Vista geral
Pode usar pipelines de dados do Dataflow para as seguintes tarefas:
- Criar agendamentos de tarefas recorrentes.
- Compreenda onde os recursos são gastos em várias execuções de tarefas.
- Defina e faça a gestão dos objetivos de atualidade dos dados.
- Analise detalhadamente as fases individuais do pipeline para corrigir e otimizar os seus pipelines.
Para consultar a documentação da API, consulte a referência de pipelines de dados.
Funcionalidades
- Crie um pipeline de processamento em lote recorrente para executar uma tarefa de processamento em lote de acordo com uma programação.
- Crie um pipeline de lotes incrementais recorrente para executar uma tarefa em lote na versão mais recente dos dados de entrada.
- Use a tabela de dados de resumo do pipeline para ver a utilização agregada da capacidade e o consumo de recursos de um pipeline.
- Veja a atualidade dos dados de um pipeline de streaming. Esta métrica, que evolui ao longo do tempo, pode ser associada a um alerta que lhe envia uma notificação quando a atualidade fica abaixo de um objetivo especificado.
- Use gráficos de métricas de pipelines para comparar tarefas de pipelines em lote e encontrar anomalias.
Limitações
Disponibilidade regional: pode criar pipelines de dados nas regiões do Cloud Scheduler disponíveis.
Quota:
- Número predefinido de pipelines por projeto: 500
Número predefinido de pipelines por organização: 2500
A quota ao nível da organização está desativada por predefinição. Pode ativar as quotas ao nível da organização e, se o fizer, cada organização pode ter, por predefinição, um máximo de 2500 pipelines.
Etiquetas: não pode usar etiquetas definidas pelo utilizador para etiquetar pipelines de dados do Dataflow. No entanto, quando usa o campo
additionalUserLabels, esses valores são transmitidos para a sua tarefa do Dataflow. Para mais informações sobre como as etiquetas se aplicam a tarefas individuais do Dataflow, consulte as opções de pipeline.
Tipos de data pipelines
O Dataflow tem dois tipos de data pipelines: streaming e em lote. Ambos os tipos de tarefas de execução de pipelines são definidos em modelos do Dataflow.
- Data pipelines de streaming
- Um data pipeline de streaming executa uma tarefa de streaming do Dataflow imediatamente após a sua criação.
- Data pipeline em lote
Um pipeline de dados em lote executa uma tarefa em lote do Dataflow num horário definido pelo utilizador. O nome do ficheiro de entrada do pipeline de lotes pode ser parametrizado para permitir o processamento incremental do pipeline de lotes.
Pipelines de processamento em lote incrementais
Pode usar marcadores de posição de data/hora para especificar um formato de ficheiro de entrada incremental para um pipeline em lote.
- Pode usar marcadores de posição para o ano, o mês, a data, a hora, os minutos e os segundos, e
têm de seguir o formato
strftime(). Os marcadores de posição são precedidos pelo símbolo de percentagem (%). - A formatação de parâmetros não é validada durante a criação do pipeline.
- Exemplo: se especificar "gs://bucket/Y" como o caminho de entrada parametrizado, este é avaliado como "gs://bucket/Y", porque "Y" sem um "%" anterior não é mapeado para o formato
strftime().
- Exemplo: se especificar "gs://bucket/Y" como o caminho de entrada parametrizado, este é avaliado como "gs://bucket/Y", porque "Y" sem um "%" anterior não é mapeado para o formato
Em cada hora de execução da pipeline de lotes agendada, a parte do marcador de posição do caminho de entrada é avaliada em função da data/hora atual (ou com mudança de tempo). Os valores de data são avaliados com base na data atual no fuso horário da tarefa agendada. Se o caminho avaliado corresponder ao caminho de um ficheiro de entrada, o ficheiro é recolhido para processamento pelo pipeline em lote à hora agendada.
- Exemplo: uma pipeline de processamento em lote está agendada para se repetir no início de cada hora
PST. Se parametrizar o caminho de entrada como
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv, a 15 de abril de 2021, às 18:00 (Hora do Pacífico), o caminho de entrada é avaliado comogs://bucket-name/2021-04-15/prefix-18_00.csv.
Use parâmetros de mudança de tempo
Pode usar parâmetros de mudança de tempo de minutos ou horas com o sinal + ou -.
