Data sampling lets you observe the data at each step of a Dataflow pipeline. This information can help you to debug problems with your pipeline, by showing the actual inputs and outputs in a running or completed job.
Uses for data sampling include the following:
During development, see what elements are produced throughout the pipeline.
If a pipeline throws an exception, view the elements that are correlated with that exception.
When debugging, view the outputs of transforms to ensure the output is correct.
Understand the behavior of a pipeline without needing to examine the pipeline code.
View the sampled elements at a later time, after the job finishes, or compare the sampled data with a previous run.
Overview
Dataflow can sample pipeline data in the following ways:
Periodic sampling. With this type of sampling, Dataflow collects samples as the job runs. You can use the sampled data to check whether your pipeline processes elements as expected, and to diagnose runtime issues such as hot keys or incorrect output. For more information, see Use periodic data sampling in this document.
Exception sampling. With this type of sampling, Dataflow collects samples if a pipeline throws an exception. You can use the samples to see the data that was being processed when the exception occurred. Exception sampling is enabled by default and can be disabled. For more information, see Use exception sampling in this document.
Dataflow writes the sampled elements to the Cloud Storage
path specified by the
gcpTempLocation
pipeline option for Java and temp_location for Python and Go. You can view the
sampled data in the Google Cloud console, or examine the raw data files in
Cloud Storage. The files persist in Cloud Storage until you
delete them.
Data sampling is executed by the Dataflow workers. Sampling is best-effort. Samples might be dropped if transient errors occur.
Requirements
To use data sampling, you must enable Runner v2. For more information, see Enable Dataflow Runner v2.
To view the sampled data in the Google Cloud console, you need the following Identity and Access Management permissions:
storage.buckets.getstorage.objects.getstorage.objects.list
Periodic sampling requires the following Apache Beam SDK:
- Apache Beam Java SDK 2.47.0 or later
- Apache Beam Python SDK 2.46.0 or later
- Apache Beam Go SDK 2.53.0 or later
Exception sampling requires the following Apache Beam SDK:
- Apache Beam Java SDK 2.51.0 or later
- Apache Beam Python SDK 2.51.0 or later
- The Apache Beam Go SDK does not support exception sampling.
Starting with these SDKs, Dataflow enables exception sampling for all jobs by default.
Use periodic data sampling
This section describes how to sample pipeline data continuously as a job runs.
Enable periodic data sampling
Periodic sampling is disabled by default. To enable it, set the following pipeline option:
Java
--experiments=enable_data_sampling
Python
--experiments=enable_data_sampling
Go
--experiments=enable_data_sampling
You can set the option programmatically or by using the command line. For more information, see Set experimental pipeline options.
When running a Dataflow template, use the additional-experiments
flag to enable data sampling:
--additional-experiments=enable_data_sampling
When periodic sampling is enabled, Dataflow collects samples
from each PCollection in the job graph. The sampling rate is approximately one
sample every 30 seconds.
Depending on the volume of data, periodic data sampling can add significant performance overhead. Therefore, we recommend that you only enable periodic sampling during testing, and disable it for production workloads.
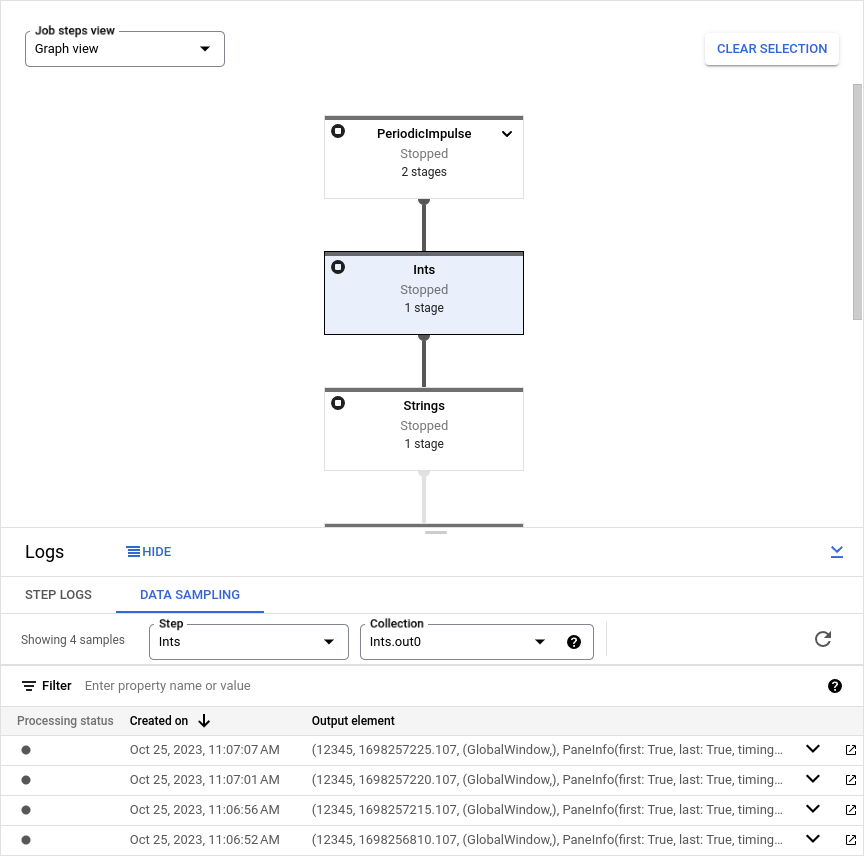
View sampled data
To view the sampled data in the Google Cloud console, perform the following steps:
In the Google Cloud console, go to the Dataflow Jobs page.
