搭配使用 Apache Beam 互動式執行器和 JupyterLab 筆記本,完成下列工作:
- 反覆開發管道。
- 檢查管道圖。
- 在「讀取-求值-印出迴圈」(REPL) 工作流程中剖析個別
PCollections。
這些 Apache Beam 筆記本可透過 Vertex AI Workbench 取得,這項服務會代管筆記本虛擬機器,並預先安裝最新的數據資料學和機器學習架構。Dataflow 僅支援使用 Apache Beam 容器的 Workbench 執行個體。
本指南著重於 Apache Beam 筆記本推出的功能,但不會說明如何建構筆記本。如要進一步瞭解 Apache Beam,請參閱 Apache Beam 程式設計指南。
支援與限制
- Apache Beam 筆記本僅支援 Python。
- 在這些筆記本中執行的 Apache Beam 管道區隔會在測試環境中執行,而不是針對正式的 Apache Beam 執行器。如要在 Dataflow 服務上啟動筆記本,請匯出在 Apache Beam 筆記本中建立的管道。詳情請參閱「從筆記本中建立的管道啟動 Dataflow 工作」。
事前準備
- Sign in to your Google Cloud Platform account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 前往 Google Cloud 控制台的 Dataflow「Workbench」頁面。
確認目前顯示的是「INSTANCES」分頁。
按一下工具列中的「新建」圖示 。
在「環境」部分,請確認「環境」和「容器」為「Apache Beam」。Apache Beam 筆記本僅支援 JupyterLab 3.x。
選用:如要在 GPU 上執行筆記本,請在「Machine type」(機器類型) 部分中,選取支援 GPU 的機器類型。詳情請參閱「GPU 平台」。
在「Networking」部分中,選取 Notebook VM 的子網路。
選用:如要設定自訂筆記本執行個體,請參閱「使用自訂容器建立執行個體」。
按一下「Create」(建立)。Dataflow Workbench 會建立新的 Apache Beam 筆記本執行個體。
