이 페이지에서는 Dataflow 파이프라인 또는 작업에 문제가 발생하는 경우 표시될 수 있는 오류 메시지를 나열하고 각 오류를 해결하는 방법을 제공합니다.
dataflow.googleapis.com/worker-startup, dataflow.googleapis.com/harness-startup, dataflow.googleapis.com/kubelet 로그 유형의 오류는 작업에 구성 문제가 있음을 나타냅니다. 또한 일반 로깅 경로가 작동하지 못하게 하는 조건을 나타낼 수도 있습니다.
데이터를 처리하는 동안 파이프라인에서 예외가 발생할 수 있습니다. 이러한 오류 중 일부는 일시적(예: 외부 서비스 액세스 시의 일시적인 어려움 발생)이지만 일부는 영구적(예: 계산 중 null 포인터 또는 손상되거나 파싱할 수 없는 입력 데이터로 인한 오류)입니다.
Dataflow는 임의 번들에서 요소를 처리하며 해당 번들의 요소에 오류가 발생하면 전체 번들을 재시도합니다. 일괄 모드에서 실행하면 실패 항목이 포함된 번들은 4번 재시도됩니다. 단일 번들이 4번 실패하면 파이프라인이 완전히 실패합니다. 스트리밍 모드에서 실행하는 경우 실패 항목이 포함된 번들은 무제한으로 재시도되므로 파이프라인이 영구 중단될 수 있습니다.
사용자 코드(예: DoFn 인스턴스)의 예외는 Dataflow 모니터링 인터페이스에 보고됩니다.
BlockingDataflowPipelineRunner로 파이프라인을 실행하는 경우 콘솔이나 터미널 창에 오류 메시지가 나타날 수 있습니다.
예외 핸들러를 추가하여 코드에서의 오류를 방지할 수 있습니다. 예를 들어 ParDo에서 수행된 일부 커스텀 입력 유효성 검사에 실패한 요소를 삭제하려면 ParDo 내에서 try/catch 블록을 사용하여 예외를 처리하고 요소를 로깅하고 삭제합니다. 프로덕션 워크로드의 경우 처리되지 않은 메시지 패턴을 구현합니다. 오류 수를 추적하려면 집계 변환을 사용합니다.
로그 파일 누락
작업에 대한 로그가 표시되지 않으면 모든 Cloud Logging 로그 라우터 싱크에서 resource.type="dataflow_step"을 포함한 모든 제외 필터를 삭제합니다.
로그 제외 삭제에 대한 자세한 내용은 제외 삭제 가이드를 참조하세요.
출력의 중복
Dataflow 작업을 실행하면 출력에 중복 레코드가 포함됩니다.
이 문제는 Dataflow 작업에서 최소 한 번 파이프라인 스트리밍 모드를 사용하면 발생할 수 있습니다. 이 모드는 레코드가 최소 한 번 이상 처리되도록 보장합니다. 그러나 이 모드에서는 중복 레코드가 가능합니다.
워크플로에서 중복 레코드를 허용할 수 없으면 '단 한 번' 스트리밍 모드를 사용합니다. 이 모드는 데이터가 파이프라인을 통해 이동할 때 레코드가 삭제되거나 중복되지 않도록 보장합니다.
작업에서 사용 중인 스트리밍 모드를 확인하려면 작업의 스트리밍 모드 보기를 참조하세요.
스트리밍 모드에 대한 자세한 내용은 파이프라인 스트리밍 모드 설정을 참조하세요.
파이프라인 오류
다음 섹션에서는 발생할 수 있는 일반적인 파이프라인 오류와 오류 해결 단계를 설명합니다.
일부 Cloud API를 사용 설정해야 함
Dataflow 작업을 실행하려고 하면 다음 오류가 발생합니다.
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
이 문제는 프로젝트에 일부 필수 API가 사용 설정되지 않았기 때문에 발생합니다.
이 문제를 해결하고 Dataflow 작업을 실행하려면 프로젝트에서 다음Google Cloud API를 사용 설정합니다.
