Información general
Puedes usar las canalizaciones de datos de Dataflow para las siguientes tareas:
- Crea programaciones de tareas recurrentes.
- Descubra dónde se gastan los recursos en varias ejecuciones de tareas.
- Definir y gestionar objetivos de actualización de datos.
- Desglosa las fases de la canalización para corregirlas y optimizarlas.
Para consultar la documentación de la API, consulta la referencia de Data Pipelines.
Funciones
- Crea una canalización de procesamiento por lotes periódica para ejecutar una tarea por lotes según una programación.
- Crea un flujo de procesamiento por lotes incremental periódico para ejecutar una tarea por lotes con la versión más reciente de los datos de entrada.
- Usa el gráfico de resultados de resumen de la canalización para ver el uso de la capacidad agregada y el consumo de recursos de una canalización.
- Consulte la actualización de datos de una canalización de streaming. Esta métrica, que evoluciona con el tiempo, se puede vincular a una alerta que te avise cuando la actualización sea inferior a un objetivo especificado.
- Usa gráficos de métricas de la canalización para comparar trabajos de canalizaciones por lotes y detectar anomalías.
Limitaciones
Disponibilidad regional: puedes crear flujos de datos en las regiones de Cloud Scheduler disponibles.
Cuota:
- Número predeterminado de flujos de procesamiento por proyecto: 500
Número predeterminado de flujos de procesamiento por organización: 2500
La cuota a nivel de organización está inhabilitada de forma predeterminada. Puedes habilitar las cuotas a nivel de organización. Si lo haces, cada organización podrá tener un máximo de 2500 canalizaciones de forma predeterminada.
Etiquetas: no puedes usar etiquetas definidas por el usuario para etiquetar flujos de procesamiento de datos de Dataflow. Sin embargo, cuando usa el campo
additionalUserLabels, esos valores se transfieren a su trabajo de Dataflow. Para obtener más información sobre cómo se aplican las etiquetas a los trabajos de Dataflow individuales, consulte Opciones de la canalización.
Tipos de flujos de procesamiento de datos
Dataflow tiene dos tipos de canalizaciones de datos: de streaming y por lotes. Ambos tipos de trabajos de ejecución de flujos de procesamiento se definen en plantillas de Dataflow.
- Flujo de procesamiento de datos de streaming
- Un flujo de procesamiento de datos de streaming ejecuta un trabajo de streaming de Dataflow inmediatamente después de crearse.
- Flujo de procesamiento de datos por lotes
Un flujo de procesamiento de datos por lotes ejecuta una tarea de Dataflow por lotes según una programación definida por el usuario. El nombre del archivo de entrada del flujo de procesamiento por lotes se puede parametrizar para permitir el procesamiento incremental del flujo de procesamiento por lotes.
Flujos de procesamiento por lotes incrementales
Puedes usar marcadores de posición de fecha y hora para especificar un formato de archivo de entrada incremental para una canalización por lotes.
- Se pueden usar marcadores de posición para el año, el mes, la fecha, la hora, los minutos y los segundos, y deben seguir el formato
strftime(). Los marcadores de posición van precedidos del símbolo de porcentaje (%). - El formato de los parámetros no se verifica durante la creación de la canalización.
- Ejemplo: Si especificas "gs://bucket/Y" como ruta de entrada parametrizada, se evaluará como "gs://bucket/Y", porque "Y" sin el prefijo "%" no se asigna al formato
strftime().
- Ejemplo: Si especificas "gs://bucket/Y" como ruta de entrada parametrizada, se evaluará como "gs://bucket/Y", porque "Y" sin el prefijo "%" no se asigna al formato
En cada hora de ejecución programada de la canalización por lotes, la parte del marcador de posición de la ruta de entrada se evalúa con la fecha y hora actuales (o desplazadas). Los valores de fecha se evalúan con la fecha actual de la zona horaria del trabajo programado. Si la ruta evaluada coincide con la ruta de un archivo de entrada, el archivo se recoge para que la canalización por lotes lo procese a la hora programada.
- Ejemplo: Una canalización por lotes se programa para que se repita al principio de cada hora (PST). Si parametrizas la ruta de entrada como
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv, el 15 de abril del 2021 a las 18:00 (PST), la ruta de entrada se evalúa comogs://bucket-name/2021-04-15/prefix-18_00.csv.
Usar parámetros de desfase horario
Puedes usar parámetros de cambio de hora de minutos u horas con los signos + o -.
