Use o executor interativo do Apache Beam com os notebooks do JupyterLab para concluir as seguintes tarefas:
- Desenvolva pipelines de maneira iterativa.
- Inspecione o gráfico do pipeline.
- Analisa
PCollectionsindividuais em um fluxo de trabalho read-eval-print-loop (REPL).
Esses notebooks do Apache Beam são disponibilizados por meio de notebooks gerenciados pelo usuário do Vertex AI Workbench, um serviço que hospeda máquinas virtuais de notebook pré-instaladas com a ciência de dados mais recente. e frameworks de machine learning. O Dataflow só oferece suporte a instâncias de notebooks gerenciados pelo usuário.
Este guia se concentra nos recursos introduzidos pelos notebooks do Apache Beam, mas não mostra como criar um notebook. Para mais informações sobre o Apache Beam, consulte o guia de programação do Apache Beam.
Suporte e limitações
- Os notebooks do Apache Beam são compatíveis apenas com Python.
- Os segmentos de pipeline do Apache Beam em execução nesses notebooks são executados em um ambiente de teste, e não em um executor do Apache Beam de produção. Para iniciar os notebooks no serviço do Dataflow, exporte os pipelines criados no notebook do Apache Beam. Para mais detalhes, consulte Iniciar jobs do Dataflow a partir de um pipeline criado no seu notebook.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Notebooks APIs.
Antes de criar uma instância de notebook do Apache Beam, ative APIs adicionais para pipelines que usam outros serviços, como o Pub/Sub.
Se não for especificado, a instância do notebook será executada pela conta de serviço padrão do Compute Engine com o papel de editor do projeto do IAM. Se o projeto limitar explicitamente os papéis da conta de serviço, verifique se ela ainda tem autorização suficiente para executar os notebooks. Por exemplo, ler em um tópico do Pub/Sub cria implicitamente uma assinatura, e sua conta de serviço precisa de um papel de editor do Pub/Sub do IAM. Por outro lado, ler em uma assinatura do Pub/Sub requer apenas um papel de assinante do Pub/Sub.
Ao concluir este guia, para evitar o faturamento contínuo, exclua os recursos criados. Para mais detalhes, consulte Limpeza.
Iniciar uma instância de notebook do Apache Beam
No console do Google Cloud, acesse a página Workbench do Dataflow.
Verifique se você está na guia Notebooks gerenciados pelo usuário.
Na barra de ferramentas, clique em Criar novo.
Na seção Ambiente, em Ambiente, selecione Apache Beam.
Opcional: se você quiser executar notebooks em uma GPU, na seção Tipo de máquina, selecione um tipo de máquina que ofereça suporte a GPUs e selecione Instalar driver de GPU NVIDIA automaticamente para mim. Para mais informações, consulte Plataformas de GPU.
Na seção Rede, selecione uma sub-rede para a VM do notebook.
Opcional: se quiser configurar uma instância de notebook personalizada, consulte Criar uma instância de notebooks gerenciados pelo usuário com propriedades específicas.
Clique em Criar. O Dataflow Workbench cria uma nova instância de notebook do Apache Beam.
Após a criação da instância do notebook, o link Abrir JupyterLab fica ativo. Clique em Abrir o JupyterLab.
Opcional: instalar dependências
Os notebooks do Apache Beam já vêm com as dependências do conector
do Apache Beam e do Google Cloud instaladas. Se o pipeline contiver conectores ou PTransforms personalizados que dependem de bibliotecas de terceiros, instale-os depois de criar uma instância de notebook. Para mais informações, consulte Instalar dependências na documentação dos notebooks gerenciados pelo usuário.
Exemplos de notebooks do Apache Beam
Depois de criar uma instância de notebooks gerenciados pelo usuário, abra-a no JupyterLab. Na guia Arquivos, na barra lateral do JupyterLab, a pasta Exemplos contém exemplos de notebooks. Para mais informações sobre como trabalhar com arquivos do JupyterLab, consulte Como trabalhar com arquivos no guia do usuário do JupyterLab.
Os seguintes notebooks estão disponíveis:
- Contagem de palavras
- Contagem de palavras por streaming
- Streaming de dados de corridas de táxi em Nova York
- SQL do Apache Beam em notebooks com comparações com pipelines
- SQL do Apache Beam em notebooks com o Dataflow Runner
- SQL do Apache Beam em notebooks
- Contagem de palavras do Dataflow
- Flink interativo em escala
- RunInference
- Usar GPUs com o Apache Beam
- Visualizar dados
A pasta Tutoriais contém outros tutoriais que explicam os princípios básicos do Apache Beam. Os seguintes tutoriais estão disponíveis:
- Operações básicas
- Operações do Element Wise
- Agregações
- Windows
- Operações de E/S
- Streaming
- Exercícios finais
Esses notebooks incluem texto explicativo e blocos de código comentados para ajudar a entender os conceitos do Apache Beam e o uso da API. Os tutoriais também oferecem exercícios para você praticar os conceitos.
As seções a seguir usam exemplos de código do notebook de contagem de palavras por streaming. Os snippets de código neste guia e o que é encontrado no notebook de contagem de palavras por streaming podem ter pequenas discrepâncias.
Criar uma instância de notebook
Navegue até Arquivo > Novo > Notebook e selecione um kernel Apache Beam 2.22 ou posterior.
Observação: os notebooks do Apache Beam são criados na ramificação principal do SDK do Apache Beam. Ou seja, a versão mais recente do kernel mostrada na interface dos notebooks pode estar à frente da versão de lançamento mais recente do SDK.
O Apache Beam está instalado na instância do notebook. Portanto, inclua os módulos interactive_runner e interactive_beam no notebook.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Se o notebook usar outras APIs do Google, adicione as seguintes instruções de importação:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Definir opções de interatividade
A linha a seguir define por quanto tempo o InteractiveRunner registra dados de uma origem ilimitada. Neste exemplo, a duração está definida para 10 minutos.
ib.options.recording_duration = '10m'
Também é possível alterar o limite de tamanho do registro (em bytes) para uma origem ilimitada usando a property recording_size_limit.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
Para outras opções interativas, consulte a classe interactive_beam.options.
Crie seu pipeline
Inicialize o pipeline usando um objeto InteractiveRunner.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
Ler e visualizar os dados
O exemplo a seguir mostra um pipeline do Apache Beam que cria uma assinatura para o tópico Pub/Sub fornecido e lê a partir dessa assinatura.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
O pipeline conta as palavras por janelas a partir da origem. Ele cria um janelamento fixo, e cada janela tem 10 segundos de duração.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Após a disposição dos dados em janelas, as palavras são contadas por janela.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
O método show() visualiza a PCollection resultante no notebook.