- Compute Engine API(Compute Engine)
- Cloud Logging API
- Cloud Storage
- Cloud Storage JSON API
- BigQuery API
- Pub/Sub
- Datastore API
자세한 안내는 Google Cloud API 사용 설정 시작하기 섹션을 참조하세요.
'@*' 및 '@N'은 예약된 샤딩 사양임
작업을 실행하려고 하면 로그 파일에 다음 오류가 표시되고 작업이 실패합니다.
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
이 오류는 임시 파일(tempLocation 또는 temp_location)의 Cloud Storage 경로 파일 이름에 @ 기호 다음에 숫자 또는 별표(*)가 오는 경우에 발생합니다.
이 문제를 해결하려면 @ 기호 다음에 지원되는 문자가 오도록 파일 이름을 변경하세요.
잘못된 요청
Dataflow 작업을 실행하면 Cloud Monitoring 로그에 다음과 비슷한 일련의 경고가 표시됩니다.
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
처리 지연으로 인해 작업자 상태 정보가 오래되었거나 동기화되지 않는 경우 잘못된 요청 경고가 발생합니다. 잘못된 요청 경고에도 불구하고 Dataflow 작업이 성공하는 경우가 많습니다. 이러한 경우 경고를 무시하세요.
다른 위치에서 읽고 쓸 수 없음
Dataflow 작업을 실행할 때는 로그 파일에 다음 오류가 표시될 수 있습니다.
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
이 오류는 소스와 대상이 다른 리전에 있을 때 발생합니다. 스테이징 위치와 대상이 다른 리전에 있는 경우에도 발생할 수 있습니다. 예를 들어 작업이 Pub/Sub에서 읽은 후 BigQuery 테이블에 쓰기 전에 Cloud Storage temp 버킷에 쓰는 경우 Cloud Storage temp 버킷과 BigQuery 테이블은 같은 리전에 있어야 합니다.
단일 리전이 멀티 리전 위치 범위 내에 있더라도 멀티 리전 위치는 단일 리전 위치와 다른 위치로 간주됩니다.
예를 들어 us (multiple regions in the United States) 및 us-central1은 서로 다른 리전입니다.
이 문제를 해결하려면 대상, 소스, 스테이징 위치를 같은 리전에 둡니다. Cloud Storage 버킷 위치를 변경할 수 없으므로 올바른 리전에 새 Cloud Storage 버킷을 만들어야 할 수도 있습니다.
연결 시간 초과
Dataflow 작업을 실행할 때는 로그 파일에 다음 오류가 표시될 수 있습니다.
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
이 문제는 Dataflow 작업자가 데이터 소스나 대상과의 연결을 설정하거나 유지할 수 없는 경우에 발생합니다.
이 문제를 해결하려면 다음 문제 해결 단계를 따르세요.
- 데이터 소스가 실행 중인지 확인합니다.
- 대상이 실행 중인지 확인합니다.
- Dataflow 파이프라인 구성에 사용된 연결 파라미터를 검토합니다.
- 성능 문제가 소스나 대상에 영향을 주지 않는지 확인합니다.
- 방화벽 규칙에서 연결을 차단하고 있지 않은지 확인합니다.
해당 객체 없음
Dataflow 작업을 실행할 때 로그 파일에 다음과 같은 오류가 표시될 수 있습니다.
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
이러한 오류는 일반적으로 실행 중인 일부 Dataflow 작업에서 같은 temp_location을 사용하여 파이프라인 실행 시에 생성된 임시 작업 파일을 스테이징할 때 발생합니다. 동시 작업 여러 개에서 같은 temp_location을 공유하면 이러한 작업은 서로의 임시 데이터를 기반으로 하므로 경합 상태가 발생할 수 있습니다. 이 문제를 방지하려면 작업마다 고유한 temp_location을 사용하는 것이 좋습니다.
