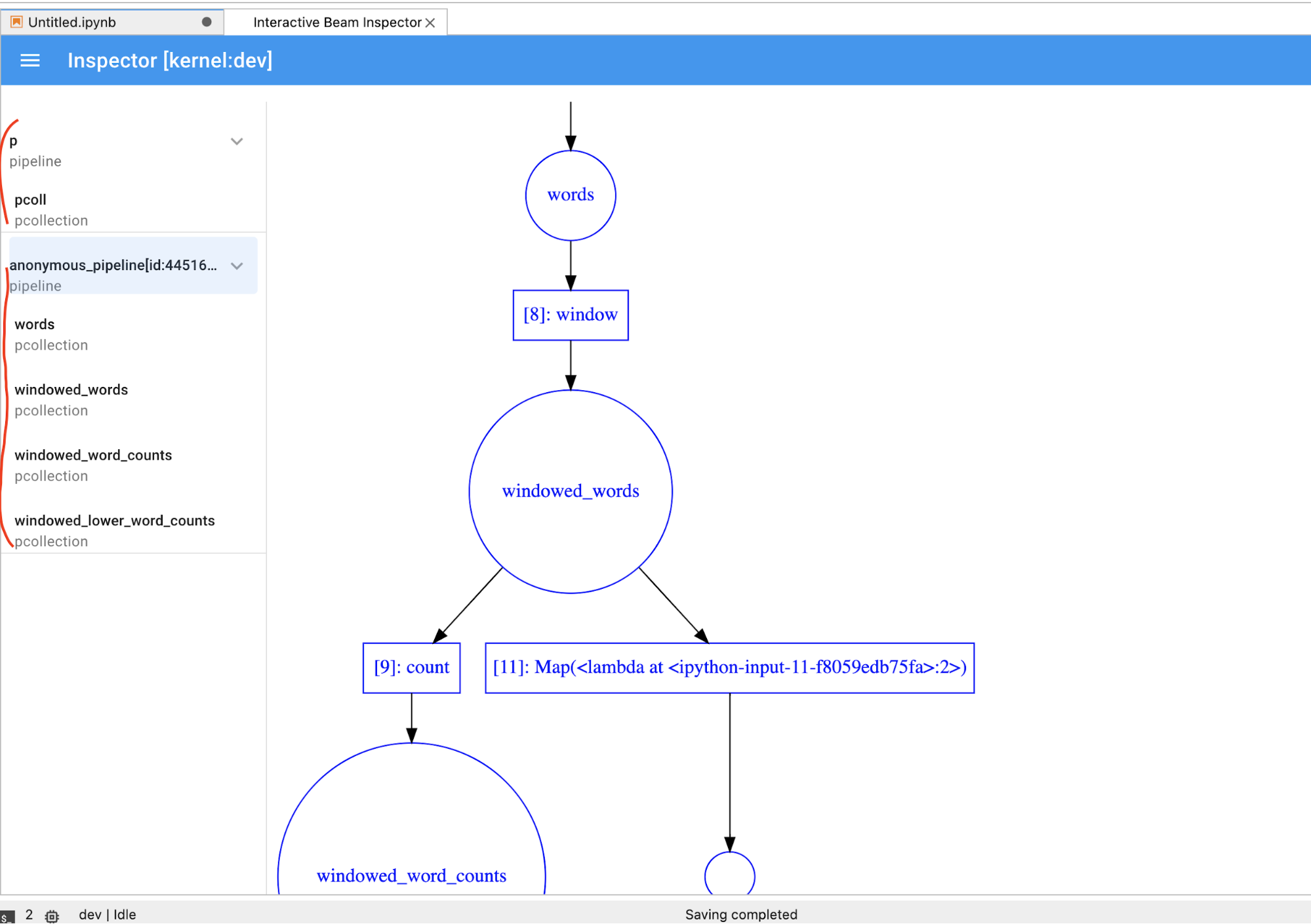
PCollectiondinamicamente, tem de clicar no botãoSTOPpara parar a visualização e libertar antecipadamente o kernel para o bloco de notas.Se for um pipeline, o inspetor apresenta o gráfico do pipeline.
- Tamanho total (em bytes) de todas as gravações do pipeline no disco
- Hora de início da tarefa de gravação em segundo plano (em segundos desde o início da época Unix)
- Estado atual do pipeline da tarefa de gravação em segundo plano
- Variável Python para o pipeline
- Opcional: antes de usar o bloco de notas para executar tarefas do Dataflow, reinicie o kernel, volte a executar todas as células e valide o resultado. Se ignorar este passo, os estados ocultos no bloco de notas podem afetar o gráfico de tarefas no objeto da pipeline.
- Ative a API Dataflow.