ib.show(windowed_word_counts, include_window_info=True)
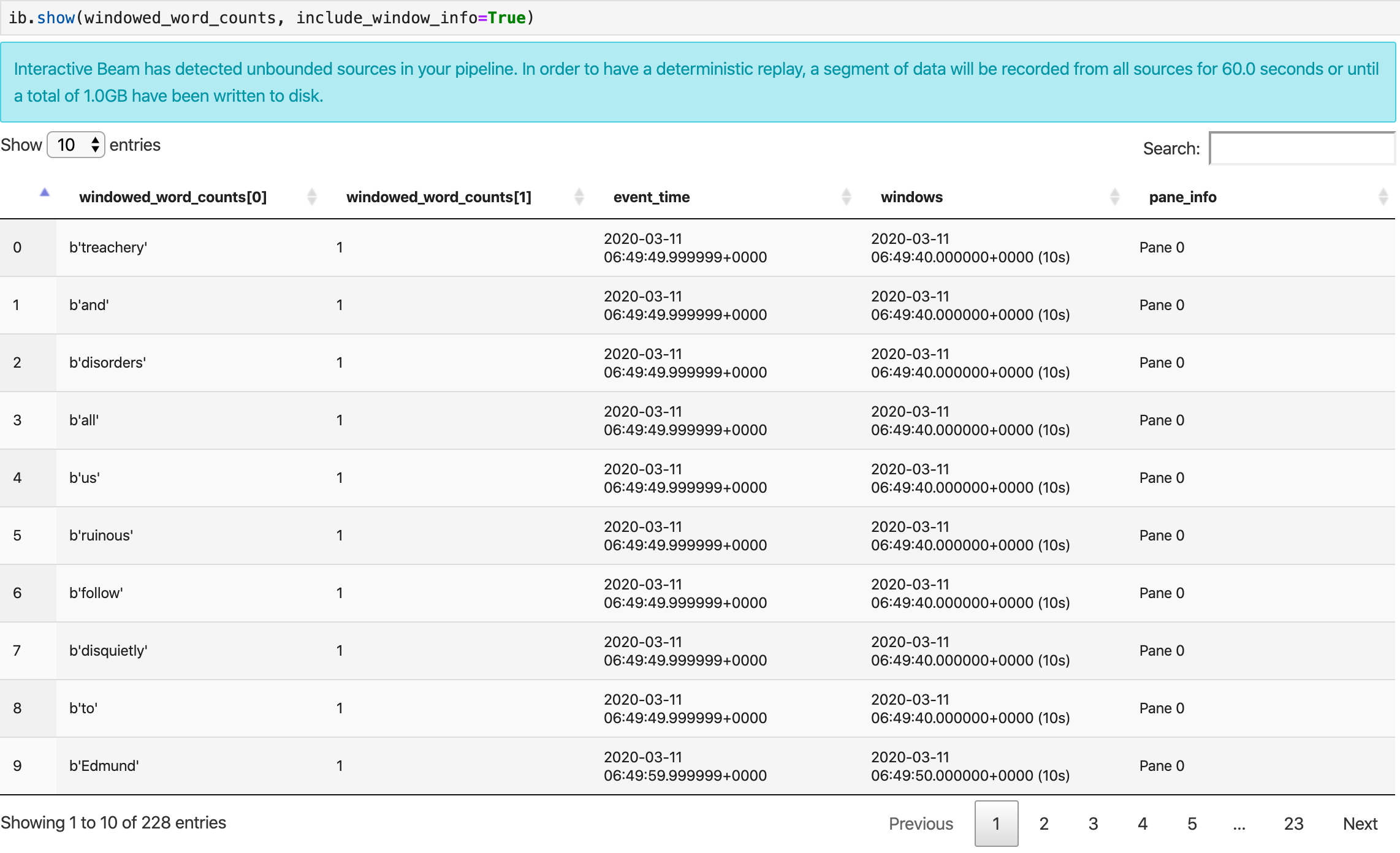
É possível definir o escopo do conjunto de resultados em show() definindo dois parâmetros opcionais: n e duration.
- Defina
npara limitar o conjunto de resultados a fim de exibir um número máximonde elementos, como 20. Sennão estiver definido, o comportamento padrão será listar os elementos mais recentes capturados até a conclusão do registro de origem. - Defina
durationpara limitar o conjunto de resultados a um número específico de segundos em termos de dados com início a partir do registro de origem. Sedurationnão for definido, o comportamento padrão será listar todos os elementos até a conclusão do registro.
Se ambos os parâmetros opcionais forem definidos, show() será interrompido sempre que um limite for atingido. No exemplo a seguir, show() retorna no máximo 20 elementos calculados com base nos primeiros 30 segundos de dados das fontes registradas.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
Para exibir visualizações de seus dados, passe visualize_data=True para o
método show(). É possível aplicar vários filtros às suas visualizações. A
seguinte visualização permite filtrar por etiqueta e eixo:
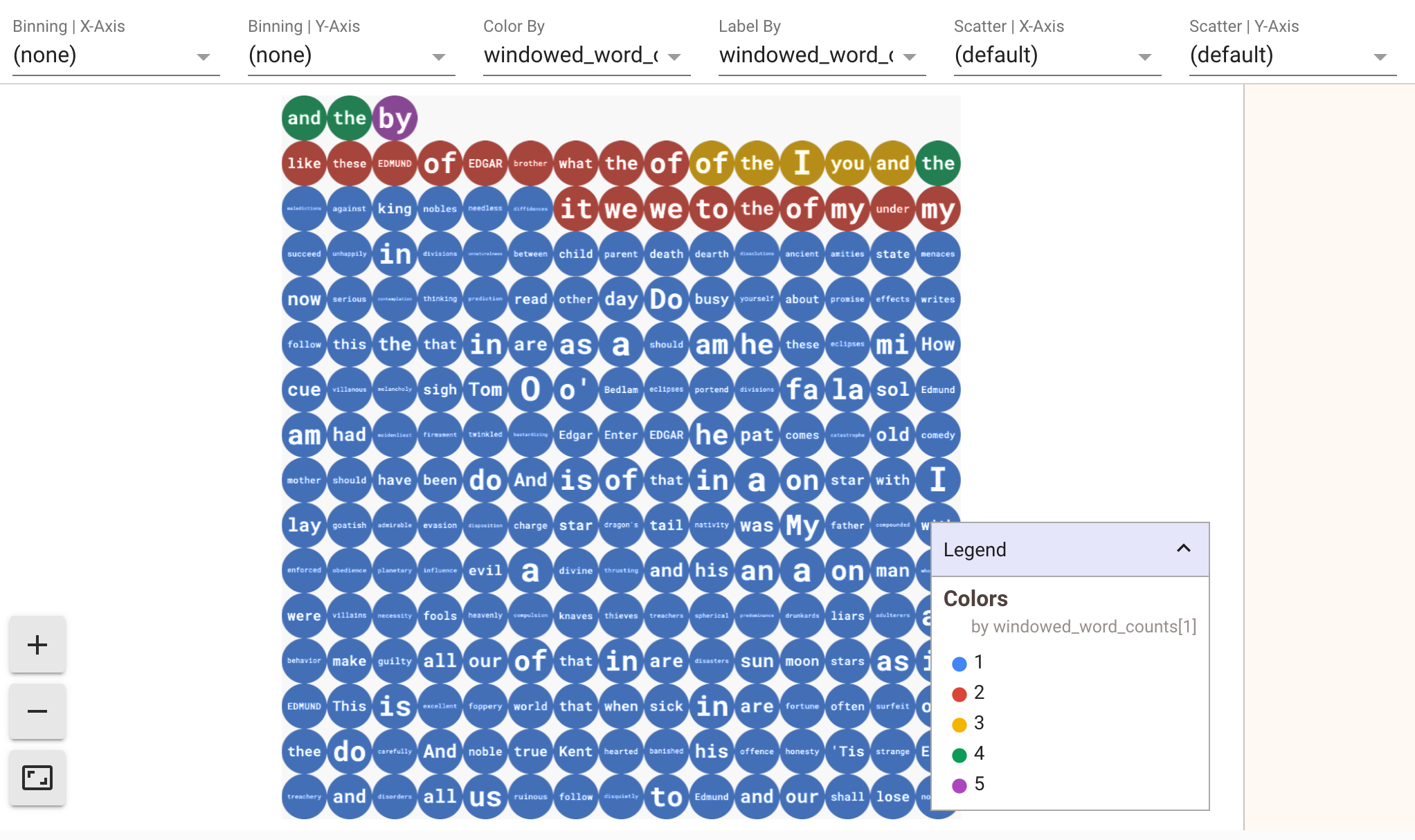
Para garantir a repetibilidade durante a prototipagem de pipelines de streaming, as chamadas do método show() reutilizam os dados capturados por padrão. Para mudar esse comportamento e fazer com que o método show() sempre busque novos dados, defina interactive_beam.options.enable_capture_replay = False. Além disso, se você adicionar uma segunda origem ilimitada ao seu notebook, os dados da origem ilimitada anterior serão descartados.
