Il campionamento dei dati consente di osservare i dati in ogni passaggio di una pipeline Dataflow. Queste informazioni possono aiutarti a eseguire il debug dei problemi relativi alla pipeline, mostrando gli input e gli output effettivi in un job in esecuzione o completato.
Gli utilizzi del campionamento dei dati includono:
Durante lo sviluppo, visualizza gli elementi prodotti durante la pipeline.
Se una pipeline genera un'eccezione, visualizza gli elementi correlati a questa eccezione.
Durante il debug, visualizza gli output delle trasformazioni per assicurarti che siano corretti.
Comprendere il comportamento di una pipeline senza dover esaminare il codice della pipeline.
Visualizza gli elementi campionati in un secondo momento, al termine del job, o confronta i dati campionati con un'esecuzione precedente.
Panoramica
Dataflow può campionare i dati della pipeline nei seguenti modi:
Campionamento periodico. Con questo tipo di campionamento, Dataflow raccoglie i campioni durante l'esecuzione del job. Puoi utilizzare i dati campionati per verificare se la pipeline elabora gli elementi come previsto e per diagnosticare problemi di runtime come tasti di scelta rapida o output errato. Per saperne di più, consulta la sezione Utilizzare il campionamento periodico dei dati in questo documento.
Campionamento delle eccezioni. Con questo tipo di campionamento, Dataflow raccoglie i campioni se una pipeline genera un'eccezione. Puoi utilizzare gli esempi per visualizzare i dati che venivano elaborati quando si è verificata l'eccezione. Il campionamento delle eccezioni è attivo per impostazione predefinita e può essere disattivato. Per ulteriori informazioni, consulta la sezione Utilizzare il campionamento delle eccezioni in questo documento.
Dataflow scrive gli elementi campionati nel percorso Cloud Storage specificato dall'opzione pipeline gcpTempLocation per Java e temp_location per Python e Go. Puoi visualizzare i dati campionati nella console Google Cloud o esaminare i file di dati non elaborati in Cloud Storage. I file rimangono in Cloud Storage finché non li elimini.
Il campionamento dei dati viene eseguito dai worker di Dataflow. Il campionamento è il risultato migliore. I campioni potrebbero essere eliminati se si verificano errori temporanei.
Requisiti
Per utilizzare il campionamento dei dati, devi abilitare Runner v2. Per ulteriori informazioni, consulta Abilitare Dataflow Runner v2.
Per visualizzare i dati campionati nella console Google Cloud , devi disporre delle seguenti autorizzazioni Identity and Access Management:
storage.buckets.getstorage.objects.getstorage.objects.list
Il campionamento periodico richiede il seguente SDK Apache Beam:
- Apache Beam Java SDK 2.47.0 o versioni successive
- SDK Apache Beam Python 2.46.0 o versioni successive
- SDK Apache Beam Go 2.53.0 o versioni successive
Il campionamento delle eccezioni richiede il seguente SDK Apache Beam:
- Apache Beam Java SDK 2.51.0 o versioni successive
- SDK Apache Beam Python 2.51.0 o versioni successive
- L'SDK Apache Beam Go non supporta il campionamento delle eccezioni.
A partire da questi SDK, Dataflow attiva per impostazione predefinita il campionamento delle eccezioni per tutti i job.
Utilizzare il campionamento periodico dei dati
Questa sezione descrive come campionare continuamente i dati della pipeline durante l'esecuzione di un job.
Attiva il campionamento periodico dei dati
Il campionamento periodico è disattivato per impostazione predefinita. Per abilitarla, imposta la seguente opzione della pipeline:
Java
--experiments=enable_data_sampling
Python
--experiments=enable_data_sampling
Vai
--experiments=enable_data_sampling
Puoi impostare l'opzione a livello di programmazione o utilizzando la riga di comando. Per ulteriori informazioni, vedi Impostare le opzioni della pipeline sperimentale.
Quando esegui un modello Dataflow, utilizza il flag additional-experiments
per attivare il campionamento dei dati:
--additional-experiments=enable_data_sampling
Quando il campionamento periodico è abilitato, Dataflow raccoglie campioni
da ogni PCollection nel grafico del job. La frequenza di campionamento è di circa un
campione ogni 30 secondi.
A seconda del volume di dati, il campionamento periodico dei dati può aggiungere un overhead delle prestazioni significativo. Pertanto, ti consigliamo di attivare il campionamento periodico solo durante i test e di disattivarlo per i carichi di lavoro di produzione.