Adicione a seguinte declaração de importação:
from apache_beam.runners import DataflowRunnerTransmita as opções do pipeline.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)Pode ajustar os valores dos parâmetros. Por exemplo, pode alterar o valor de
regionus-central1.Execute o pipeline com
DataflowRunner. Este passo executa a tarefa no serviço Dataflow.runner = DataflowRunner() runner.run_pipeline(p, options=options)pé um objeto de pipeline de Criar o seu pipeline.Crie ou anexe um Persistent Disk. Siga as instruções para usar
sshpara se ligar à VM da instância do bloco de notas e emitir comandos no Cloud Shell aberto.Tenha em atenção o diretório onde o Persistent Disk está montado, por exemplo,
/mnt/myDisk.Edite os detalhes da VM da instância do bloco de notas para adicionar uma entrada à chave
Custom metadata:container-custom-params; valor:-v /mnt/myDisk:/mnt/myDisk.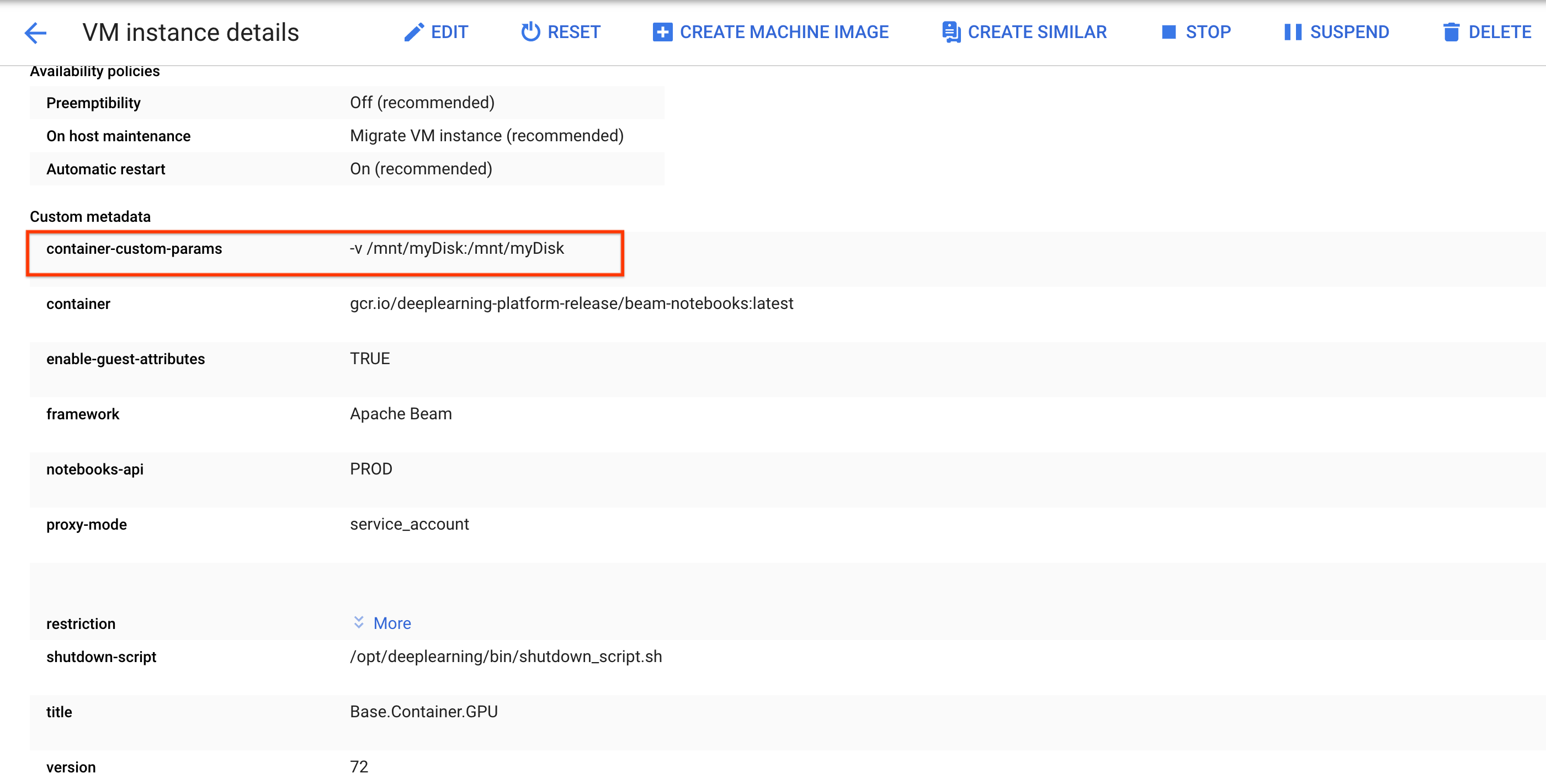
Clique em Guardar.
Para atualizar estas alterações, reponha a instância do bloco de notas.
Após a reposição, clique em Abrir JupyterLab. A IU do JupyterLab pode demorar algum tempo a ficar disponível. Depois de a IU ser apresentada, abra um terminal e execute o seguinte comando:
ls -al /mntO diretório/mnt/myDiskdeve ser apresentado.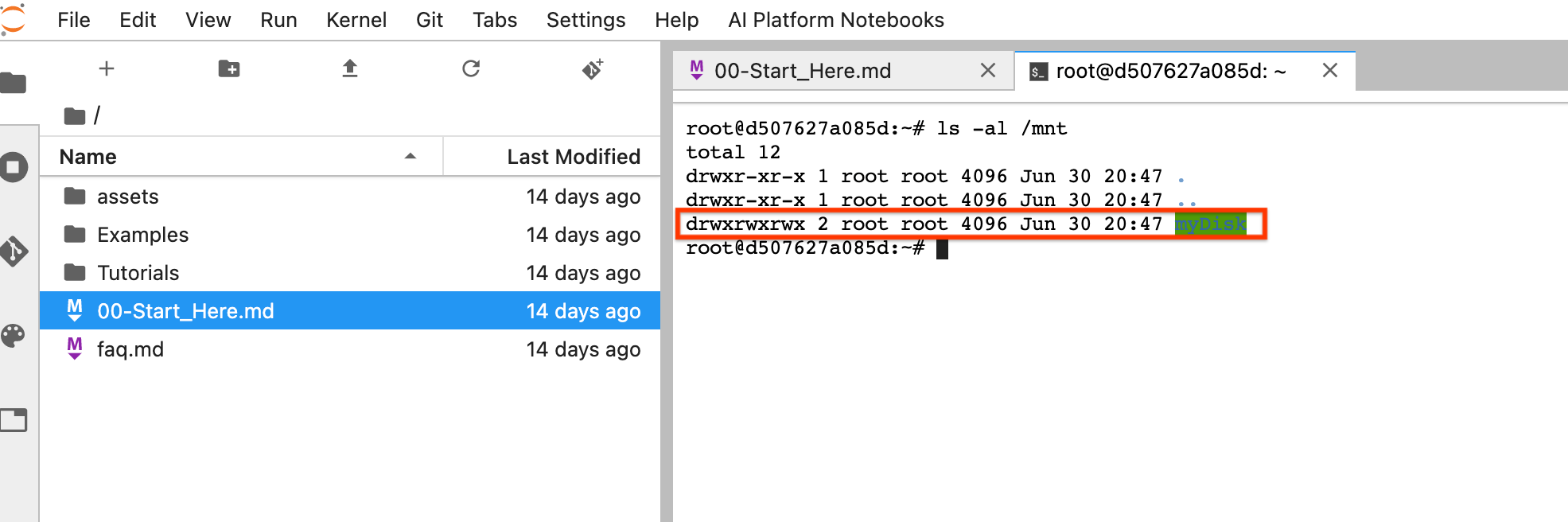
- Saiba mais sobre as funcionalidades avançadas que pode usar com os seus blocos de notas do Apache Beam. As funcionalidades avançadas incluem os seguintes fluxos de trabalho:
Antes de criar a instância do bloco de notas do Apache Beam, ative APIs adicionais para pipelines que usam outros serviços, como o Pub/Sub.
Se não for especificado, a instância do bloco de notas é executada pela conta de serviço predefinida do Compute Engine com a função de editor de projetos do IAM. Se o projeto limitar explicitamente as funções da conta de serviço, certifique-se de que continua a ter autorização suficiente para executar os seus blocos de notas. Por exemplo, a leitura de um tópico do Pub/Sub cria implicitamente uma subscrição, e a sua conta de serviço precisa de uma função de editor do Pub/Sub do IAM. Por outro lado, a leitura a partir de uma subscrição do Pub/Sub só requer uma função de subscritor do Pub/Sub do IAM.
Quando terminar este guia, para evitar a faturação contínua, elimine os recursos que criou. Para mais detalhes, consulte o artigo Limpar.
Inicie uma instância de notebook do Apache Beam
Opcional: instale dependências
Os blocos de notas do Apache Beam já incluem o Apache Beam e as dependências do conector instaladas.Google Cloud Se o seu pipeline contiver conectores personalizados ou PTransforms personalizados que dependam de bibliotecas de terceiros, instale-os depois de criar uma instância do bloco de notas.
Exemplos de blocos de notas do Apache Beam
Depois de criar uma instância de notebook, abra-a no JupyterLab. No separador Ficheiros na barra lateral do JupyterLab, a pasta Exemplos contém blocos de notas de exemplo. Para mais informações sobre como trabalhar com ficheiros do JupyterLab, consulte o artigo Trabalhar com ficheiros no guia do utilizador do JupyterLab.
Estão disponíveis os seguintes blocos de notas:
A pasta Tutoriais contém tutoriais adicionais que explicam os fundamentos do Apache Beam. Estão disponíveis os seguintes tutoriais:
Estes blocos de notas incluem texto explicativo e blocos de código com comentários para ajudar a compreender os conceitos do Apache Beam e a utilização da API. Os tutoriais também oferecem exercícios para praticar os conceitos.
As secções seguintes usam código de exemplo do bloco de notas Streaming Word Count. Os fragmentos de código neste guia e o que se encontra no bloco de notas Streaming Word Count podem ter pequenas discrepâncias.