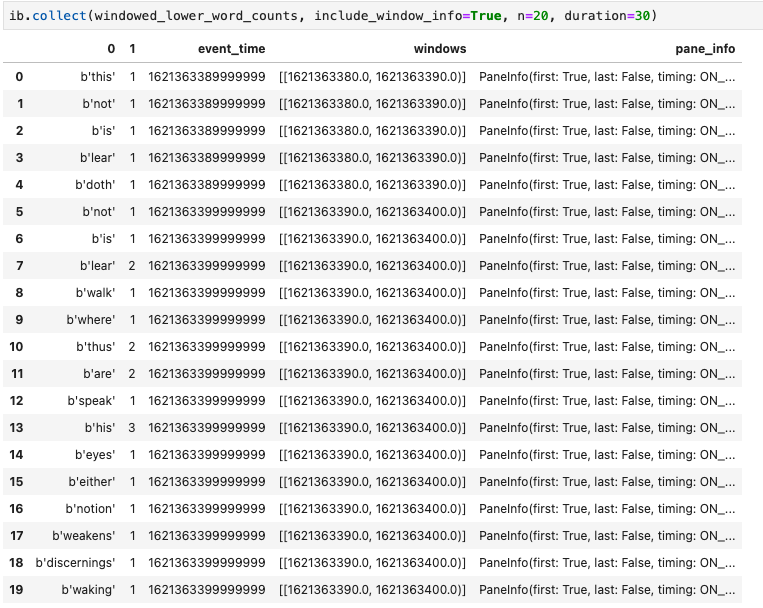
Outra visualização importante em notebooks do Apache Beam é um DataFrame do Pandas. O seguinte exemplo converte as palavras em minúsculas e depois calcula a frequência de cada uma delas.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
O método collect() fornece a saída em um DataFrame de Pandas.
ib.collect(windowed_lower_word_counts, include_window_info=True)
Editar e executar novamente uma célula é uma prática comum no desenvolvimento de notebooks. Quando você edita e executa novamente uma célula em um notebook do Apache Beam, ela não desfaz a ação pretendida do código na célula original. Por exemplo, se uma célula adicionar um PTransform a um pipeline, executar novamente essa célula adicionará outro PTransform ao pipeline. Se quiser limpar o estado, reinicie o kernel e execute as células novamente.
Visualizar os dados com o inspetor do Beam interativo
A introspecção dos dados de uma PCollection chamando constantemente show() e collect() pode ser uma distração, especialmente quando a saída ocupa muito espaço na sua tela e dificulta a navegação pelo notebook. Pode ser conveniente também comparar várias PCollections lado a lado para validar se uma transformação funciona conforme o esperado. Por exemplo, quando uma PCollection passa por uma transformação e produz a outra. Para esses casos de uso, o inspetor do Beam interativo é uma solução mais conveniente.
O inspector do Beam interativo é fornecido como uma extensão do JupyterLab apache-beam-jupyterlab-sidepanel pré-instalada no notebook do Apache Beam. Com a extensão, é possível inspecionar interativamente o estado de pipelines e dados associados a cada PCollection sem invocar explicitamente show() ou collect().