筆記本執行個體建立完成後,「Open JupyterLab」連結就會啟用。 點選「Open JupyterLab」。
- 字數計算
- 串流字數統計
- 串流紐約市計程車乘車資料
- 筆記本中的 Apache Beam SQL,並與管道進行比較
- 在筆記本中使用 Apache Beam SQL 和 Dataflow 執行器
- 筆記本中的 Apache Beam SQL
- Dataflow 字數
- 大規模互動式 Flink
- RunInference
- 搭配使用 GPU 和 Apache Beam
- 以視覺化方式呈現資料
- 基本作業
- 元素級別作業
- 匯總資料
- Windows
- I/O 作業
- 串流
- 最終練習
- 設定
n,將結果集限制為最多顯示n個元素,例如 20 個。如未設定n,預設行為是列出擷取到的最新元素,直到來源錄製結束為止。 - 設定
duration,將結果集限制為從來源錄音開頭算起,指定秒數的資料。如果未設定duration,預設動作是列出所有元素,直到錄製結束為止。 按一下 JupyterLab 頂端選單列的
Interactive Beam。在下拉式選單中找到Open Inspector,然後按一下即可開啟檢查器。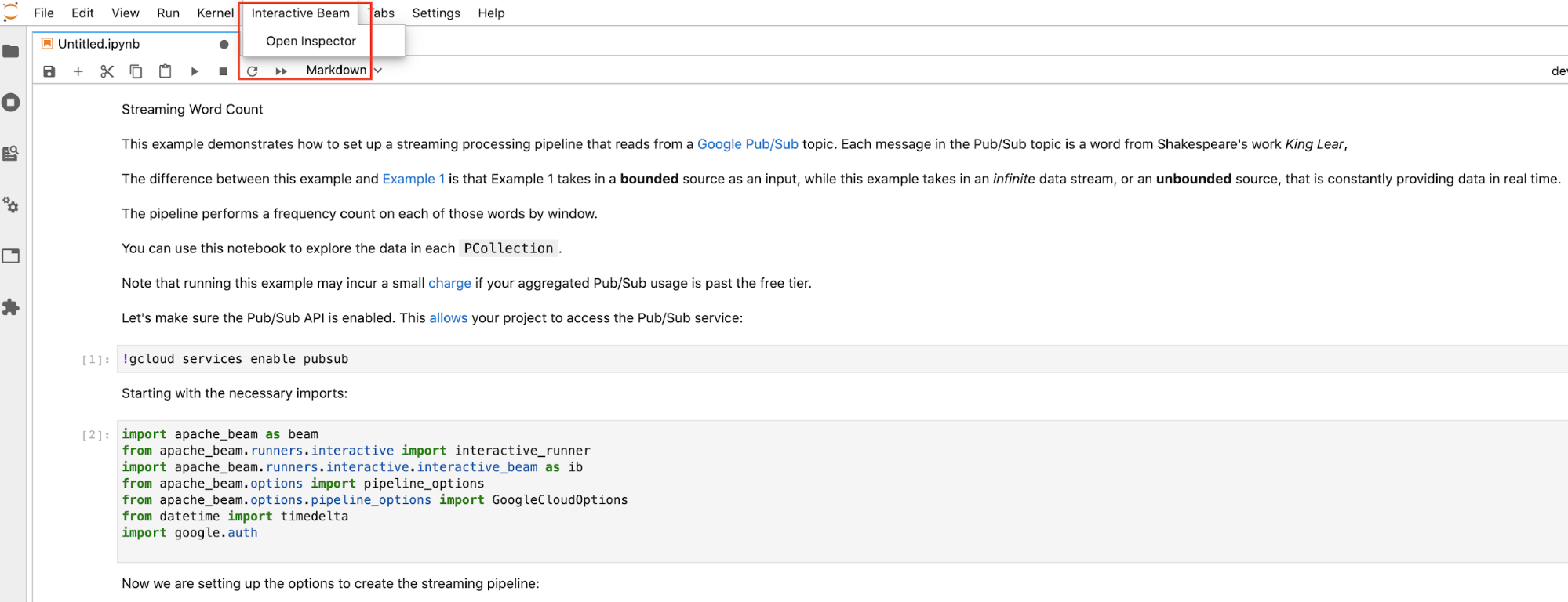
使用啟動器頁面。如果沒有開啟啟動器頁面,請按一下
File->New Launcher開啟。在啟動器頁面中找出Interactive Beam,然後按一下Open Inspector開啟檢查器。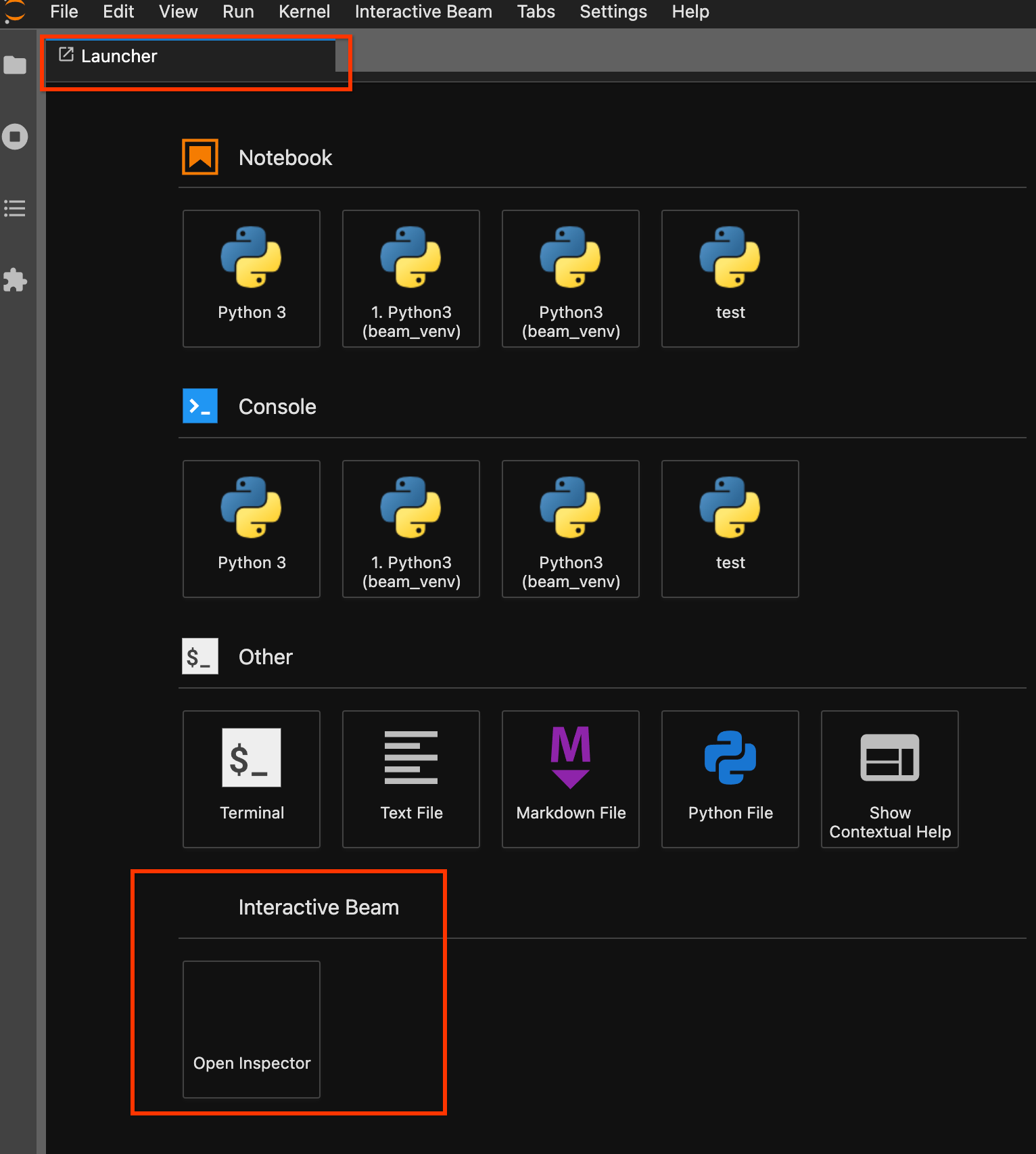
使用指令區塊面板。在 JupyterLab 選單列中,依序點選
View>Activate Command Palette。在對話方塊中搜尋Interactive Beam,列出擴充功能的所有選項。按一下Open Inspector開啟檢查器。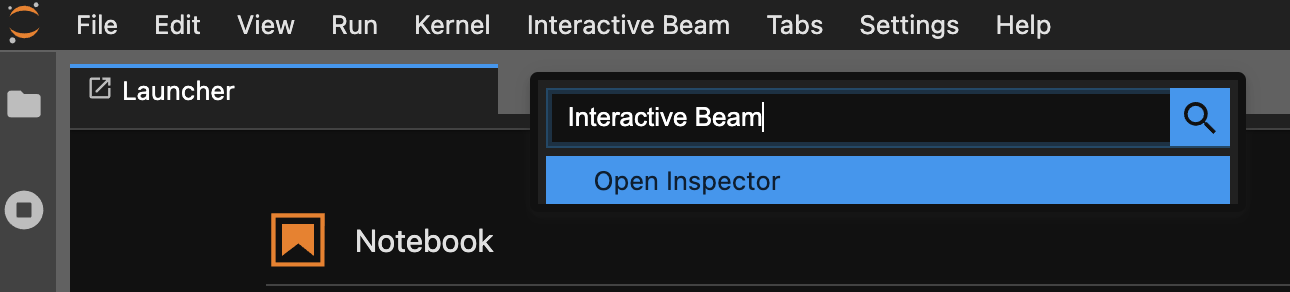
如果只開啟一個筆記本,檢查器會自動連線至該筆記本。
如果沒有開啟任何筆記本,系統會顯示對話方塊,供您選取核心。
如果開啟多個筆記本,系統會顯示對話方塊,方便你選取筆記本工作階段。

如果是
