개요
다음 태스크에 Dataflow 데이터 파이프라인을 사용할 수 있습니다.
- 반복 작업 일정을 만듭니다.
- 여러 작업 실행에서 리소스가 소비되는 위치를 파악합니다.
- 데이터 최신 상태 목표를 정의하고 관리합니다.
- 개별 파이프라인 단계를 드릴다운하여 파이프라인을 수정하고 최적화합니다.
API 문서는 데이터 파이프라인 참조를 확인하세요.
기능
- 일정에 따라 일괄 작업을 실행할 반복 일괄 파이프라인을 만듭니다.
- 최신 버전의 입력 데이터에 대해 일괄 작업을 실행하려면 반복 증분 일괄 파이프라인을 만듭니다.
- 파이프라인 요약 스코어카드를 사용하여 파이프라인의 집계량 사용 및 리소스 소비를 확인합니다.
- 스트리밍 파이프라인 데이터 기록 빈도를 봅니다. 시간 경과에 따라 발전하는 이 측정항목은 최신 상태가 지정된 목표 미만이 되면 알려주는 알림에 연결될 수 있습니다.
- 파이프라인 측정항목 그래프를 사용하여 일괄 파이프라인 작업을 비교하고 이상치를 찾습니다.
제한사항
사용 가능한 리전: 사용 가능한 Cloud Scheduler 리전에서 데이터 파이프라인을 만들 수 있습니다.
할당량:
- 프로젝트당 기본 파이프라인 수: 500개
조직당 기본 파이프라인 수: 2,500개
조직 수준 할당량은 기본적으로 중지되어 있습니다. 조직 수준의 할당량을 선택할 수 있으며, 이 경우 각 조직은 기본적으로 최대 2,500개의 파이프라인을 사용할 수 있습니다.
라벨: 사용자 정의 라벨을 사용하여 Dataflow 데이터 파이프라인에 라벨을 지정할 수 없습니다. 하지만
additionalUserLabels필드를 사용하면 해당 값이 Dataflow 작업으로 전달됩니다. 라벨이 개별 Dataflow 작업에 적용되는 방식에 대한 자세한 내용은 파이프라인 옵션을 참조하세요.
데이터 파이프라인 유형
Dataflow에는 스트리밍과 일괄과 같은 두 가지 데이터 파이프라인 유형이 있습니다. 두 가지 파이프라인 유형 모두 Dataflow 템플릿에 정의된 작업을 실행합니다.
- 스트리밍 데이터 파이프라인
- 스트리밍 데이터 파이프라인은 생성되는 Dataflow 스트리밍 작업을 바로 실행합니다.
- 일괄 데이터 파이프라인
일괄 데이터 파이프라인은 사용자 정의 일정에 따라 Dataflow 일괄 작업을 실행합니다. 일괄 파이프라인 입력 파일 이름을 매개변수화하여 증분 일괄 파이프라인 처리를 허용할 수 있습니다.
증분 일괄 파이프라인
날짜/시간 자리표시자를 사용하여 일괄 파이프라인의 증분 입력 파일 형식을 지정할 수 있습니다.
- 연도, 월, 날짜, 시간, 분, 초 자리표시자를 사용할 수 있으며
strftime()형식을 따라야 합니다. 자리표시자 앞에는 백분율 기호(%)가 옵니다. - 파이프라인 생성 중에는 매개변수 형식이 확인되지 않습니다.
- 예: 매개변수화된 입력 파일 경로로 'gs://bucket/Y'를 지정한 경우 앞에 '%'가 없는 'Y'는
strftime()형식에 매핑되지 않기 때문에 'gs://bucket/Y'로 평가됩니다.
- 예: 매개변수화된 입력 파일 경로로 'gs://bucket/Y'를 지정한 경우 앞에 '%'가 없는 'Y'는
각 예약된 일괄 파이프라인 실행 시에 입력 경로의 자리표시자 부분은 현재(또는 타임 시프트) 날짜/시간으로 평가됩니다. 날짜 값은 예약된 작업의 시간대에서 현재 날짜를 사용하여 평가됩니다. 평가된 경로가 입력 파일의 경로와 일치할 경우 파일은 예약된 시간에 일괄 파이프라인에서 처리되기 위해 선택됩니다.