Existem três formas de abrir o inspetor:
Clique em
Interactive Beamna barra de menus superior do JupyterLab. No menu suspenso, localize oOpen Inspectore clique nele para abrir o inspetor.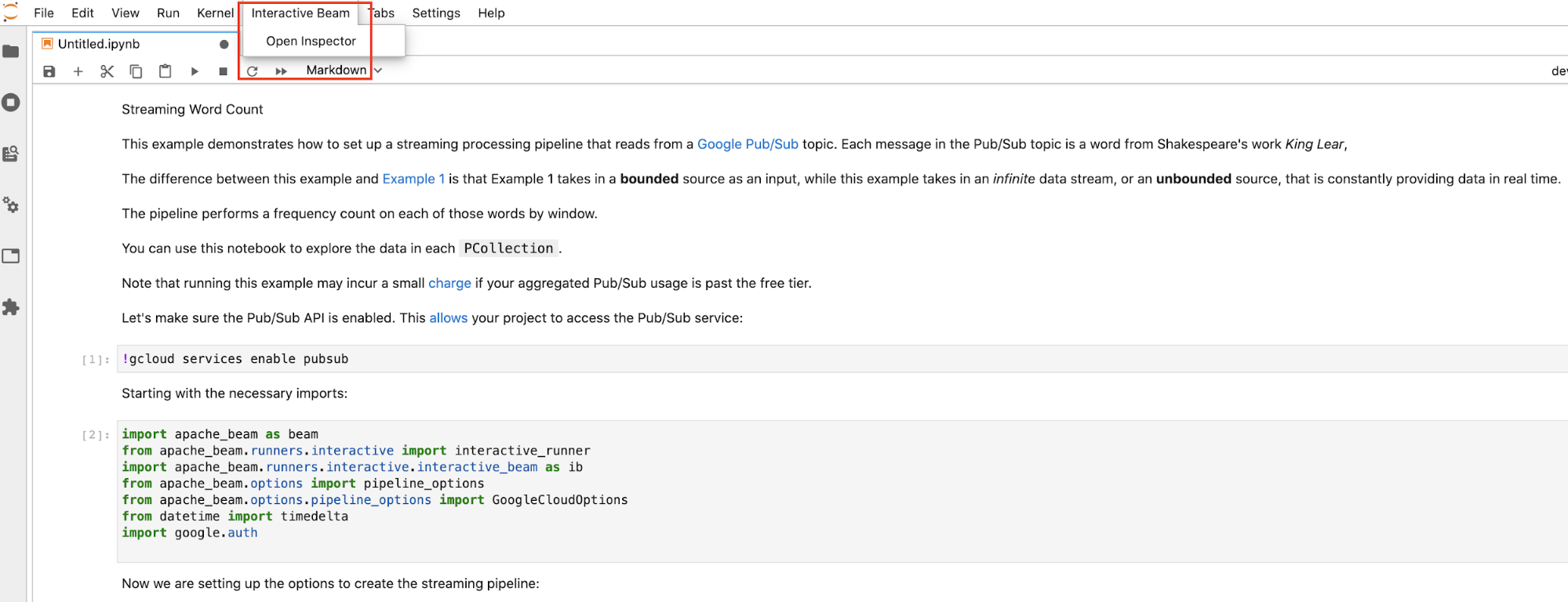
Use a página de início. Se não houver uma página de início aberta, clique em
File->New Launcherpara abri-la. Na página de início, localizeInteractive Beame clique emOpen Inspectorpara abrir o inspetor.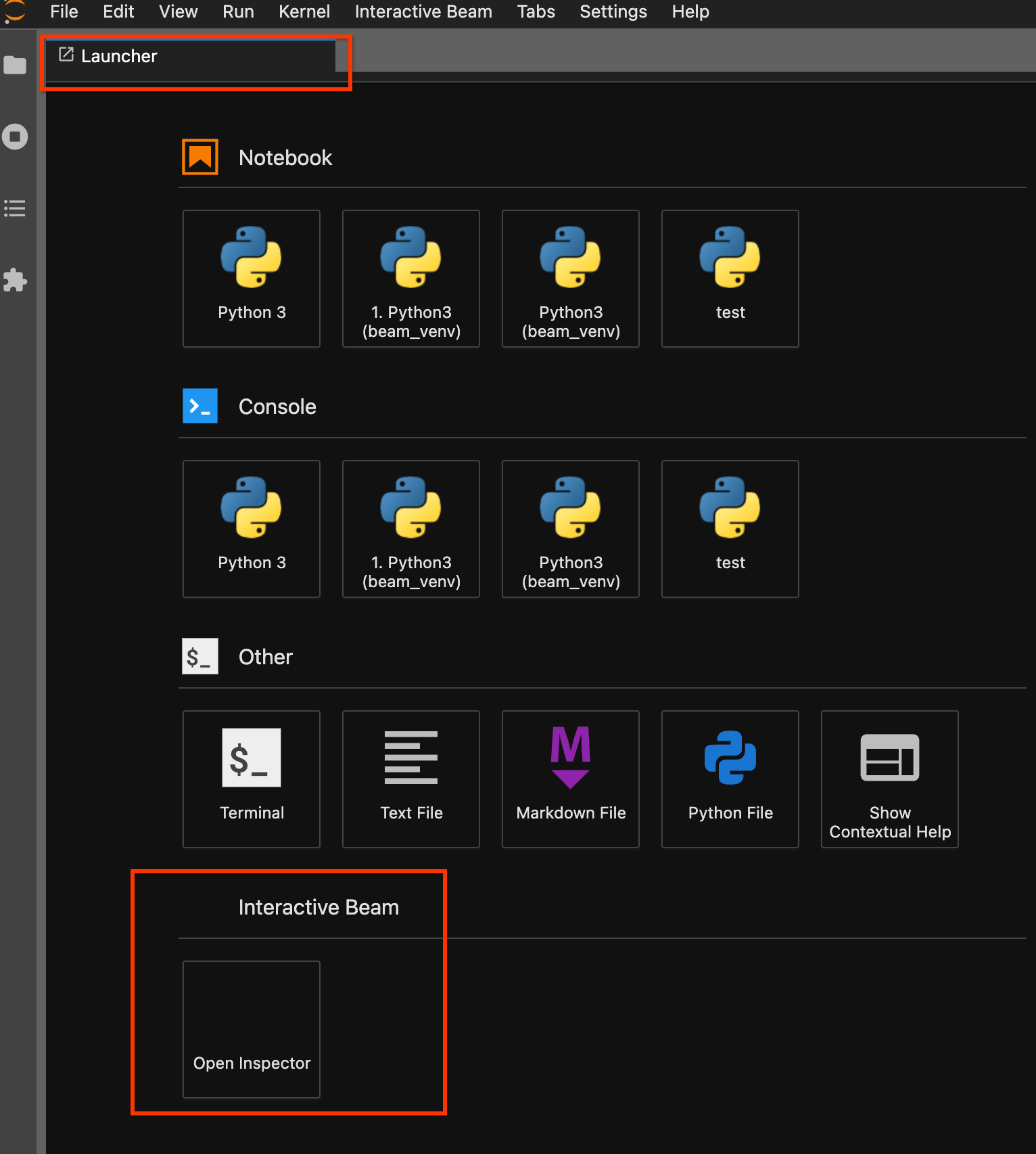
Use a paleta de comandos. Na barra de menu do JupyterLab, clique em
View>Activate Command Palette. Na caixa de diálogo, pesquiseInteractive Beampara listar todas as opções da extensão. Clique emOpen Inspectorpara abrir o inspetor.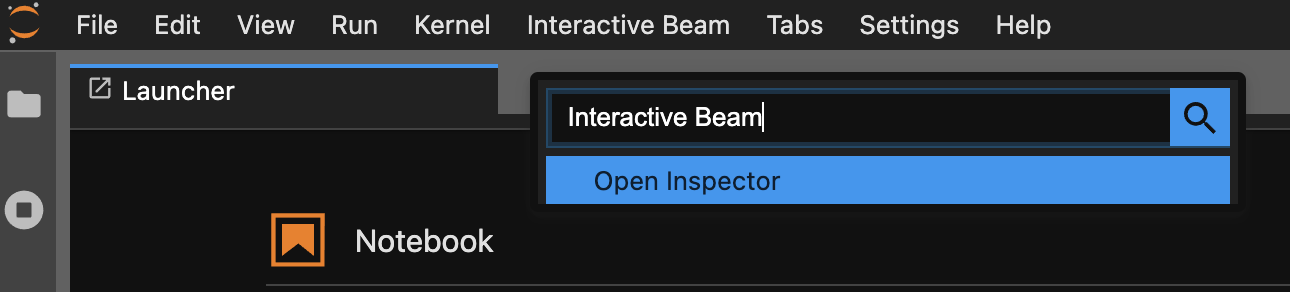
Quando o inspetor está prestes a abrir:
Se houver exatamente um notebook aberto, o inspetor será conectado automaticamente a ele.
Se nenhum notebook estiver aberto, uma caixa de diálogo será exibida para você selecionar um kernel.
Se vários notebooks estiverem abertos, uma caixa de diálogo será exibida para você selecionar a sessão do notebook.
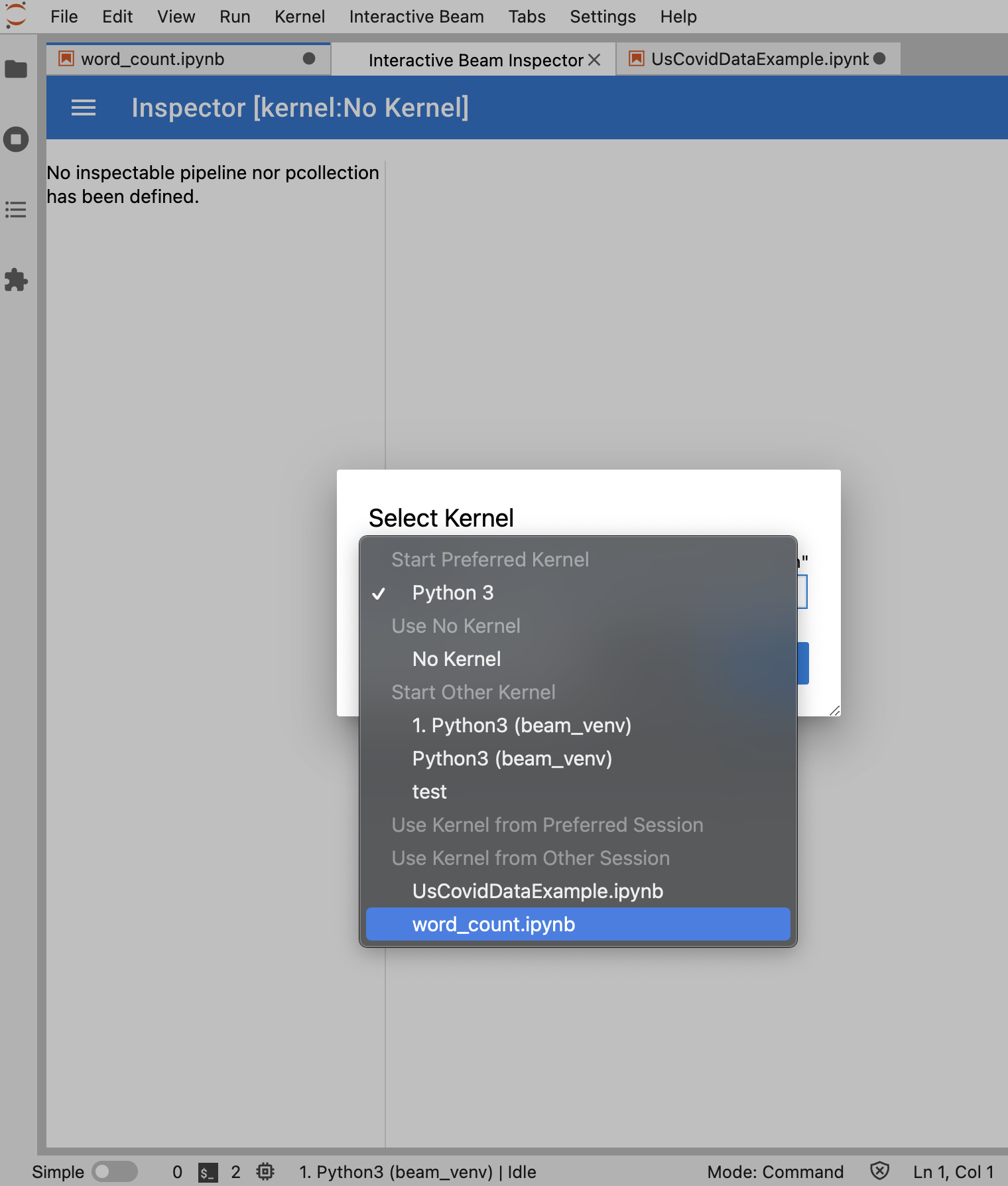
É recomendável abrir pelo menos um notebook e selecionar um kernel para ele antes de abrir o inspetor. Se você abrir um inspetor com um kernel antes de abrir qualquer notebook, mais tarde, ao abrir um notebook para se conectar ao inspetor, será preciso selecionar Interactive Beam Inspector Session em Use
Kernel from Preferred Session. Um inspetor e um notebook são conectados quando
compartilham a mesma sessão, e não sessões diferentes criadas a partir do mesmo
kernel. Selecionar o mesmo kernel em Start Preferred Kernel cria uma nova sessão independente das sessões existentes dos inspetores ou notebooks abertos.