PCollection,檢查器會算繪其資料 (如果資料仍適用於無界限的PCollections,則為動態),並在點選APPLY按鈕後,提供額外的小工具來調整視覺化效果。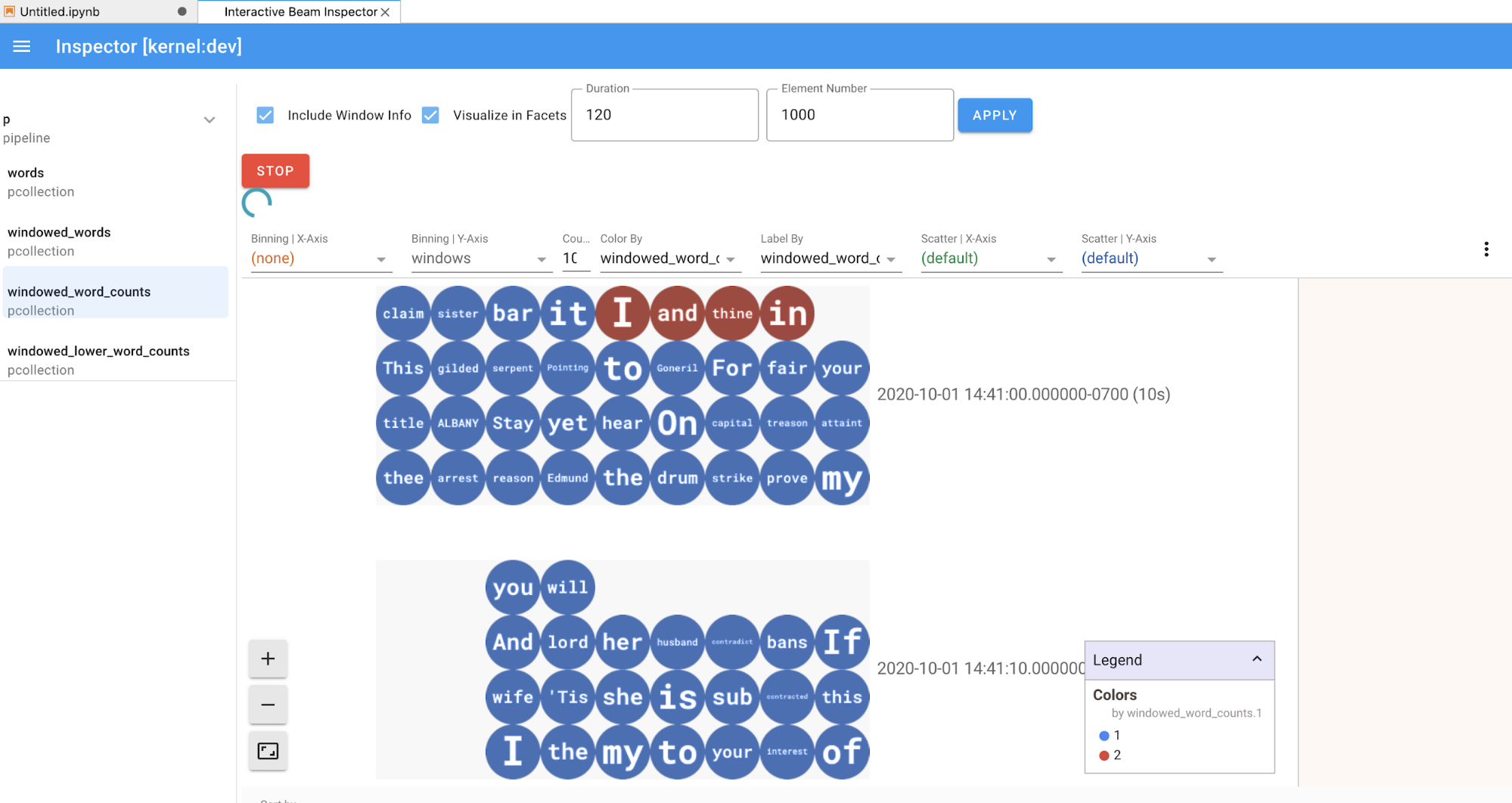
由於檢查器和開啟的筆記本共用同一個核心工作階段,因此兩者會互相阻礙執行作業。舉例來說,如果筆記本忙於執行程式碼,檢查器就不會更新,直到筆記本完成該執行作業為止。反之,如果您想在檢查器動態顯示
PCollection時,立即在筆記本中執行程式碼,則必須點選STOP按鈕停止顯示,並預先將核心發布至筆記本。如果是管道,檢查器會顯示管道圖。
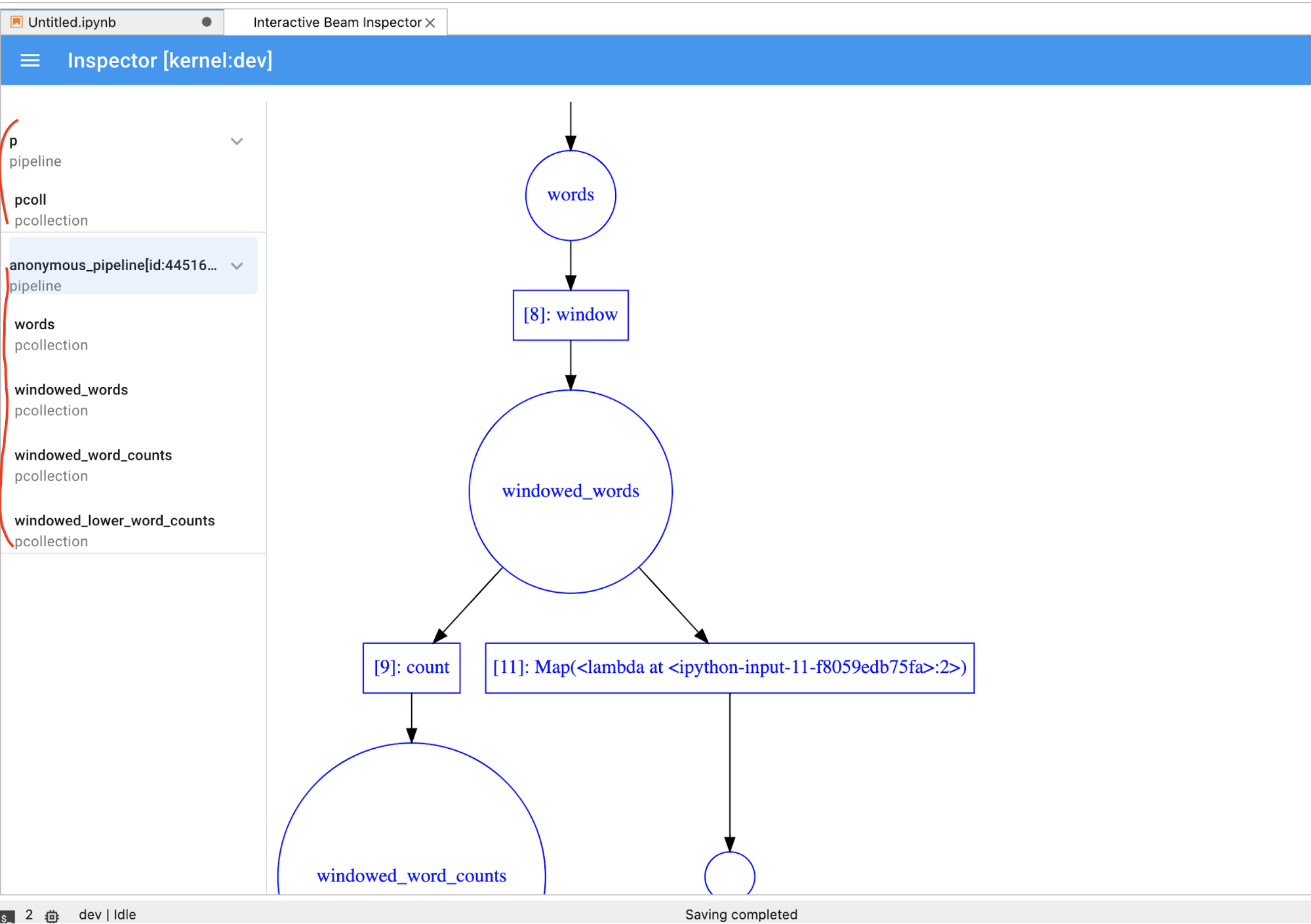
- 磁碟上管道所有錄音的總大小 (以位元組為單位)
- 背景錄製作業的開始時間 (自 Unix Epoch 紀元時間開始算起,以秒為單位)
- 背景錄製工作的目前管道狀態
- 管道的 Python 變數
- 選用:使用筆記本執行 Dataflow 工作前,請先重新啟動核心、重新執行所有儲存格,並驗證輸出內容。如果略過這個步驟,筆記本中隱藏的狀態可能會影響管道物件中的工作圖。
- 啟用 Dataflow API。
新增下列匯入陳述式:
from apache_beam.runners import DataflowRunner傳入管道選項。
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)您可以調整參數值。例如,您可以將
region值從us-central1變更為其他值。使用
DataflowRunner執行管道。這個步驟會在 Dataflow 服務上執行工作。runner = DataflowRunner() runner.run_pipeline(p, options=options)p是來自「建立管道」的管道物件。建立或連結永久磁碟。按照操作說明使用
ssh連線至筆記本執行個體的 VM,並在開啟的 Cloud Shell 中發出指令。請記下永久磁碟的掛接目錄,例如
/mnt/myDisk。編輯筆記本執行個體的 VM 詳細資料,在
Custom metadata中新增項目:鍵 -container-custom-params;值 --v /mnt/myDisk:/mnt/myDisk。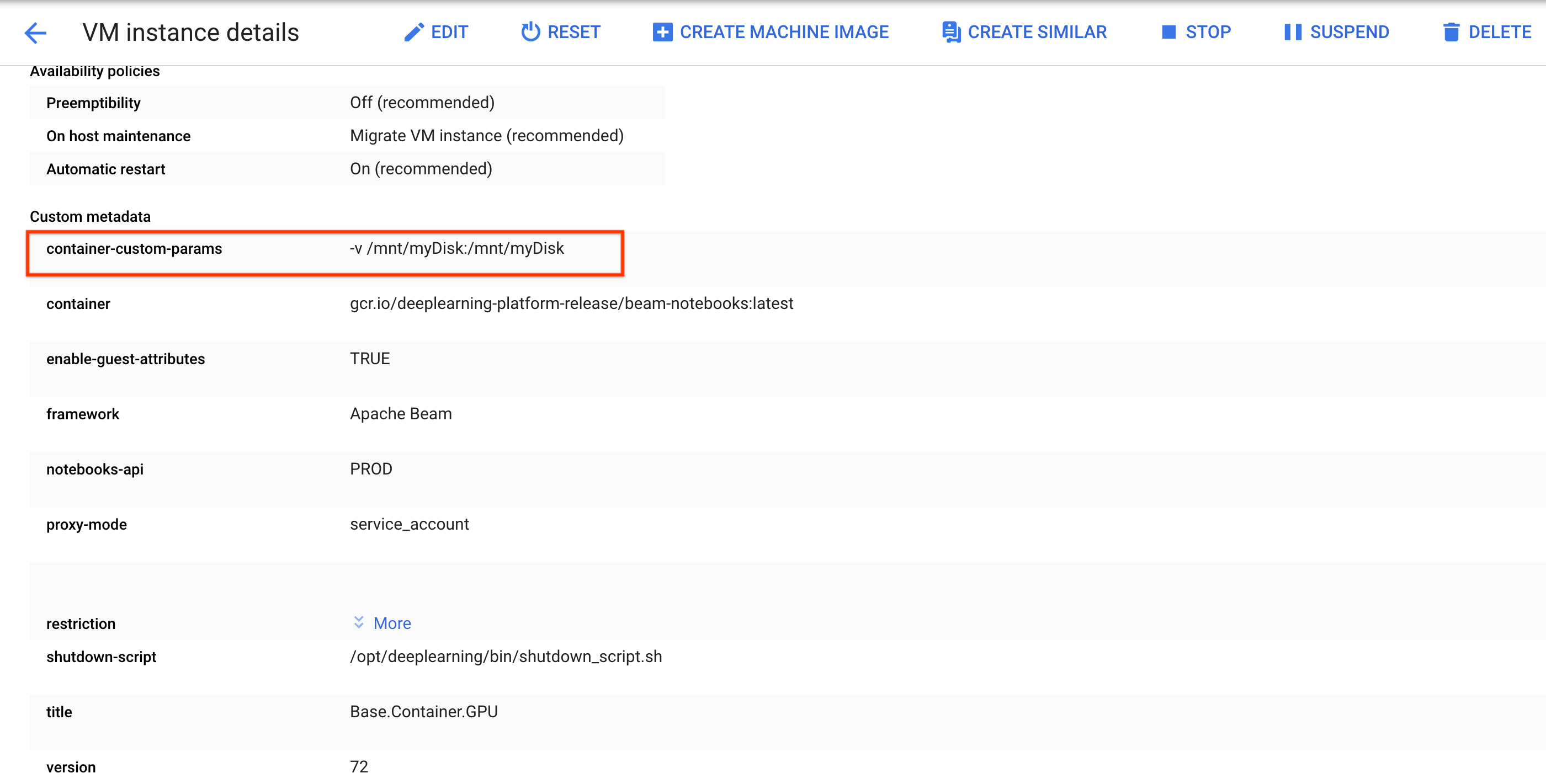