- 예: 일괄 파이프라인은 해당 시간(PST) 정각에 반복되도록 예약됩니다. 입력 경로를
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv로 매개변수화하면 2021년 4월 15일 오후 6시(PST)에 입력 경로가gs://bucket-name/2021-04-15/prefix-18_00.csv로 평가됩니다.
타임 시프트 매개변수 사용
+ 또는 - 분 또는 시간 타임 시프트 매개변수를 사용할 수 있습니다.
파이프라인 일정의 현재 날짜/시간 전후로 이동된 평가 날짜/시간과 입력 경로를 일치시키려면 이러한 매개변수를 중괄호로 묶습니다.
{[+|-][0-9]+[m|h]} 형식을 사용합니다. 배치 파이프라인은 예약된 시간에 계속 반복되지만 입력 경로는 지정된 타임스탬프로 평가됩니다.
- 예: 일괄 파이프라인은 해당 시간(PST) 정각에 반복되도록 예약됩니다. 입력 경로를
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}로 매개변수화하면 2021년 4월 15일 오후 6시(PST)에 입력 경로가gs://bucket-name/2021-04-15/prefix-16_00.csv로 평가됩니다.
데이터 파이프라인 역할
Dataflow 데이터 파이프라인 작업이 성공하려면 다음과 같이 필요한 IAM 역할이 있어야 합니다.
작업을 수행하려면 적절한 역할이 필요합니다.
Datapipelines.admin: 모든 데이터 파이프라인 작업을 수행할 수 있습니다.Datapipelines.viewer: 데이터 파이프라인 및 작업을 볼 수 있습니다.Datapipelines.invoker: 데이터 파이프라인 작업 실행을 호출할 수 있습니다(API를 사용하여 이 역할을 사용 설정할 수 있음).
Cloud Scheduler에서 사용하는 서비스 계정에는
roles/iam.serviceAccountUser역할이 있어야 합니다. 서비스 계정은 사용자가 지정한 계정이거나 기본 Compute Engine 서비스 계정일 수 있습니다. 자세한 내용은 데이터 파이프라인 역할을 참조하세요.해당 계정에 대한
roles/iam.serviceAccountUser역할이 부여되어 Cloud Scheduler 및 Dataflow에서 사용하는 서비스 계정의 역할을 할 수 있어야 합니다. Cloud Scheduler 및 Dataflow의 서비스 계정을 선택하지 않으면 기본 Compute Engine 서비스 계정이 사용됩니다.
데이터 파이프라인 만들기
다음 두 가지 방법으로 Dataflow 데이터 파이프라인을 만들 수 있습니다.
데이터 파이프라인 설정 페이지: Google Cloud 콘솔에서 Dataflow 파이프라인 기능에 처음 액세스하면 설정 페이지가 열립니다. 나열된 API를 사용 설정하여 데이터 파이프라인을 만듭니다.
작업 가져오기
기본 또는 Flex 템플릿을 기반으로 하는 Dataflow 일괄 또는 스트리밍 작업을 가져와서 데이터 파이프라인으로 만들 수 있습니다.
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
완료된 작업을 선택한 후 작업 세부정보 페이지에서 +파이프라인으로 가져오기를 선택합니다.
템플릿에서 파이프라인 만들기 페이지에서 매개변수는 가져온 작업의 옵션으로 채워집니다.
일괄 작업의 경우 파이프라인 예약 섹션에서 반복 일정을 제공합니다. 일괄 실행을 예약하는 데 사용되는 Cloud Scheduler의 이메일 계정 주소를 제공하는 것은 선택사항입니다. 지정하지 않으면 기본 Compute Engine 서비스 계정이 사용됩니다.