É possível abrir vários inspetores para um notebook aberto e organizar os inspetores arrastando e soltando as guias livremente no espaço de trabalho.
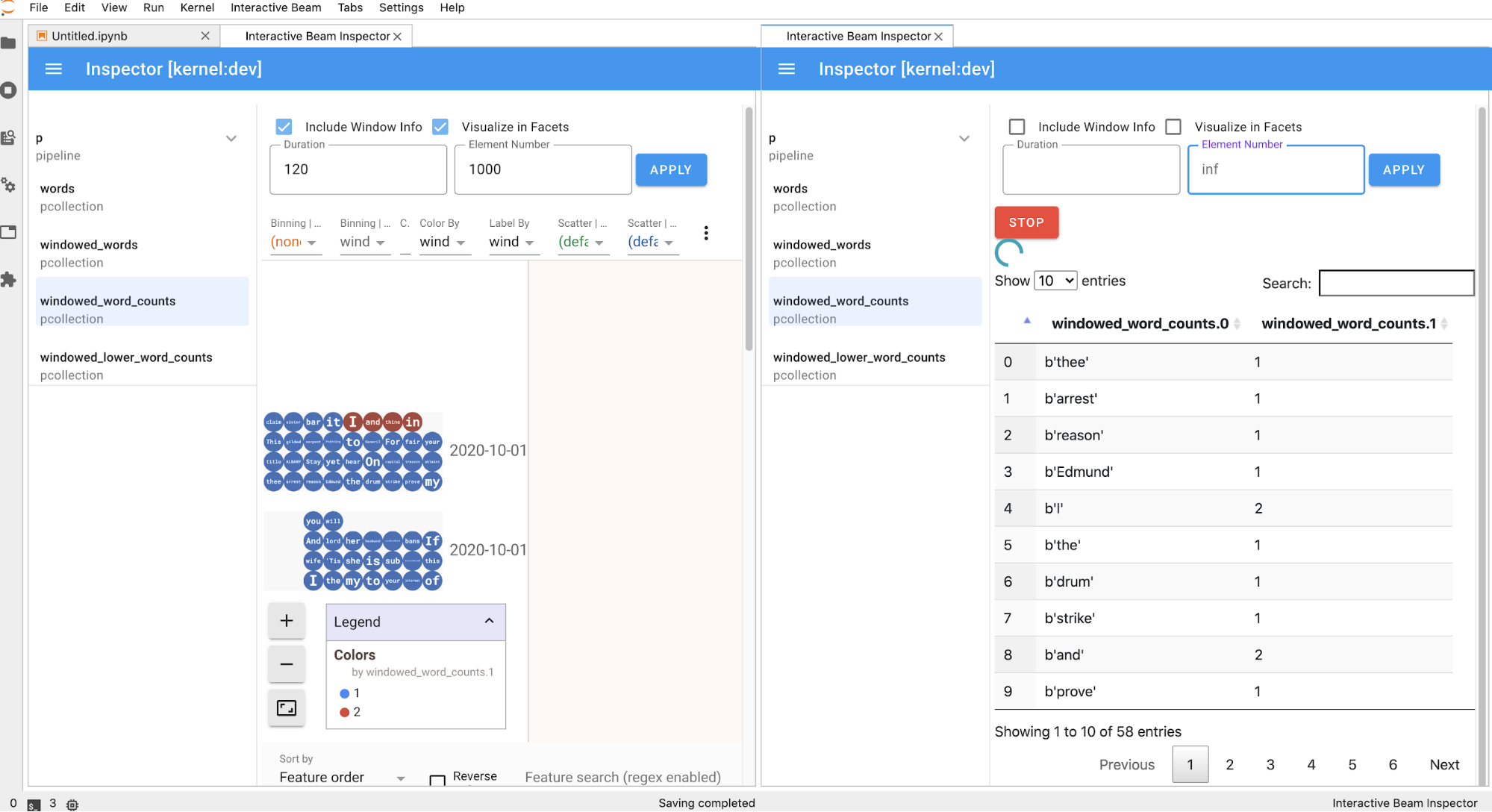
A página do inspetor é atualizada automaticamente quando você executa as células no notebook. A página lista os pipelines e as PCollections definidas no notebook conectado. As PCollections são organizadas pelos pipelines a que pertencem e podem ser recolhidas clicando no pipeline de cabeçalho.
