Si vous rencontrez des problèmes avec votre pipeline ou votre tâche Dataflow, cette page liste les messages d'erreur susceptibles de s'afficher et fournit des suggestions pour y remédier.
Les erreurs dans les types de journaux dataflow.googleapis.com/worker-startup, dataflow.googleapis.com/harness-startup et dataflow.googleapis.com/kubelet indiquent des problèmes de configuration d'une tâche. Elles peuvent également indiquer des conditions empêchant le bon fonctionnement du chemin d'accès de journalisation normal.
Votre pipeline peut générer des exceptions lors du traitement des données. Certaines de ces erreurs sont temporaires, par exemple lorsque vous rencontrez des difficultés pour accéder à un service externe. Certaines de ces erreurs sont permanentes, par exemple les erreurs causées par des données d'entrée corrompues ou impossibles à analyser, ou par des pointeurs vides lors du calcul.
Dataflow traite les éléments sous forme d'ensembles arbitraires et relance l'ensemble complet lorsqu'une erreur est générée pour l'un des éléments qu'il contient. Lors de l'exécution en mode de traitement par lots, les ensembles comprenant un élément défaillant sont relancés quatre fois. Le pipeline échoue complètement lorsqu'un ensemble échoue quatre fois. Lors de l'exécution en mode de traitement en flux continu, un ensemble comprenant un élément défaillant est relancé indéfiniment, ce qui risque de bloquer votre pipeline de manière permanente.
Les exceptions détectées dans le code utilisateur (par exemple, dans vos instances DoFn) sont signalées dans l'interface de surveillance de Dataflow.
Si vous exécutez votre pipeline avec BlockingDataflowPipelineRunner, des messages d'erreur s'affichent également dans la console ou la fenêtre de terminal.
Envisagez d'ajouter des gestionnaires d'exceptions pour éviter toute erreur dans votre code. Par exemple, si vous souhaitez supprimer des éléments qui font échouer une validation d'entrée personnalisée effectuée dans une transformation ParDo, utilisez un bloc "try" ou "catch" dans ParDo pour gérer les exceptions, la journaliser et supprimer l'élément. Pour les charges de travail de production, mettez en œuvre un modèle de message non traité. Pour suivre le nombre d'erreurs, vous devez utiliser des transformations d'agrégation.
Fichiers journaux manquants
Si vous ne voyez aucun journal pour vos tâches, supprimez les filtres d'exclusion contenant resource.type="dataflow_step" de tous les récepteurs du Routeur de journaux de Cloud Logging.
Accéder au Routeur de journaux
Pour en savoir plus sur la suppression de vos exclusions de journaux, consultez le guide Supprimer des exclusions.
Doublons dans la sortie
Lorsque vous exécutez un job Dataflow, la sortie contient des enregistrements en double.
Ce problème peut se produire lorsque votre job Dataflow utilise le mode de traitement en flux continu du pipeline "au moins une fois". Ce mode garantit que les enregistrements sont traités au moins une fois. Toutefois, des doublons peuvent exister dans ce mode.
Si votre workflow ne peut pas tolérer les enregistrements en double, utilisez le mode de traitement en flux continu "exactement une fois". Ce mode permet de s'assurer que les enregistrements ne sont pas supprimés ni dupliqués lorsque les données transitent dans le pipeline.
Pour vérifier le mode de traitement en flux continu utilisé par votre job, consultez la page Afficher le mode de traitement en flux continu d'un job.
Pour en savoir plus sur les modes de traitement en flux continu, consultez la section Définir le mode de traitement en flux continu du pipeline.
Erreurs de pipeline
Les sections suivantes contiennent les erreurs de pipeline courantes que vous pouvez rencontrer et les étapes à suivre pour les résoudre.
Certaines API Cloud doivent être activées
Lorsque vous essayez d'exécuter une tâche Dataflow, l'erreur suivante se produit :
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
Ce problème survient, car certaines API requises ne sont pas activées dans votre projet.
Pour résoudre ce problème et exécuter une tâche Dataflow, activez les APIGoogle Cloud suivantes dans votre projet :
- API Compute Engine (Compute Engine)
- API Cloud Logging
- Cloud Storage
- API Cloud Storage JSON
- API BigQuery
- Pub/Sub
- API Datastore
Pour obtenir des instructions détaillées, consultez le guide de démarrage sur l'activation des API Google Cloud .
"@*" et "@N" sont des spécifications de segmentation réservées.
Lorsque vous essayez d'exécuter une tâche, l'erreur suivante apparaît dans les fichiers journaux et la tâche échoue :
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
Cette erreur se produit si le nom de votre chemin d'accès Cloud Storage dans les fichiers temporaires (tempLocation ou temp_location) est précédé d'un signe (@) suivi d'un numéro ou d'un astérisque (*).
Pour résoudre ce problème, modifiez le nom du fichier afin que le signe "@" soit suivi d'un caractère compatible.
Requête erronée
Lorsque vous exécutez une tâche Dataflow, les journaux Cloud Monitoring affichent une série d'avertissements semblables à ce qui suit :
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
Des avertissements de requête incorrecte se produisent si les informations sur l'état du nœud de calcul sont obsolètes ou désynchronisées en raison de retards de traitement. La tâche Dataflow aboutit la plupart du temps, en dépit des avertissements de requête incorrecte. Si tel est le cas, ignorez les avertissements.
Impossible de lire et d'écrire dans des emplacements différents
L'erreur suivante peut apparaître dans les fichiers journaux lorsque vous exécutez une tâche Dataflow :
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
Cette erreur se produit lorsque la source et la destination se trouvent dans des régions différentes. Elle peut également se produire lorsque l'emplacement de préproduction et la destination se trouvent dans des régions différentes. Par exemple, si la tâche lit les données à partir de Pub/Sub, puis les écrit dans un bucket temp Cloud Storage avant d'écrire dans une table BigQuery, le bucket temp Cloud Storage et la table BigQuery doivent se trouver dans la même région.
Les emplacements multirégionaux sont considérés comme différents des emplacements régionaux, même si la région de l'emplacement régional relève de l'emplacement multirégional.
Par exemple, us (multiple regions in the United States) et us-central1 sont des régions différentes.
Pour résoudre ce problème, placez vos emplacements de destination, sources et de préproduction dans la même région. Les emplacements des buckets Cloud Storage ne peuvent pas être modifiés. Par conséquent, vous devrez peut-être créer un bucket Cloud Storage dans la région appropriée.
Connexion expirée
L'erreur suivante peut apparaître dans les fichiers journaux lorsque vous exécutez une tâche Dataflow :
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
Ce problème survient lorsque les nœuds de calcul Dataflow ne parviennent pas à établir ou maintenir une connexion avec la source de données ou la destination.
Pour résoudre le problème, suivez les étapes de dépannage ci-dessous :
- Vérifiez que la source de données est en cours d'exécution.
- Vérifiez que la destination est en cours d'exécution.
- Examinez les paramètres de connexion utilisés dans la configuration du pipeline Dataflow.
- Vérifiez que les problèmes de performances n'affectent pas la source ou la destination.
- Assurez-vous que les règles de pare-feu ne bloquent pas la connexion.
Cet objet n'existe pas
Lorsque vous exécutez des tâches Dataflow, l'erreur suivante peut s'afficher dans les fichiers journaux :
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
Ces erreurs se produisent généralement lorsque certaines de vos jobs Dataflow en cours d'exécution utilisent le même temp_location pour préparer les fichiers de jobs temporaires créés lors de l'exécution du pipeline. Lorsque plusieurs tâches simultanées partagent le même temp_location, ces tâches peuvent se trouver sur les données temporaires les unes des autres, et une condition de concurrence peut se produire. Pour éviter ce problème, il est recommandé d'utiliser un temp_location unique pour chaque tâche.
Dataflow ne parvient pas à déterminer le nombre de tâches en attente
Lors de l'exécution d'un pipeline de traitement en flux continu à partir de Pub/Sub, l'avertissement suivant se produit :
Dataflow is unable to determine the backlog for Pub/Sub subscription
Lorsqu'un pipeline Dataflow extrait des données de Pub/Sub, il doit demander à plusieurs reprises des informations à Pub/Sub. Ces informations incluent le volume de messages en attente dans l'abonnement et l'âge du plus ancien message non confirmé. Parfois, Dataflow ne peut pas récupérer ces informations à partir de Pub/Sub en raison de problèmes système internes pouvant entraîner une accumulation temporaire de tâches en attente.
Pour en savoir plus, consultez la page Diffuser des données avec Cloud Pub/Sub.
DEADLINE_EXCEEDED ou absence de réponse serveur
Lorsque vous exécutez vos tâches, vous pouvez rencontrer des exceptions de dépassement de délai RPC ou l'une des erreurs suivantes :
DEADLINE_EXCEEDED
ou
Server Unresponsive
Ces erreurs se produisent généralement pour l'une des raisons suivantes :
Il manque peut-être une règle de pare-feu dans le réseau privé virtuel (VPC, Virtual Private Cloud) utilisé pour votre tâche. Cette règle de pare-feu doit autoriser tout le trafic TCP entre les VM du réseau VPC que vous avez spécifié dans les options de pipeline. Pour en savoir plus, consultez la section Règles de pare-feu pour Dataflow.
Dans certains cas, les nœuds de calcul ne peuvent pas communiquer entre eux. Lorsque vous exécutez un job Dataflow qui n'utilise pas Dataflow Shuffle ou Streaming Engine, les nœuds de calcul doivent communiquer entre eux à l'aide des ports TCP
12345et12346au sein du réseau VPC. Dans ce scénario, l'erreur inclut le nom du faisceau de nœud de calcul et le port TCP bloqué. L'erreur ressemble à l'un des exemples suivants :DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)Pour résoudre ce problème, utilisez l'option de règles
gcloud compute firewall-rules createpour autoriser le trafic réseau vers les ports12345et12346. L'exemple suivant présente la commande Google Cloud CLI :gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346Remplacez les éléments suivants :
FIREWALL_RULE_NAME: nom de votre règle de pare-feu.NETWORK: nom de votre réseau.