按一下 [儲存]。
如要更新這些變更,請重設筆記本執行個體。
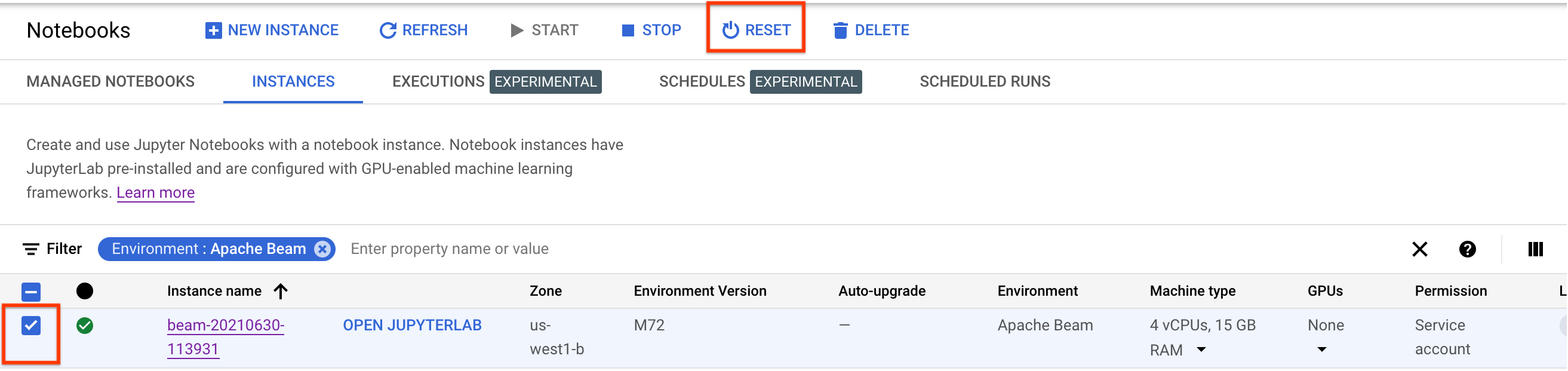
重設後,按一下「Open JupyterLab」。JupyterLab UI 可能需要一段時間才能使用。使用者介面顯示後,請開啟終端機並執行下列指令:
ls -al /mnt應該會列出/mnt/myDisk目錄。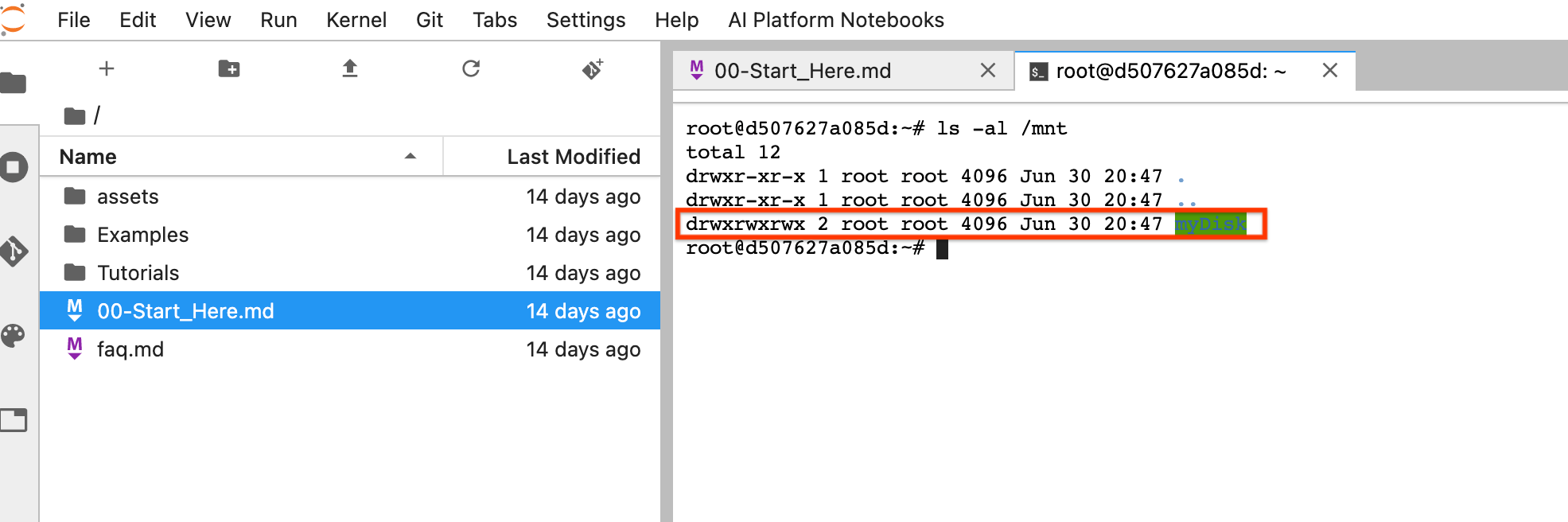
- 瞭解如何搭配使用 Apache Beam 筆記本的進階功能。進階功能包括下列工作流程:
建立 Apache Beam 筆記本執行個體前,請為使用其他服務 (例如 Pub/Sub) 的管道啟用額外 API。
如未指定,筆記本執行個體會由預設的 Compute Engine 服務帳戶執行,並具備 IAM 專案編輯者角色。如果專案明確限制服務帳戶的角色,請確認該帳戶仍有足夠的授權可執行筆記本。舉例來說,從 Pub/Sub 主題讀取資料會隱含建立訂閱項目,而您的服務帳戶需要 IAM Pub/Sub 編輯者角色。相較之下,從 Pub/Sub 訂閱項目讀取資料只需要 IAM Pub/Sub 訂閱者角色。
完成本指南後,請刪除您建立的資源,以免系統繼續計費。詳情請參閱清除所用資源一節。
啟動 Apache Beam 筆記本執行個體
選用:安裝依附元件
Apache Beam 筆記本已安裝 Apache Beam 和Google Cloud 連接器依附元件。如果管線包含依附於第三方程式庫的自訂連線器或自訂 PTransforms,請在建立筆記本執行個體後安裝這些程式庫。
Apache Beam 筆記本範例
建立筆記本執行個體後,請在 JupyterLab 中開啟。在 JupyterLab 側欄的「Files」分頁中,「Examples」資料夾包含範例筆記本。如要進一步瞭解如何使用 JupyterLab 檔案,請參閱 JupyterLab 使用者指南中的「使用檔案」。
可用的筆記本如下:
「Tutorials」資料夾包含其他教學課程,說明 Apache Beam 的基本概念。以下是可用的教學課程:
這些筆記本包含說明文字和註解程式碼區塊,可協助您瞭解 Apache Beam 概念和 API 用法。教學課程也會提供練習,讓您實際運用所學概念。