Ao clicar nos itens da lista de pipelines e PCollections, o inspetor renderiza as visualizações correspondentes no lado direito:
Se for uma
PCollection, o inspetor renderizará os dados (dinamicamente quando ainda houver dados paraPCollectionsilimitadas) com widgets adicionais para ajustar a visualização depois de clicar no botãoAPPLY.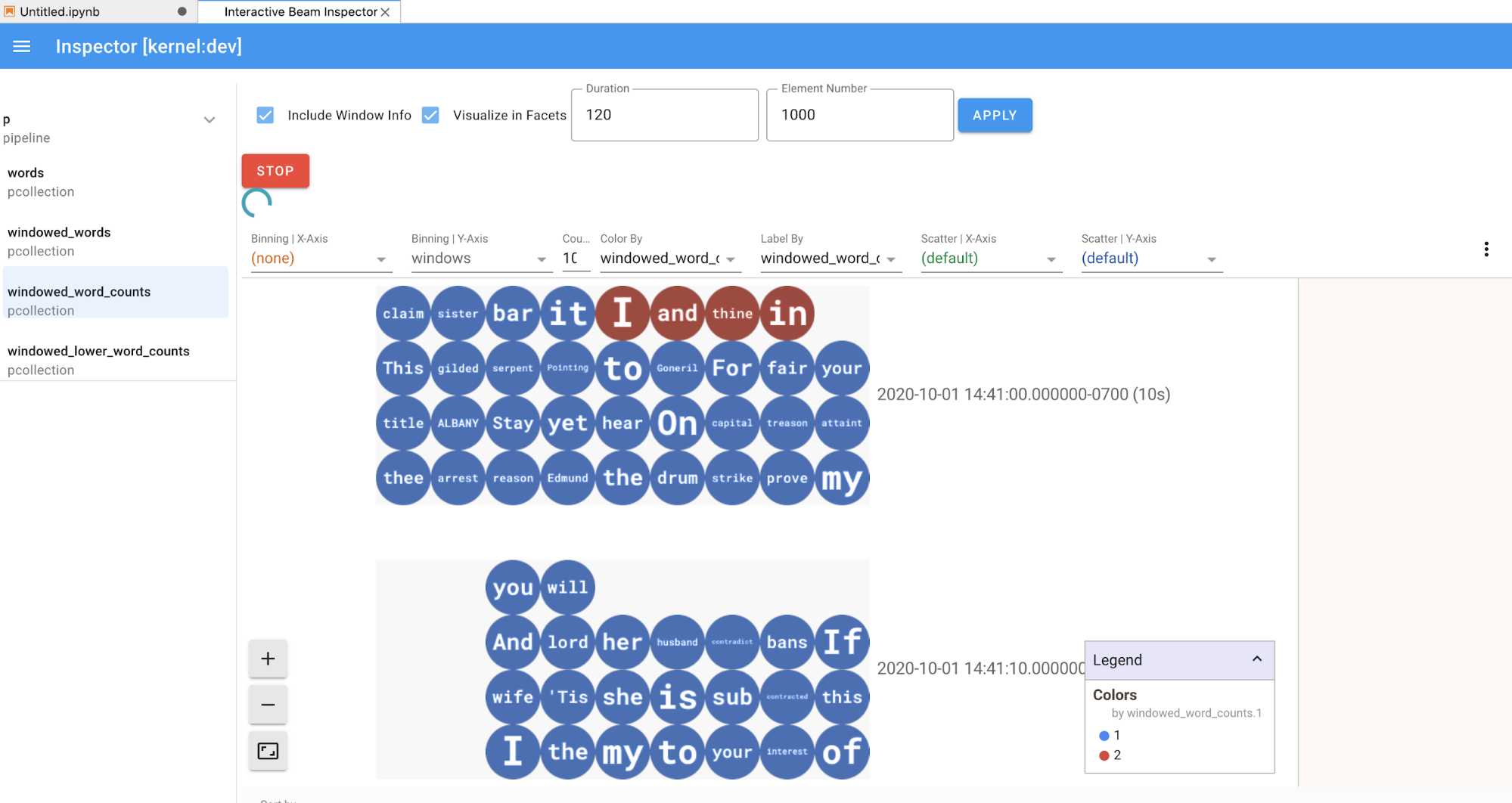
Como o inspetor e o notebook aberto compartilham a mesma sessão de kernel, eles bloqueiam a execução um do outro. Por exemplo, se o notebook estiver ocupado executando um código, o inspetor não será atualizado até que o notebook conclua essa execução. Em contrapartida, se você quiser executar um código imediatamente no seu notebook enquanto o inspetor visualiza uma
PCollectiondinamicamente, será preciso clicar no botãoSTOPpara interromper a visualização e liberar preventivamente o kernel ao notebook.Se for um pipeline, o inspetor exibirá o gráfico do pipeline.
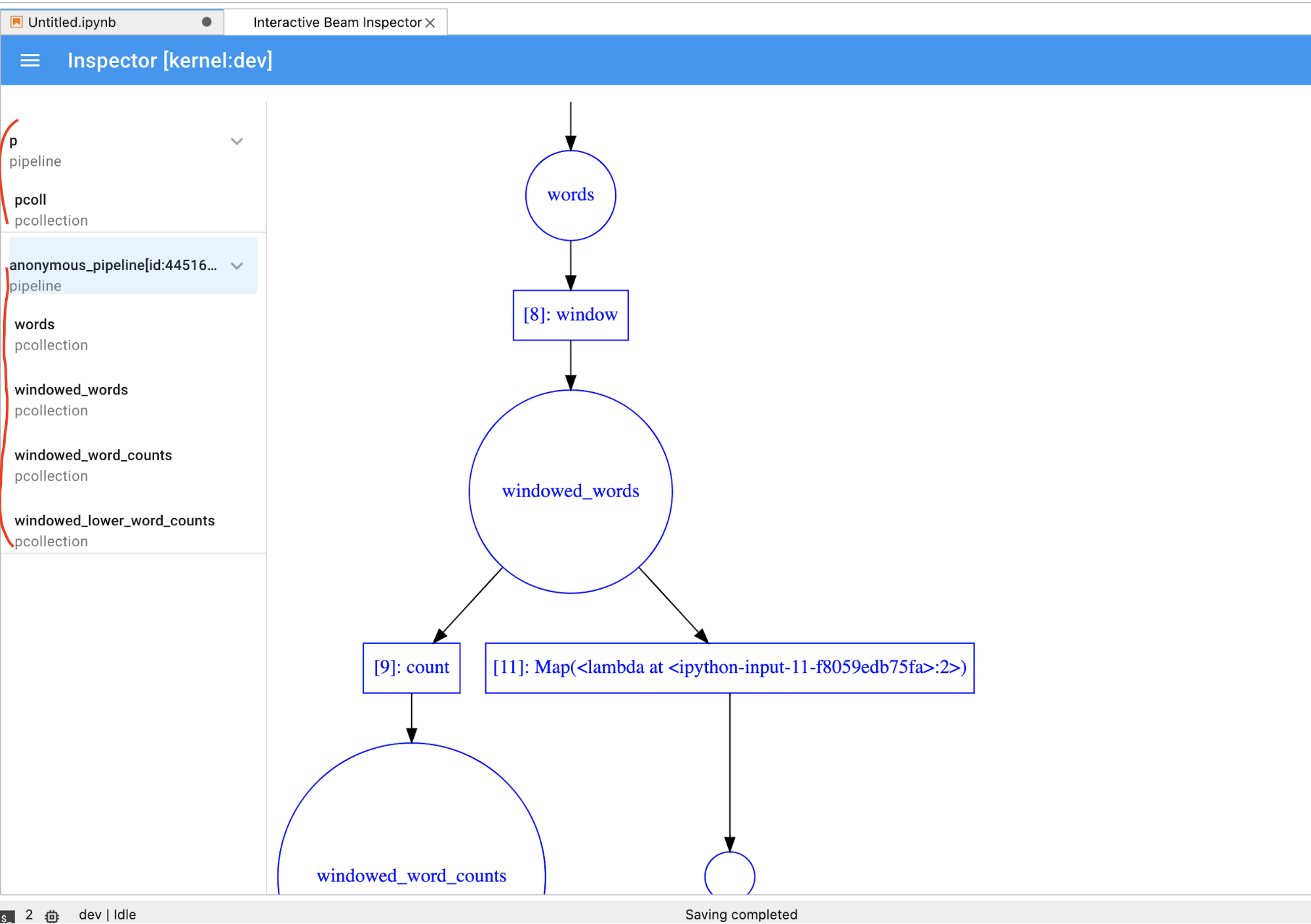
Talvez você note pipelines anônimos. Esses pipelines têm PCollections que podem ser acessadas, mas elas não são mais referenciadas pela sessão principal. Por exemplo:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
O exemplo anterior cria um pipeline vazio p e um pipeline anônimo que contém um PCollection pcoll. É possível acessar o pipeline anônimo usando pcoll.pipeline.