Votre tâche est limitée en capacités de brassage.
Pour résoudre ce problème, effectuez une ou plusieurs des modifications suivantes.
Java
- Si la tâche n'utilise pas le brassage basé sur les services, passez à la fonctionnalité Dataflow Shuffle basée sur les services en définissant
--experiments=shuffle_mode=service. Pour plus d'informations, consultez la page Dataflow Shuffle. - Ajoutez des nœuds de calcul. Essayez d'exécuter votre pipeline en spécifiant une valeur plus élevée pour le paramètre
--numWorkers. - Augmentez la taille des disques associés aux nœuds de calcul. Essayez d'exécuter votre pipeline en spécifiant une valeur plus élevée pour le paramètre
--diskSizeGb. - Utilisez un disque persistant SSD. Essayez d'exécuter votre pipeline en spécifiant une valeur pour le paramètre
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd".
Python
- Si la tâche n'utilise pas le brassage basé sur les services, passez à la fonctionnalité Dataflow Shuffle basée sur les services en définissant
--experiments=shuffle_mode=service. Pour plus d'informations, consultez la page Dataflow Shuffle. - Ajoutez des nœuds de calcul. Essayez d'exécuter votre pipeline en spécifiant une valeur plus élevée pour le paramètre
--num_workers. - Augmentez la taille des disques associés aux nœuds de calcul. Essayez d'exécuter votre pipeline en spécifiant une valeur plus élevée pour le paramètre
--disk_size_gb. - Utilisez un disque persistant SSD. Essayez d'exécuter votre pipeline en spécifiant une valeur pour le paramètre
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd".
Go
- Si la tâche n'utilise pas le brassage basé sur les services, passez à la fonctionnalité Dataflow Shuffle basée sur les services en définissant
--experiments=shuffle_mode=service. Pour plus d'informations, consultez la page Dataflow Shuffle. - Ajoutez des nœuds de calcul. Essayez d'exécuter votre pipeline en spécifiant une valeur plus élevée pour le paramètre
--num_workers. - Augmentez la taille des disques associés aux nœuds de calcul. Essayez d'exécuter votre pipeline en spécifiant une valeur plus élevée pour le paramètre
--disk_size_gb. - Utilisez un disque persistant SSD. Essayez d'exécuter votre pipeline en spécifiant une valeur pour le paramètre
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd".
- Si la tâche n'utilise pas le brassage basé sur les services, passez à la fonctionnalité Dataflow Shuffle basée sur les services en définissant
Erreurs d'encodage, exceptions "IOException" ou comportement inattendu dans le code utilisateur.
Les SDK Apache Beam et les nœuds de calcul Dataflow dépendent de composants tiers courants. Ces composants importent des dépendances supplémentaires. Les conflits de version peuvent entraîner un comportement inattendu au niveau du service. De plus, certaines bibliothèques ne sont pas rétrocompatibles. Vous devrez peut-être épingler les versions incluses dans le champ d'application pendant l'exécution. La page Dépendances des SDK et des nœuds de calcul contient la liste des dépendances et des versions requises associées.
Erreur lors de l'exécution de LookupEffectiveGuestPolicies
L'erreur suivante peut apparaître dans les fichiers journaux lorsque vous exécutez une tâche Dataflow :
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
Cette erreur se produit si OS Configuration Management est activé pour l'ensemble du projet.
Pour résoudre ce problème, désactivez les règles VM Manager qui s'appliquent à l'ensemble du projet. Si vous ne pouvez pas désactiver les règles VM Manager pour l'ensemble du projet, vous pouvez ignorer sans risque cette erreur et la filtrer pour l'effacer des outils de surveillance des journaux.
Une erreur fatale a été détectée par l'environnement d'exécution Java
L'erreur suivante se produit lors du démarrage du nœud de calcul :
A fatal error has been detected by the Java Runtime Environment
Cette erreur se produit si le pipeline utilise JNI (Java Native Interface) pour exécuter du code non Java, et que ce code ou les liaisons JNI contiennent une erreur.
Erreur de clé d'attribut googclient_deliveryattempt
Votre tâche Dataflow échoue avec l'une des erreurs suivantes :
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
ou
Invalid extensions name: googclient_deliveryattempt
Cette erreur se produit lorsque votre job Dataflow présente les caractéristiques suivantes :
- Le job Dataflow utilise Streaming Engine.
- Le pipeline dispose d'un récepteur Pub/Sub.
- Le pipeline utilise un abonnement pull.
- Le pipeline utilise l'une des API de service Pub/Sub pour publier des messages à la place du réceptacle d'E/S Pub/Sub intégré.
- Pub/Sub utilise la bibliothèque cliente Java ou C#.
- L'abonnement Pub/Sub possède une file d'attente de lettres mortes.
Cette erreur se produit car lorsque vous utilisez la bibliothèque cliente Pub/Sub Java ou C# et qu'un sujet de lettres mortes pour un abonnement est activé, les tentatives de distribution se trouvent dans googclient_deliveryattempt au lieu de l'attribut delivery_attempt. Pour en savoir plus, consultez la section Suivre les tentatives d'envoi de la page "Gérer les échecs de message".
Pour contourner ce problème, effectuez une ou plusieurs des modifications suivantes.
- Désactivez Streaming Engine.
- Utilisez le connecteur
PubSubIOApache Beam intégré au lieu de l'API de service Pub/Sub. - Utiliser un autre type d'abonnement Pub/Sub.
- Supprimez la file d'attente de lettres mortes.
- N'utilisez pas la bibliothèque cliente Java ou C# avec votre abonnement pull Pub/Sub. Pour connaître les autres options, consultez la section Exemples de code de la bibliothèque cliente.
- Dans le code de votre pipeline, lorsque les clés d'attribut commencent par
goog, effacez les attributs de message avant de publier les messages.
Une clé chaude ... a été détectée.
L'erreur suivante se produit :
A hot key HOT_KEY_NAME was detected in...
Ces erreurs se produisent si vos données contiennent une clé chaude. Une clé chaude est une clé contenant suffisamment d'éléments pour avoir un impact négatif sur les performances du pipeline. Ces clés limitent la capacité de Dataflow à traiter les éléments en parallèle, ce qui a pour effet d'augmenter le temps d'exécution.
Pour imprimer la clé lisible dans les journaux lorsqu'une clé chaude est détectée dans le pipeline, utilisez l'option de pipeline de clé chaude.
Pour résoudre ce problème, vérifiez que vos données sont réparties de manière uniforme. Si une clé comporte un nombre disproportionné de valeurs, appliquez les mesures suivantes :
- Saisissez de nouveau vos données. Appliquez une transformation
ParDopour générer de nouvelles paires clé/valeur. - Pour les jobs Java, utilisez la transformation
Combine.PerKey.withHotKeyFanout. - Pour les jobs Python, utilisez la transformation
CombinePerKey.with_hot_key_fanout. - Activez Dataflow Shuffle.
Pour afficher les clés d'hôte dans l'interface de surveillance Dataflow, consultez la page Résoudre les problèmes liés aux retardataires dans les jobs par lot.
Spécification de table non valide dans Data Catalog
Lorsque vous utilisez Dataflow SQL pour créer des tâches Dataflow SQL, votre tâche peut échouer avec l'erreur suivante dans les fichiers journaux :
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
Cette erreur se produit si le compte de service Dataflow n'a pas accès à l'API Data Catalog.
Pour résoudre ce problème, activez l'API Data Catalog dans le projet Google Cloudque vous utilisez pour composer et exécuter des requêtes.
Attribuez le rôle roles/datacatalog.viewer au compte de service Dataflow.
Le graphique de tâche est trop grand.
Votre tâche peut échouer avec l'erreur suivante :
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
Cette erreur se produit si la taille de graphique de votre job dépasse 10 Mo. Certaines conditions existantes dans votre pipeline peuvent entraîner un dépassement de la limite de la part du graphique. Les facteurs de dépassement les plus courants sont les suivants :
- Une transformation
Createincluant une grande quantité de données en mémoire. - Une instance
DoFnvolumineuse sérialisée pour transmission aux nœuds de calcul distants - Une fonction
DoFndéfinie comme une instance d'une classe interne anonyme, et qui intègre (peut-être par inadvertance) une grande quantité de données à sérialiser - Le graphe orienté acyclique (DAG) est utilisé dans le cadre d'une boucle automatisée énumérant une longue liste.
Pour éviter ces situations, envisagez de restructurer votre pipeline.
Commit de clé trop volumineux
Lors de l'exécution d'une tâche de traitement en flux continu, l'erreur suivante apparaît dans les fichiers journaux des nœuds de calcul :
KeyCommitTooLargeException
Cette erreur se produit dans les scénarios de traitement en flux continu si une très grande quantité de données est regroupée sans utiliser de transformation Combine ou si une grande quantité de données est générée à partir d'un seul élément d'entrée.
Pour réduire le risque de rencontrer cette erreur, utilisez les stratégies suivantes :
- Assurez-vous que le traitement d'un seul élément ne peut pas entraîner des sorties ou des modifications d'état dépassant les limites.
- Si plusieurs éléments ont été regroupés suivant une clé, envisagez d'augmenter l'espace de clé pour réduire les éléments regroupés par clé.
- Si les éléments associés à une clé sont émis à une fréquence élevée sur une courte période, cela peut générer de nombreux Go d'événements pour cette clé dans les fenêtres. Réécrivez le pipeline afin de détecter les clés de ce type et émettez une sortie indiquant uniquement que la clé figurait fréquemment dans cette fenêtre.
- Utilisez des transformations d'espace sous-linéaires
Combinepour les opérations commutatives et associatives. N'utilisez pas de combinaison si elle ne réduit pas l'espace. Par exemple, utiliser une combinaison pour ajouter des chaînes est pire que de ne pas utiliser de combinaison.