以下各節會使用「Streaming Word Count」筆記本中的程式碼範例。本指南中的程式碼片段與「Streaming Word Count」筆記本中的程式碼片段可能略有差異。
建立筆記本執行個體
依序前往「File」>「New」>「Notebook」,然後選取 Apache Beam 2.22 以上版本。
Apache Beam 筆記本是根據 Apache Beam SDK 的主要分支版本建構而成。也就是說,筆記本 UI 中顯示的最新核心版本,可能比最近發布的 SDK 版本還新。
Apache Beam 已安裝在筆記本執行個體上,因此請在筆記本中加入 interactive_runner 和 interactive_beam 模組。
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
如果筆記本使用其他 Google API,請新增下列匯入陳述式:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
設定互動選項
下一行會設定 InteractiveRunner 從無界限來源記錄資料的時間量。在本範例中,時間長度設為 10 分鐘。
ib.options.recording_duration = '10m'
您也可以使用 recording_size_limit 屬性,變更無界限來源的錄音大小限制 (以位元組為單位)。
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
如需其他互動式選項,請參閱 interactive_beam.options 類別。
建立管道
使用 InteractiveRunner 物件初始化管道。
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud Platform environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
讀取及以圖表呈現資料
下例顯示 Apache Beam 管道,該管道會建立指定 Pub/Sub 主題的訂閱項目,並從該訂閱項目讀取資料。
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