데이터 파이프라인 만들기
Google Cloud 콘솔에서 Dataflow 데이터 파이프라인 페이지로 이동합니다.
+데이터 파이프라인 만들기를 선택합니다.
템플릿에서 파이프라인 만들기 페이지에서 파이프라인 이름을 제공하고 다른 템플릿 선택 및 매개변수 필드를 채웁니다.
일괄 작업의 경우 파이프라인 예약 섹션에서 반복 일정을 제공합니다. 일괄 실행을 예약하는 데 사용되는 Cloud Scheduler의 이메일 계정 주소를 제공하는 것은 선택사항입니다. 값을 지정하지 않으면 기본 Compute Engine 서비스 계정이 사용됩니다.
일괄 데이터 파이프라인 만들기
이 샘플 일괄 데이터 파이프라인을 만들려면 프로젝트의 다음 리소스에 액세스할 수 있어야 합니다.
- 입력 및 출력 파일을 저장할 Cloud Storage 버킷
- 테이블을 만들 BigQuery 데이터 세트
이 예시 파이프라인에서는 Cloud Storage Text to BigQuery 일괄 파이프라인 템플릿을 사용합니다. 이 템플릿은 Cloud Storage에서 CSV 형식의 파일을 읽고 변환을 실행한 다음 세 개의 열이 있는 BigQuery 테이블에 값을 삽입합니다.
로컬 드라이브에 다음 파일을 만듭니다.
대상 BigQuery 테이블에 다음 스키마가 포함된
bq_three_column_table.json파일입니다.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }split_csv_3cols.js자바스크립트 파일입니다. BigQuery에 삽입하기 전에 입력 데이터에 대한 간단한 변환을 구현합니다.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }BigQuery 테이블에 삽입되는 레코드가 여러 개 있는
file01.csvCSV 파일입니다.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
다음과 같이
gcloud storage cp명령어를 사용하여 프로젝트의 Cloud Storage 버킷 폴더에 파일을 복사합니다.bq_three_column_table.json및split_csv_3cols.js를gs://BUCKET_ID/text_to_bigquery/에 복사합니다.gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/file01.csv를gs://BUCKET_ID/inputs/에 복사합니다.gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
Cloud Storage 버킷에
tmp폴더를 만들려면 폴더 이름을 선택하여 버킷 세부정보 페이지를 연 다음 폴더 만들기를 클릭합니다.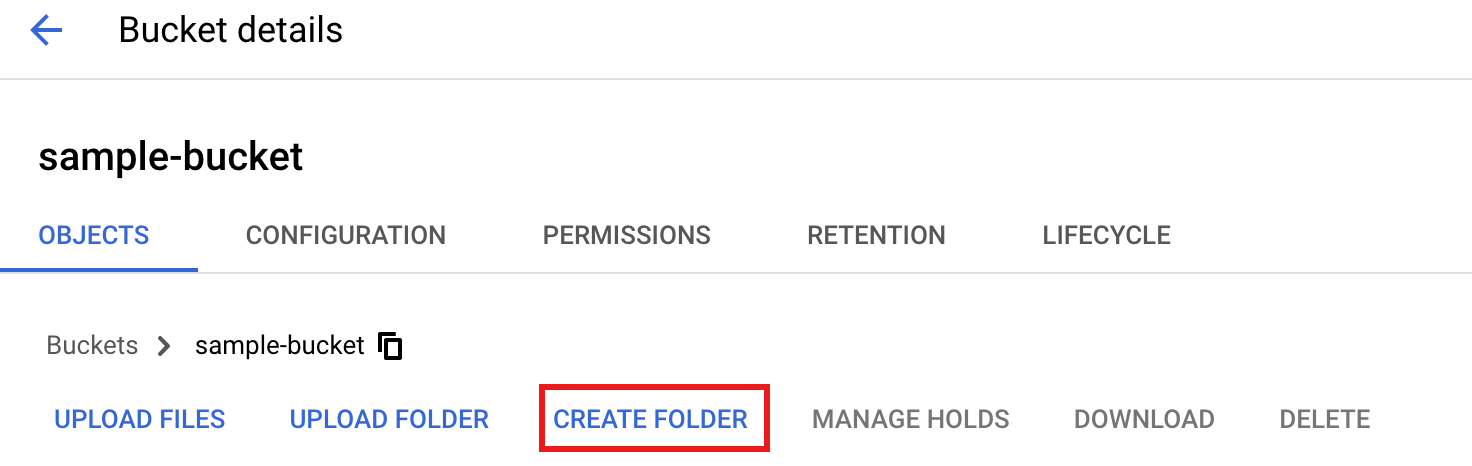
Google Cloud 콘솔에서 Dataflow 데이터 파이프라인 페이지로 이동합니다.
데이터 파이프라인 만들기를 선택합니다. 템플릿에서 파이프라인 만들기 페이지에서 다음 항목을 입력하거나 선택합니다.
- 파이프라인 이름에
text_to_bq_batch_data_pipeline을 입력합니다. - 리전 엔드포인트에 Compute Engine 리전을 선택합니다. 소스 및 대상 리전은 일치해야 합니다. 따라서 Cloud Storage 버킷과 BigQuery 테이블은 같은 리전에 있어야 합니다.
Dataflow 템플릿의 대량 데이터 처리(일괄 작업)에서 Cloud Storage의 텍스트 파일을 BigQuery로를 선택합니다.
파이프라인 예약에 속해 있는 시간대에서 매시간 25분과 같은 일정을 선택합니다. 파이프라인을 제출한 후에 일정을 수정할 수 있습니다. 일괄 실행을 예약하는 데 사용되는 Cloud Scheduler의 이메일 계정 주소를 제공하는 것은 선택사항입니다. 지정하지 않으면 기본 Compute Engine 서비스 계정이 사용됩니다.
필수 파라미터에 다음을 입력합니다.
- Cloud Storage의 자바스크립트 UDF 경로:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- JSON 경로:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- 자바스크립트 UDF 이름:
transform - BigQuery 출력 테이블:
PROJECT_ID:DATASET_ID.three_column_table
- Cloud Storage 입력 경로:
BUCKET_ID/inputs/file01.csv
- 임시 BigQuery 디렉터리:
BUCKET_ID/tmp
- 임시 위치:
BUCKET_ID/tmp
- Cloud Storage의 자바스크립트 UDF 경로:
파이프라인 만들기를 클릭합니다.
- 파이프라인 이름에
파이프라인 세부정보 페이지에서 파이프라인 및 템플릿 정보를 확인하고 현재 및 이전 기록을 봅니다.
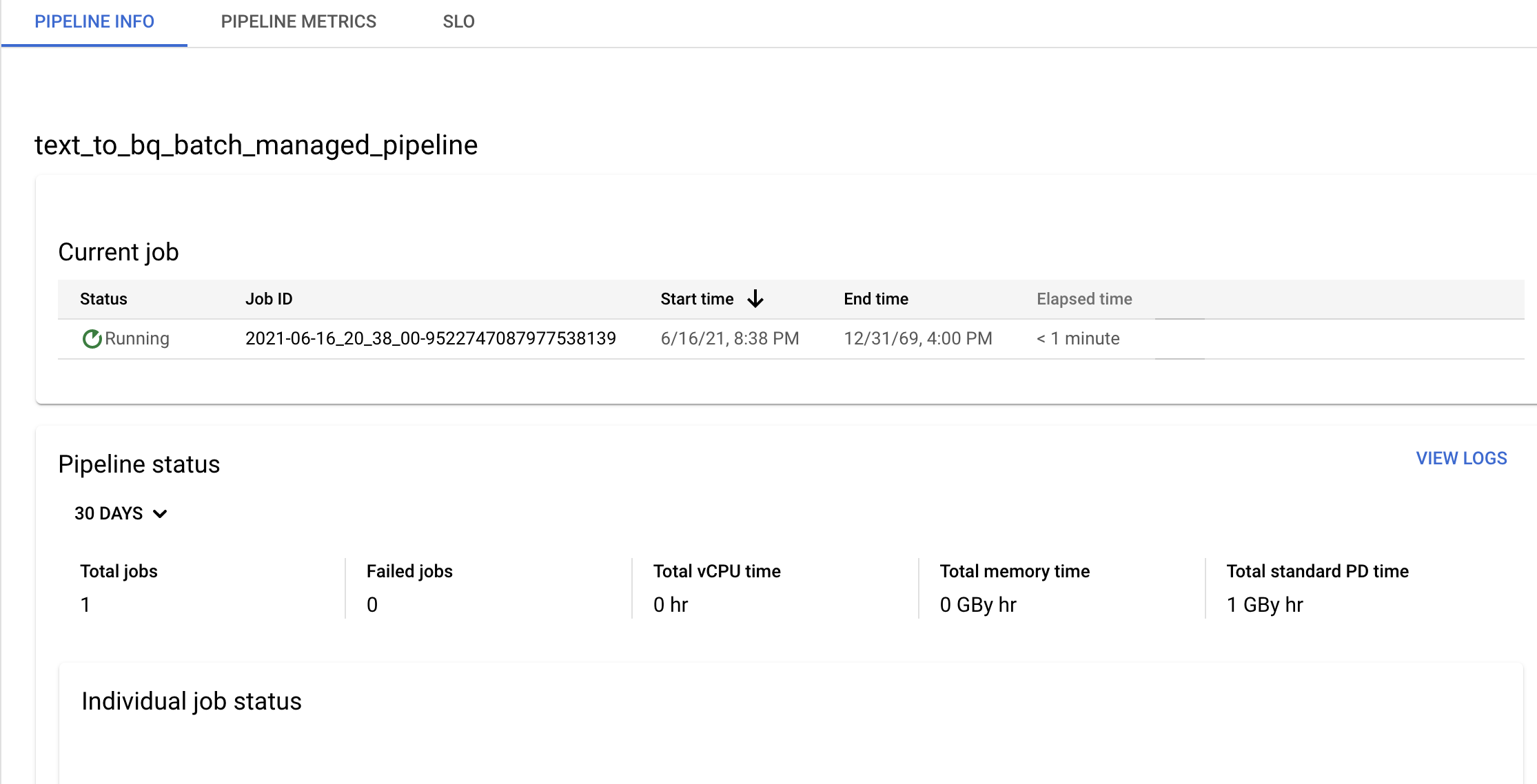
파이프라인 세부정보 페이지의 파이프라인 정보 패널에서 데이터 파이프라인 일정을 수정할 수 있습니다.
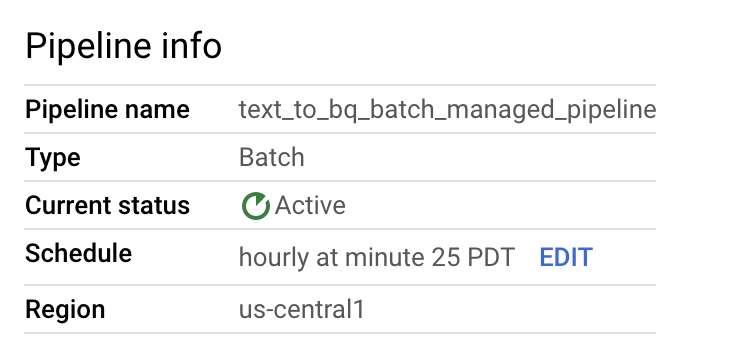
또한 Dataflow 파이프라인 콘솔에서 실행 버튼을 사용하여 필요에 따라 일괄 파이프라인을 실행할 수도 있습니다.
샘플 스트리밍 데이터 파이프라인 만들기
샘플 일괄 파이프라인 안내에 따라 샘플 스트리밍 데이터 파이프라인을 만들 수 있지만 다음과 같은 차이점이 있습니다.