Dataflow에서 백로그를 확인할 수 없음
Pub/Sub에서 스트리밍 파이프라인을 실행할 때 다음 경고가 발생합니다.
Dataflow is unable to determine the backlog for Pub/Sub subscription
Dataflow 파이프라인이 Pub/Sub에서 데이터를 가져올 때 Dataflow는 Pub/Sub에서 정보를 반복적으로 요청해야 합니다. 이 정보에는 구독의 백로그 양과 확인되지 않은 가장 오래된 메시지의 기간이 포함됩니다. 경우에 따라 내부 시스템 문제로 인해 Dataflow가 Pub/Sub에서 이 정보를 검색할 수 없습니다. 이 경우 일시적으로 백로그가 누적될 수 있습니다.
자세한 내용은 Cloud Pub/Sub로 스트리밍을 참조하세요.
DEADLINE_EXCEEDED 또는 서버 응답 없음
작업을 실행하면 RPC 제한 시간 예외나 다음 오류 중 하나가 발생할 수 있습니다.
DEADLINE_EXCEEDED
또는
Server Unresponsive
이러한 오류는 일반적으로 다음 이유 중 하나로 인해 발생합니다.
작업에 사용된 Virtual Private Cloud(VPC) 네트워크에 방화벽 규칙이 없을 수 있습니다. 방화벽 규칙은 파이프라인 옵션에서 사용자가 지정한 VPC 네트워크의 VM 사이에서 모든 TCP 트래픽을 사용 설정해야 합니다. 자세한 내용은 Dataflow의 방화벽 규칙을 참조하세요.
작업자가 서로 통신할 수 없는 경우가 있습니다. Dataflow Shuffle 또는 Streaming Engine을 사용하지 않는 Dataflow 작업을 실행할 때 작업자는 VPC 네트워크 내에서 TCP 포트
12345및12346를 사용하여 서로 통신해야 합니다. 이 시나리오의 오류에는 작업자 하네스 이름과 차단된 TCP 포트가 포함됩니다. 이 오류는 다음 예시 중 하나와 유사합니다.DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)이 문제를 해결하려면
gcloud compute firewall-rules create규칙 플래그를 사용하여 포트12345및12346에 대한 네트워크 트래픽을 허용하세요. 다음 예시에서는 Google Cloud CLI 명령어를 보여줍니다.gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346다음을 바꿉니다.
FIREWALL_RULE_NAME: 방화벽 규칙 이름NETWORK: 네트워크의 이름
작업이 셔플 바운딩되었습니다.
이 문제를 해결하려면 다음 변경사항 중 하나 이상을 수행하세요.
자바
- 작업이 서비스 기반 셔플을 사용 중이 아니면
--experiments=shuffle_mode=service를 설정하여 서비스 기반 Dataflow Shuffle 사용으로 전환합니다. 자세한 내용과 사용 가능 여부는 Dataflow Shuffle을 참조하세요. - 작업자를 추가합니다. 파이프라인 실행 시 더 높은 값으로
--numWorkers를 설정해 보세요. - 작업자에 연결된 디스크 크기를 늘립니다. 파이프라인 실행 시 더 높은 값으로
--diskSizeGb를 설정해 보세요. - SSD 지원 영구 디스크를 사용합니다. 파이프라인 실행 시
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"를 설정해 보세요.
Python
- 작업이 서비스 기반 셔플을 사용 중이 아니면
--experiments=shuffle_mode=service를 설정하여 서비스 기반 Dataflow Shuffle 사용으로 전환합니다. 자세한 내용과 사용 가능 여부는 Dataflow Shuffle을 참조하세요. - 작업자를 추가합니다. 파이프라인 실행 시 더 높은 값으로
--num_workers를 설정해 보세요. - 작업자에 연결된 디스크 크기를 늘립니다. 파이프라인 실행 시 더 높은 값으로
--disk_size_gb를 설정해 보세요. - SSD 지원 영구 디스크를 사용합니다. 파이프라인 실행 시
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"를 설정해 보세요.