Select a job.
Click keyboard_capslock on the bottom panel to expand the logs panel.
Click the Data Sampling tab.
In the Step field, select a pipeline step. You can also select a step in the job graph.
In the Collection field, choose a
PCollection.
If Dataflow has collected samples for that PCollection, the
sampled data appears in the tab. For each sample, the tab displays the creation
date and the output element. The output element is a serialized representation
of the collection element, including the element data, timestamp, and window and
pane information.
The following examples show sampled elements.
Java
TimestampedValueInGlobalWindow{value=KV{way, [21]},
timestamp=294247-01-09T04:00:54.775Z, pane=PaneInfo{isFirst=true, isLast=true,
timing=ON_TIME, index=0, onTimeIndex=0}}
Python
(('THE', 1), MIN_TIMESTAMP, (GloblWindow,), PaneInfo(first: True, last: True,
timing: UNKNOWN, index: 0, nonspeculative_index: 0))
Go
KV<THE,1> [@1708122738999:[[*]]:{3 true true 0 0}]
The following image shows how the sampled data appears in the Google Cloud console.
Use exception sampling
If your pipeline throws an unhandled exception, you can view both the exception and the input element that is correlated with that exception. Exception sampling is enabled by default when you use a supported Apache Beam SDK.
View exceptions
To view an exception, perform the following steps:
In the Google Cloud console, go to the Dataflow Jobs page.
Select a job.
To expand the Logs panel, click keyboard_capslock Toggle panel on the Logs panel.
Click the Data Sampling tab.
In the Step field, select a pipeline step. You can also select a step in the job graph.
In the Collection field, choose a
PCollection.The Exception column contains the exception details. There is no output element for an exception. Instead, the Output element column contains the message
Failed to process input element: INPUT_ELEMENT, where INPUT_ELEMENT is the correlated input element.To view the input sample and the exception details in a new window, click Open in new.
The following image shows how an exception appears in the Google Cloud console.

Disable exception sampling
To disable exception sampling, set the following pipeline option:
Java
--experiments=disable_always_on_exception_sampling
Python
--experiments=disable_always_on_exception_sampling
You can set the option programmatically or by using the command line. For more information, see Set experimental pipeline options.
When running a Dataflow template, use the additional-experiments
flag to disable exception sampling:
--additional-experiments=disable_always_on_exception_sampling
Security considerations
Dataflow writes the sampled data to a Cloud Storage bucket that you create and manage. Use the security features of Cloud Storage to safeguard the security of your data. In particular, consider the following additional security measures:
- Use a customer-managed encryption key (CMEK) to encrypt the Cloud Storage bucket. For more information about choosing an encryption option, see Choose the right encryption for your needs.
- Set a time to live (TTL) on the Cloud Storage bucket, so that data files are automatically deleted after a period of time. For more information, see Set the lifecycle configuration for a bucket.
- Use the principle of least privilege when assigning IAM permissions to the Cloud Storage bucket.
You can also obfuscate individual fields in your PCollection data type, so
that the raw value does not appear in the sampled data:
- Python: Override the
__repr__or__str__method. - Java: Override the
toStringmethod.
However, you can't obfuscate the inputs and outputs from I/O connectors, unless you modify the connector source code to do so.
Billing
When Dataflow performs data sampling, you are charged for the Cloud Storage data storage and for the read and write operations on Cloud Storage. For more information, see Cloud Storage pricing.
Each Dataflow worker writes samples in batches, incurring one read operation and one write operation per batch.
Troubleshooting
This section contains information about common issues when using data sampling.
Permissions error
If you don't have permission to view the samples, the Google Cloud console shows the following error:
You don't have permission to view a data sample.
To resolve this error, check that you have the required IAM permissions. If the error still occurs, you might be subject to an IAM deny policy.
I don't see any samples
If you don't see any samples, check the following:
- Ensure that data sampling is enabled by setting the
enable_data_samplingoption. See Enable data sampling. - Ensure that you are using Runner v2
- Make sure the workers have started. Sampling does not start until the workers start.
- Make sure the job and workers are in a healthy state.
- Double check the project's Cloud Storage quotas. If you exceed your Cloud Storage quota limits, then Dataflow cannot write the sample data.
- Data sampling can't sample from iterables. Samples from these types of streams aren't available.