管道會依來源的視窗計算字數。這會建立固定時間區間,每個時間區間的持續時間為 10 秒。
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
資料經過視窗化處理後,系統會計算每個視窗中的字詞。
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
show() 方法會在筆記本中將產生的 PCollection 視覺化。
ib.show(windowed_word_counts, include_window_info=True)
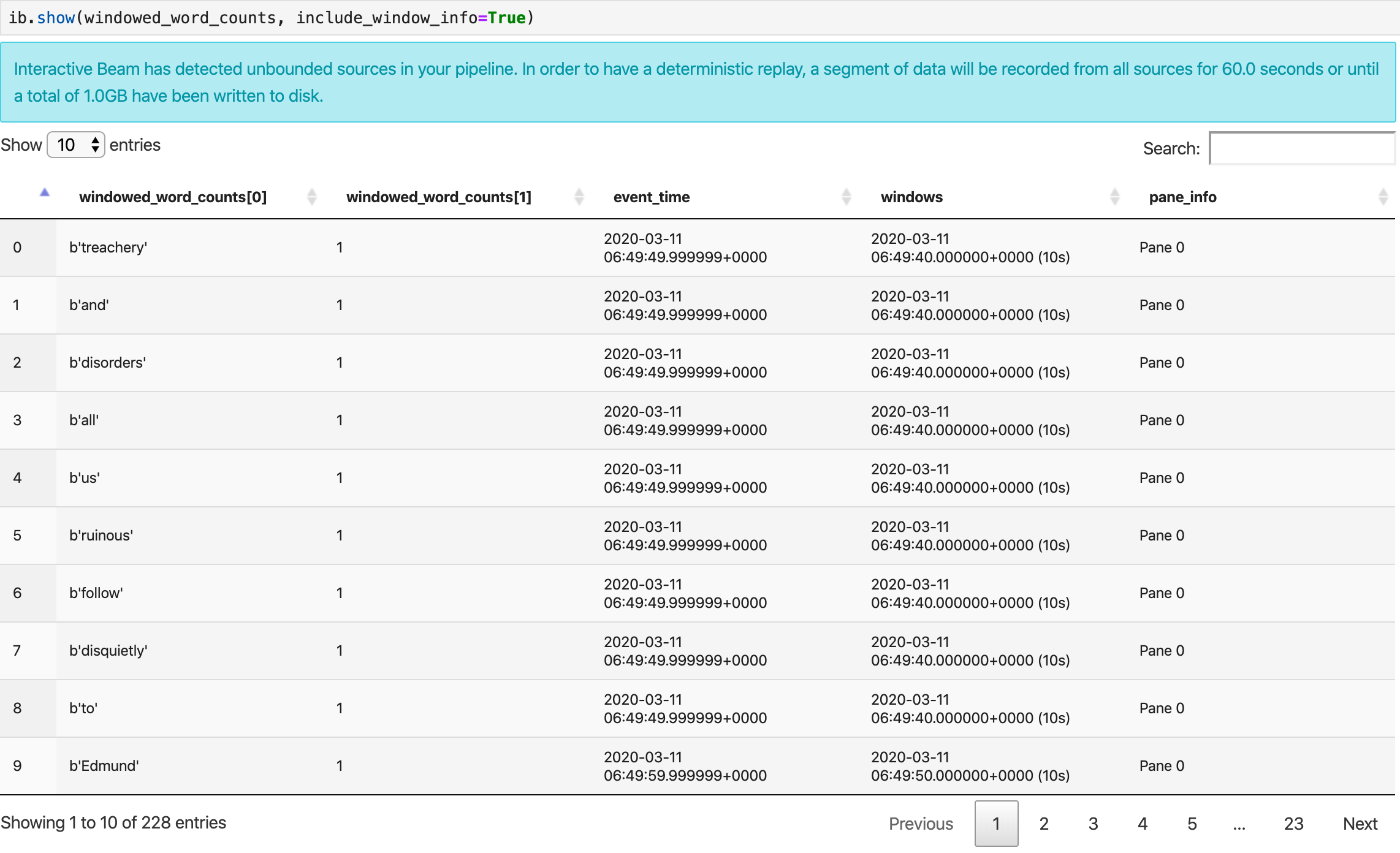
您可以設定兩個選用參數:n 和 duration,將結果集範圍縮小回 show()。
如果同時設定這兩個選用參數,只要達到任一門檻,show() 就會停止。在下列範例中,show() 最多會傳回 20 個元素,這些元素是根據錄製來源的前 30 秒資料計算而得。
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
如要顯示資料的視覺化效果,請將 visualize_data=True 傳遞至 show() 方法。您可以對視覺化內容套用多個篩選器。您可以透過下列視覺化圖表,依標籤和軸篩選:
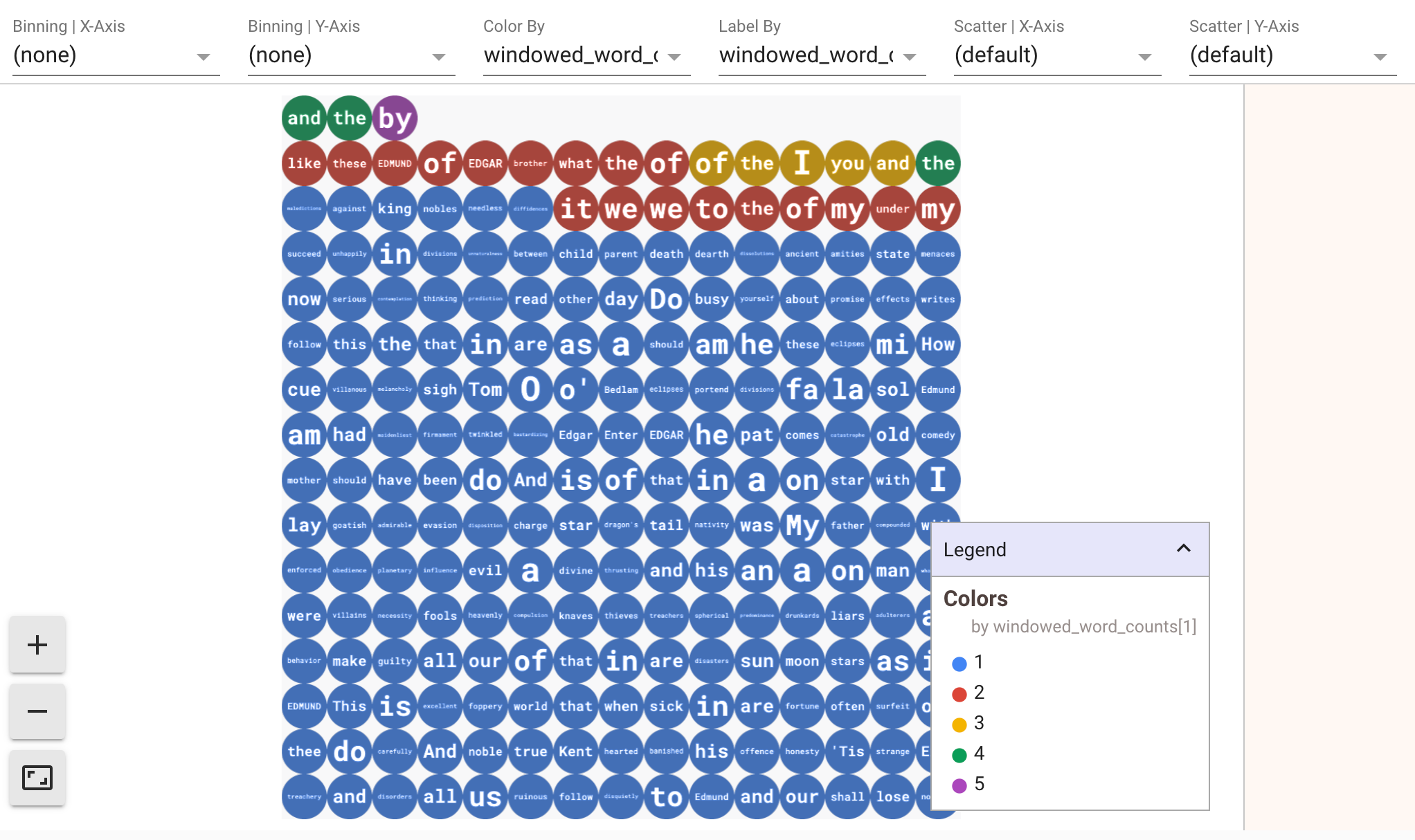
為確保在原型設計串流管道時可重複播放,show() 方法預設會重複使用擷取的資料。如要變更這項行為,讓 show() 方法一律擷取新資料,請設定 interactive_beam.options.enable_capture_replay = False。此外,如果您在筆記本中新增第二個不受限的來源,系統會捨棄先前不受限來源的資料。
Apache Beam 筆記本中另一個實用的視覺化項目是 Pandas DataFrame。以下範例會先將字詞轉換為小寫,然後計算每個字詞的頻率。
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
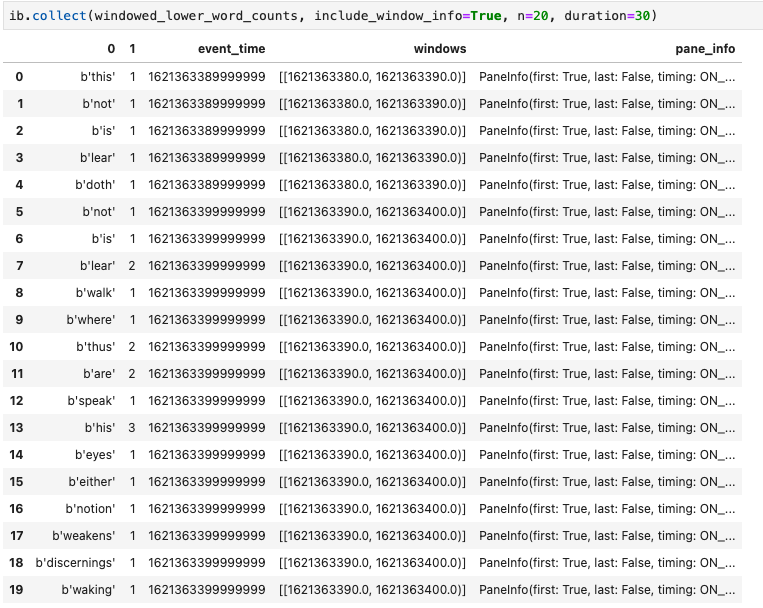
collect() 方法會以 Pandas DataFrame 格式提供輸出內容。