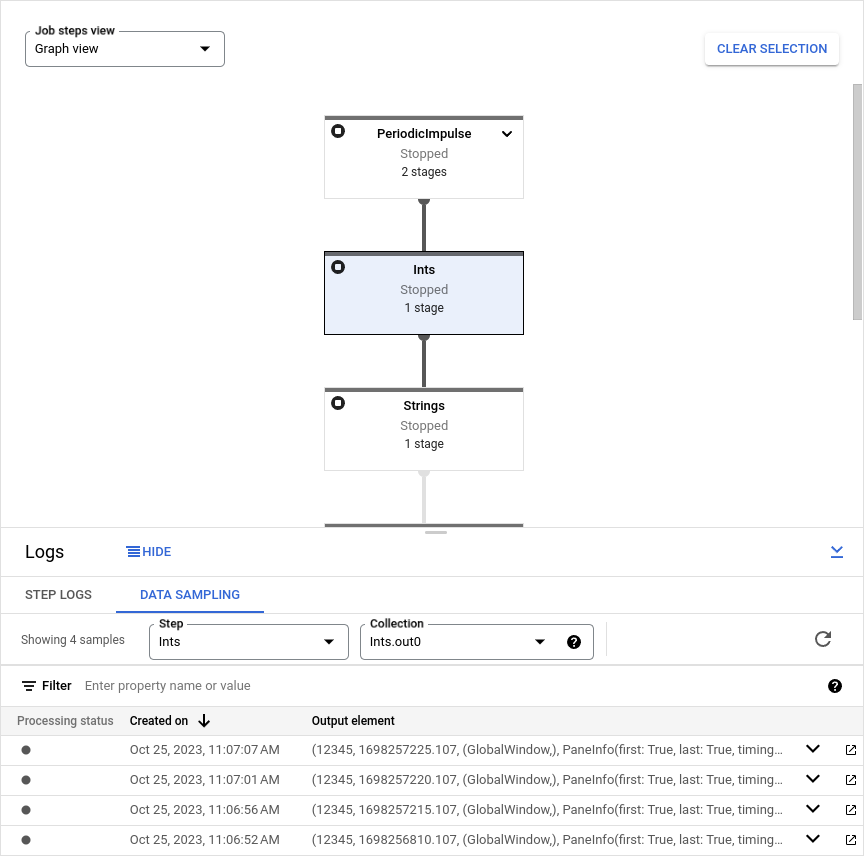
Visualizzare i dati campionati
Per visualizzare i dati campionati nella console Google Cloud , segui questi passaggi:
Nella console Google Cloud , vai alla pagina Job di Dataflow.
Seleziona un lavoro.
Fai clic su keyboard_capslock nel riquadro inferiore per espandere il riquadro dei log.
Fai clic sulla scheda Campionamento dei dati.
Nel campo Passaggio, seleziona un passaggio della pipeline. Puoi anche selezionare un passaggio nel grafico del job.
Nel campo Raccolta, scegli un
PCollection.
Se Dataflow ha raccolto campioni per PCollection, i dati campionati vengono visualizzati nella scheda. Per ogni campione, la scheda mostra la data di creazione e l'elemento di output. L'elemento di output è una rappresentazione serializzata
dell'elemento di raccolta, inclusi i dati dell'elemento, il timestamp e le informazioni su finestra e
riquadro.
Gli esempi riportati di seguito mostrano gli elementi campionati.
Java
TimestampedValueInGlobalWindow{value=KV{way, [21]},
timestamp=294247-01-09T04:00:54.775Z, pane=PaneInfo{isFirst=true, isLast=true,
timing=ON_TIME, index=0, onTimeIndex=0}}
Python
(('THE', 1), MIN_TIMESTAMP, (GloblWindow,), PaneInfo(first: True, last: True,
timing: UNKNOWN, index: 0, nonspeculative_index: 0))
Vai
KV<THE,1> [@1708122738999:[[*]]:{3 true true 0 0}]
L'immagine seguente mostra come vengono visualizzati i dati campionati nella consoleGoogle Cloud .
Utilizzare il campionamento delle eccezioni
Se la pipeline genera un'eccezione non gestita, puoi visualizzare sia l'eccezione sia l'elemento di input correlato. Il campionamento delle eccezioni è attivato per impostazione predefinita quando utilizzi un SDK Apache Beam supportato.
Visualizza le eccezioni
Per visualizzare un'eccezione, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Job di Dataflow.