Go
- 작업이 서비스 기반 셔플을 사용 중이 아니면
--experiments=shuffle_mode=service를 설정하여 서비스 기반 Dataflow Shuffle 사용으로 전환합니다. 자세한 내용과 사용 가능 여부는 Dataflow Shuffle을 참조하세요. - 작업자를 추가합니다. 파이프라인 실행 시 더 높은 값으로
--num_workers를 설정해 보세요. - 작업자에 연결된 디스크 크기를 늘립니다. 파이프라인 실행 시 더 높은 값으로
--disk_size_gb를 설정해 보세요. - SSD 지원 영구 디스크를 사용합니다. 파이프라인 실행 시
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"를 설정해 보세요.
- 작업이 서비스 기반 셔플을 사용 중이 아니면
빈 분할이 반환됨
Dataflow 작업을 실행할 때 작업자 로그에 다음 메시지가 표시될 수 있습니다.
Continuing to process work-id WORK_ID without splitting. Reader split status was: INTERNAL: Empty split returned and SDK split status was: ...
작업이 올바르게 실행된다면 이 메시지는 무해하므로 무시해도 됩니다. 서비스가 이미 완료된 작업을 분할하려고 시도하는 경합 상태로 인해 이런 메시지가 표시될 수 있습니다.
인코딩 오류, IOExceptions 또는 사용자 코드의 예상치 못한 동작
Apache Beam SDK와 Dataflow 작업자는 일반적인 타사 구성요소에 의존합니다. 이러한 구성요소는 추가적인 종속 항목을 가져옵니다. 버전이 충돌하면 서비스에서 예기치 않은 동작이 발생할 수 있습니다. 또한 일부 라이브러리는 이후 버전과 호환되지 않습니다. 실행하는 시점을 기준으로 범위 내에 있는 것으로 표시되는 버전을 사용해야 할 수도 있습니다. SDK 및 작업자 종속 항목에는 종속 항목 목록과 필요한 버전이 포함되어 있습니다.
LookupEffectiveGuestPolicies 실행 오류
Dataflow 작업을 실행할 때는 로그 파일에 다음 오류가 표시될 수 있습니다.
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
이 오류는 OS 설정 관리가 전체 프로젝트에 사용 설정된 경우에 발생합니다.
이 문제를 해결하려면 전체 프로젝트에 적용되는 VM Manager 정책을 중지합니다. 전체 프로젝트에서 VM Manager 정책을 중지할 수 없으면 이 오류를 무시하고 로그 모니터링 도구에서 필터링하면 됩니다.
Java 런타임 환경에서 치명적인 오류가 감지됨
작업자 시작 중에 다음 오류가 발생합니다.
A fatal error has been detected by the Java Runtime Environment
이 오류는 파이프라인이 Java 이외의 코드를 실행하기 위해 Java 기반 인터페이스(JNI)를 사용 중이고 해당 코드 또는 JNI 바인딩에 오류가 있는 경우 발생합니다.
googclient_deliveryattempt 속성 키 오류
다음 오류 중 하나가 발생하면서 Dataflow 작업이 실패합니다.
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
또는
Invalid extensions name: googclient_deliveryattempt
이 오류는 Dataflow 작업에 다음과 같은 특성이 있는 경우에 발생합니다.
- Dataflow 작업이 Streaming Engine을 사용함
- 파이프라인에 Pub/Sub 싱크가 있음
- 파이프라인이 가져오기 구독을 사용함
- 파이프라인이 기본 제공되는 Pub/Sub I/O 싱크를 사용하는 대신 Pub/Sub 서비스 API 중 하나를 사용하여 메시지를 게시함
- Pub/Sub가 Java 또는 C# 클라이언트 라이브러리를 사용함
- Pub/Sub 구독에 데드 레터 주제가 있음
이 오류는 Pub/Sub Java 또는 C# 클라이언트 라이브러리를 사용하고 구독에 데드 레터 주제가 사용 설정되었으며, 전송 시도가 delivery_attempt 필드가 아닌 googclient_deliveryattempt 메시지 속성에 있기 때문에 발생합니다. 자세한 내용은 '메시지 오류 처리' 페이지의 전송 시도 추적을 참조하세요.