ib.collect(windowed_lower_word_counts, include_window_info=True)
在筆記本開發作業中,編輯及重新執行儲存格是常見做法。在 Apache Beam 筆記本中編輯並重新執行儲存格時,儲存格不會還原原始儲存格中程式碼的預期動作。舉例來說,如果儲存格將 PTransform 新增至管道,重新執行該儲存格會將額外的 PTransform 新增至管道。如要清除狀態,請重新啟動核心,然後重新執行儲存格。
透過互動式 Beam 檢查器將資料視覺化
您可能會發現,不斷呼叫 show() 和 collect() 來內省 PCollection 的資料會造成干擾,尤其是在輸出內容佔用大量螢幕空間,導致難以瀏覽筆記本時。您也可以並列比較多個 PCollections,驗證轉換作業是否正常運作。舉例來說,當一個 PCollection 經過轉換並產生另一個時,對於這些用途,互動式光束檢查工具是便利的解決方案。
互動式 Beam 檢查器以 JupyterLab 擴充功能的形式提供,並預先安裝在 Apache Beam 筆記本中:
apache-beam-jupyterlab-sidepanel
使用擴充功能時,您可以互動式檢查管道的狀態,以及與每個 PCollection 相關聯的資料,不必明確叫用 show() 或 collect()。
開啟檢查器的方式有 3 種:
檢查工具即將開啟時:
建議您先開啟至少一個筆記本,並選取核心,再開啟檢查器。如果您在開啟任何筆記本之前,先使用核心開啟檢查器,之後開啟筆記本並連線至檢查器時,必須從 Use
Kernel from Preferred Session 選取 Interactive Beam Inspector Session。檢查器和筆記本共用相同的工作階段時,兩者會連線,而不是共用從相同核心建立的不同工作階段。從 Start Preferred Kernel 選取相同核心會建立新工作階段,與已開啟筆記本或檢查器的現有工作階段無關。
您可以為開啟的筆記本開啟多個檢查器,並在工作區中隨意拖曳分頁標籤來排列檢查器。
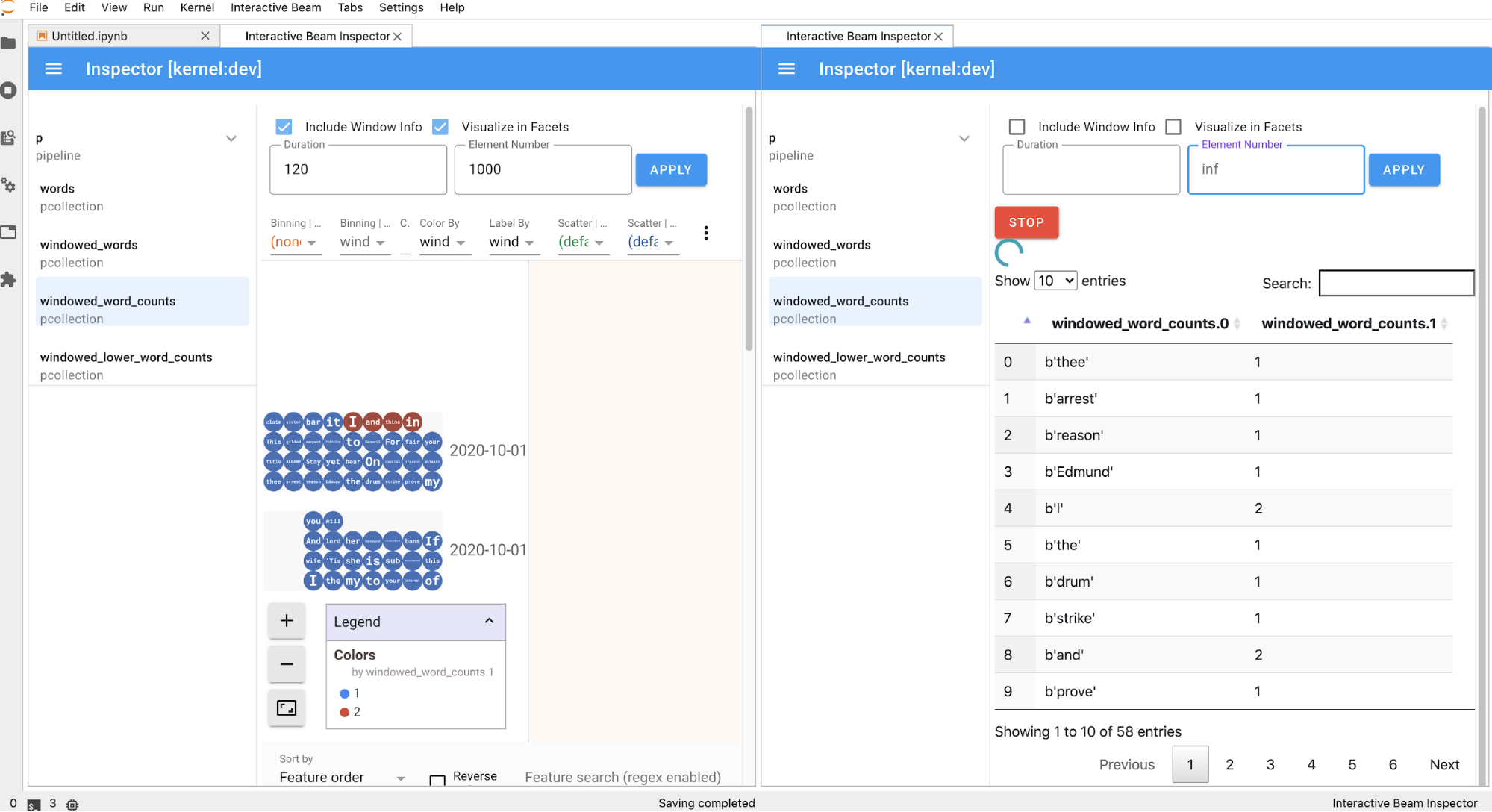