Para suportar a correspondência de um caminho de entrada com uma data/hora avaliada que seja deslocada antes ou depois da data/hora atual da programação do pipeline, inclua estes parâmetros entre chavetas.
Use o formato {[+|-][0-9]+[m|h]}. O pipeline de processamento em lote continua a repetir-se na hora agendada, mas o caminho de entrada é avaliado com o desvio de tempo especificado.
- Exemplo: uma pipeline de processamento em lote está agendada para se repetir no início de cada hora
PST. Se parametrizar o caminho de entrada como
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}, a 15 de abril de 2021, às 18:00 (Hora do Pacífico), o caminho de entrada é avaliado comogs://bucket-name/2021-04-15/prefix-16_00.csv.
Funções de data pipeline
Para que as operações da pipeline de dados do Dataflow sejam bem-sucedidas, precisa das funções do IAM necessárias, da seguinte forma:
Precisa da função adequada para realizar operações:
Datapipelines.admin: Pode realizar todas as operações de pipeline de dadosDatapipelines.viewer: Pode ver pipelines de dados e tarefasDatapipelines.invoker: Pode invocar uma execução de tarefa de pipeline de dados (esta função pode ser ativada através da API)
A conta de serviço usada pelo Cloud Scheduler tem de ter a função
roles/iam.serviceAccountUser, quer a conta de serviço seja especificada pelo utilizador ou a conta de serviço predefinida do Compute Engine. Para mais informações, consulte o artigo Funções do pipeline de dados.Tem de poder agir como a conta de serviço usada pelo Cloud Scheduler e pelo Dataflow. Para tal, tem de lhe ser atribuída a função
roles/iam.serviceAccountUsernessa conta. Se não selecionar uma conta de serviço para o Cloud Scheduler e o Dataflow, é usada a conta de serviço do Compute Engine predefinida.
Crie um data pipeline
Pode criar um pipeline de dados do Dataflow de duas formas:
A página de configuração dos pipelines de dados: quando acede pela primeira vez à funcionalidade de pipelines do Dataflow na Google Cloud consola, é aberta uma página de configuração. Ativar as APIs indicadas para criar pipelines de dados.
Importe um trabalho
Pode importar uma tarefa de streaming ou em lote do Dataflow baseada num modelo clássico ou flexível e transformá-la num pipeline de dados.
Na Google Cloud consola, aceda à página Tarefas do Dataflow.
Selecione uma tarefa concluída e, de seguida, na página Detalhes da tarefa, selecione + Importar como um pipeline.
Na página Criar pipeline a partir de modelo, os parâmetros são preenchidos com as opções da tarefa importada.
Para um trabalho em lote, na secção Agende o seu pipeline, forneça uma programação de recorrência. O fornecimento de um endereço de conta de email para o Cloud Scheduler, que é usado para agendar execuções em lote, é opcional. Se não for especificado, é usada a conta de serviço predefinida do Compute Engine.
Crie um data pipeline
Na Google Cloud consola, aceda à página Dataflow Pipelines de dados.
Selecione + Criar pipeline de dados.
Na página Criar pipeline a partir de modelo, indique um nome para o pipeline e preencha os outros campos de seleção e parâmetros do modelo.
Para um trabalho em lote, na secção Agende o seu pipeline, forneça uma programação de recorrência. O fornecimento de um endereço de conta de email para o Cloud Scheduler, que é usado para agendar execuções em lote, é opcional. Se não for especificado um valor, é usada a conta de serviço predefinida do Compute Engine.
Crie um data pipeline em lote
Para criar este pipeline de dados em lote de amostra, tem de ter acesso aos seguintes recursos no seu projeto:
- Um contentor do Cloud Storage para armazenar ficheiros de entrada e saída
- Um conjunto de dados do BigQuery para criar uma tabela.
Esta pipeline de exemplo usa o modelo de pipeline em lote Texto do Cloud Storage para o BigQuery. Este modelo lê ficheiros no formato CSV do Cloud Storage, executa uma transformação e, em seguida, insere valores numa tabela do BigQuery com três colunas.