Crie uma instância do notebook
Navegue para Ficheiro > Novo > Bloco de notas e selecione um kernel que seja Apache Beam 2.22 ou posterior.
Os blocos de notas do Apache Beam são criados com base no ramo principal do SDK do Apache Beam. Isto significa que a versão mais recente do kernel apresentada na IU dos blocos de notas pode estar à frente da versão do SDK lançada mais recentemente.
O Apache Beam está instalado na instância do bloco de notas, por isso, inclua os módulos interactive_runner e interactive_beam no bloco de notas.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Se o seu bloco de notas usar outras APIs Google, adicione as seguintes declarações de importação:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Defina opções de interatividade
A linha seguinte define a quantidade de tempo durante o qual o InteractiveRunner regista dados de uma origem ilimitada. Neste exemplo, a duração está definida como 10 minutos.
ib.options.recording_duration = '10m'
Também pode alterar o limite de tamanho da gravação (em bytes) para uma origem ilimitada
usando a propriedade recording_size_limit.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
Para opções interativas adicionais, consulte a classe interactive_beam.options.
Crie o seu pipeline
Inicialize o pipeline com um objeto InteractiveRunner.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud Platform environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
Leia e visualize os dados
O exemplo seguinte mostra um pipeline do Apache Beam que cria uma subscrição para o tópico Pub/Sub fornecido e lê a partir da subscrição.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
O pipeline conta as palavras por janelas da origem. Cria janelas fixas com uma duração de 10 segundos cada.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Depois de os dados serem divididos em janelas, as palavras são contabilizadas por janela.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
O método show() visualiza a PCollection resultante no bloco de notas.
ib.show(windowed_word_counts, include_window_info=True)
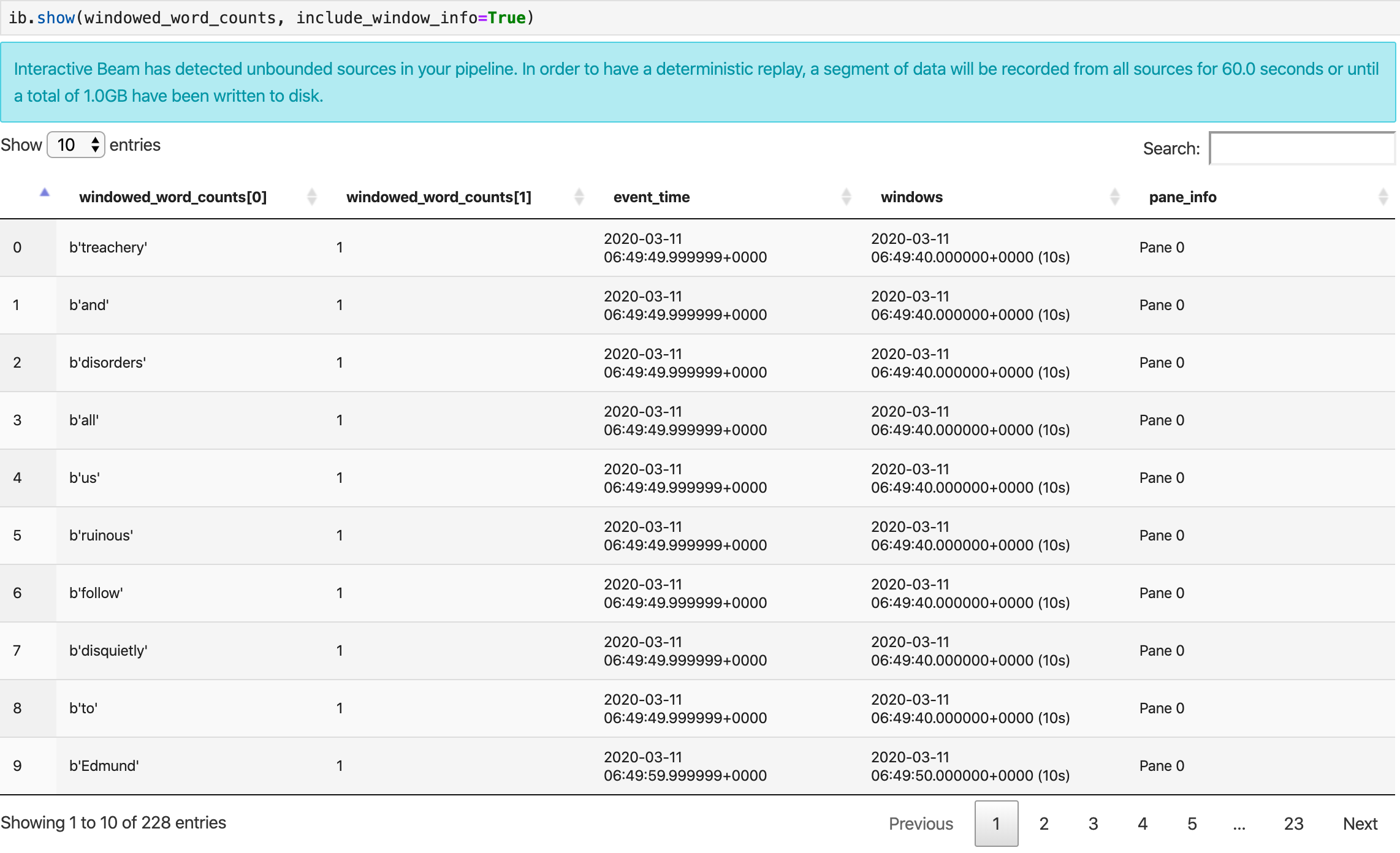
Pode restringir o conjunto de resultados a partir de show() definindo dois parâmetros opcionais: n e duration.