Rejet des messages de plus de 7 168 Ko
Lorsque vous exécutez un job Dataflow créé à partir d'un modèle, le job peut échouer et renvoyer l'erreur suivante :
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
Cette erreur se produit lorsque les messages écrits dans une file d'attente de lettres mortes dépassent la limite de taille de 7 168 Ko. Pour contourner ce problème, activez Streaming Engine, qui offre une limite de taille plus élevée. Pour activer Streaming Engine, utilisez l'option de pipeline suivante.
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
Request Entity Too Large (Entité de requête trop grande)
Lorsque vous envoyez la tâche, l'une des erreurs suivantes apparaît dans la console ou la fenêtre de terminal :
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
Si vous rencontrez une erreur liée à la charge utile JSON au moment de l'envoi de votre job, la représentation JSON de votre pipeline dépasse la taille de requête maximale fixée à 20 Mo.
La taille de votre job est liée à la représentation JSON du pipeline. Plus celui-ci est grand, plus la taille de la requête sera importante. Dataflow limite actuellement la taille des requêtes à 20 Mo.
Pour estimer la taille de la requête JSON de votre pipeline, exécutez-le avec l'option suivante :
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
La génération de votre tâche au format JSON n'est pas disponible dans Go.
Cette commande écrit une représentation JSON de votre tâche dans un fichier. La taille du fichier sérialisé fournit une bonne approximation de la taille de la requête. La taille réelle est légèrement supérieure du fait de l'inclusion d'informations supplémentaires dans la requête.
Certaines caractéristiques de votre pipeline peuvent amener la représentation JSON à dépasser la limite. Les facteurs de dépassement les plus courants sont les suivants :
- Une transformation
Createincluant une grande quantité de données en mémoire. - Une instance
DoFnvolumineuse sérialisée pour transmission aux nœuds de calcul distants - Une fonction
DoFndéfinie comme une instance d'une classe interne anonyme, et qui intègre (peut-être par inadvertance) une grande quantité de données à sérialiser
Pour éviter ces situations, envisagez de restructurer votre pipeline.
Les options de pipeline du SDK ou la liste des fichiers de préproduction dépassent la taille maximale
Lors de l'exécution d'un pipeline, l'une des erreurs suivantes se produit :
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
ou
Value for field 'resource.properties.metadata' is too large: maximum size
Ces erreurs se produisent si le pipeline n'a pas pu être démarré en raison du dépassement des limites de métadonnées de Compute Engine. Les limites ne peuvent pas être modifiées. Dataflow utilise les métadonnées Compute Engine pour les options de pipeline. Cette limite est documentée dans les limites des métadonnées personnalisées Compute Engine.
Les scénarios suivants peuvent amener la représentation JSON à dépasser la limite :
- Il y a trop de fichiers JAR à préparer.
- Le champ de requête
sdkPipelineOptionsest trop grand.
Pour estimer la taille de la requête JSON de votre pipeline, exécutez-le avec l'option suivante :
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
La génération de votre tâche au format JSON n'est pas disponible dans Go.
La taille du fichier de sortie de cette commande doit être inférieure à 256 Ko. Les 512 Ko dans le message d'erreur font référence à la taille totale du fichier de sortie et aux options de métadonnées personnalisées pour l'instance de VM Compute Engine.
Vous pouvez obtenir une estimation approximative de l'option de métadonnées personnalisées pour l'instance de VM lorsque vous exécutez des tâches Dataflow dans le projet. Choisissez n'importe quel job Dataflow en cours d'exécution. Prenez une instance de VM, puis accédez à la page des détails de l'instance de VM Compute Engine pour cette VM afin de vérifier la section des métadonnées personnalisées. La longueur totale des métadonnées personnalisées et du fichier doit être inférieure à 512 Ko. Il n'est pas possible de fournir une estimation précise pour la tâche ayant échoué, car les VM ne sont pas démarrées pour les tâches ayant échoué.
Si votre liste JAR atteint la limite de 256 Ko, vérifiez-la et éliminez les fichiers JAR inutiles. Si la taille est encore trop grande, essayez d'exécuter le job Dataflow en utilisant un fichier Uber JAR. Pour obtenir un exemple illustrant la création et l'utilisation d'un fichier Uber JAR, consultez la section Créer et déployer un fichier Uber JAR.
Si le champ de requête sdkPipelineOptions est trop grand, incluez l'option suivante lorsque vous exécutez votre pipeline. L'option de pipeline est la même pour Java, Python et Go.
--experiments=no_display_data_on_gce_metadata
Clé de brassage trop volumineuse
L'erreur suivante apparaît dans les fichiers journaux des nœuds de calcul :
Shuffle key too large
Cette erreur se produit si la clé sérialisée attribuée à une valeur (Co-)GroupByKey particulière est trop volumineuse après l'application du codeur correspondant. Dataflow possède une limite pour les clés de brassage sérialisées.
Pour résoudre ce problème, réduisez la taille des clés ou utilisez des codeurs plus économes en espace.
Pour en savoir plus, consultez la section Limites de production pour Dataflow.
Le nombre total d'objets BoundedSource ... dépasse la limite autorisée
L'une des erreurs suivantes peut se produire lors de l'exécution de tâches avec Java :
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
ou
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
Cette erreur peut se produire si vous lisez des données à partir d'un très grand nombre de fichiers à l'aide de TextIO, AvroIO, BigQueryIO via EXPORT ou une autre source basée sur des fichiers. La limite exacte dépend des détails de votre source, mais elle est de l'ordre de plusieurs dizaines de milliers de fichiers par pipeline. Par exemple, l'intégration de schémas dans AvroIO.Read limite le nombre de fichiers autorisés.
Cette erreur peut également se produire si vous avez créé une source de données personnalisée pour votre pipeline et que la méthode splitIntoBundles de votre source a renvoyé une liste d'objets BoundedSource qui occupe plus de 20 Mo une fois sérialisée.
La limite autorisée pour la taille totale des objets BoundedSource générés par l'opération splitIntoBundles() de votre source personnalisée est de 20 Mo.
Pour contourner cette limitation, effectuez l'une des modifications suivantes :
Activez l'exécuteur V2. L'exécuteur v2 convertit les sources en DoFns divisibles qui ne possèdent pas cette limite de division de source.
Modifiez votre sous-classe
BoundedSourcepersonnalisée de telle sorte que la taille totale des objetsBoundedSourcegénérés soit inférieure à cette limite de 20 Mo. Par exemple, votre source pourrait générer un nombre réduit de divisions initiales et s'appuyer sur le rééquilibrage dynamique du travail pour fractionner davantage les entrées à la demande.
La taille de la charge utile de la requête dépasse la limite : 20 971 520 octets
Lorsque vous exécutez un pipeline, la tâche peut échouer avec l'erreur suivante :
com.google.api.client.googleapis.json.GoogleJsonResponseException: 400 Bad Request
POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/workItems:reportStatus
{
"code": 400,
"errors": [
{
"domain": "global",
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"reason": "badRequest"
}
],
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"status": "INVALID_ARGUMENT"
}
Cette erreur peut se produire lorsqu'une tâche utilisant l'exécuteur Dataflow présente un graphique de tâche très volumineux. Un grand graphique de job peut générer un grand nombre de métriques qui doivent être renvoyées au service Dataflow. Si la taille de ces métriques dépasse la limite de 20 Mo pour les requêtes API, le job échoue.
Pour résoudre ce problème, migrez votre pipeline afin d'utiliser Dataflow Runner v2. Runner v2 utilise une méthode plus efficace pour générer des rapports sur les métriques et ne présente pas cette limite de 20 Mo.
NameError
Lorsque vous exécutez votre pipeline en utilisant le service Dataflow, l'erreur suivante se produit :
NameError
Cette erreur ne se produit pas lors de l'exécution en local, par exemple lorsque vous utilisez l'opérateur DirectRunner.
Cette erreur se produit si vos DoFn utilisent des valeurs de l'espace de noms global qui ne sont pas disponibles sur le nœud de calcul Dataflow.
Par défaut, les importations, les fonctions et les variables globales définies dans la session principale ne sont pas enregistrées lors de la sérialisation d'une tâche Dataflow.
Pour résoudre ce problème, utilisez l'une des méthodes suivantes. Si vos fonctions DoFn sont définies dans le fichier principal et qu'elles référencent les importations et fonctions de l'espace de noms global, définissez l'option de pipeline --save_main_session sur True. Cette modification permet de pickler l'espace de noms global et de le charger sur le nœud de calcul Dataflow.
Si vous possédez des objets ne pouvant pas être picklés dans votre espace de noms global, une erreur de pickling se produit. Si l'erreur concerne un module qui devrait être disponible dans la distribution Python, importez le module en local, à l'emplacement où il est utilisé.
Par exemple, au lieu du code suivant :
import re … def myfunc(): # use re module
utilisez les lignes ci-dessous :
def myfunc(): import re # use re module
Si vos fonctions DoFn couvrent plusieurs fichiers, utilisez une approche différente pour mettre en package votre workflow et gérer les dépendances.
L'objet est soumis à la règle de conservation du bucket
Lorsqu'un job Dataflow écrit dans un bucket Cloud Storage, le job échoue et renvoie l'erreur suivante :
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
L'erreur suivante peut également s'afficher :
Unable to rename "gs://BUCKET"
La première erreur se produit lorsque la conservation des objets est activée sur le bucket Cloud Storage dans lequel le job Dataflow écrit. Pour en savoir plus, consultez la page Activer et utiliser des configurations de conservation des objets.
Pour résoudre ce problème, utilisez l'une des solutions suivantes :
Écrivez dans un bucket Cloud Storage qui ne comporte pas de règle de conservation dans le dossier
temp.Supprimez la règle de conservation du bucket dans lequel le job écrit. Pour en savoir plus, consultez la page Définir la configuration de conservation d'un objet.