Crie os seguintes ficheiros no seu disco local:
Um ficheiro
bq_three_column_table.jsonque contém o seguinte esquema da tabela de destino do BigQuery.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }Um ficheiro
split_csv_3cols.jsJavaScript que implementa uma transformação simples nos dados de entrada antes da inserção no BigQuery.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }Um
file01.csvficheiro CSV com vários registos que são inseridos na tabela do BigQuery.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
Use o comando
gcloud storage cppara copiar os ficheiros para pastas num contentor do Cloud Storage no seu projeto, da seguinte forma:Copiar
bq_three_column_table.jsonesplit_csv_3cols.jsparags://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/Copiar
file01.csvparags://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
Na Google Cloud consola, aceda à página Recipientes do Cloud Storage.
Para criar uma
tmppasta no seu contentor do Cloud Storage, selecione o nome da pasta para abrir a página de detalhes do contentor, e, de seguida, clique em Criar pasta.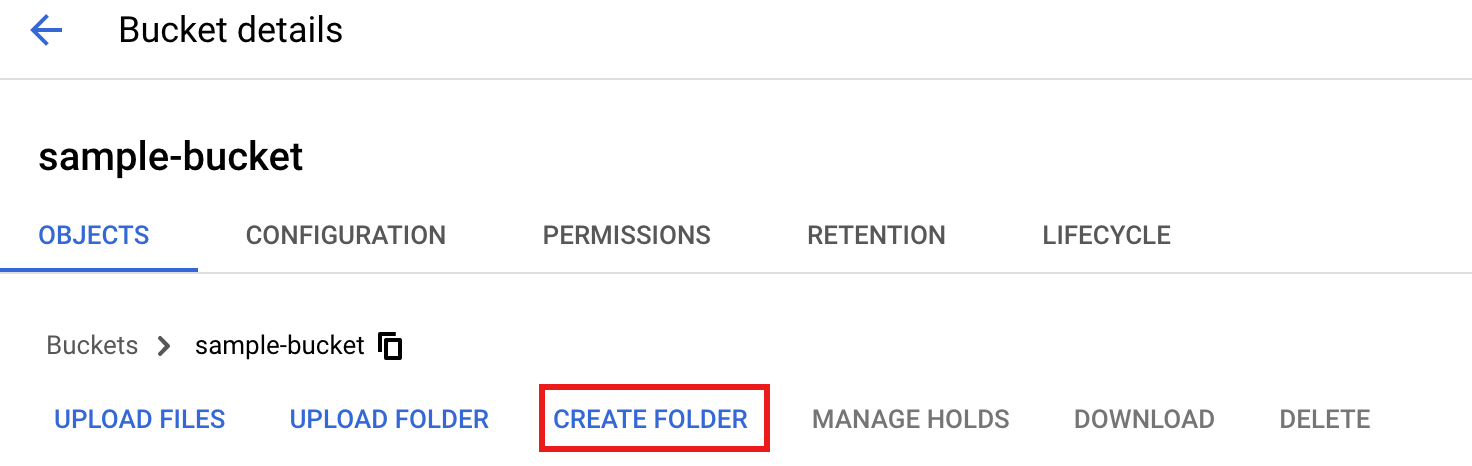
Na Google Cloud consola, aceda à página Dataflow Pipelines de dados.
Selecione Criar pipeline de dados. Introduza ou selecione os seguintes itens na página Criar pipeline a partir de modelo:
- Em Nome do pipeline, introduza
text_to_bq_batch_data_pipeline. - Para Ponto final regional, selecione uma região do Compute Engine. As regiões de origem e de destino têm de corresponder. Por conseguinte, o contentor do Cloud Storage e a tabela do BigQuery têm de estar na mesma região.
Para o modelo do Dataflow, em Processar dados em massa (em lote), selecione Ficheiros de texto no Cloud Storage para o BigQuery.
Para Agendar a sua conduta, selecione um agendamento, como Por hora no minuto 25, no seu fuso horário. Pode editar a programação depois de enviar o pipeline. O fornecimento de um endereço de email para o Cloud Scheduler, que é usado para agendar execuções em lote, é opcional. Se não for especificado, é usada a conta de serviço predefinida do Compute Engine.
Em Parâmetros obrigatórios, introduza o seguinte:
- Para o caminho da UDF de JavaScript no Cloud Storage:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- Para o caminho JSON:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- Para Nome da FDU de JavaScript:
transform - Para a tabela de saída do BigQuery:
PROJECT_ID:DATASET_ID.three_column_table
- Para o caminho de entrada do Cloud Storage:
BUCKET_ID/inputs/file01.csv
- Para o diretório temporário do BigQuery:
BUCKET_ID/tmp
- Para Localização temporária:
BUCKET_ID/tmp
- Para o caminho da UDF de JavaScript no Cloud Storage:
Clique em Criar pipeline.