Para que se pueda asociar una ruta de entrada con una fecha y hora evaluadas que se hayan desplazado antes o después de la fecha y hora actuales de la programación de la canalización, incluye estos parámetros entre llaves.
Usa el formato {[+|-][0-9]+[m|h]}. La canalización por lotes sigue repitiéndose a la hora programada, pero la ruta de entrada se evalúa con el desfase horario especificado.
- Ejemplo: Una canalización por lotes se programa para que se repita al principio de cada hora (PST). Si parametrizas la ruta de entrada como
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}, el 15 de abril del 2021 a las 18:00 (PST), la ruta de entrada se evalúa comogs://bucket-name/2021-04-15/prefix-16_00.csv.
Roles de flujo de procesamiento de datos
Para que las operaciones de la canalización de datos de Dataflow se realicen correctamente, necesitas los roles de gestión de identidades y accesos necesarios, que se indican a continuación:
Necesita el rol adecuado para realizar operaciones:
Datapipelines.admin: Puede realizar todas las operaciones de la canalización de datos.Datapipelines.viewer: Puede ver flujos de datos y trabajosDatapipelines.invoker: Puede invocar una ejecución de un trabajo de una canalización de datos (este rol se puede habilitar mediante la API).
La cuenta de servicio que usa Cloud Scheduler debe tener el rol
roles/iam.serviceAccountUser, tanto si la cuenta de servicio la especifica el usuario como si es la cuenta de servicio predeterminada de Compute Engine. Para obtener más información, consulta Roles de la canalización de datos.Para poder actuar como la cuenta de servicio que usan Cloud Scheduler y Dataflow, debes tener el rol
roles/iam.serviceAccountUseren esa cuenta. Si no seleccionas una cuenta de servicio para Cloud Scheduler y Dataflow, se usará la cuenta de servicio predeterminada de Compute Engine.
Crear un flujo de procesamiento de datos
Puedes crear una canalización de datos de Dataflow de dos formas:
Página de configuración de las canalizaciones de datos: cuando accedas por primera vez a la función de canalizaciones de Dataflow en la consola de Google Cloud , se abrirá una página de configuración. Habilita las APIs indicadas para crear flujos de procesamiento de datos.
Importar una tarea
Puedes importar una tarea de Dataflow por lotes o de streaming basada en una plantilla clásica o flexible y convertirla en un flujo de datos.
En la Google Cloud consola, ve a la página Trabajos de Dataflow.
Selecciona un trabajo completado y, en la página Detalles del trabajo, selecciona +Importar como una canalización.
En la página Crear flujo de procesamiento a partir de plantilla, los parámetros se rellenan con las opciones de la tarea importada.
En el caso de una tarea por lotes, en la sección Programa tu flujo de procesamiento, proporciona una programación de recurrencia. Proporcionar una dirección de cuenta de correo para Cloud Scheduler, que se usa para programar ejecuciones por lotes, es opcional. Si no se especifica, se usa la cuenta de servicio predeterminada de Compute Engine.
Crear un flujo de procesamiento de datos
En la Google Cloud consola, ve a la página Dataflow Pipelines de datos.
Selecciona + Crear flujo de procesamiento de datos.
En la página Crear flujo de procesamiento a partir de plantilla, proporcione un nombre para el flujo de procesamiento y rellene los demás campos de selección de plantilla y de parámetros.
En el caso de una tarea por lotes, en la sección Programa tu flujo de procesamiento, proporciona una programación de recurrencia. Proporcionar una dirección de cuenta de correo para Cloud Scheduler, que se usa para programar ejecuciones por lotes, es opcional. Si no se especifica ningún valor, se usa la cuenta de servicio predeterminada de Compute Engine.
Crear un flujo de procesamiento de datos por lotes
Para crear esta canalización de datos por lotes de ejemplo, debe tener acceso a los siguientes recursos de su proyecto:
- Un segmento de Cloud Storage para almacenar archivos de entrada y salida
- Un conjunto de datos de BigQuery para crear una tabla.
Este ejemplo de flujo de procesamiento usa la plantilla de flujo de procesamiento por lotes De archivos de texto de Cloud Storage a BigQuery. Esta plantilla lee archivos en formato CSV de Cloud Storage, ejecuta una transformación y, a continuación, inserta valores en una tabla de BigQuery con tres columnas.