在筆記本中執行儲存格時,檢查器頁面會自動重新整理。這個頁面會列出已連結筆記本中定義的管道和 PCollections。PCollections 會依所屬管道分類,點選管道標題即可收合。
點選管道和 PCollections 清單中的項目時,檢查器會在右側顯示對應的視覺化內容:
您可能會看到匿名管道。這些管道有PCollections可供存取,但主要工作階段不再參照這些管道。例如:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
上一個範例會建立空白管道 p,以及包含一個 PCollection pcoll 的匿名管道。您可以使用 pcoll.pipeline 存取匿名管道。
你可以切換管道和 PCollection 清單,為大型視覺化內容節省空間。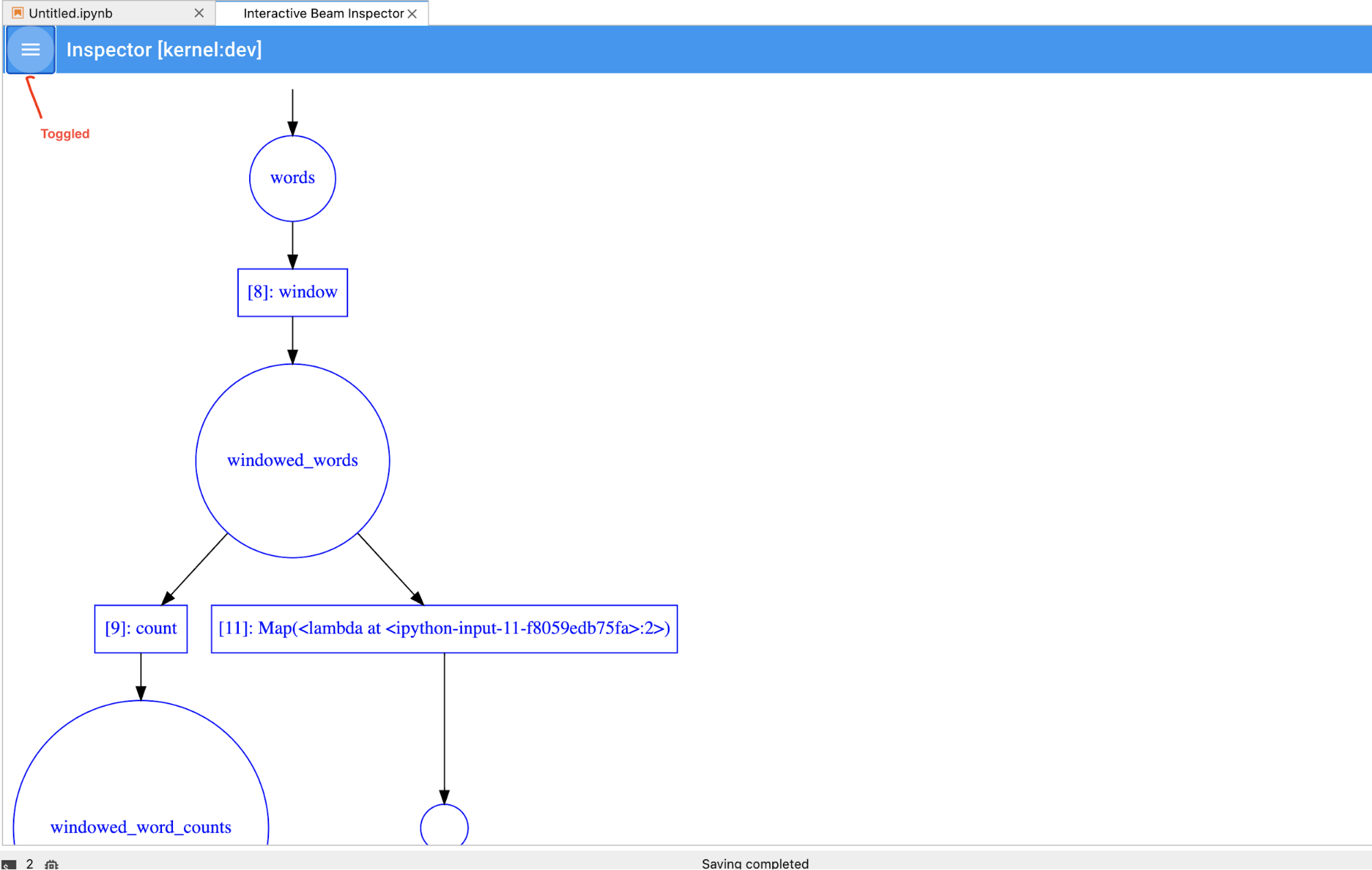
瞭解管道的錄製狀態
除了視覺化,您也可以呼叫 describe,檢查筆記本執行個體中一或多個管道的錄製狀態。
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
describe() 方法提供下列詳細資料:
從筆記本中建立的管道啟動 Dataflow 工作
如需在互動式筆記本中執行這項轉換的範例,請參閱筆記本執行個體中的 Dataflow 字數筆記本。
或者,您也可以將筆記本匯出為可執行的指令碼,使用先前的步驟修改產生的 .py 檔案,然後將管道部署至 Dataflow 服務。
儲存筆記本
您建立的筆記本會儲存在執行中的筆記本例項。如果您在開發期間重設或關閉筆記本執行個體,只要新筆記本是在 /home/jupyter 目錄下建立,就會保留下來。不過,如果刪除筆記本執行個體,系統也會一併刪除這些筆記本。
如要保留筆記本以供日後使用,請將筆記本下載到工作站本機、儲存至 GitHub,或匯出為其他檔案格式。
將筆記本儲存到其他永久磁碟
如要在不同筆記本執行個體中保留筆記本和指令碼等工作內容,請將這些內容儲存在永久磁碟中。
現在你可以將工作儲存至 /mnt/myDisk 目錄。即使刪除筆記本執行個體,永久磁碟仍會保留在專案中。接著,您就可以將這個永久磁碟附加至其他筆記本執行個體。
清除所用資源
使用完 Apache Beam 筆記本執行個體後,請 Google Cloud 關閉筆記本執行個體,清除您建立的資源。