Seleziona un lavoro.
Per espandere il riquadro Log, fai clic su keyboard_capslock Attiva/disattiva riquadro nel riquadro Log.
Fai clic sulla scheda Campionamento dei dati.
Nel campo Passaggio, seleziona un passaggio della pipeline. Puoi anche selezionare un passaggio nel grafico del job.
Nel campo Raccolta, scegli un
PCollection.La colonna Eccezione contiene i dettagli dell'eccezione. Non esiste un elemento output per un'eccezione. La colonna Elemento di output contiene invece il messaggio
Failed to process input element: INPUT_ELEMENT, dove INPUT_ELEMENT è l'elemento di input correlato.Per visualizzare l'esempio di input e i dettagli dell'eccezione in una nuova finestra, fai clic su Apri in una nuova.
L'immagine seguente mostra come appare un'eccezione nella console Google Cloud .

Disattiva il campionamento delle eccezioni
Per disattivare il campionamento delle eccezioni, imposta la seguente opzione della pipeline:
Java
--experiments=disable_always_on_exception_sampling
Python
--experiments=disable_always_on_exception_sampling
Puoi impostare l'opzione a livello di programmazione o utilizzando la riga di comando. Per ulteriori informazioni, vedi Impostare le opzioni della pipeline sperimentale.
Quando esegui un modello Dataflow, utilizza il flag additional-experiments
per disattivare il campionamento delle eccezioni:
--additional-experiments=disable_always_on_exception_sampling
Considerazioni sulla sicurezza
Dataflow scrive i dati campionati in un bucket Cloud Storage che crei e gestisci. Utilizza le funzionalità di sicurezza di Cloud Storage per salvaguardare la sicurezza dei tuoi dati. In particolare, valuta le seguenti misure di sicurezza aggiuntive:
- Utilizza una chiave di crittografia gestita dal cliente (CMEK) per criptare il bucket Cloud Storage. Per ulteriori informazioni sulla scelta di un'opzione di crittografia, vedi Scegliere la crittografia giusta per le tue esigenze.
- Imposta una durata (TTL) per il bucket Cloud Storage, in modo che i file di dati vengano eliminati automaticamente dopo un periodo di tempo. Per maggiori informazioni, consulta Impostare la configurazione del ciclo di vita per un bucket.
- Utilizza il principio del privilegio minimo quando assegni le autorizzazioni IAM al bucket Cloud Storage.
Puoi anche offuscare i singoli campi nel tipo di dati PCollection, in modo che
il valore non elaborato non venga visualizzato nei dati campionati:
- Python: esegui l'override del metodo
__repr__o__str__. - Java: esegui l'override del metodo
toString.
Tuttavia, non puoi offuscare gli input e gli output dei connettori I/O, a meno che non modifichi il codice sorgente del connettore per farlo.
Fatturazione
Quando Dataflow esegue il campionamento dei dati, ti vengono addebitati i costi per l'archiviazione dei dati in Cloud Storage e per le operazioni di lettura e scrittura su Cloud Storage. Per maggiori informazioni, consulta la pagina Prezzi di Cloud Storage.
Ogni worker Dataflow scrive i campioni in batch, comportando un'operazione di lettura e una di scrittura per batch.
Risoluzione dei problemi
Questa sezione contiene informazioni sui problemi comuni quando si utilizza il campionamento dei dati.
Errore di autorizzazioni
Se non hai l'autorizzazione per visualizzare i campioni, la console Google Cloud mostra il seguente errore:
You don't have permission to view a data sample.
Per risolvere questo errore, verifica di disporre delle autorizzazioni IAM richieste. Se l'errore si verifica ancora, potresti essere soggetto a un criterio di negazione IAM.
Non vedo campioni
Se non vedi campioni, controlla quanto segue:
- Assicurati che il campionamento dei dati sia attivato impostando l'opzione
enable_data_sampling. Consulta Abilitare il campionamento dei dati. - Assicurati di utilizzare Runner v2.
- Assicurati che i worker siano stati avviati. Il campionamento non inizia finché non vengono avviati i worker.
- Assicurati che il job e i lavoratori siano in uno stato integro.
- Controlla di nuovo le quote di Cloud Storage del progetto. Se superi i limiti di quota di Cloud Storage, Dataflow non può scrivere i dati di esempio.
- Il campionamento dei dati non può campionare da iterabili. I campioni di questi tipi di stream non sono disponibili.