Crea los siguientes archivos en tu unidad local:
Un archivo
bq_three_column_table.jsonque contenga el siguiente esquema de la tabla de BigQuery de destino.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }Un archivo
split_csv_3cols.jsJavaScript que implementa una transformación sencilla en los datos de entrada antes de insertarlos en BigQuery.function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }Un archivo
file01.csvCSV con varios registros que se insertan en la tabla de BigQuery.b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
Usa el comando
gcloud storage cppara copiar los archivos en carpetas de un segmento de Cloud Storage de tu proyecto, como se indica a continuación:Copiar
bq_three_column_table.jsonysplit_csv_3cols.jsengs://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/Copiar
file01.csvengs://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
En la Google Cloud consola, ve a la página Segmentos de Cloud Storage.
Para crear una carpeta
tmpen tu segmento de Cloud Storage, selecciona el nombre de la carpeta para abrir la página de detalles del segmento y, a continuación, haz clic en Crear carpeta.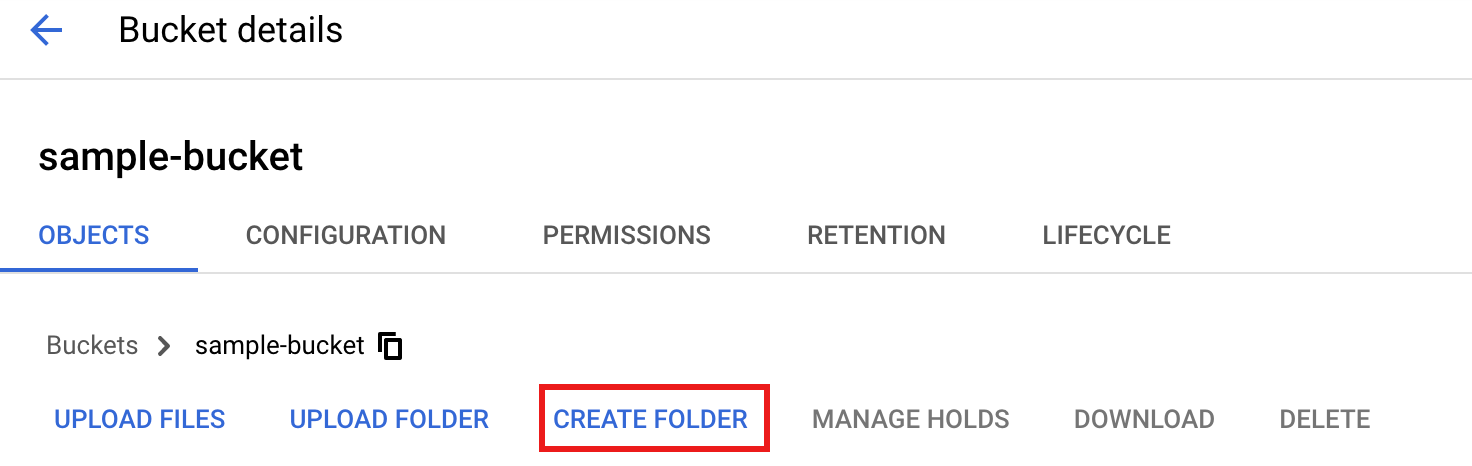
En la Google Cloud consola, ve a la página Dataflow Pipelines de datos.
Selecciona Crear flujo de procesamiento de datos. En la página Crear flujo de procesamiento a partir de plantilla, introduce o selecciona los siguientes elementos:
- En Nombre de la canalización, escribe
text_to_bq_batch_data_pipeline. - En Endpoint regional, selecciona una región de Compute Engine. Las regiones de origen y de destino deben coincidir. Por lo tanto, el segmento de Cloud Storage y la tabla de BigQuery deben estar en la misma región.
En Plantilla de Dataflow, en Procesar datos de forma masiva (por lotes), selecciona Archivos de texto en Cloud Storage a BigQuery.
En Programar flujo de procesamiento, seleccione una programación, como Cada hora en el minuto 25 de su zona horaria. Puedes editar la programación después de enviar la canalización. Proporcionar una dirección de cuenta de correo para Cloud Scheduler, que se usa para programar ejecuciones por lotes, es opcional. Si no se especifica, se usa la cuenta de servicio predeterminada de Compute Engine.
En Parámetros obligatorios, introduzca lo siguiente:
- En Ruta de la UDF de JavaScript en Cloud Storage:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- En Ruta de JSON:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- En Nombre de la función definida por el usuario de JavaScript, escriba
transform. - En Tabla de salida de BigQuery:
PROJECT_ID:DATASET_ID.three_column_table
- En Ruta de entrada de Cloud Storage:
BUCKET_ID/inputs/file01.csv
- En Directorio temporal de BigQuery:
BUCKET_ID/tmp
- En Ubicación temporal:
BUCKET_ID/tmp
- En Ruta de la UDF de JavaScript en Cloud Storage:
Haz clic en Crear canalización.