Se ambos os parâmetros opcionais estiverem definidos, show() é interrompido sempre que qualquer um dos limites for atingido. No exemplo seguinte, show() devolve, no máximo, 20 elementos que são calculados com base nos dados dos primeiros 30 segundos das origens registadas.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
Para apresentar visualizações dos seus dados, transmita visualize_data=True para o método show(). Pode aplicar vários filtros às visualizações. A visualização seguinte permite-lhe filtrar por etiqueta e eixo:
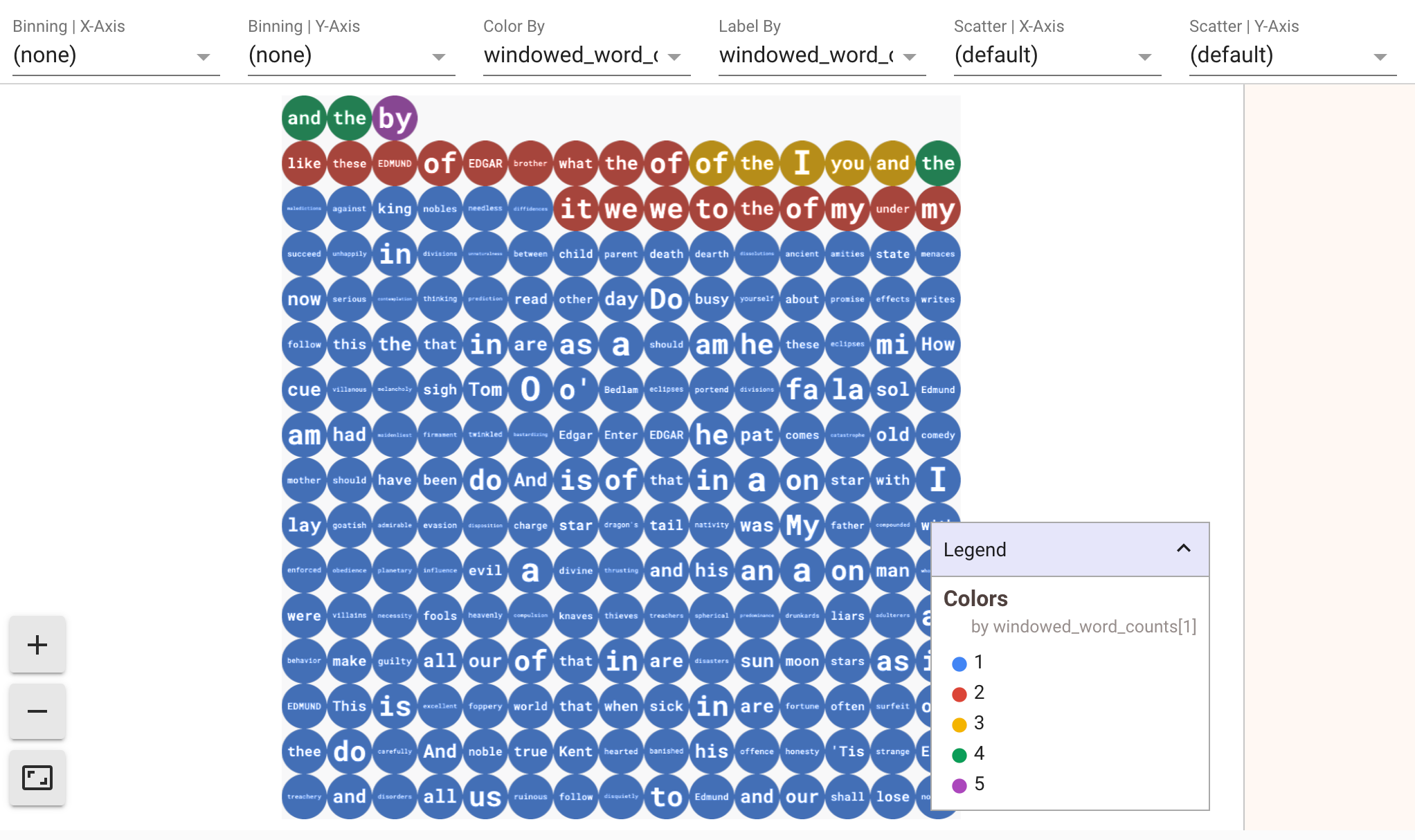
Para garantir a capacidade de repetição durante a criação de protótipos de pipelines de streaming, as chamadas do método show() reutilizam os dados capturados por predefinição. Para alterar este comportamento e fazer com que o método show() obtenha sempre novos dados, defina interactive_beam.options.enable_capture_replay = False. Além disso, se adicionar uma segunda origem ilimitada ao seu bloco de notas, os dados da origem ilimitada anterior são rejeitados.
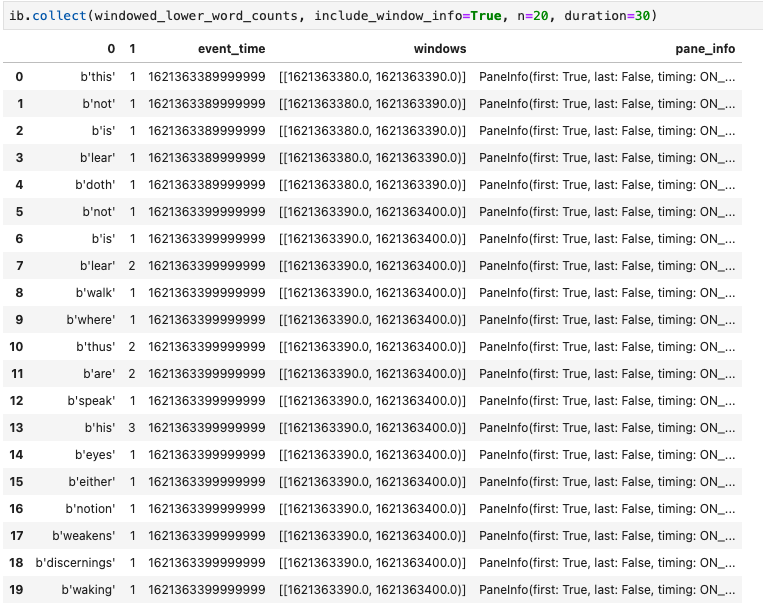
Outra visualização útil nos blocos de notas do Apache Beam é um Pandas DataFrame. O exemplo seguinte converte primeiro as palavras em minúsculas e, em seguida, calcula a frequência de cada palavra.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
O método collect() fornece o resultado num Pandas DataFrame.
ib.collect(windowed_lower_word_counts, include_window_info=True)
Editar e executar novamente uma célula é uma prática comum no desenvolvimento de blocos de notas. Quando edita e volta a executar uma célula num bloco de notas do Apache Beam,
a célula não anula a ação pretendida do código na célula original. Por exemplo, se uma célula adicionar um PTransform a um pipeline, a nova execução dessa célula adiciona um PTransform adicional ao pipeline. Se quiser limpar o estado,
reinicie o kernel e, em seguida, volte a executar as células.
Visualize os dados através do inspetor do Interactive Beam
Pode ser uma distração inspecionar os dados de um PCollection chamando
constantemente show() e collect(), especialmente quando a saída ocupa
muito espaço no ecrã e dificulta a navegação no
bloco de notas. Também pode comparar várias PCollections lado a lado para validar se uma transformação funciona como previsto. Por exemplo, quando um PCollection
passa por uma transformação e produz o outro. Para estes exemplos de utilização, o inspetor de Interactive Beam é uma solução conveniente.
O inspetor interativo do Beam é fornecido como uma extensão do JupyterLab
apache-beam-jupyterlab-sidepanel
pré-instalada no bloco de notas do Apache Beam. Com a extensão, pode inspecionar interativamente o estado dos pipelines e os dados associados a cada PCollection sem invocar explicitamente show() ou collect().
Existem 3 formas de abrir o inspetor:
Quando o inspetor está prestes a ser aberto:
Recomendamos que abra, pelo menos, um bloco de notas e selecione um kernel para o mesmo
antes de abrir o inspetor. Se abrir um inspetor com um kernel antes de abrir qualquer notebook, mais tarde, quando abrir um notebook para se ligar ao inspetor, tem de selecionar o Interactive Beam Inspector Session a partir de Use
Kernel from Preferred Session. Um inspetor e um bloco de notas estão ligados quando
partilham a mesma sessão e não sessões diferentes criadas a partir do mesmo
kernel. Selecionar o mesmo kernel a partir de Start Preferred Kernel cria uma nova sessão independente das sessões existentes de notebooks ou inspetores abertos.
Pode abrir vários inspetores para um bloco de notas aberto e organizar os inspetores arrastando e largando os respetivos separadores livremente no espaço de trabalho.
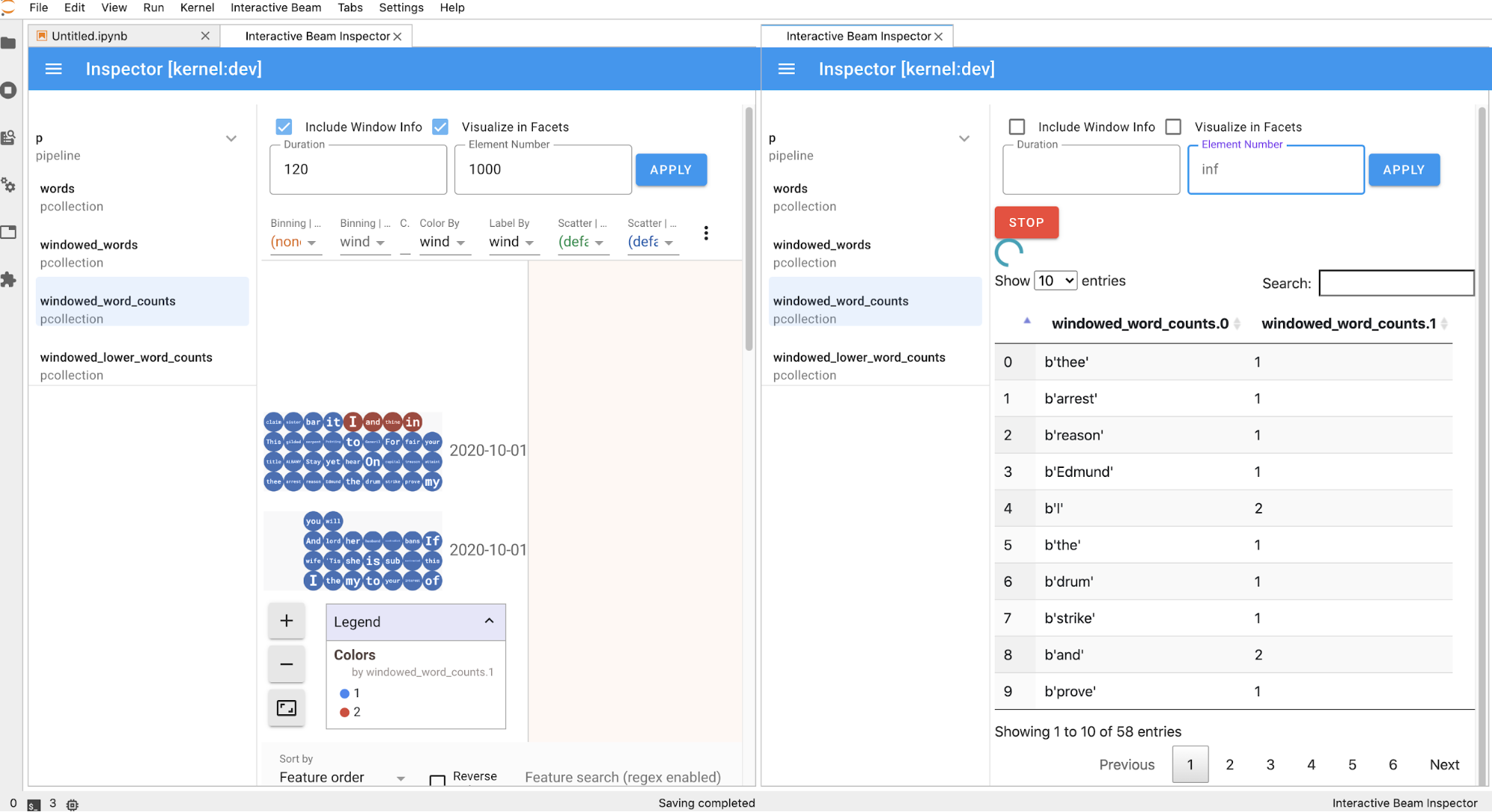
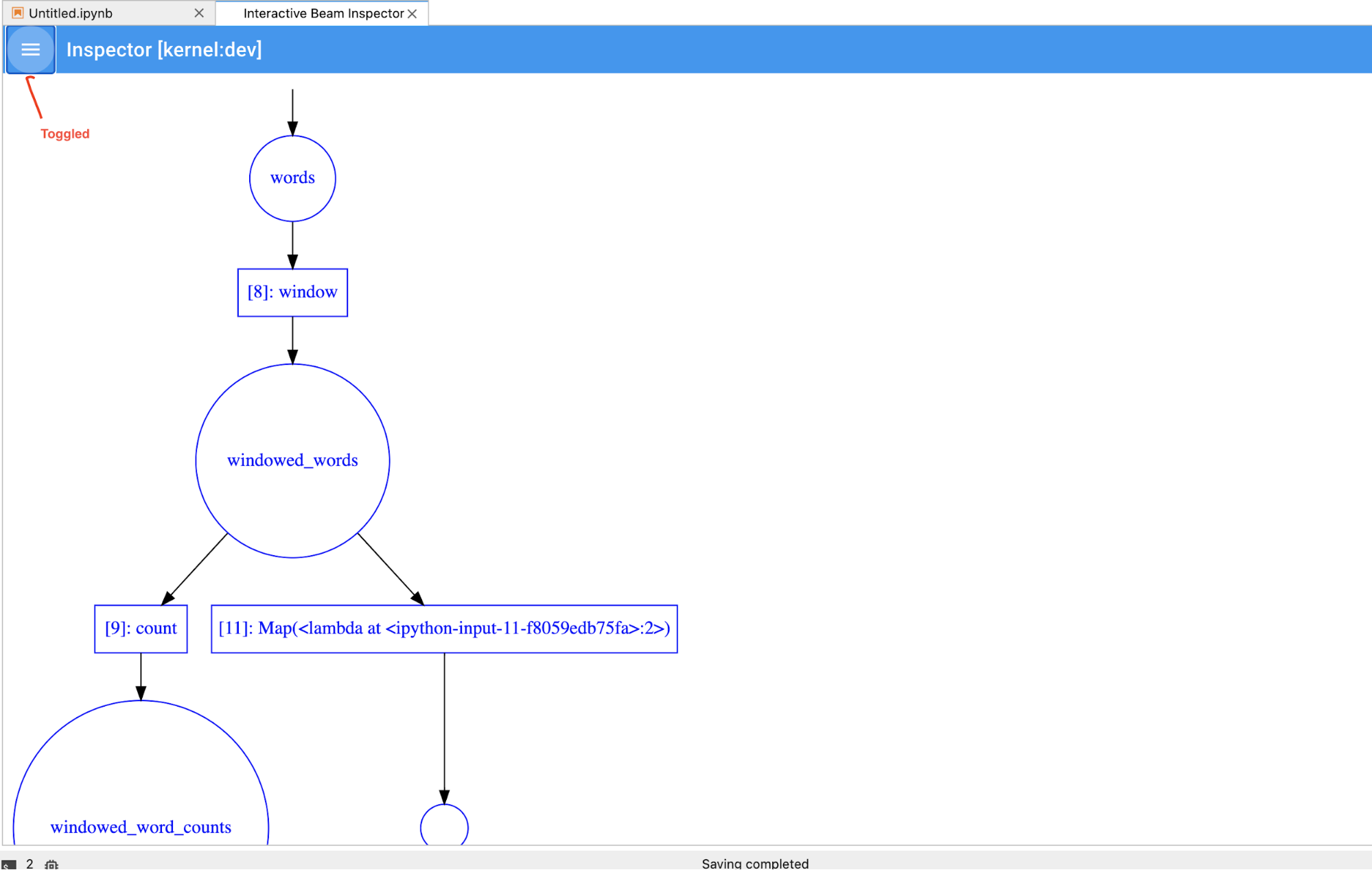
A página do inspetor é atualizada automaticamente quando executa células no bloco de notas. A página apresenta as pipelines e as PCollections definidas no bloco de notas associado. PCollections estão organizados pelos pipelines a que pertencem e pode reduzi-los clicando no pipeline do cabeçalho.
Para os itens nas listas de pipelines e PCollections, quando clica, o inspetor
renderiza as visualizações correspondentes no lado direito:
Pode reparar em pipelines anónimos. Esses pipelines têm
PCollections aos quais pode aceder, mas já não são referenciados pela sessão principal. Por exemplo:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
O exemplo anterior cria um pipeline vazio p e um pipeline anónimo que
contém um PCollection pcoll. Pode aceder ao pipeline anónimo
através de pcoll.pipeline.
Pode ativar/desativar o pipeline e a lista PCollection para poupar espaço para visualizações grandes.
Compreenda o estado de gravação de um pipeline
Além das visualizações, também pode inspecionar o estado da gravação de um ou todos os pipelines na instância do bloco de notas chamando describe.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
O método describe() fornece os seguintes detalhes:
Inicie tarefas do Dataflow a partir de um pipeline criado no seu bloco de notas
Para ver um exemplo de como realizar esta conversão num bloco de notas interativo, consulte o bloco de notas de contagem de palavras do Dataflow na instância do bloco de notas.