La deuxième erreur peut indiquer que la conservation des objets est activée sur le bucket Cloud Storage ou que le compte de service de nœud de calcul Dataflow n'est pas autorisé à écrire dans le bucket Cloud Storage.
Si la deuxième erreur s'affiche et que la conservation des objets est activée sur le bucket Cloud Storage, essayez les solutions de contournement décrites précédemment. Si la conservation des objets n'est pas activée sur le bucket Cloud Storage, vérifiez si le compte de service de nœud de calcul Dataflow dispose d'autorisations en écriture sur le bucket Cloud Storage. Pour en savoir plus, consultez la page Accéder aux buckets Cloud Storage.
Traitement bloqué ou opération en cours
Si Dataflow passe plus de temps à exécuter une opération DoFn que le temps spécifié dans TIME_INTERVAL sans retour, le message suivant est affiché.
Java
L'un des deux messages de journal suivants, en fonction de la version :
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
Ce comportement a deux causes possibles :
- Votre code
DoFnest lent, ou en attente d'une opération externe lente. - Votre code
DoFnpeut être bloqué ou anormalement lent pour terminer le traitement.
Pour déterminer quel est votre cas, développez l'entrée de journal Cloud Monitoring pour afficher une trace de la pile. Recherchez les messages indiquant que le code DoFn est bloqué ou rencontre des problèmes. Si aucun message n'est présent, le problème peut être la vitesse d'exécution du code DoFn. Envisagez d'utiliser Cloud Profiler ou un autre outil pour analyser les performances de votre code.
Si votre pipeline s'appuie sur la VM Java (avec Java ou Scala), vous pouvez examiner la cause de votre code bloqué. Effectuez un vidage de thread complet de la VM Java entière (pas seulement du thread bloqué) en procédant comme suit :
- Notez le nom du nœud de calcul à partir de l'entrée de journal.
- Dans la section Compute Engine de la console Google Cloud , recherchez l'instance Compute Engine avec le nom du nœud de calcul que vous avez noté.
- Utilisez SSH pour vous connecter à l'instance portant ce nom.
Exécutez la commande suivante :
curl http://localhost:8081/threadz
Opération en cours dans le bundle
Lorsque vous exécutez un pipeline qui lit des données à partir de JdbcIO, les lectures partitionnées à partir de JdbcIO sont lentes et le message suivant s'affiche dans les fichiers journaux des nœuds de calcul :
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
Pour résoudre ce problème, effectuez une ou plusieurs des modifications suivantes dans votre pipeline :
Utilisez des partitions pour augmenter le parallélisme des jobs. Lire avec plus de partitions plus petites pour une meilleure mise à l'échelle.
Vérifiez si la colonne de partitionnement est une colonne d'index ou une véritable colonne de partitionnement dans la source. Activez l'indexation et le partitionnement sur cette colonne dans la base de données source pour obtenir les meilleures performances.
Utilisez les paramètres
lowerBoundetupperBoundpour ignorer la recherche des limites.
Erreurs de quota Pub/Sub
Lorsque vous exécutez un pipeline de traitement en flux continu à partir de Pub/Sub, les erreurs suivantes se produisent :
429 (rateLimitExceeded)
ou
Request was throttled due to user QPS limit being reached
Ces erreurs se produisent si votre projet ne dispose pas d'un quota Pub/Sub suffisant.
Pour savoir si le quota de votre projet est insuffisant, procédez comme suit pour rechercher les erreurs client :
- Accédez à la consoleGoogle Cloud .
- Dans le menu de gauche, sélectionnez API et services.
- Dans le champ de recherche, recherchez Cloud Pub/Sub.
- Cliquez sur l'onglet Utilisation.
- Vérifiez les codes de réponse et recherchez les codes d'erreur client
(4xx).
La requête est interdite par une règle de l'organisation
Lors de l'exécution d'un pipeline, l'erreur suivante se produit :
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
Cette erreur se produit si le bucket Cloud Storage ne se trouve pas dans votre périmètre de service.
Pour résoudre ce problème, créez une règle de sortie autorisant l'accès au bucket en dehors du périmètre de service.
Le package intermédiaire ... est inaccessible
Les tâches qui aboutissaient par le passé peuvent échouer avec l'erreur suivante :
Staged package...is inaccessible
Pour remédier à ce problème, procédez comme suit :
- Vérifiez que le bucket Cloud Storage utilisé pour la préproduction ne présente pas de paramètres de la valeur TTL entraînant la suppression des packages en préproduction.
Vérifiez que le compte de service du nœud de calcul de votre projet Dataflow est autorisé à accéder au bucket Cloud Storage utilisé en préproduction. Les lacunes des autorisations peuvent être dues à l'une des raisons suivantes :
- Le bucket Cloud Storage utilisé en préproduction est présent dans un autre projet.
- Le bucket Cloud Storage utilisé en préproduction a été migré d'un accès ultraprécis à un accès uniforme au niveau du bucket. En raison de l'incohérence entre les stratégies IAM et LCA, la migration du bucket de préproduction vers un accès uniforme au niveau du bucket interdit les LCA pour les ressources Cloud Storage. Les LCA incluent les autorisations détenues par le compte de service du nœud de calcul de votre projet Dataflow sur le bucket de préproduction.
Pour en savoir plus, consultez Accéder aux buckets Cloud Storage dans les projets Google Cloud Platform.
Un élément de travail a échoué quatre fois
L'erreur suivante se produit en cas d'échec d'un job par lot :
The job failed because a work item has failed 4 times.
Cette erreur se produit si une même opération dans un job par lot entraîne l'échec du code de nœud de calcul à quatre reprises. Dataflow fait alors échouer la tâche et ce message s'affiche.
Lors de l'exécution en mode de traitement en flux continu, un ensemble comprenant un élément défaillant est relancé indéfiniment, ce qui risque de bloquer votre pipeline de manière permanente.
Vous ne pouvez pas configurer ce seuil d'échec. Pour plus de détails, reportez-vous à la section Traitement des erreurs et des exceptions de pipeline.
Pour résoudre ce problème, recherchez les quatre échecs un par un dans les journaux Cloud Monitoring du job. Dans les journaux des nœuds de calcul, recherchez les entrées de journal de niveau Erreur ou niveau Fatal qui affichent des exceptions ou des erreurs. L'exception ou l'erreur doit apparaître au moins quatre fois. Si les journaux ne contiennent que des erreurs d'expiration génériques liées à l'accès à des ressources externes, telles que MongoDB, vérifiez que le compte de service du nœud de calcul est autorisé à accéder au sous-réseau de la ressource.
Expiration du délai dans le fichier de résultats de l'interrogation
Pour en savoir plus sur la résolution de l'erreur "Délai d'attente dépassé dans le fichier de résultats de l'interrogation", consultez Résoudre les problèmes liés aux modèles Flex.
Échec de l'écriture de File/Write/WriteImpl/PreFinalize
Lorsque vous exécutez un job, il échoue de manière intermittente, et l'erreur suivante se produit :
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
Cette erreur se produit lorsque le même sous-dossier est utilisé comme emplacement de stockage temporaire pour plusieurs jobs qui s'exécutent simultanément.
Pour résoudre ce problème, n'utilisez pas le même sous-dossier comme emplacement de stockage temporaire pour plusieurs pipelines. Pour chaque pipeline, indiquez un sous-dossier unique à utiliser comme emplacement de stockage temporaire.
L'élément dépasse la taille maximale du message protobuf
Lorsque vous exécutez des jobs Dataflow et que votre pipeline contient de gros éléments, des erreurs semblables aux exemples suivants peuvent s'afficher :
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
ou
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
Un avertissement semblable à l'exemple suivant peut également s'afficher :
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
Ces erreurs se produisent lorsque votre pipeline contient des éléments volumineux.
Pour résoudre ce problème, si vous utilisez le SDK Python, passez à Apache Beam version 2.57.0 ou ultérieure. Les versions 2.57.0 et ultérieures du SDK Python améliorent le traitement des éléments volumineux et ajoutent des journaux pertinents.
Si les erreurs persistent après la mise à niveau ou si vous n'utilisez pas le SDK Python, identifiez l'étape du job où l'erreur se produit et essayez de réduire la taille des éléments de cette étape.
Lorsque les objets PCollection de votre pipeline contiennent des éléments volumineux, les besoins en RAM du pipeline augmentent.
Les éléments volumineux peuvent également entraîner des erreurs d'exécution, en particulier lorsqu'ils franchissent les limites des étapes fusionnées.
Des éléments volumineux peuvent survenir lorsqu'un pipeline matérialise par inadvertance un itérable volumineux. Par exemple, un pipeline qui transmet la sortie d'une opération GroupByKey dans une opération Reshuffle inutile matérialise les listes en tant qu'éléments uniques. Ces listes peuvent contenir un grand nombre de valeurs pour chaque clé.
Si l'erreur se produit à une étape qui utilise une entrée secondaire, sachez que l'utilisation d'entrées secondaires peut entraîner une barrière de fusion. Vérifiez si la transformation qui produit un élément volumineux et celle qui le consomme appartiennent à la même étape.
Lorsque vous créez votre pipeline, suivez ces bonnes pratiques :
- Dans
PCollections, utilisez plusieurs petits éléments au lieu d'un seul grand élément. - Stockez des blobs volumineux dans des systèmes de stockage externes. Utilisez
PCollectionspour transmettre leurs métadonnées ou un encodeur personnalisé qui réduit la taille de l'élément. - Si vous devez transmettre une PCollection pouvant dépasser 2 Go en tant qu'entrée secondaire, utilisez des vues itérables, telles que
AsIterableetAsMultiMap.
La taille maximale d'un seul élément dans un job Dataflow est limitée à 2 Go. Pour en savoir plus, consultez la page Quotas et limites.
Dataflow n'est pas en mesure de traiter la ou les transformations gérées...