- En Nombre de la canalización, escribe
Confirma la información de la canalización y la plantilla, y consulta el historial actual y anterior en la página Detalles de la canalización.
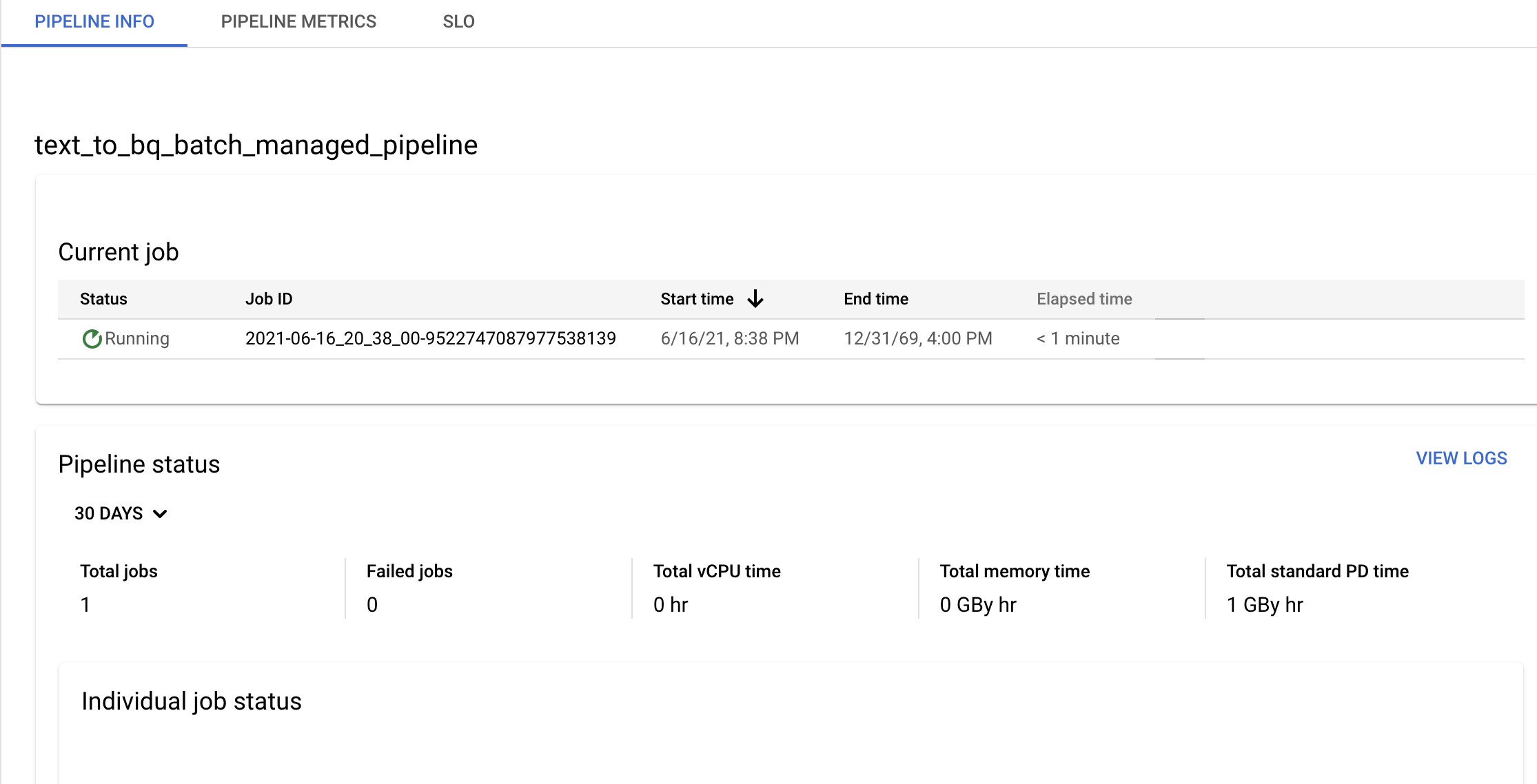
Puedes editar la programación de la canalización de datos en el panel Información de la canalización de la página Detalles de la canalización.