Em alternativa, pode exportar o bloco de notas como um script executável, modificar o ficheiro .py gerado através dos passos anteriores e, em seguida, implementar o pipeline no serviço Dataflow.
Guarde o seu bloco de notas
Os notebooks que cria são guardados localmente na instância do notebook em execução. Se repuser ou desligar a instância do bloco de notas durante o desenvolvimento, esses novos blocos de notas são mantidos desde que sejam criados no diretório /home/jupyter.
No entanto, se uma instância do notebook for eliminada, esses notebooks também são eliminados.
Para manter os seus blocos de notas para utilização futura, transfira-os localmente para a sua estação de trabalho, guarde-os no GitHub ou exporte-os para um formato de ficheiro diferente.
Guarde o seu notebook em discos persistentes adicionais
Se quiser manter o seu trabalho, como blocos de notas e scripts, em várias instâncias de blocos de notas, armazene-o no disco persistente.
Agora, pode guardar o seu trabalho no diretório /mnt/myDisk. Mesmo que a instância do bloco de notas seja eliminada, o disco persistente existe no seu projeto. Em seguida, pode anexar este disco persistente a outras instâncias de blocos de notas.
Limpar
Depois de terminar a utilização da instância do bloco de notas do Apache Beam, limpe os recursos que criou no Google Cloud encerrando a instância do bloco de notas.