이 문제를 해결하려면 다음 변경사항 중 하나 이상을 수행하세요.
- Streaming Engine을 사용 중지합니다.
- Pub/Sub 서비스 API 대신 기본 제공되는 Apache Beam
PubSubIO커넥터를 사용합니다. - 다른 유형의 Pub/Sub 구독을 사용합니다.
- 데드 레터 주제를 삭제합니다.
- Pub/Sub 풀 구독과 함께 Java 또는 C# 클라이언트 라이브러리를 사용하지 마세요. 다른 옵션은 클라이언트 라이브러리 코드 샘플을 참조하세요.
- 파이프라인 코드에서 속성 키가
goog로 시작되면 메시지를 게시하기 전 메시지 속성을 삭제하세요.
단축키가 감지됨
다음 오류가 발생합니다.
A hot key HOT_KEY_NAME was detected in...
이 오류는 데이터에 단축키가 포함되면 발생합니다. 단축키는 파이프라인 성능에 부정적인 영향을 주는 요소가 있는 키를 말합니다. 이러한 키는 요소를 병렬로 처리하는 Dataflow 기능을 제한하므로 실행 시간이 길어집니다.
파이프라인에서 단축키가 감지되었을 때 인간이 읽을 수 있는 키를 로그에 출력하려면 단축키 파이프라인 옵션을 사용합니다.
이 문제를 해결하려면 데이터가 균등하게 분산되었는지 확인합니다. 키의 값이 불균형하다면 다음 조치 실행을 고려해 보세요.
- 데이터를 다시 입력하세요.
ParDo변환을 적용하여 새로운 키-값 쌍을 출력합니다. - Java 작업의 경우
Combine.PerKey.withHotKeyFanout변환을 사용합니다. - Python 작업의 경우
CombinePerKey.with_hot_key_fanout변환을 사용합니다. - Dataflow Shuffle 사용 설정
Dataflow 모니터링 인터페이스에서 핫 키를 보려면 일괄 작업의 낙오 항목 문제 해결을 참조하세요.
Data Catalog의 잘못된 테이블 사양
Dataflow SQL을 사용하여 Dataflow SQL 작업을 만들 때는 로그 파일에서 다음 오류와 함께 작업이 실패할 수 있습니다.
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
이 오류는 Dataflow 서비스 계정에 Data Catalog API에 대한 액세스 권한이 없으면 발생합니다.
이 문제를 해결하려면 쿼리를 작성하고 실행하는 데 사용하는 Google Cloud프로젝트에서 Data Catalog API를 사용 설정합니다.
또는 roles/datacatalog.viewer 역할을 Dataflow 서비스 계정에 할당합니다.
작업 그래프가 너무 큽니다.
다음 오류와 함께 작업이 실패할 수 있습니다.
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
이 오류는 작업의 그래프 크기가 10MB를 초과하는 경우에 발생합니다. 파이프라인의 특정 조건으로 인해 작업 그래프가 제한을 초과할 수 있습니다. 일반적인 조건은 다음과 같습니다.
- 대량의 메모리 내 데이터를 포함한
Create변환 - 원격 작업자에게 전송하기 위해 직렬화된 큰
DoFn인스턴스 - (의도하지 않게) 대량의 데이터가 직렬화되도록 가져오는 익명 내부 클래스 인스턴스로서의
DoFn - 방향성 비순환 그래프(DAG)는 큰 목록을 열거하는 프로그래매틱 루프의 일부로 사용되고 있습니다.
이러한 상황을 방지하려면 파이프라인을 재구성하세요.
키 커밋이 너무 큼
스트리밍 작업을 실행할 때 작업자 로그 파일에 다음 오류가 표시됩니다.