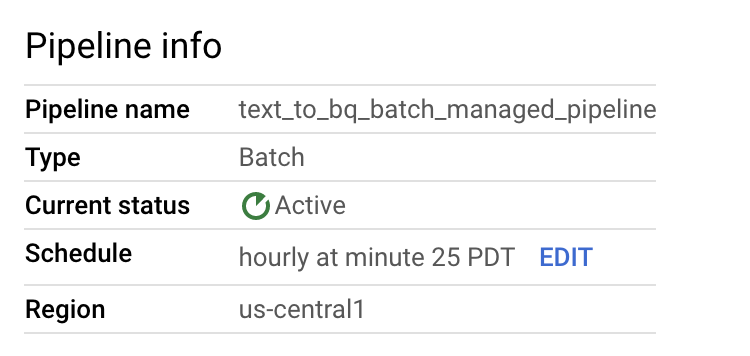
También puedes ejecutar un flujo de procesamiento por lotes bajo demanda con el botón Ejecutar de la consola de flujos de procesamiento de Dataflow.
Crear un flujo de procesamiento de datos de streaming de ejemplo
Para crear un flujo de procesamiento de datos de streaming de ejemplo, sigue las instrucciones del flujo de procesamiento por lotes de ejemplo, con las siguientes diferencias:
- En Programación del flujo de procesamiento, no especifiques ninguna programación para un flujo de procesamiento de datos de streaming. El trabajo de streaming de Dataflow se inicia inmediatamente.
- En Plantilla de Dataflow, en Procesar datos continuamente (streaming), selecciona Archivos de texto en Cloud Storage a BigQuery.
- En el caso de Tipo de máquina de trabajador, la canalización procesa el conjunto inicial de archivos que coinciden con el patrón
gs://BUCKET_ID/inputs/file01.csvy los archivos adicionales que coincidan con este patrón y que subas a la carpetainputs/. Si el tamaño de los archivos CSV supera varios GB, para evitar posibles errores de falta de memoria, selecciona un tipo de máquina con más memoria que el tipo de máquinan1-standard-4predeterminado, comon1-highmem-8.
Solución de problemas
En esta sección se explica cómo resolver problemas con las canalizaciones de datos de Dataflow.
No se puede iniciar un trabajo de flujo de procesamiento de datos
Cuando usas las canalizaciones de datos para crear una programación de tareas periódicas, es posible que tu tarea de Dataflow no se inicie y que aparezca un error de estado 503 en los archivos de registro de Cloud Scheduler.
Este problema se produce cuando Dataflow no puede ejecutar el trabajo temporalmente.
Para solucionar este problema, configura Cloud Scheduler para que vuelva a intentar ejecutar la tarea. Como el problema es temporal, es posible que el trabajo se complete cuando se vuelva a intentar. Para obtener más información sobre cómo definir los valores de reintento en Cloud Scheduler, consulta Crear un trabajo.
Investigar infracciones de objetivos de la cartera
En las siguientes secciones se describe cómo investigar las canalizaciones que no cumplen los objetivos de rendimiento.
Flujos de procesamiento por lotes periódicos
Para hacer un análisis inicial del estado de tu flujo de procesamiento, ve a la página Información del flujo de procesamiento de la Google Cloud consola y consulta los gráficos Estado de los trabajos individuales y Tiempo de los hilos por paso. Estos gráficos se encuentran en el panel de estado de la canalización.
Investigación de ejemplo:
Tienes una canalización por lotes periódica que se ejecuta cada hora a los 3 minutos de cada hora. Cada tarea suele ejecutarse durante unos 9 minutos. Tienes el objetivo de completar todos los trabajos en menos de 10 minutos.
El gráfico de estado de la tarea muestra que una tarea se ha ejecutado durante más de 10 minutos.
En la tabla de historial Actualización/Ejecución, busca el trabajo que se haya ejecutado durante la hora que te interese. Haz clic para ir a la página de detalles del trabajo de Dataflow. En esa página, busca la fase que se esté ejecutando durante más tiempo y, a continuación, consulta los registros para ver si hay errores que puedan ser la causa del retraso.
Flujos de procesamiento en streaming
Para hacer un análisis inicial del estado de su flujo de procesamiento, vaya a la página Detalles del flujo de procesamiento y, en la pestaña Información del flujo de procesamiento, consulte el gráfico de actualización de datos. Este gráfico se encuentra en el panel de estado de la canalización.
Investigación de ejemplo:
Tienes una canalización de streaming que normalmente genera un resultado con una actualidad de los datos de 20 segundos.