Les pipelines qui utilisent Managed I/O peuvent échouer avec cette erreur si Dataflow ne peut pas mettre à niveau automatiquement les transformations d'E/S vers la dernière version compatible. L'URN et les noms d'étapes fournis dans l'erreur doivent indiquer les transformations exactes que Dataflow n'a pas réussi à mettre à niveau.
Vous trouverez peut-être des informations supplémentaires sur cette erreur dans l'explorateur de journaux, sous les noms de journaux Dataflow managed-transforms-worker et managed-transforms-worker-startup.
Si l'explorateur de journaux ne fournit pas suffisamment d'informations pour résoudre l'erreur, veuillez contacter Cloud Customer Care.
Erreurs de la tâche d'archivage
Les sections suivantes présentent des erreurs courantes que vous pouvez rencontrer lorsque vous essayez d'archiver une tâche Dataflow à l'aide de l'API.
Aucune valeur n'est fournie
Lorsque vous essayez d'archiver un job Dataflow à l'aide de l'API, l'erreur suivante peut se produire :
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
Cette erreur se produit pour l'une des raisons suivantes :
Le chemin spécifié pour le champ
updateMaskne suit pas le format approprié. Ce problème peut se produire en raison de fautes de frappe.L'élément
JobMetadatan'est pas correctement spécifié. Dans le champJobMetadata, pouruserDisplayProperties, utilisez la paire clé-valeur"archived":"true".
Pour résoudre cette erreur, vérifiez que la commande que vous transmettez à l'API correspond au format requis. Pour en savoir plus, consultez la section Archiver une tâche.
L'API ne reconnaît pas la valeur
Lorsque vous essayez d'archiver un job Dataflow à l'aide de l'API, l'erreur suivante peut se produire :
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
Cette erreur se produit lorsque la valeur fournie dans la paire clé/valeur des tâches d'archive n'est pas une valeur acceptée. Les valeurs acceptées pour la paire clé/valeur de tâches d'archive sont "archived":"true" et "archived":"false".
Pour résoudre cette erreur, vérifiez que la commande que vous transmettez à l'API correspond au format requis. Pour en savoir plus, consultez la section Archiver une tâche.
Impossible de mettre à jour l'état et le masque
Lorsque vous essayez d'archiver un job Dataflow à l'aide de l'API, l'erreur suivante peut se produire :
Cannot update both state and mask.
Cette erreur se produit lorsque vous essayez de mettre à jour l'état de la tâche et l'état de l'archive dans le même appel d'API. Vous ne pouvez pas mettre à jour l'état de la tâche et le paramètre de requête updateMask dans le même appel d'API.
Pour résoudre cette erreur, mettez à jour l'état de la tâche dans un appel d'API distinct. Mettez à jour l'état de la tâche avant de mettre à jour l'état d'archive de la tâche.
Échec de la modification du workflow
Lorsque vous essayez d'archiver un job Dataflow à l'aide de l'API, l'erreur suivante peut se produire :
Workflow modification failed.
Cette erreur se produit généralement lorsque vous essayez d'archiver une tâche en cours d'exécution.
Pour résoudre cette erreur, attendez la fin de la tâche avant de l'archiver. Les jobs terminés présentent l'un des états suivants :
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Pour plus d'informations, consultez la section Détecter l'achèvement d'une tâche Dataflow.
Erreurs liées aux images de conteneurs
Les sections suivantes présentent les erreurs courantes que vous pouvez rencontrer lors de l'utilisation de conteneurs personnalisés, ainsi que les étapes à suivre pour les marquer comme terminées ou bien les résoudre. Les erreurs sont généralement précédées du message suivant :
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
Autorisation "containeranalysis.occurrences.list" refusée
L'erreur suivante apparaît dans vos fichiers journaux :
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
L'API Container Analysis est requise pour l'analyse des failles.
Pour en savoir plus, consultez les pages Présentation de l'analyse de l'OS et Configurer le contrôle des accès dans la documentation Artifact Analysis.
Erreur lors de la synchronisation du pod ... Échec de "StartContainer"
L'erreur suivante se produit lors du démarrage du nœud de calcul :
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Un pod est un groupe de conteneurs Docker colocalisés qui s'exécutent sur un nœud de calcul Dataflow. Cette erreur se produit lorsqu'un des conteneurs Docker du pod ne parvient pas à démarrer. Si l'échec n'est pas récupérable, le nœud de calcul Dataflow ne parvient pas à démarrer, et les tâches par lot Dataflow finissent par échouer avec des erreurs telles que celle-ci :
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Cette erreur se produit généralement lorsqu'un des conteneurs plante en permanence au démarrage.
Pour en comprendre la cause, recherchez les journaux enregistrés immédiatement avant l'échec. Pour analyser les journaux, utilisez l'explorateur de journaux. Dans l'explorateur de journaux, limitez les fichiers journaux aux entrées de journal émises par le nœud de calcul présentant des erreurs de démarrage du conteneur. Pour limiter les entrées de journal, procédez comme suit :
- Dans l'explorateur de journaux, recherchez l'entrée de journal
Error syncing pod. - Pour afficher les étiquettes associées à l'entrée de journal, développez l'entrée de journal.
- Cliquez sur l'étiquette associée à la zone
resource_name, puis sur Afficher les entrées correspondantes.
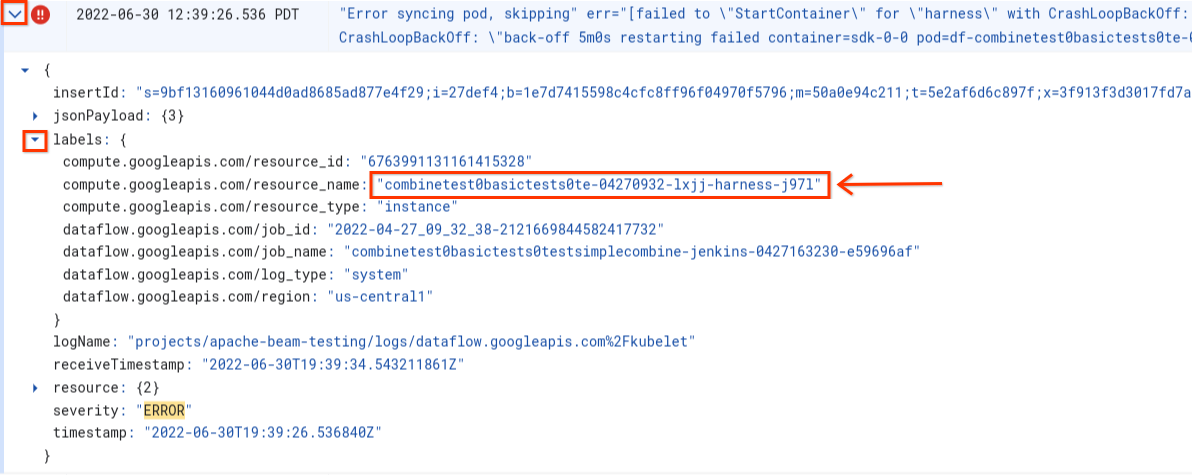
Dans l'explorateur de journaux, les journaux Dataflow sont organisés en plusieurs flux de journaux. Le message Error syncing pod est émis dans le journal nommé kubelet. Toutefois, les journaux du conteneur en échec peuvent se trouver dans un autre flux de journaux. Chaque conteneur possède un nom. Le tableau suivant vous permet de déterminer le flux de journaux susceptible de contenir des journaux pertinents pour le conteneur en échec.
| Nom du conteneur | Noms des journaux |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0 et autres | docker |
| harness | harness, harness-startup |
| python, java-batch, java-streaming | worker-startup, worker |
| artefact | artefact |
Lorsque vous interrogez l'explorateur de journaux, assurez-vous que la requête inclut les noms de journaux pertinents dans l'interface du générateur de requêtes ou qu'elle n'inclut pas de restrictions sur le nom du journal.
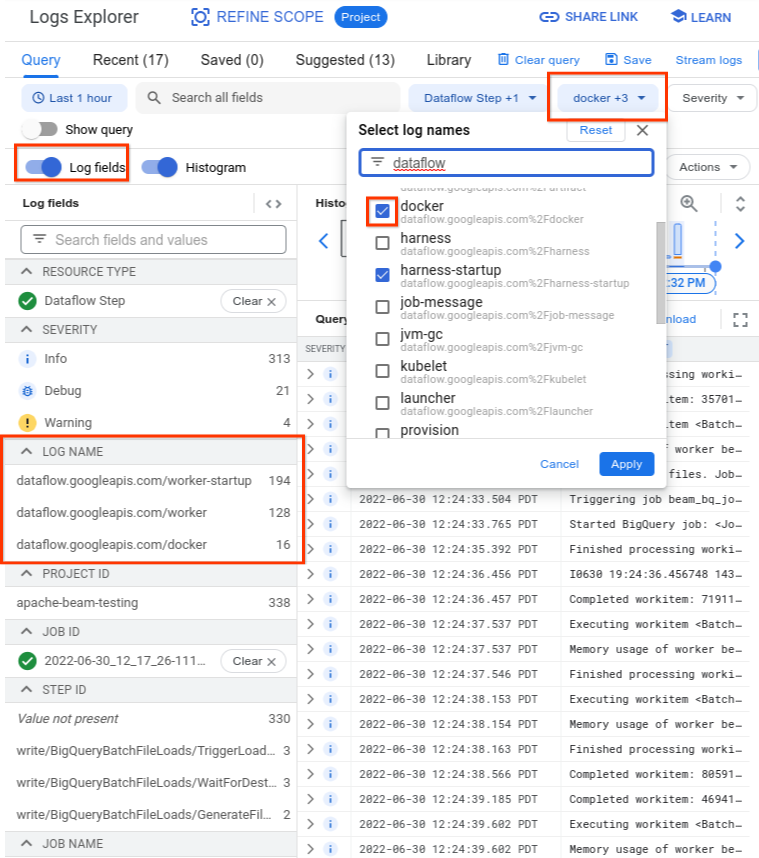
Une fois que vous avez sélectionné les journaux pertinents, le résultat de la requête peut ressembler à l'exemple suivant :
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
Comme les journaux indiquant les symptômes de l'échec du conteneur sont parfois signalés comme INFO, incluez les journaux INFO dans votre analyse.
Parmi les causes les plus courantes de défaillances de conteneurs, on trouve notamment les suivantes :
- Votre pipeline Python contient des dépendances supplémentaires installées au moment de l'exécution, et l'installation échoue. Vous pouvez rencontrer des erreurs telles que
pip install failed with error. Ce problème peut être dû à des conflits entre exigences ou à une configuration réseau restreinte qui empêche un nœud de calcul Dataflow d'extraire une dépendance externe d'un dépôt public sur Internet. Un nœud de calcul échoue durant l'exécution du pipeline en raison d'une erreur de mémoire saturée. Vous pouvez rencontrer une erreur semblable à celle-ci :
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
Pour déboguer un problème de mémoire insuffisante, consultez Résoudre les erreurs Dataflow de mémoire insuffisante.
Dataflow ne parvient pas à extraire l'image de conteneur. Pour en savoir plus, consultez la section Échec de la demande d'extraction d'image avec une erreur.
Le conteneur utilisé n'est pas compatible avec l'architecture du processeur de la VM de nœud de calcul. Dans les journaux de démarrage du faisceau, une erreur semblable à celle-ci peut s'afficher :
exec /opt/apache/beam/boot: exec format error. Pour vérifier l'architecture de l'image de conteneur, exécutezdocker image inspect $IMAGE:$TAGet recherchez le mot cléArchitecture. SiError: No such image: $IMAGE:$TAGest affiché, vous devrez peut-être d'abord extraire l'image en exécutant la commandedocker pull $IMAGE:$TAG. Pour en savoir plus sur la création d'images multi-architectures, consultez Créer une image de conteneur multi-architecture.
Après avoir identifié l'erreur à l'origine de l'échec du conteneur, essayez de la corriger, puis envoyez à nouveau le pipeline.
Échec de la demande d'extraction d'image avec une erreur
Lors du démarrage du nœud de calcul, l'une des erreurs suivantes s'affiche dans les journaux des nœuds de calcul ou des tâches :
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
Ces erreurs se produisent lorsqu'un nœud de calcul ne parvient pas à démarrer, car il ne peut pas extraire d'image de conteneur Docker. Ce problème se produit dans les scénarios suivants :
- L'URL de l'image du conteneur du SDK personnalisé est incorrecte
- Le nœud de calcul n'a pas d'identifiant ni d'accès réseau à l'image distante.
Pour remédier à ce problème :
- Si vous utilisez une image de conteneur personnalisée avec votre job, vérifiez que l'URL de votre image est correcte et qu'elle contient un tag ou un condensé valide. Les nœuds de calcul Dataflow doivent également avoir accès à l'image.
- Vérifiez que les images publiques peuvent être extraites localement en exécutant la commande
docker pull $imageà partir d'une machine non authentifiée.
Pour les images privées ou les nœuds de calcul privés :
- Si vous utilisez Container Registry pour héberger votre image de conteneur, nous vous recommandons plutôt d'utiliser Artifact Registry. Container Registry est obsolète depuis le 15 mai 2023. Si vous utilisez actuellement Container Registry, vous pouvez passer à Artifact Registry. Si vos images se trouvent dans un autre projet que celui utilisé pour exécuter votre job Google Cloud Platform, configurez le contrôle des accès pour le compte de service Google Cloud Platform par défaut.
- Si vous utilisez un cloud privé virtuel (VPC) partagé, assurez-vous que les nœuds de calcul peuvent accéder à l'hôte du dépôt de conteneurs personnalisés.
- Utilisez
sshpour vous connecter à une VM de nœud de calcul de job en cours d'exécution et exécutezdocker pull $imagepour vérifier directement que le nœud de calcul est correctement configuré.
Si les nœuds de calcul échouent plusieurs fois de suite en raison de cette erreur et qu'un travail a commencé sur un job, celui-ci peut échouer avec une erreur similaire au message suivant :
Job appears to be stuck.
Si vous supprimez l'accès à l'image pendant l'exécution du job, soit en supprimant l'image elle-même, soit en révoquant les identifiants du compte de service du nœud de calcul Dataflow ou l'accès Internet pour accéder aux images, Dataflow ne consigne que les erreurs. Dataflow ne fait pas échouer le job. Dataflow évite également de faire échouer les pipelines de streaming de longue durée afin d'éviter de perdre l'état des pipelines.
D'autres erreurs peuvent provenir de problèmes de quota de dépôt ou d'interruptions. Si vous rencontrez des problèmes de dépassement du quota Docker Hub pour l'extraction d'images publiques ou des pannes générales liées à un dépôt tiers, envisagez d'utiliser Artifact Registry en tant que service de dépôt d'images.
SystemError : opcode inconnu
Votre pipeline de conteneurs personnalisés Python peut échouer en renvoyant l'erreur suivante, immédiatement après l'envoi de votre tâche :
SystemError: unknown opcode
En outre, la trace de pile peut inclure les éléments suivants :
apache_beam/internal/pickler.py
Pour résoudre ce problème, vérifiez que la version Python que vous utilisez localement correspond à la version de l'image de conteneur jusqu'à la version majeure et mineure. Une différence au niveau de la version de correctif, telle que 3.6.7 et 3.6.8, ne crée pas de problèmes de compatibilité. Une différence de version mineure, telle que 3.6.8 et 3.8.2, peut entraîner des échecs du pipeline.
Erreurs de mise à niveau des pipelines de traitement en flux continu
Pour savoir comment résoudre les erreurs lors de la mise à niveau d'un pipeline de streaming à l'aide de fonctionnalités telles que l'exécution d'un job de remplacement parallèle, consultez Résoudre les problèmes de mise à niveau des pipelines de streaming.
Mise à jour du harnais de l'exécuteur v2
Le message d'information suivant s'affiche dans les journaux des jobs Runner v2 :
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
Cela signifie que la version du processus de harnais de l'exécuteur sera automatiquement mise à jour au bout de sept jours après l'envoi initial du message, ce qui entraînera une brève pause dans le traitement. Si vous souhaitez contrôler le moment où cette pause se produit, consultez Mettre à jour un pipeline existant pour démarrer un job de remplacement qui disposera de la version la plus récente du harnais de l'exécuteur.
Erreurs de nœud de calcul
Les sections suivantes contiennent les erreurs de nœud de calcul courantes que vous pouvez rencontrer et les étapes à suivre pour les résoudre.
Échec de l'appel du faisceau de nœud de calcul Java vers Python DoFn
Si un appel provenant du faisceau de nœud de calcul Java vers une classe DoFn Python échoue, un message d'erreur approprié s'affiche.
Pour examiner l'erreur, développez l'entrée du journal des erreurs Cloud Monitoring, et examinez le message d'erreur et la trace. Vous découvrirez ainsi quelle ligne de code a échoué afin de la corriger si nécessaire. Si vous pensez que l'erreur est un bug dans Apache Beam ou Dataflow, veuillez le signaler.
EOFError : données marshal trop courtes
L'erreur suivante s'affiche dans les journaux des nœuds de calcul :
EOFError: marshal data too short
Cette erreur se produit parfois lorsque les nœuds de calcul du pipeline Python manquent d'espace disque.
Pour résoudre ce problème, consultez Aucun espace restant sur le dispositif.
Échec de l'association du disque
Lorsque vous essayez de lancer un job Dataflow qui utilise des VM C3 avec Persistent Disk, le job échoue en renvoyant l'une des erreurs suivantes, ou les deux :
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
Ces erreurs se produisent lorsque vous utilisez des VM C3 avec un type de disque persistant non compatible. Pour plus d'informations, consultez la section Types de disques compatibles avec la famille C3.
Pour utiliser des VM C3 avec votre job Dataflow, choisissez le type de disque de calcul pd-ssd. Pour en savoir plus, consultez la section Options au niveau des nœuds de calcul.
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
Aucun espace restant sur le dispositif
Lorsqu'une tâche manque d'espace disque, l'erreur suivante peut apparaître dans les journaux des nœuds de calcul :
No space left on device
Cette erreur peut se produire pour l'une des raisons suivantes :
- L'espace de stockage persistant d'un nœud de calcul manque d'espace, ce qui peut être dû à l'une des raisons suivantes :
- Une tâche télécharge des dépendances importantes lors de l'exécution
- Une tâche utilise des conteneurs personnalisés volumineux
- Une tâche écrit de nombreuses données temporaires sur le disque local
- Lorsque vous utilisez Dataflow Shuffle, Dataflow définit une taille minimale de disque par défaut. En conséquence, cette erreur peut se produire lorsque des tâches sont transférées à partir d'un brassage basé sur les nœuds de calcul.
- Le disque de démarrage du nœud de calcul se remplit, car il enregistre plus de 50 entrées par seconde.
Pour résoudre ce problème, suivez les étapes de dépannage ci-dessous :
Pour afficher les ressources de disque associées à un seul nœud de calcul, recherchez les détails d'instance de VM pour les VM de nœud de calcul associées à votre tâche. Une partie de l'espace disque est consommée par le système d'exploitation, les fichiers binaires, les journaux et les conteneurs.
Pour augmenter l'espace sur le disque persistant ou le disque de démarrage, ajustez l'option de pipeline de taille de disque.
Suivez l'utilisation de l'espace disque sur les instances de VM de nœud de calcul à l'aide de Cloud Monitoring. Consultez la section Recevoir les métriques de VM de nœuds de calcul via l'agent Monitoring pour obtenir des instructions de configuration.
Recherchez les problèmes d'espace disque de démarrage en affichant les données de sortie du port série sur les instances de VM de nœud de calcul, et en recherchant des messages tels que les suivants :
Failed to open system journal: No space left on device
Si vous disposez d'un grand nombre d'instances de VM de nœud de calcul, vous pouvez créer un script pour exécuter gcloud compute instances get-serial-port-output sur toutes ces instances simultanément.
Vous pouvez alors examiner ce résultat à la place.
Le pipeline Python échoue après une heure d'inactivité du nœud de calcul
Lorsque vous utilisez le SDK Apache Beam pour Python avec l'exécuteur Dataflow V2 sur des machines de calcul avec de nombreux cœurs de processeur, utilisez le SDK Apache Beam 2.35.0 ou version ultérieure. Si votre tâche utilise un conteneur personnalisé, utilisez le SDK Apache Beam 2.46.0 ou version ultérieure.
Envisagez de précompiler votre conteneur Python. Cette étape peut améliorer les temps de démarrage des VM et les performances d'autoscaling horizontal. Pour utiliser cette fonctionnalité, activez l'API Cloud Build sur votre projet et envoyez le pipeline avec le paramètre suivant :
‑‑prebuild_sdk_container_engine=cloud_build.
Pour en savoir plus, consultez la page Exécuteur Dataflow V2.
Vous pouvez également utiliser une image de conteneur personnalisée avec toutes les dépendances préinstallées.
RESOURCE_POOL_EXHAUSTED
Lorsque vous créez une ressource Google Cloud Platform, l'erreur suivante se produit :
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
Cette erreur se produit pour les conditions de rupture temporaire d'une ressource spécifique dans une zone spécifique.
Pour résoudre le problème, vous pouvez attendre ou créer la même ressource dans une autre zone.
Pour contourner ce problème, implémentez une boucle de réessai pour vos jobs. Ainsi, lorsqu'une erreur de rupture de stock se produit, le job effectue automatiquement une nouvelle tentative jusqu'à ce que des ressources soient disponibles. Pour créer une boucle de nouvelle tentative, implémentez le workflow suivant :
- Créez une tâche Dataflow et obtenez son ID.
- Interrogez l'état du job jusqu'à ce qu'il soit
RUNNINGouFAILED.- Si l'état du job est
RUNNING, quittez la boucle de nouvelle tentative. - Si l'état du job est
FAILED, utilisez l'API Cloud Logging pour interroger les journaux du job et rechercher la chaîneZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS. Pour en savoir plus, consultez Utiliser les journaux de pipeline.- Si les journaux ne contiennent pas la chaîne, quittez la boucle de nouvelle tentative.
- Si les journaux contiennent la chaîne, créez un job Dataflow, obtenez l'ID du job et redémarrez la boucle de réessai.
- Si l'état du job est
Une bonne pratique consiste à répartir vos ressources sur plusieurs zones et régions afin de permettre la tolérance aux interruptions.
Les instances avec des accélérateurs invités ne sont pas compatibles avec la migration à chaud.
Un pipeline Dataflow échoue lors de l'envoi du job et renvoie l'erreur suivante :
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
Cette erreur peut se produire lorsque vous avez demandé un type de machine de nœud de calcul doté d'accélérateurs matériels, mais que vous n'avez pas configuré Dataflow pour utiliser des accélérateurs.
Utilisez l'option de service --worker_accelerator Dataflow ou l'indication de ressource accelerator pour demander des accélérateurs matériels.
Si vous utilisez des modèles Flex, vous pouvez utiliser l'option --additionalExperiments pour fournir des options de service Dataflow. Si vous avez correctement suivi les étapes, l'option worker_accelerator se trouve dans le panneau d'informations sur le job de la consoleGoogle Cloud .
Quota du projet … ou règles de contrôle des accès empêchant l'opération
L'erreur suivante se produit :
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
Cette erreur se produit pour l'une des raisons suivantes :
- Vous avez peut-être dépassé l'un des quotas Compute Engine dont dépend la création de nœuds de calcul Dataflow.
- Votre organisation a mis en place des contraintes qui interdisent certains aspects du processus de création d'instances de VM, telles que le compte utilisé ou la zone ciblée.
Pour résoudre ce problème, suivez les étapes de dépannage ci-dessous :
Consultez le journal des instances de VM.
- Accédez à la visionneuse Cloud Logging.
- Dans la liste déroulante Ressource auditée, sélectionnez Instance de VM.
- Dans la liste déroulante Tous les journaux, sélectionnez compute.googleapis.com/activity_log.
- Recherchez dans le journal les entrées éventuelles liées à l'échec de la création d'une instance de VM.
Vérifiez votre utilisation des quotas Compute Engine.
Pour afficher l'utilisation des ressources Compute Engine par rapport aux quotas Dataflow pour la zone que vous ciblez, exécutez la commande suivante :
gcloud compute regions describe [REGION]Examinez les résultats des ressources suivantes pour voir si certaines dépassent le quota :
- CPUS
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
Si nécessaire, demandez une modification du quota.
Examinez les contraintes liées aux règles d'administration.
- Accéder à la page Règles d'administration
- Passez en revue les contraintes pour tout élément pouvant limiter la création d'instances de VM pour le compte que vous utilisez (par défaut, le compte de service Dataflow) ou dans la zone que vous ciblez.
- Si vous disposez d'une règle qui limite l'utilisation d'adresses IP externes, désactivez les adresses IP externes pour cette tâche. Pour en savoir plus sur la désactivation des adresses IP externes, consultez la page Configurer l'accès à Internet et les règles de pare-feu.
Délai d'attente dépassé lors de la mise à jour du nœud de calcul
Lorsqu'une tâche Dataflow échoue, l'erreur suivante se produit :
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Plusieurs causes peuvent entraîner cette erreur, y compris les suivantes :
- Surcharge des nœuds de calcul
- Maintien du verrouillage global de l'interpréteur
- Configuration de DoFn de longue durée
Surcharge des nœuds de calcul
Une erreur de délai avant expiration se produit parfois lorsque le nœud de calcul manque de mémoire ou d'espace d'échange. Pour résoudre ce problème, essayez d'exécuter à nouveau le job. Si la tâche échoue toujours et que la même erreur se produit, essayez d'utiliser un nœud de calcul disposant de plus de mémoire et d'espace disque. Par exemple, ajoutez l'option de démarrage de pipeline suivante :
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
La modification du type de nœud de calcul peut avoir une incidence sur les coûts facturés. Pour en savoir plus, consultez la section Résoudre les erreurs Dataflow de mémoire insuffisante.
Cette erreur peut également se produire lorsque vos données contiennent une clé chaude. Dans ce scénario, l'utilisation du processeur est élevée sur certains nœuds de calcul pendant la plupart de la durée du job. Toutefois, le nombre de nœuds de calcul n'atteint pas le maximum autorisé. Pour en savoir plus sur les clés d'hôte et les solutions possibles, consultez la page Écrire des pipelines Dataflow en tenant compte de l'évolutivité.
Pour découvrir d'autres solutions à ce problème, consultez la section Une clé chaude ... a été détectée.
Python : verrouillage global de l'interpréteur (GIL)
Si votre code Python appelle du code C/C++ à l'aide du mécanisme d'extension Python, vérifiez si le code de l'extension libère le verrou d'interpréteur global de Python (Global Interpreter Lock ou GIL) dans les parties de code qui utilisent beaucoup de ressources de calcul qui n'accèdent pas à l'état Python. Si le GIL n'est pas libéré pendant une période prolongée, des messages d'erreur tels que Unable to retrieve status info from SDK harness <...> within allowed time et SDK worker appears to be permanently unresponsive. Aborting the SDK peuvent s'afficher.
Les bibliothèques facilitant les interactions avec des extensions telles que Cython et PyBind disposent de primitives pour contrôler l'état du GIL. Vous pouvez également libérer manuellement le GIL et le récupérer avant de renvoyer le contrôle à l'interpréteur Python à l'aide des macros Py_BEGIN_ALLOW_THREADS et Py_END_ALLOW_THREADS.
Pour en savoir plus, consultez la page État du thread et verrou de l'interpréteur global dans la documentation Python.
Il peut être possible de récupérer les traces de pile d'un thread qui détient le GIL sur un nœud de calcul Dataflow en cours d'exécution comme suit :
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
Dans les pipelines Python, dans la configuration par défaut, Dataflow part du principe que chaque processus Python exécuté sur les nœuds de calcul utilise efficacement un cœur de processeur virtuel. Si le code du pipeline contourne les limites du GIL, par exemple en utilisant des bibliothèques mises en œuvre en C++, les éléments de traitement peuvent utiliser des ressources provenant de plusieurs cœurs de processeur virtuel, et il est possible que les nœuds de calcul ne disposent pas de ressources de processeur suffisantes. Pour contourner ce problème, réduisez le nombre de threads sur les nœuds de calcul.
Configuration de DoFn de longue durée
Si vous n'utilisez pas Runner v2, un appel de longue durée à DoFn.Setup peut entraîner l'erreur suivante :
Timed out waiting for an update from the worker
En général, évitez les opérations longues dans DoFn.Setup.
Erreurs temporaires lors de la publication dans un sujet
Lorsque votre job par flux utilise le mode de traitement en flux continu "au moins une fois" et qu'il est publié sur un récepteur Pub/Sub, l'erreur suivante apparaît dans les journaux du job :
There were transient errors publishing to topic
Si votre job s'exécute correctement, cette erreur est bénigne et vous pouvez l'ignorer. Dataflow relance automatiquement l'envoi des messages Pub/Sub avec un délai d'intervalle entre les tentatives.
Impossible de récupérer les données en raison d'une incompatibilité de jeton pour la clé
L'erreur suivante signifie que l'élément de travail en cours de traitement a été réattribué à un autre nœud de calcul :
Unable to fetch data due to token mismatch for key
Cela se produit le plus souvent lors de l'autoscaling, mais peut arriver à tout moment. Toute tâche concernée sera relancée. Vous pouvez ignorer cette erreur.
Problèmes de dépendance Java
Les classes et les bibliothèques incompatibles peuvent entraîner des problèmes de dépendance Java. Lorsque votre pipeline rencontre des problèmes de dépendance Java, l'une des erreurs suivantes peut se produire :
NoClassDefFoundError: cette erreur se produit lorsqu'une classe entière n'est pas disponible pendant l'exécution. Cela peut être dû à des problèmes de configuration généraux ou à des incompatibilités entre la version protobuf de Beam et les protos générés d'un client (par exemple, ce problème).NoSuchMethodError: cette erreur se produit lorsque la classe dans le chemin de classe utilise une version qui ne contient pas la bonne méthode ou lorsque la signature de la méthode a été modifiée.NoSuchFieldError: cette erreur se produit lorsque la classe dans le chemin de classe utilise une version qui ne comporte pas un champ requis pendant l'exécution.FATAL ERROR in native method: cette erreur se produit lorsqu'une dépendance intégrée ne peut pas être chargée correctement. Lorsque vous utilisez un fichier Uber JAR (ombré), n'incluez pas de bibliothèques utilisant des signatures (comme Conscrypt) dans le même fichier JAR.
Si votre pipeline contient du code et des paramètres spécifiques à l'utilisateur, le code ne peut pas contenir de versions mixtes des bibliothèques. Si vous utilisez une bibliothèque de gestion des dépendances, nous vous recommandons d'utiliser la BOM des bibliothèques Google Cloud Platform.
Si vous utilisez le SDK Apache Beam, utilisez beam-sdks-java-io-google-cloud-platform-bom pour importer la BOM des bibliothèques appropriées :
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
Pour en savoir plus, consultez Gérer les dépendances de pipeline dans Dataflow.
InaccessibleObjectException dans JDK 17 et versions ultérieures
Lorsque vous exécutez des pipelines avec la version 17 ou ultérieure du kit de développement Java (JDK), l'erreur suivante peut apparaître dans les fichiers journaux des nœuds de calcul :
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
Ce problème survient, car à partir de la version 9 de Java, des options de machine virtuelle Java (JVM) de module ouvert sont nécessaires pour accéder aux composants internes du JDK. Dans Java 16 et versions ultérieures, les options JVM de modules ouverts sont toujours obligatoires pour accéder aux composants internes du JDK.
Pour résoudre ce problème, lorsque vous transmettez des modules à votre pipeline Dataflow à ouvrir, utilisez le format MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* avec l'option de pipeline jdkAddOpenModules. Ce format permet d'accéder à la bibliothèque nécessaire.
Par exemple, si l'erreur est module java.base does not "opens java.lang" to unnamed module @..., incluez l'option de pipeline suivante lorsque vous exécutez votre pipeline :
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
Pour en savoir plus, consultez la documentation sur les classes DataflowPipelineOptions.
Progression des éléments de travail de création de rapports d'erreurs
Pour les pipelines Java, si vous n'utilisez pas Runner v2, l'erreur suivante peut s'afficher :
Error reporting workitem progress update to Dataflow service: ...
Cette erreur est due à une exception non gérée lors de la mise à jour de la progression d'un élément de travail, par exemple lors de la division d'une source. Dans la plupart des cas, si le code utilisateur Apache Beam génère une exception non gérée, l'élément de travail échoue, ce qui entraîne l'échec du pipeline.Toutefois, les exceptions dans Source.split sont supprimées, car cette partie du code se trouve en dehors d'un élément de travail. Par conséquent, seul un journal des erreurs est enregistré.
Cette erreur est généralement inoffensive si elle ne se produit que de manière intermittente. Toutefois, pensez à gérer les exceptions de manière élégante dans votre code Source.split.
Erreurs du connecteur BigQuery
Les sections suivantes contiennent les erreurs courantes du connecteur BigQuery que vous pouvez rencontrer et les étapes à suivre pour les résoudre.
quotaExceeded
Lorsque vous utilisez le connecteur BigQuery pour écrire dans BigQuery à l'aide d'insertions en flux continu, le débit d'écriture est inférieur à celui attendu, et l'erreur suivante peut se produire :
quotaExceeded
Le débit peut être ralenti lorsque votre pipeline dépasse le quota d'insertion en flux continu BigQuery disponible. Dans ce cas, les messages d'erreur liés au quota BigQuery s'affichent dans les journaux des nœuds de calcul Dataflow (recherchez les erreurs quotaExceeded).
Si des erreurs quotaExceeded s'affichent, pour résoudre ce problème :
- Lorsque vous utilisez le SDK Apache Beam pour Java, définissez l'option de récepteur BigQuery
ignoreInsertIds(). - Lorsque vous utilisez le SDK Apache Beam pour Python, utilisez l'option
ignore_insert_ids.
Ces paramètres vous permettent de bénéficier d'un débit d'insertion en flux continu de 1 Go/s dans BigQuery. Pour en savoir plus sur les mises en garde liées à la déduplication automatique des messages, consultez la documentation BigQuery. Pour augmenter le quota d'insertion en flux continu BigQuery au-delà de 1 Gbit/s, envoyez une demande via la console Google Cloud .
Si les erreurs liées aux quotas ne s'affichent pas dans les journaux des nœuds de calcul, le problème peut être dû au fait que le regroupement par défaut ou les paramètres liés au traitement par lots ne fournissent pas le parallélisme approprié pour votre pipeline. Vous pouvez ajuster plusieurs configurations liées au connecteur BigQuery pour Dataflow afin d'obtenir les performances attendues lorsque vous écrivez des données dans BigQuery par le biais d'insertions en flux continu. Par exemple, pour le SDK Apache Beam pour Java, ajustez numStreamingKeys afin que sa valeur corresponde au nombre maximal de nœuds de calcul. Envisagez également d'augmenter la valeur de insertBundleParallelism afin de configurer le connecteur BigQuery de sorte qu'il utilise davantage de threads parallèles pour l'écriture dans BigQuery.
Pour connaître les configurations disponibles dans le SDK Apache Beam pour Java, consultez la page BigQueryPipelineOptions. Pour connaître les configurations disponibles dans le SDK Apache Beam pour Python, consultez la page sur la transformation WriteToBigQuery.
rateLimitExceeded
Lorsque vous utilisez le connecteur BigQuery, l'erreur suivante se produit :
rateLimitExceeded
Cette erreur se produit si BigQuery envoie trop de requêtes API pendant une courte période. BigQuery applique des limites de quota à court terme.
Il est possible que votre pipeline Dataflow dépasse temporairement ce quota. Dans un tel scénario, les requêtes API de votre pipeline Dataflow vers BigQuery peuvent échouer, ce qui peut entraîner l'apparition d'erreurs rateLimitExceeded dans les journaux des nœuds de calcul.
Dataflow effectue de nouvelles tentatives en cas de défaillance. Vous pouvez donc ignorer ces erreurs. Si vous pensez que votre pipeline est affecté par des erreurs rateLimitExceeded, prenez contact avec Cloud Customer Care.
Erreurs diverses
Les sections suivantes contiennent diverses erreurs que vous pouvez rencontrer et les étapes à suivre pour les résoudre.
Impossible d'allouer sha384
Votre job s'exécute correctement, mais l'erreur suivante apparaît dans ses journaux :
ima: Can not allocate sha384 (reason: -2)
Si votre job s'exécute correctement, cette erreur est bénigne et vous pouvez l'ignorer. Les images de base de VM de nœud de calcul génèrent parfois ce message. Dataflow répond automatiquement au problème sous-jacent et le résout.
Une demande de fonctionnalité existe pour faire passer le niveau de ce message de WARN à INFO. Pour en savoir plus, consultez Réduire le niveau de journalisation des erreurs de lancement du système Dataflow sur "WARN" ou "INFO".
Erreur lors de l'initialisation du vérificateur dynamique plug-in
Votre job s'exécute correctement, mais l'erreur suivante apparaît dans ses journaux :
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
Si votre job s'exécute correctement, cette erreur est bénigne et vous pouvez l'ignorer. Cette erreur se produit lorsque le job Dataflow tente de créer un répertoire sans les autorisations d'écriture nécessaires, et que la tâche échoue. Si votre job réussit, soit le répertoire n'était pas nécessaire, soit Dataflow a traité le problème sous-jacent.
Une demande de fonctionnalité existe pour faire passer le niveau de ce message de WARN à INFO. Pour en savoir plus, consultez Réduire le niveau de journalisation des erreurs de lancement du système Dataflow sur "WARN" ou "INFO".
Cet objet n'existe pas : pipeline.pb
Lorsque vous répertoriez des tâches à l'aide de l'option JOB_VIEW_ALL, l'erreur suivante se produit :
No such object: BUCKET_NAME/PATH/pipeline.pb
Cette erreur peut se produire si vous supprimez le fichier pipeline.pb des fichiers de préproduction pour la tâche.
Ignorer la synchronisation des pods
Votre job s'exécute correctement, mais l'une des erreurs suivantes s'affiche dans ses journaux :
Skipping pod synchronization" err="container runtime status check may not have completed yet"
ou
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
Si votre job s'exécute correctement, ces erreurs sont bénignes et vous pouvez les ignorer.
Le message container runtime status check may not have completed yet s'affiche lorsque le kubelet de Kubernetes ignore la synchronisation des pods, car il attend l'initialisation de l'environnement d'exécution du conteneur. Ce scénario se produit pour diverses raisons, par exemple lorsque l'environnement d'exécution du conteneur a récemment démarré ou redémarre.
Lorsque le message inclut PLEG is not healthy: pleg has yet to be successful, le kubelet attend que le générateur d'événements de cycle de vie des pods (PLEG) devienne opérationnel avant de synchroniser les pods. Le PLEG est chargé de générer des événements utilisés par le kubelet pour suivre l'état des pods.
Une demande de fonctionnalité existe pour faire passer le niveau de ce message de WARN à INFO. Pour en savoir plus, consultez Réduire le niveau de journalisation des erreurs de lancement du système Dataflow sur "WARN" ou "INFO".
Recommandations
Pour obtenir des conseils sur les recommandations générées par les insights Dataflow, consultez la page Insights.