KeyCommitTooLargeException
이 오류는 Combine 변환을 사용하지 않고 매우 많은 데이터 양을 그룹화하거나 단일 입력 요소에서 많은 데이터 양이 생성된 경우 스트리밍 시나리오에서 발생합니다.
이 오류가 발생할 가능성을 줄이려면 다음 전략을 사용합니다.
- 단일 요소를 처리하는 경우 출력 또는 상태 수정사항이 한도를 초과하지 않도록 해야 합니다.
- 요소 여러 개가 키별로 그룹화된 경우 키 공간을 늘려 키별로 그룹화되는 요소를 줄이는 것이 좋습니다.
- 짧은 기간 동안 키의 요소를 높은 빈도로 내보내면 기간에 해당 키의 많은 이벤트(GB 단위)가 발생할 수 있습니다. 파이프라인을 재작성하여 이러한 키를 감지하고 해당 기간에 키가 자주 있음을 나타내는 출력만 내보냅니다.
- 가환 작업과 연관 작업에 하위 선형 공간
Combine변환을 사용합니다. 공간이 줄어들지 않는다면 결합자를 사용하지 마세요. 예를 들어 단순히 문자열을 함께 추가하는 문자열의 결합자는 결합자를 사용하지 않는 것보다 나쁩니다.
7168K 초과 메시지 거부
템플릿에서 생성된 Dataflow 작업을 실행하면 작업이 실패하며 다음 오류가 반환됩니다.
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
이 오류는 데드 레터 큐에 쓰인 메시지가 크기 한도인 7168K를 초과하면 발생합니다. 이 문제를 해결하려면 크기 한도가 더 높은 Streaming Engine을 사용 설정합니다. Streaming Engine을 사용 설정하려면 다음 파이프라인 옵션을 사용합니다.
자바
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
요청 요소가 너무 큼
작업을 제출할 때 다음 오류 중 하나가 콘솔이나 터미널 창에 표시됩니다.
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
작업을 제출할 때 JSON 페이로드에 대한 오류가 발생하면 파이프라인의 JSON 표현이 최대 20MB 요청 크기를 초과합니다.
작업 크기는 파이프라인의 JSON 표현과 관계가 있습니다. 파이프라인이 클수록 요청이 커집니다. Dataflow는 20MB로 요청 크기를 제한합니다.
파이프라인의 JSON 요청 크기를 예측하려면 다음 옵션을 사용하여 파이프라인을 실행합니다.
자바
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go에서는 JSON으로 작업 출력이 지원되지 않습니다.
이 명령어는 작업의 JSON 표현을 파일에 작성합니다. 직렬화된 파일 크기로 요청 크기를 가늠할 수 있습니다. 실제 크기는 요청에 포함된 추가 정보로 인해 약간 더 커집니다.
파이프라인의 특정 조건으로 인해 JSON 표현이 제한을 초과할 수 있습니다. 가장 흔한 예시는 다음과 같습니다.
- 대량의 메모리 내 데이터를 포함한
Create변환 - 원격 작업자에게 전송하기 위해 직렬화된 큰
DoFn인스턴스 - (의도하지 않게) 대량의 데이터가 직렬화되도록 가져오는 익명 내부 클래스 인스턴스로서의
DoFn
이러한 상황을 방지하려면 파이프라인을 재구성하세요.
SDK 파이프라인 옵션 또는 스테이징 파일 목록이 크기 한도를 초과함
파이프라인을 실행할 때 다음 오류 중 하나가 발생합니다.
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
또는
Value for field 'resource.properties.metadata' is too large: maximum size
Compute Engine 메타데이터 한도 초과로 인해 파이프라인을 시작할 수 없을 때 이러한 오류가 발생합니다. 이러한 한도는 변경할 수 없습니다. Dataflow는 파이프라인 옵션의 Compute Engine 메타데이터를 사용합니다. 한도는 Compute Engine 커스텀 메타데이터 한도에 설명되어 있습니다.