Te has fijado el objetivo de tener una garantía de actualización de datos de 30 segundos. Al revisar el gráfico de actualización de datos, observas que, entre las 9:00 y las 10:00, la actualización de datos ha aumentado hasta casi 40 segundos.
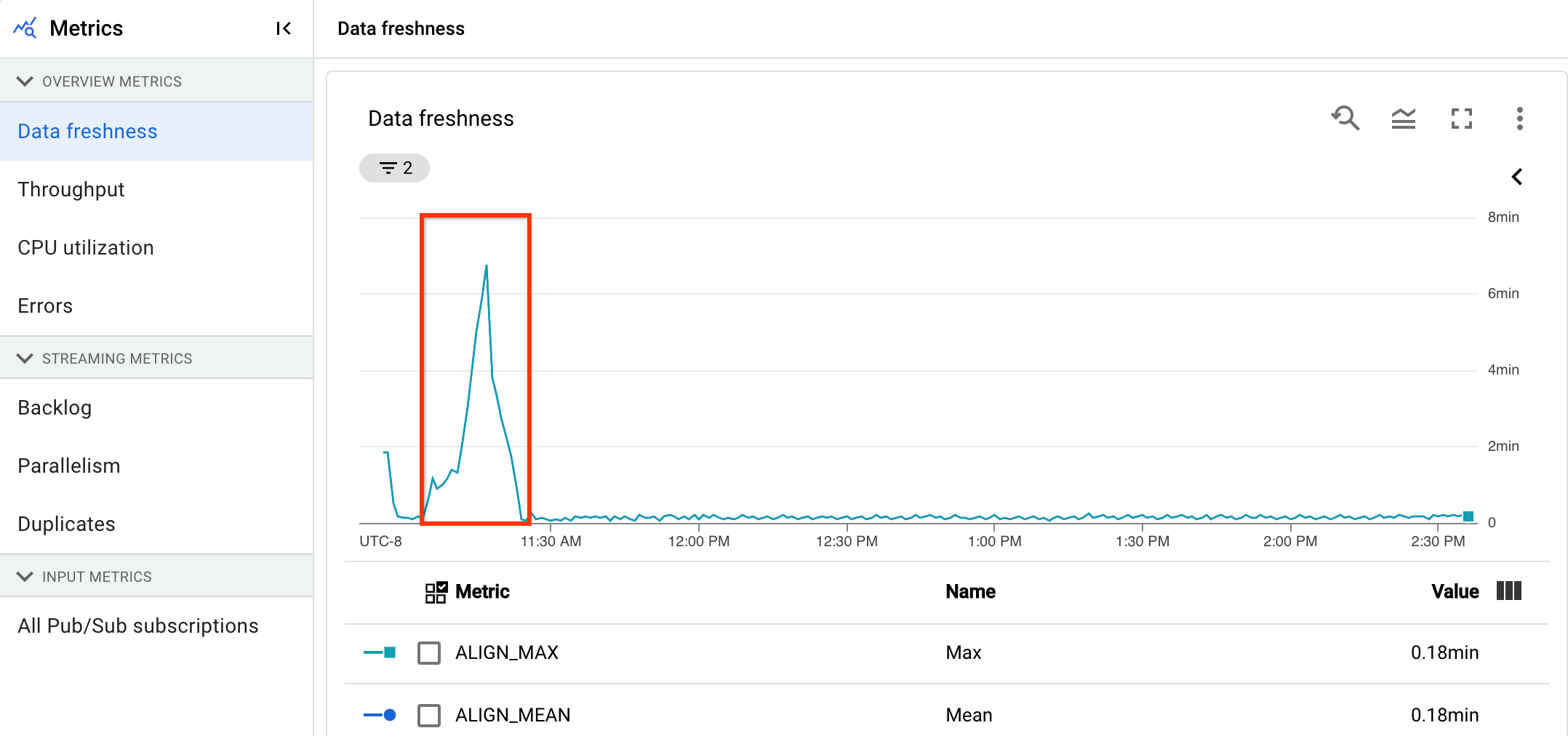
Cambia a la pestaña Métricas de la canalización y consulta los gráficos de uso de CPU y de memoria para obtener más información.
Error: El ID de la canalización ya existe en el proyecto
Si intentas crear una nueva canalización con un nombre que ya existe en tu proyecto, recibirás este mensaje de error: Pipeline Id already exist within the
project. Para evitar este problema, elige siempre nombres únicos para tus canalizaciones.