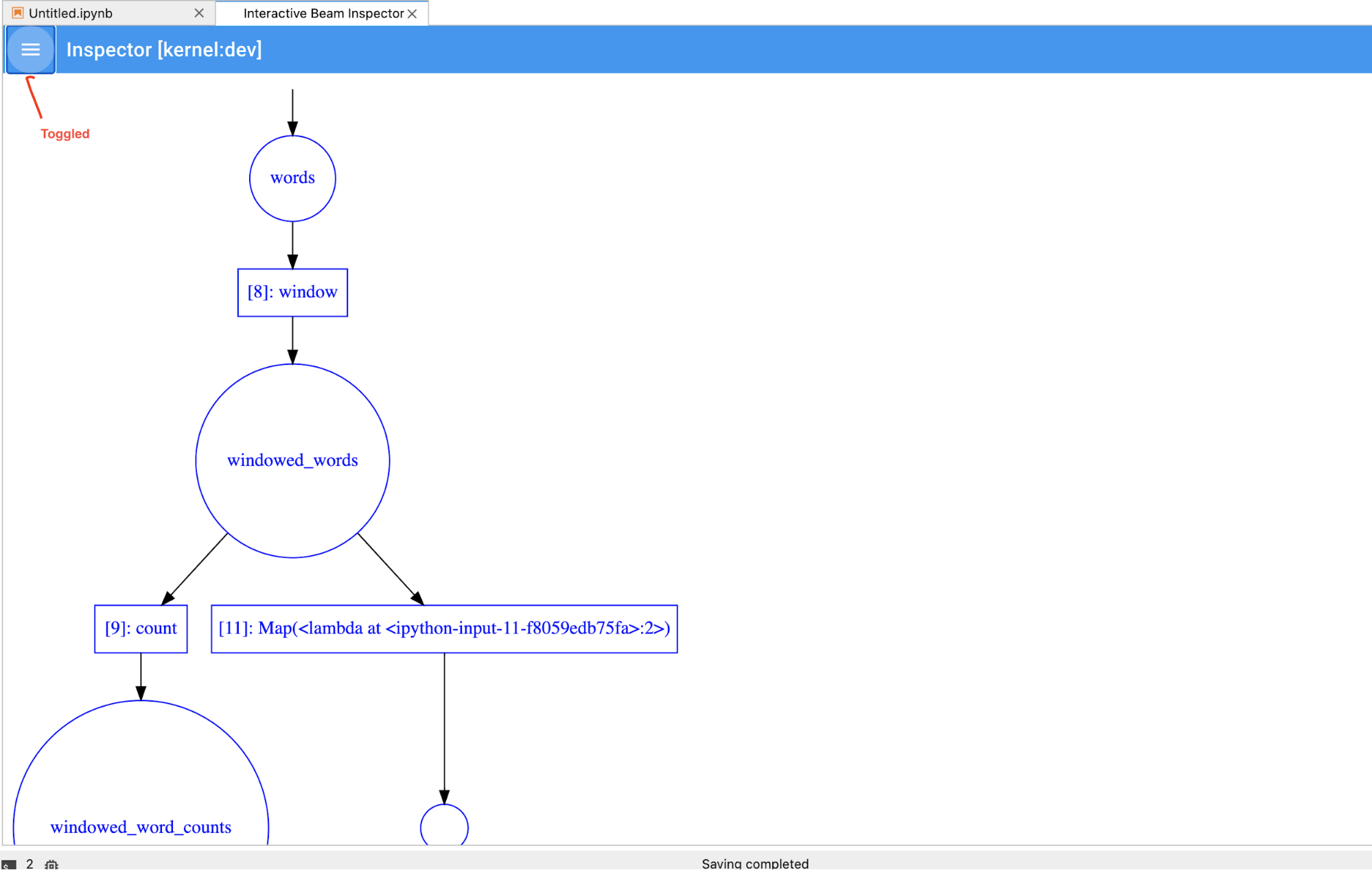
Alterne a lista de pipelines e PCollection para economizar espaço em visualizações grandes.
Noções básicas sobre o status do registro de um pipeline
Além das visualizações, também é possível inspecionar o status de gravação de um ou todos os pipelines na instância do notebook ao chamar describe.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
O método describe() fornece os seguintes detalhes:
- Tamanho total (em bytes) de todas as gravações do pipeline no disco
- Horário de início do início do job de gravação em segundo plano (em segundos, a partir da época do Unix)
- Status atual do pipeline do job de gravação em segundo plano
- Variável Python para o pipeline
Iniciar jobs do Dataflow a partir de um pipeline criado no notebook
- Opcional: antes de usar o notebook para executar jobs do Dataflow, reinicie o kernel, execute novamente todas as células e verifique a saída. Se você pular essa etapa, os estados ocultos no notebook poderão afetar o gráfico de jobs no objeto de pipeline.
- Ative a API Dataflow.
Adicione a seguinte declaração de importação:
from apache_beam.runners import DataflowRunnerPasse as opções do pipeline.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)É possível ajustar os valores dos parâmetros. Por exemplo, é possível alterar o valor
regiondeus-central1.Execute o pipeline com
DataflowRunner. Essa etapa executa o job no serviço do Dataflow.runner = DataflowRunner() runner.run_pipeline(p, options=options)pé um objeto de pipeline como Criar o pipeline.
Para ver um exemplo de como realizar essa conversão em um notebook interativo, consulte o notebook de contagem de palavras do Dataflow na sua instância do notebook.
Também é possível exportar o notebook como um script executável, modificar
.py usando as etapas anteriores e, em seguida, implantar o
pipeline ao serviço
do Dataflow.
Salvar o notebook
Os notebooks criados são salvos localmente na instância do notebook em execução. Se você
redefinir ou
encerrar a instância do notebook durante o desenvolvimento, esses novos notebooks
serão mantidos desde que sejam criados no diretório /home/jupyter.
No entanto, se uma instância de notebook for excluída, isso também acontecerá.
Para manter os notebooks para uso futuro, faça o download deles localmente na estação de trabalho, salve-os no GitHub ou exporte-os para um formato de arquivo diferente.
Salvar seu notebook em discos permanentes adicionais
Se quiser manter seu trabalho com notebooks e scripts em várias instâncias de notebook, armazene-os no Persistent Disk.