다음 시나리오는 JSON 표현이 한도를 초과하도록 만들 수 있습니다.
- 스테이징할 JAR 파일이 너무 많습니다.
sdkPipelineOptions요청 필드가 너무 큽니다.
파이프라인의 JSON 요청 크기를 예측하려면 다음 옵션을 사용하여 파이프라인을 실행합니다.
자바
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go에서는 JSON으로 작업 출력이 지원되지 않습니다.
이 명령어의 출력 파일 크기는 256KB보다 작아야 합니다. 오류 메시지에서 512KB는 출력 파일의 총 크기 및 Compute Engine VM 인스턴스의 커스텀 메타데이터 옵션을 나타냅니다.
프로젝트에서 Dataflow 작업을 실행하여 VM 인스턴스에 대한 커스텀 메타데이터 옵션의 대략적인 값을 예상할 수 있습니다. 실행 중인 Dataflow 작업을 선택합니다. VM 인스턴스를 가져온 후 해당 VM의 Compute Engine VM 인스턴스 세부정보 페이지로 이동하여 커스텀 메타데이터 섹션을 확인합니다. 커스텀 메타데이터와 파일의 총 길이는 512KB 미만이어야 합니다. VM이 실패한 작업에 작동하지 않으므로 실패한 작업에 대한 정확한 예상이 불가능합니다.
JAR 목록이 256KB 한도에 도달하면 이를 검토하고 불필요한 JAR 파일을 줄입니다. 여전히 너무 크면 Uber JAR을 사용해서 Dataflow 작업을 실행해 보세요. Uber JAR을 만들고 사용하는 방법을 보여주는 예시는 Uber JAR 빌드 및 배포를 참조하세요.
sdkPipelineOptions 요청 필드가 너무 크면 파이프라인을 실행할 때 다음 옵션을 포함합니다. 파이프라인 옵션은 Java, Python, Go에 모두 동일합니다.
--experiments=no_display_data_on_gce_metadata
셔플 키가 너무 큼
작업자 로그 파일에 다음 오류가 나타납니다.
Shuffle key too large
이 오류는 해당 코더가 적용된 후 특정 (Co-)GroupByKey로 내보낸 직렬화된 키가 너무 큰 경우에 발생합니다. Dataflow는 직렬화된 셔플 키에 대한 제한이 있습니다.
이 문제를 해결하려면 키 크기를 줄이거나 보다 공간 효율적인 코더를 사용합니다.
자세한 내용은 Dataflow의 프로덕션 한도를 참조하세요.
BoundedSource 객체의 총 수가 허용 제한보다 큼
Java로 작업을 실행할 때 다음 오류 중 하나가 발생할 수 있습니다.
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
또는
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
자바
이 오류는 EXPORT를 통한 TextIO, AvroIO, BigQueryIO 또는 다른 파일 기반 소스를 통해 너무 많은 파일을 읽으면 발생할 수 있습니다. 구체적인 제한은 소스의 세부정보에 따라 다르지만 파이프라인 하나에 파일 수만 개 정도입니다. 예를 들어 AvroIO.Read에 스키마를 삽입하면 허용 파일 수가 줄어듭니다.
이 오류는 파이프라인용 커스텀 데이터 소스를 만들고 소스의 splitIntoBundles 메서드에서 직렬화 시 20MB를 초과 사용하는 BoundedSource 객체 목록을 반환하는 경우에도 발생할 수 있습니다.
커스텀 소스의 splitIntoBundles() 작업으로 생성된 BoundedSource 객체의 총 크기 제한은 20MB입니다.
이 제한사항을 해결하려면 다음 중 하나를 변경합니다.
Runner V2를 사용 설정합니다. Runner v2는 소스를 이 소스 분할 한도가 없는 분할 가능한 DoFn으로 변환합니다.
생성된
BoundedSource객체의 총 크기가 20MB 한도보다 작도록 커스텀BoundedSource서브클래스를 수정합니다. 예를 들어, 소스가 처음에 분할을 적게 생성하고 동적 작업 리밸런스를 사용하여 필요에 따라 입력을 추가로 분할할 수 있습니다.