- Em Nome do pipeline, introduza
Confirme as informações do pipeline e do modelo, e veja o histórico atual e anterior na página Detalhes do pipeline.
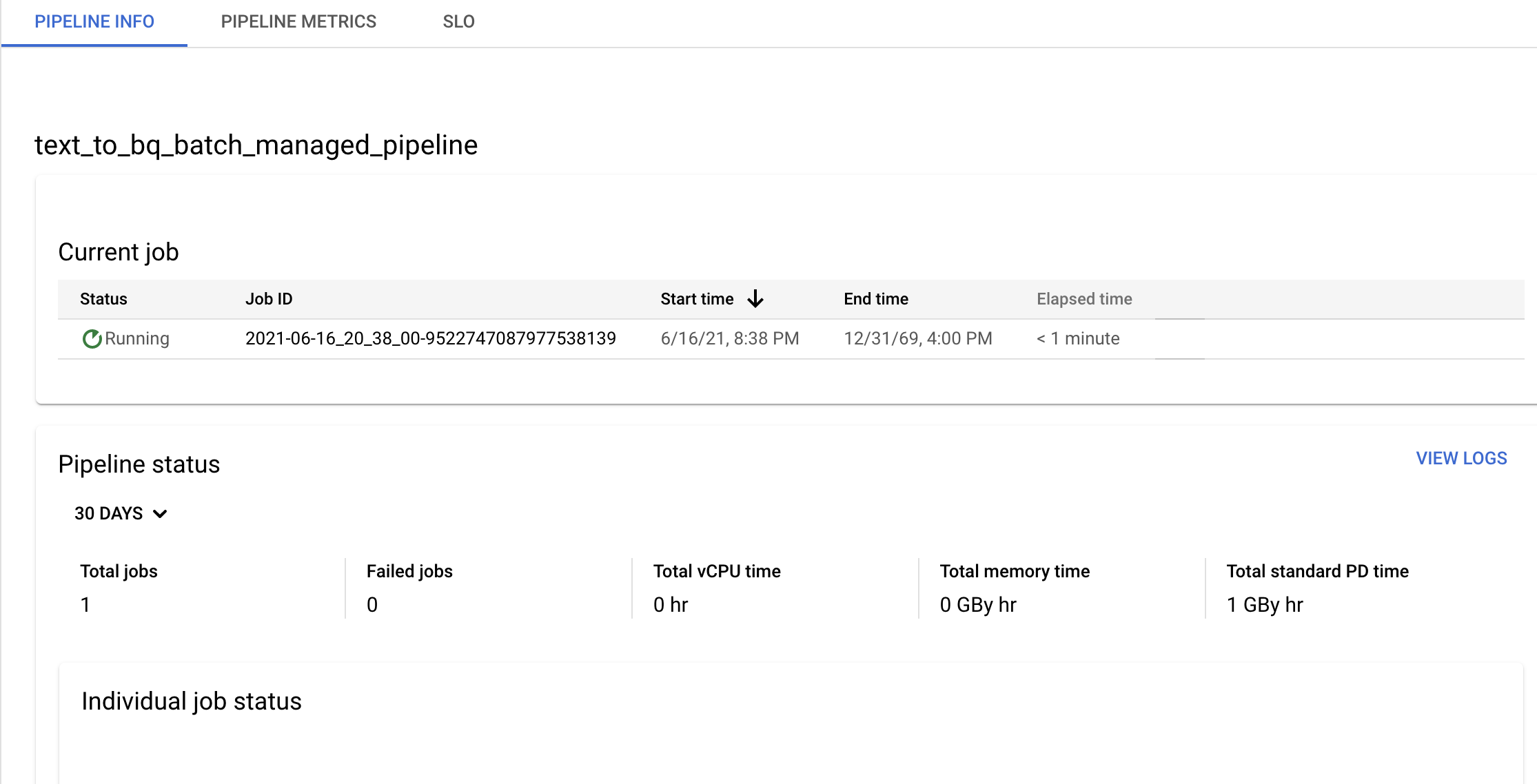
Pode editar o horário do pipeline de dados no painel Informações do pipeline na página Detalhes do pipeline.
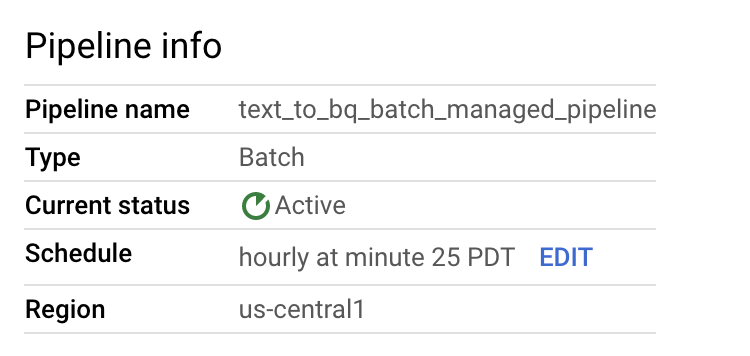
Também pode executar um pipeline em lote a pedido através do botão Executar na consola de pipelines do Dataflow.
Crie um data pipeline de streaming de amostra
Pode criar um pipeline de dados de streaming de amostra seguindo as instruções do pipeline de lotes de amostra, com as seguintes diferenças:
- Para Horário do pipeline, não especifique um horário para um pipeline de dados de streaming. A tarefa de streaming do Dataflow é iniciada imediatamente.
- Para o modelo do Dataflow, em Processar dados continuamente (stream), selecione Ficheiros de texto no Cloud Storage para o BigQuery.
- Para o Tipo de máquina de trabalho, o pipeline processa o conjunto inicial de ficheiros que correspondem ao padrão
gs://BUCKET_ID/inputs/file01.csve quaisquer ficheiros adicionais que correspondam a este padrão que carregar para a pastainputs/. Se o tamanho dos ficheiros CSV exceder vários GB, para evitar possíveis erros de falta de memória, selecione um tipo de máquina com mais memória do que o tipo de máquinan1-standard-4predefinido, comon1-highmem-8.
Resolução de problemas
Esta secção mostra como resolver problemas com pipelines de dados do Dataflow.
A tarefa do data pipeline não é iniciada
Quando usa pipelines de dados para criar uma programação de tarefas recorrente, a tarefa do Dataflow pode não ser iniciada e é apresentado um erro de estado 503 nos ficheiros de registo do Cloud Scheduler.
Este problema ocorre quando o Dataflow não consegue executar temporariamente a tarefa.
Para contornar este problema, configure o Cloud Scheduler para tentar novamente a tarefa. Uma vez que o problema é temporário, quando a tarefa é repetida, pode ter êxito. Para mais informações sobre como definir valores de repetição no Cloud Scheduler, consulte o artigo Criar uma tarefa.
Investigue violações de objetivos da pipeline
As secções seguintes descrevem como investigar pipelines que não cumprem os objetivos de desempenho.
Pipelines de lotes recorrentes
Para uma análise inicial do estado do seu pipeline, na página Informações do pipeline na Google Cloud consola, use os gráficos Estado da tarefa individual e Tempo de processamento por passo. Estes gráficos encontram-se no painel de estado do pipeline.
Exemplo de investigação:
Tem um pipeline de processamento em lote recorrente que é executado a cada hora, 3 minutos depois da hora. Normalmente, cada tarefa é executada durante aproximadamente 9 minutos. Tem um objetivo para todas as tarefas a concluir em menos de 10 minutos.
O gráfico de estado da tarefa mostra que uma tarefa foi executada durante mais de 10 minutos.
Na tabela do histórico de atualização/execução, encontre a tarefa que foi executada durante a hora de interesse. Clique para aceder à página de detalhes da tarefa do Dataflow. Nessa página, encontre a fase de execução mais longa e, em seguida, procure nos registos possíveis erros para determinar a causa do atraso.
Pipelines de streaming
Para uma análise inicial do estado da sua conduta, na página Detalhes da conduta, no separador Informações da conduta, use o gráfico de atualização de dados. Este gráfico encontra-se no painel de estado do pipeline.
Exemplo de investigação:
Tem um pipeline de streaming que normalmente produz um resultado com uma atualidade dos dados de 20 segundos.
Definiu um objetivo de ter uma garantia de atualidade dos dados de 30 segundos. Quando revê o gráfico de atualidade dos dados, repara que, entre as 09:00 e as 10:00, a atualidade dos dados aumentou para quase 40 segundos.
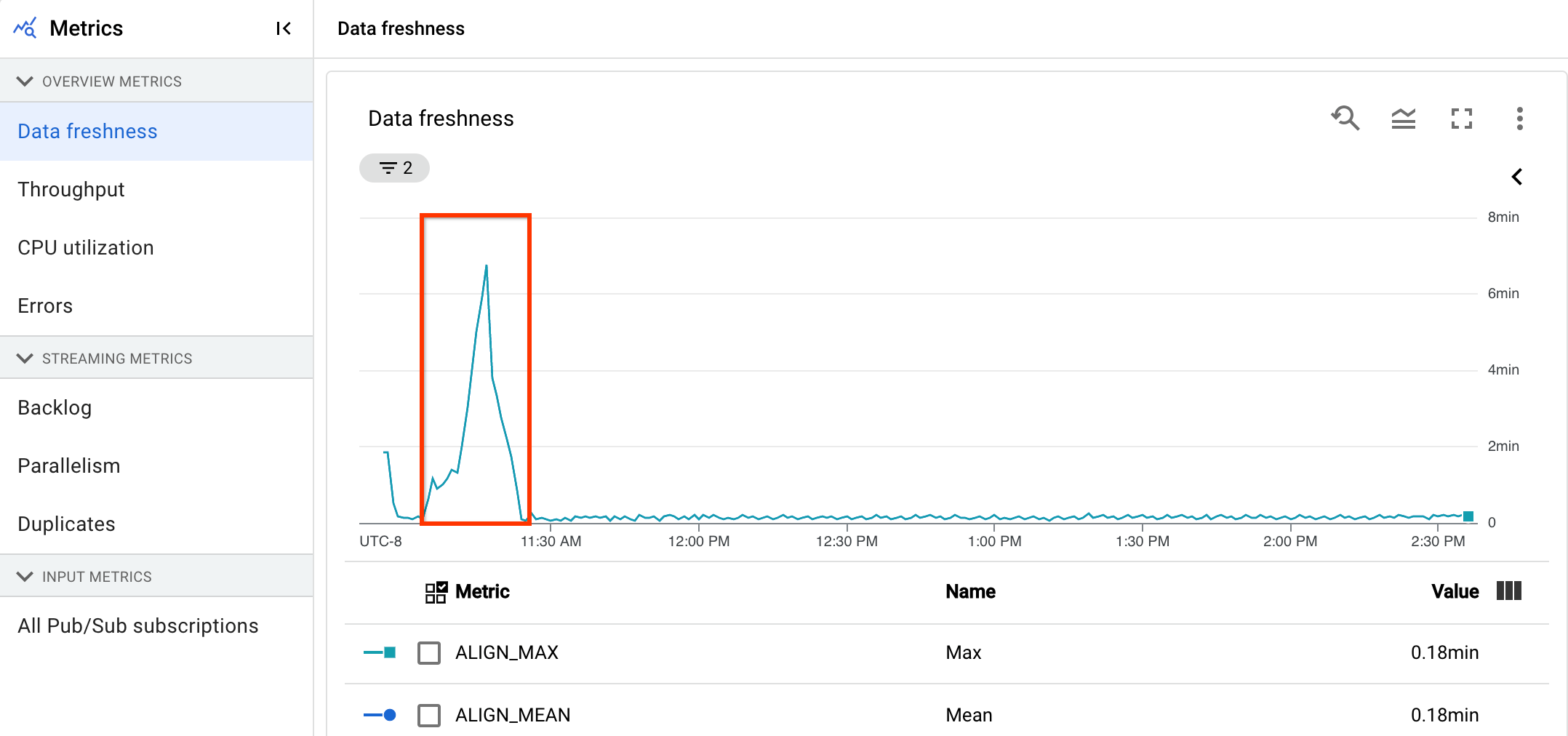
Mude para o separador Métricas de pipeline e, em seguida, veja os gráficos de utilização da CPU e utilização da memória para análise mais detalhada.
Erro: o ID do pipeline já existe no projeto
Se tentar criar um novo pipeline com um nome que já existe no seu projeto, recebe esta mensagem de erro: Pipeline Id already exist within the
project. Para evitar este problema, escolha sempre nomes exclusivos para os seus pipelines.