- 파이프라인 일정에 스트리밍 데이터 파이프라인의 일정을 지정하지 않습니다. Dataflow 스트리밍 작업이 즉시 시작됩니다.
- Dataflow 템플릿의 데이터 연속 처리(스트림)에서 Cloud Storage의 텍스트 파일을 BigQuery로를 선택합니다.
- 작업자 머신 유형의 경우 파이프라인은
gs://BUCKET_ID/inputs/file01.csv패턴과 일치하는 초기 파일 집합과inputs/폴더에 업로드하는 이 패턴과 일치하는 추가 파일을 처리합니다. CSV 파일 크기가 몇 GB를 초과하는 경우 발생 가능한 메모리 부족 오류를 방지하기 위해n1-highmem-8과 같이 기본n1-standard-4머신 유형보다 메모리가 더 많은 머신 유형을 선택합니다.
문제 해결
이 섹션에서는 Dataflow 데이터 파이프라인 문제를 해결하는 방법을 보여줍니다.
데이터 파이프라인 작업이 실행되지 않음
데이터 파이프라인을 사용하여 반복 작업 일정을 만들면 Dataflow 작업이 시작되지 않고 Cloud Scheduler 로그 파일에 503 상태 오류가 표시됩니다.
이 문제는 Dataflow가 일시적으로 작업을 실행할 수 없을 때 발생합니다.
이 문제를 해결하려면 Cloud Scheduler를 구성하여 작업을 다시 시도하세요. 이 문제는 일시적이므로 작업을 재시도하면 성공할 수 있습니다. Cloud Scheduler에서 재시도 값을 설정하는 방법에 대한 자세한 내용은 작업 만들기를 참조하세요.
파이프라인 목표 위반 조사
다음 섹션에서는 성능 목표를 충족하지 않는 파이프라인을 조사하는 방법을 설명합니다.
반복 일괄 파이프라인
파이프라인 상태의 초기 분석을 위해 Google Cloud 콘솔의 파이프라인 정보 페이지에서 개별 작업 상태 및 단계당 스레드 시간 그래프를 사용합니다. 이러한 그래프는 파이프라인 상태 패널에 있습니다.
조사 예시:
매시간 3분에 실행되는 반복 일괄 파이프라인이 있으며, 각 작업은 일반적으로 약 9분 동안 실행됩니다. 모든 작업을 10분 이내에 완료하려는 목표가 있습니다.
작업 상태 그래프는 작업이 10분 넘게 실행되었음을 보여줍니다.
업데이트/실행 기록 테이블에서 원하는 시간 동안 실행된 작업을 찾습니다. 클릭하여 Dataflow 작업 세부정보 페이지로 이동합니다. 이 페이지에서 더 오래 실행되는 단계를 찾은 후 로그에서 가능한 오류를 찾아 지연의 원인을 파악합니다.
스트리밍 파이프라인
파이프라인 상태 초기 분석을 위해 파이프라인 세부정보 페이지의 파이프라인 정보 탭에서 데이터 기록 빈도 그래프를 사용합니다. 이 그래프는 파이프라인 상태 패널에 있습니다.
조사 예시:
일반적으로 20초의 데이터 최신 상태로 출력을 생성하는 스트리밍 파이프라인이 있습니다.
30초의 데이터 최신 상태를 보장한다는 목표를 설정합니다. 데이터 최신 상태 그래프를 검토한 결과, 오전 9시에서 10시 사이에 데이터 최신 상태가 거의 40초로 급증한 것을 발견했습니다.
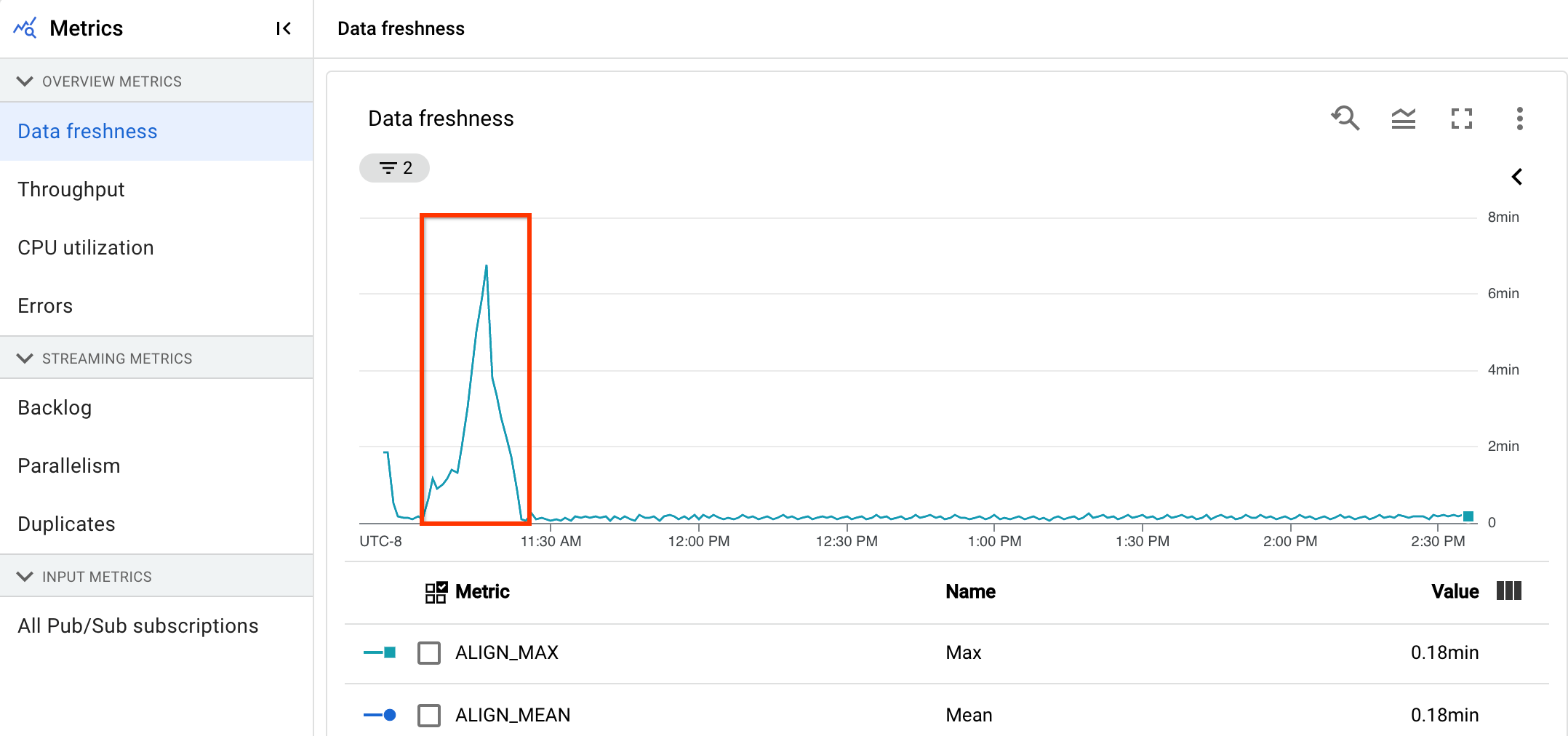
파이프라인 측정항목 탭으로 전환한 다음 처리량, CPU 사용률, 메모리 사용률 그래프를 확인하여 추가 분석을 수행합니다.
오류: 파이프라인 ID가 이미 프로젝트 내에 있음
프로젝트에 이미 있는 이름으로 새 파이프라인을 만들려고 하면 Pipeline Id already exist within the
project 오류 메시지가 표시됩니다. 이 문제를 방지하려면 항상 파이프라인에 고유한 이름을 지정하세요.