Crie ou anexe um disco permanente. Siga as instruções para usar o
sshpara se conectar à VM da instância do notebook e emitir comandos no Cloud Shell aberto.Observe o diretório em que o disco permanente está montado, por exemplo,
/mnt/myDisk.Edite os detalhes da VM da instância do notebook para adicionar uma entrada ao
Custom metadata: chave -container-custom-params; valor --v /mnt/myDisk:/mnt/myDisk.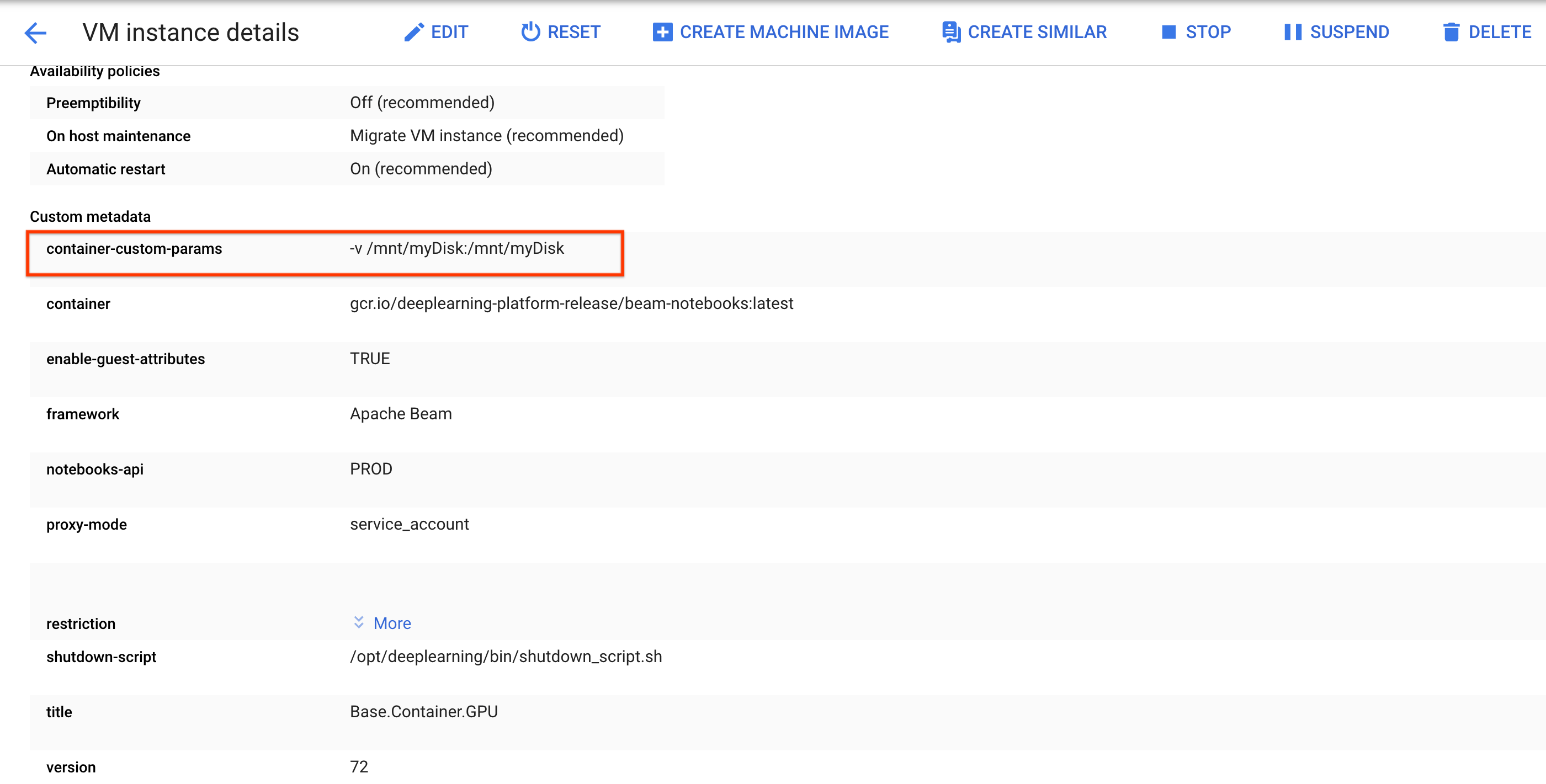
Clique em Salvar.
Para atualizar essas alterações, redefina a instância de notebook.
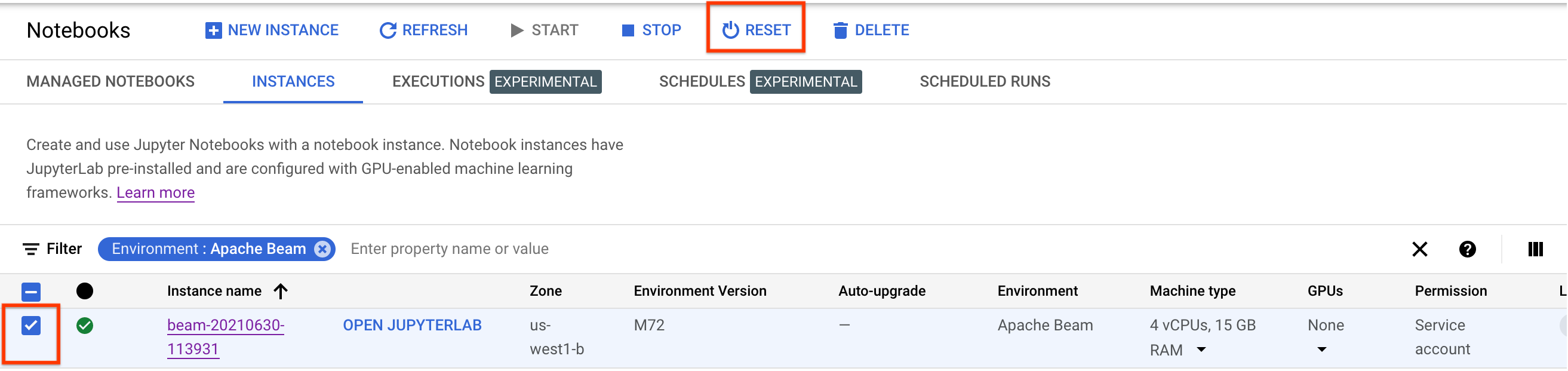
Após a redefinição, clique em Abrir JupyterLab. Pode levar algum tempo para que a interface do JupyterLab fique disponível. Após a exibição da interface, abra um terminal e execute o seguinte comando:
ls -al /mntO diretório/mnt/myDiskserá listado.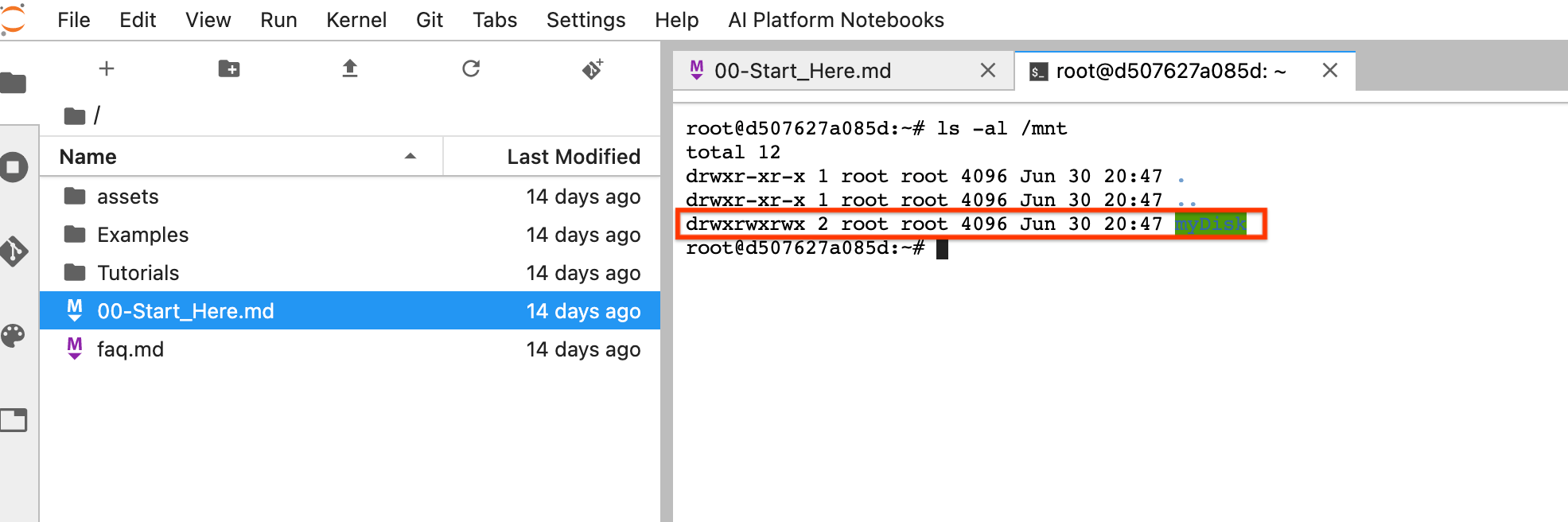
Agora você pode salvar seu trabalho no diretório /mnt/myDisk. Mesmo que a instância de notebook seja excluída, o Persistent Disk existirá no projeto. Em seguida, você pode anexar esse disco permanente a outras instâncias de notebook.
Limpar
Depois de terminar de usar a instância do notebook do Apache Beam, limpe os recursos criados no Google Cloud encerrando a instância do notebook.
A seguir
- Saiba mais sobre recursos avançados que podem ser usados com seus notebooks do Apache Beam. Os recursos avançados incluem os seguintes fluxos de trabalho: