Übersicht
Sie können Dataflow Data Pipelines für die folgenden Aufgaben verwenden:
- Wiederkehrende Jobzeitpläne erstellen
- Ermitteln, wo Ressourcen für mehrere Jobausführungen eingesetzt werden
- Ziele zur Datenaktualität definieren und verwalten
- Einzelne Pipelinephasen aufschlüsseln, um Ihre Pipelines zu korrigieren und zu optimieren
Die API-Dokumentation finden Sie in der Data Pipelines-Referenz.
Features
- Wiederkehrende Batchpipeline erstellen, um einen Batchjob nach einem Zeitplan auszuführen.
- Wiederkehrende Batchpipeline erstellen, um einen Batchjob mit der neuesten Version der Eingabedaten auszuführen.
- Kurzübersicht der Pipelineübersicht verwenden, um die zusammengefasste Kapazitätsnutzung und den Ressourcenverbrauch einer Pipeline aufzurufen.
- Datenaktualität einer Streamingpipeline ansehen. Dieser Messwert, der sich im Laufe der Zeit ändert, kann an eine Benachrichtigung gebunden werden, die Sie informiert, wenn die Aktualität unter ein bestimmtes Ziel fällt.
- Mit Grafiken zu Pipelinemesswerten Batchpipelinejobs vergleichen und Anomalien finden.
Beschränkungen
Regionale Verfügbarkeit: Sie können Datenpipelines in verfügbaren Cloud Scheduler-Regionen erstellen.
Kontingent:
- Standardanzahl von Pipelines pro Projekt: 500
Standardanzahl von Pipelines pro Organisation: 2.500
Das Kontingent auf Organisationsebene ist standardmäßig deaktiviert. Sie können Kontingente auf Organisationsebene aktivieren. In diesem Fall kann jede Organisation standardmäßig höchstens 2.500 Pipelines haben.
Labels: Sie können keine benutzerdefinierten Labels verwenden, um Datenpipelines mit Labels zu versehen. Wenn Sie jedoch das Feld
additionalUserLabelsverwenden, werden diese Werte an den Dataflow-Job weitergegeben. Weitere Informationen dazu, wie Labels auf einzelne Dataflow-Jobs angewendet werden, finden Sie unter Pipeline-Optionen.
Arten von Datenpipelines
Dataflow hat zwei Datenpipeline-Typen: Streaming und Batch. Beide Pipeline-Typen führen Jobs aus, die in Dataflow-Vorlagen definiert sind.
- Streaming-Datenpipeline
- Eine Streaming-Datenpipeline führt unmittelbar nach ihrer Erstellung einen Dataflow-Streamingjob aus.
- Batch-Datenpipeline
Eine Batch-Datenpipeline führt einen Dataflow-Batchjob nach einem benutzerdefinierten Zeitplan aus. Der Dateiname der Batchpipeline-Eingabe kann parametrisiert werden, um eine inkrementelle Batchpipeline-Verarbeitung zu ermöglichen.
Inkrementelle Batchpipelines
Sie können Datum-/Uhrzeit-Platzhalter verwenden, um ein inkrementelles Eingabedateiformat für eine Batchpipeline anzugeben.
- Platzhalter für Jahr, Monat, Tag, Stunde, Minute und Sekunde können verwendet werden und müssen dem
strftime()-Format entsprechen. Vor Platzhaltern steht das Prozentsymbol (%). - Die Parameterformatierung wird beim Erstellen der Pipeline nicht überprüft.
- Beispiel: Wenn Sie "gs://bucket/Y" als parametrisierten Eingabepfad angeben, wird dieser als "gs://bucket/Y" ausgewertet, da "Y" ohne vorangestelltes "%" nicht dem
strftime()-Format entspricht.
- Beispiel: Wenn Sie "gs://bucket/Y" als parametrisierten Eingabepfad angeben, wird dieser als "gs://bucket/Y" ausgewertet, da "Y" ohne vorangestelltes "%" nicht dem
Bei jeder Ausführungszeit der geplanten Batchpipeline wird der Platzhalterteil des Pfads der Eingabedatei mit der aktuellen (oder versetzten) Zeit bewertet. Datumswerte werden anhand des aktuellen Datums in der Zeitzone des geplanten Jobs ausgewertet. Wenn der ausgewertete Pfad mit dem Pfad einer Eingabedatei übereinstimmt, wird die Datei zur Verarbeitung durch die Batchpipeline zum geplanten Zeitpunkt erfasst.
- Beispiel: Die Ausführung einer Batchpipeline wird zu Beginn jeder Stunde (PST) geplant. Wenn Sie den Eingabepfad als
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csvparametrisieren, wird der Eingabepfad der am 15. April 2021 um 18:00 Uhr PST alsgs://bucket-name/2021-04-15/prefix-18_00.csvausgewertet.
Zeitverschiebungsparameter verwenden
Sie können die Zeitverschiebungsparameter „+“ oder „-“ für Minuten oder Stunden verwenden.
Um einen Eingabepfad mit einer ausgewerteten Datum-/Uhrzeit-Angabe zu unterstützen, die an einen Punkt vor oder nach der aktuellen Datum-/Uhrzeit-Angabe des Pipelinezeitplans verschoben wird, schließen Sie diese Parameter in geschweiften Klammern ein.
Verwenden Sie das Format {[+|-][0-9]+[m|h]}. Die Batchpipeline wird zum geplanten Zeitpunkt wiederholt, der Eingabedateipfad wird jedoch mit dem angegebenen zeitlichen Versatz ausgewertet.
- Beispiel: Die Ausführung einer Batchpipeline wird zu Beginn jeder Stunde (PST) geplant. Wenn Sie den Eingabepfad als
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}parametrisieren, wird der Eingabepfad der am 15. April 2021 um 18:00 Uhr PST alsgs://bucket-name/2021-04-15/prefix-16_00.csvausgewertet.
Datenpipeline-Rollen
Damit Dataflow-Datenpipeline-Vorgänge erfolgreich sind, benötigen Sie die erforderlichen IAM-Rollen:
Sie benötigen die entsprechende Rolle, um Vorgänge auszuführen:
Datapipelines.admin: kann alle Datenpipelinevorgänge ausführenDatapipelines.viewer: kann Datenpipelines und Jobs ansehenDatapipelines.invoker: kann einen Datenpipeline-Job ausführen (diese Rolle kann mit der API aktiviert werden)
Das von Cloud Scheduler verwendete Dienstkonto muss die Rolle
roles/iam.serviceAccountUserhaben. Dies gilt unabhängig davon, ob es sich um ein benutzerdefiniertes Dienstkonto oder das Compute Engine-Standarddienstkonto handelt. Weitere Informationen finden Sie unter Datenpipeline-Rollen.Sie müssen in der Lage sein, als das von Cloud Scheduler und Dataflow verwendete Dienstkonto zu fungieren, indem Sie die
roles/iam.serviceAccountUser-Rolle für dieses Konto erhalten. Wenn Sie kein Dienstkonto für Cloud Scheduler und Dataflow auswählen, wird das Compute Engine-Standarddienstkonto verwendet.
Datenpipeline erstellen
Sie können eine Datenpipeline auf zwei Arten erstellen:
Einrichtungsseite für Datenpipelines: Wenn Sie in der Google Cloud Console zum ersten Mal auf das Dataflow-Pipelines-Feature zugreifen, wird eine Einrichtungsseite geöffnet. Aktivieren Sie die aufgelisteten APIs, um Datenpipelines zu erstellen.
Job importieren
Sie können einen Dataflow-Batch- oder -Streamingjob importieren, der auf einer klassischen oder flexiblen Vorlage basiert, und ihn zu einer Datenpipeline machen.
Rufen Sie in der Google Cloud Console die Dataflow-Seite Jobs auf.
Wählen Sie einen abgeschlossenen Job aus und wählen Sie dann auf der Seite Jobdetails die Option +Als Pipeline importieren aus.
Auf der Seite Pipeline aus Vorlage erstellen werden die Parameter mit den Optionen des importierten Jobs ausgefüllt.
Geben Sie im Abschnitt Pipeline planen für einen Batchjob einen Wiederholungsplan an. Die Angabe einer E-Mail-Adresse für Cloud Scheduler, die zum Planen von Batchausführungen verwendet wird, ist optional. Wenn keine angegeben ist, wird das Compute Engine-Standarddienstkonto verwendet.
Datenpipeline erstellen
Rufen Sie in der Google Cloud Console die Dataflow-Seite Datenpipelines auf.
Wählen Sie +Datenpipeline erstellen aus.
Geben Sie auf der Seite Pipeline aus Vorlage erstellen einen Pipeline-Namen an und füllen Sie die anderen Vorlagenauswahl- und Parameterfelder aus.
Geben Sie im Abschnitt Pipeline planen für einen Batchjob einen Wiederholungsplan an. Die Angabe einer E-Mail-Adresse für Cloud Scheduler, die zum Planen von Batchausführungen verwendet wird, ist optional. Wenn kein Wert angegeben ist, wird das Compute Engine-Standarddienstkonto verwendet.
Batch-Datenpipeline erstellen
Zum Erstellen dieser Beispiel-Batch-Datenpipeline müssen Sie Zugriff auf die folgenden Ressourcen in Ihrem Projekt haben:
- Einen Cloud Storage-Bucket zum Speichern von Eingabe- und Ausgabedateien
- Ein BigQuery-Dataset zum Erstellen einer Tabelle
Diese Beispiel-Pipeline verwendet die Batchpipeline-Vorlage Cloud Storage-Text für BigQuery. Sie liest die Dateien im CSV-Format aus Cloud Storage, führt eine Transformation aus und fügt dann Werte in eine BigQuery-Tabelle mit drei Spalten ein.
Erstellen Sie die folgenden Dateien auf Ihrem lokalen Laufwerk:
Eine
bq_three_column_table.json-Datei, die das folgende Schema der BigQuery-Zieltabelle enthält.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }Eine
split_csv_3cols.js-JavaScript-Datei, die eine einfache Transformation für die Eingabedaten vor dem Einfügen in BigQuery implementiert.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }Eine
file01.csv-CSV-Datei mit mehreren Datensätzen, die in die BigQuery-Tabelle eingefügt werden.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
Verwenden Sie den Befehl
gcloud storage cp, um die Dateien so in Ordner in einem Cloud Storage-Bucket in Ihrem Projekt zu kopieren:Kopieren Sie
bq_three_column_table.jsonundsplit_csv_3cols.jsnachgs://BUCKET_ID/text_to_bigquery/:gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/Kopieren Sie
file01.csvnachgs://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
Wechseln Sie in der Cloud Console zur Seite Cloud Storage-Buckets.
Wählen Sie zum Erstellen eines Ordners
tmpin Ihrem Cloud Storage-Bucket den Namen des Ordners aus, um die Seite Bucket-Details zu öffnen, und klicken Sie dann auf Ordner erstellen.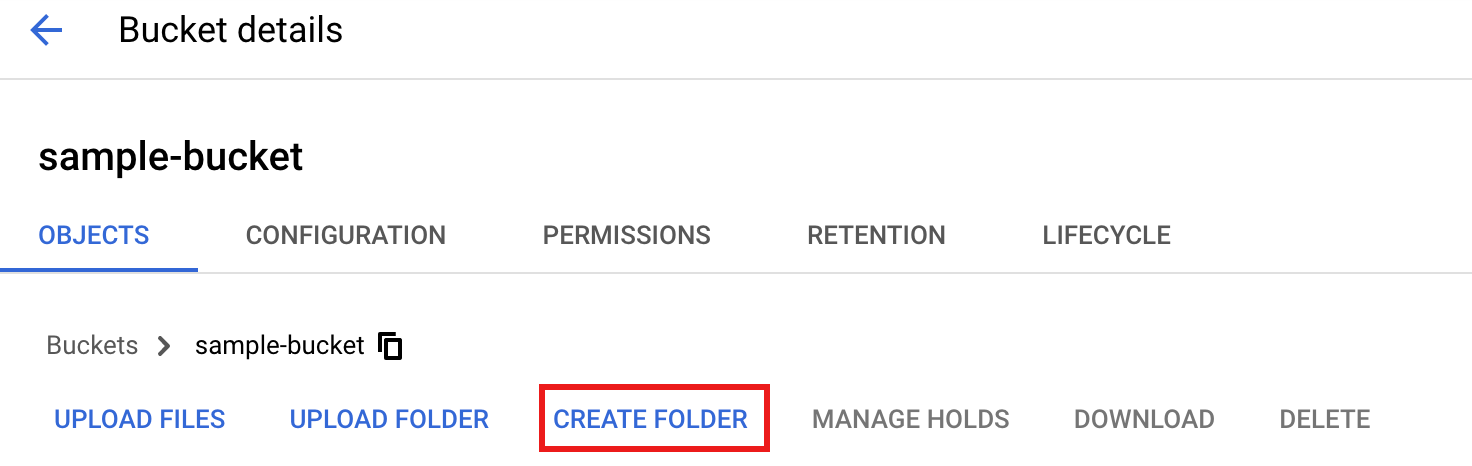
Rufen Sie in der Google Cloud Console die Dataflow-Seite Datenpipelines auf.
Wählen Sie Datenpipeline erstellen aus. Geben Sie auf der Seite Pipeline aus Vorlage erstellen die folgenden Elemente ein oder wählen Sie sie aus:
- Geben Sie als Pipelinenamen
text_to_bq_batch_data_pipelineein. - Wählen Sie für Regionaler Endpunkt eine Compute Engine-Region aus. Die Quell- und Zielregionen müssen übereinstimmen. Daher müssen sich Ihr Cloud Storage-Bucket und die BigQuery-Tabelle in derselben Region befinden.
Wählen Sie für die Dataflow-Vorlage in Daten im Bulk verarbeiten (Batch) die Option Textdateien in Cloud Storage für BigQuery aus.
Wählen Sie für Pipeline planen einen Zeitplan aus, z. B. Stündlich zur Minute 25 in Ihrer Zeitzone. Sie können den Zeitplan bearbeiten, nachdem Sie die Pipeline gesendet haben. Die Angabe einer E-Mail-Adresse für Cloud Scheduler, die zum Planen von Batchausführungen verwendet wird, ist optional. Wenn keine angegeben ist, wird das Compute Engine-Standarddienstkonto verwendet.
Geben Sie unter Erforderliche Parameter Folgendes ein:
- Für JavaScript-UDF-Pfad in Cloud Storage:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- Für JSON-Pfad:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- Für JavaScript-UDF-Name:
transform - Für BigQuery-Ausgabetabelle:
PROJECT_ID:DATASET_ID.three_column_table
- Für Cloud Storage-Eingabepfad:
BUCKET_ID/inputs/file01.csv
- Für Temporäres BigQuery-Verzeichnis:
BUCKET_ID/tmp
- Für Temporärer Speicherort:
BUCKET_ID/tmp
- Für JavaScript-UDF-Pfad in Cloud Storage:
Klicken Sie auf Pipeline erstellen.
- Geben Sie als Pipelinenamen
Bestätigen Sie die Pipeline- und Vorlageninformationen sowie den aktuellen und vorherigen Verlauf auf der Seite Pipelinedetails.
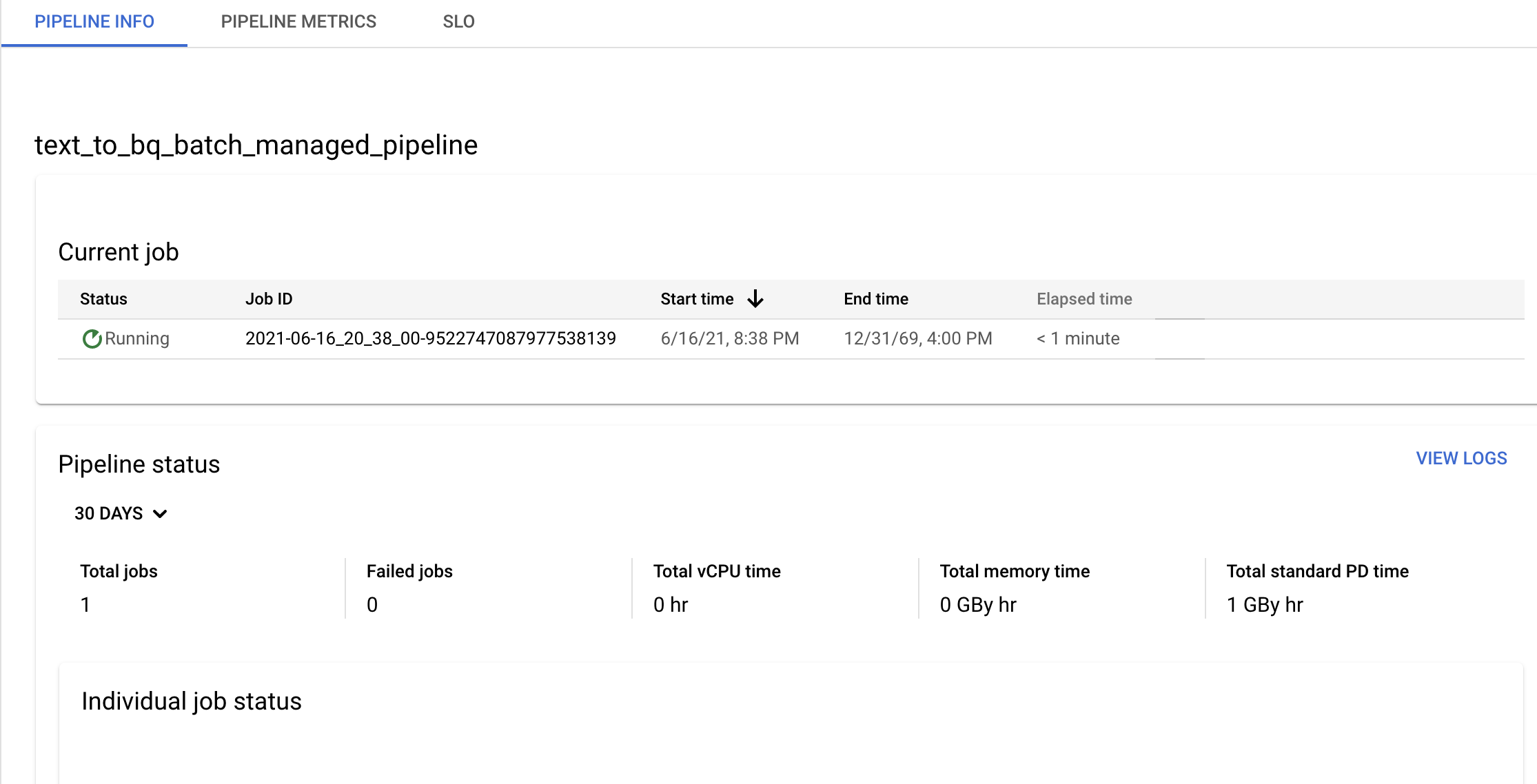
Sie können den Zeitplan der Datenpipeline auf dem Feld Pipeline-Details im Bereich Informationen zur Pipeline bearbeiten.
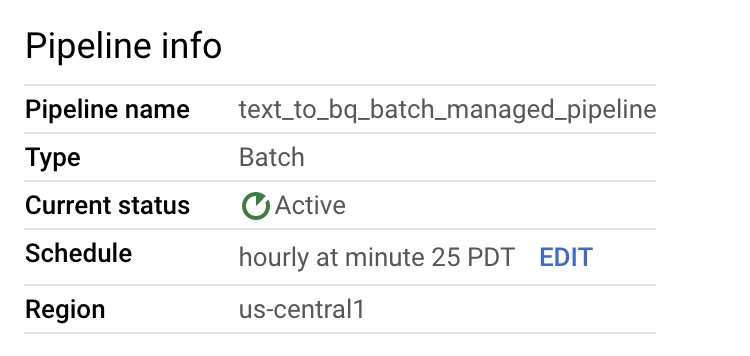
Sie können bei Bedarf auch eine Batchpipeline über die Schaltfläche Run in der Dataflow Pipelines-Konsole ausführen.
Beispiel-Streaming-Datenpipeline erstellen
Sie können eine Beispiel-Streaming-Datenpipeline gemäß der Anleitung für die Beispiel-Batchpipeline erstellen. Es gibt jedoch folgende Unterschiede:
- Geben Sie für Pipelinezeitplan keinen Zeitplan für eine Streaming-Datenpipeline an. Der Dataflow-Streamingjob wird sofort gestartet.
- Wählen Sie für die Dataflow-Vorlage in Daten kontinuierlich verarbeiten (Stream) die Option Textdateien in Cloud Storage für BigQuery aus.
- Für den Worker-Maschinentyp verarbeitet die Pipeline den ersten Satz von Dateien, die mit dem Muster
gs://BUCKET_ID/inputs/file01.csvübereinstimmen, sowie alle zusätzlichen Dateien, die diesem Muster entsprechen und die Sie in den Ordnerinputs/hochladen. Wenn die Größe der CSV-Dateien mehrere GB überschreitet, wählen Sie einen Maschinentyp aus, der mehr Arbeitsspeicher als der Standardmaschinentypn1-standard-4hat, z. B.n1-highmem-8, um eventuelle Fehler aufgrund mangelnden Speichers zu vermeiden.
Fehlerbehebung
In diesem Abschnitt erfahren Sie, wie Sie Probleme mit Dataflow-Datenpipelines beheben.
Datenpipelinejob kann nicht gestartet werden
Wenn Sie Datenpipelines zum Erstellen eines wiederkehrenden Jobzeitplans verwenden, wird der Dataflow-Job möglicherweise nicht gestartet und in den Cloud Scheduler-Logdateien wird der Statusfehler 503 angezeigt.
Dieses Problem tritt auf, wenn Dataflow den Job vorübergehend nicht ausführen kann.
Zur Umgehung dieses Problems konfigurieren Sie Cloud Scheduler so, dass der Job wiederholt wird. Da das Problem nur vorübergehend ist, kann der Job beim Wiederholen des Jobs erfolgreich sein. Weitere Informationen zum Festlegen von Wiederholungswerten in Cloud Scheduler finden Sie unter Job erstellen.
Verstöße gegen Pipelineziele untersuchen
In den folgenden Abschnitten wird beschrieben, wie Sie Pipelines untersuchen, die den Leistungszielen nicht genügen.
Wiederkehrende Batchpipelines
Für eine erste Analyse des Zustands Ihrer Pipeline verwenden Sie auf der Seite Informationen zur Pipeline in der Google Cloud Console den Diagramme Status der einzelnen Jobs und Thread-Zeit pro Schritt. Diese Grafiken befinden sich im Pipelinestatusbereich.
Beispieluntersuchung:
Sie haben eine wiederkehrende Batchpipeline, die stündlich drei Minuten nach der vollen Stunde ausgeführt wird. Jeder Job wird in der Regel ca. 9 Minuten lang ausgeführt und das Ziel ist, dass alle Jobs in weniger als 10 Minuten abgeschlossen werden.
Das Diagramm zum Jobstatus zeigt, dass ein Job länger als 10 Minuten ausgeführt wurde.
Suchen Sie in der Verlaufstabelle Aktualisierung/Ausführung den Job, der in der entsprechenden Stunde ausgeführt wurde. Klicken Sie zur Seite mit den Dataflow-Jobdetails. Suchen Sie auf dieser Seite die länger laufende Phase und suchen in den Logs nach möglichen Fehlern, um die Ursache der Verzögerung zu ermitteln.
Streamingpipelines
Für eine erste Analyse des Zustands Ihrer Pipeline verwenden Sie auf der Seite Pipeline-Details auf dem Tab Informationen zur Pipeline das Diagramm zur Datenaktualität. Diese Grafik befindet sich im Bereich "Pipelinestatus".
Beispieluntersuchung:
Sie haben eine Streamingpipeline, die normalerweise eine Ausgabe mit einer Datenaktualität von 20 Sekunden erzeugt.
Sie legen als Ziel eine garantierte Datenaktualität von 30 Sekunden fest. Bei der Überprüfung des Diagramms zur Datenaktualität sehen Sie, dass die Datenaktualität zwischen 9 und 10 Uhr auf fast 40 Sekunden gestiegen ist.
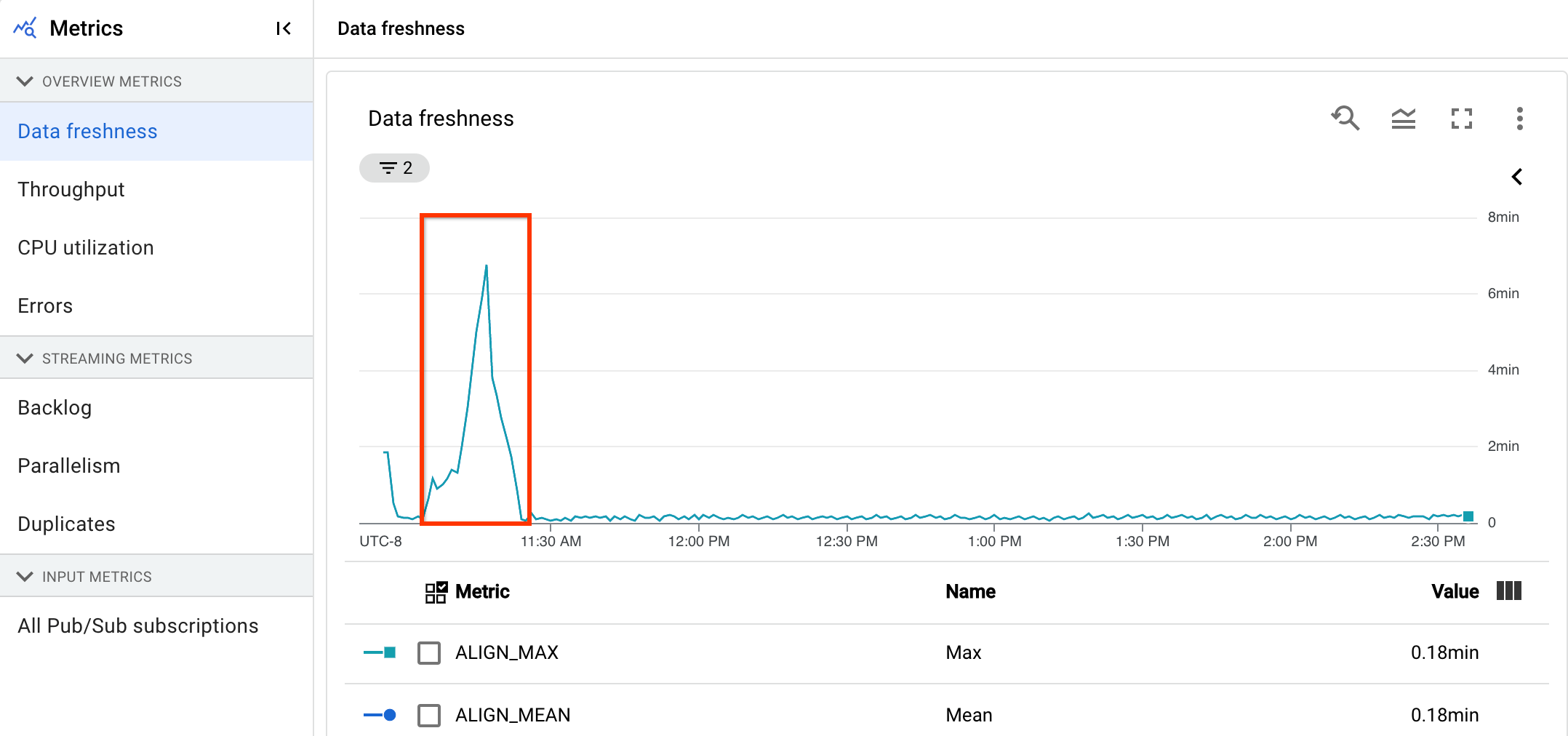
Wechseln Sie zum Tab Pipeline-Messwerte und sehen sich dann die Diagramme zu CPU-Auslastung und Arbeitsspeicherauslastung zur weiteren Analyse an.
Fehler: Pipeline-ID ist bereits im Projekt vorhanden
Wenn Sie versuchen, eine neue Pipeline mit einem Namen zu erstellen, der bereits in Ihrem Projekt vorhanden ist, erhalten Sie diese Fehlermeldung: Pipeline Id already exist within the
project. Wählen Sie zur Vermeidung dieses Problems immer eindeutige Namen für Ihre Pipelines.