요청 페이로드 크기가 한도(20,971,520바이트)를 초과함
파이프라인을 실행할 때 다음 오류와 함께 작업이 실패할 수 있습니다.
com.google.api.client.googleapis.json.GoogleJsonResponseException: 400 Bad Request
POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/workItems:reportStatus
{
"code": 400,
"errors": [
{
"domain": "global",
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"reason": "badRequest"
}
],
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"status": "INVALID_ARGUMENT"
}
이 오류는 Dataflow Runner를 사용하는 작업에 매우 큰 작업 그래프가 있는 경우 발생할 수 있습니다. 작업 그래프가 크면 Dataflow 서비스에 다시 보고해야 하는 측정항목이 많이 생성될 수 있습니다. 이러한 측정항목의 크기가 20MB API 요청 한도를 초과하면 작업이 실패합니다.
이 문제를 해결하려면 Dataflow Runner v2를 사용하도록 파이프라인을 마이그레이션하세요. Runner v2는 측정항목을 보고하는 데 더 효율적인 방법을 사용하며 20MB 제한이 없습니다.
NameError
Dataflow 서비스를 사용하여 파이프라인을 실행하면 다음 오류가 발생합니다.
NameError
이 오류는 DirectRunner를 사용하여 실행하는 경우와 같이 로컬에서 실행할 때 발생하지 않습니다.
이 오류는 DoFn가 Dataflow 작업자에서 사용할 수 없는 전역 네임스페이스의 값을 사용하는 경우에 발생합니다.
기본적으로 기본 세션에 정의된 전역 가져오기, 함수, 변수는 Dataflow 작업 직렬화 중에 저장되지 않습니다.
이 문제를 해결하려면 다음 방법 중 하나를 사용하세요. DoFn가 기본 파일에 정의되고 참조 가져오기와 함수가 전역 네임스페이스에 정의되어 있으면 --save_main_session 파이프라인 옵션을 True로 설정합니다. 이 변경사항은 전역 네임스페이스의 상태를 피클링하고 Dataflow 작업자에 로드합니다.
전역 네임스페이스에 피클링할 수 없는 객체가 있으면 피클링 오류가 발생합니다. Python 배포에서 사용할 수 있어야 하는 모듈과 관련된 오류가 발생하면 모듈을 로컬(사용되는 곳)로 가져옵니다.
예를 들어 다음을 사용하지 않습니다.
import re … def myfunc(): # use re module
대신 다음을 사용합니다.
def myfunc(): import re # use re module
또는 DoFn가 여러 파일에 걸쳐 있는 경우에는 다른 방식을 사용하여 워크플로를 패키징하고 종속 항목을 관리 합니다.
객체에 버킷의 보관 정책이 적용됨
Cloud Storage 버킷에 쓰는 Dataflow 작업이 있으면 작업이 실패하고 다음 오류가 발생합니다.
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
다음 오류가 표시될 수도 있습니다.
Unable to rename "gs://BUCKET"
첫 번째 오류는 Dataflow 작업이 쓰고 있는 Cloud Storage 버킷에서 객체 보관이 사용 설정된 경우에 발생합니다. 자세한 내용은 객체 보관 구성 사용 설정 및 사용을 참조하세요.
이 문제를 해결하려면 다음 해결 방법 중 하나를 사용하세요.
temp폴더에 보관 정책이 없는 Cloud Storage 버킷에 씁니다.작업이 쓰는 버킷에서 보관 정책을 삭제합니다. 자세한 내용은 객체 보관 구성 설정을 참조하세요.
두 번째 오류는 Cloud Storage 버킷에서 객체 보관이 사용 설정되었음을 나타내거나 Dataflow 작업자 서비스 계정에 Cloud Storage 버킷에 쓸 수 있는 권한이 없음을 나타낼 수도 있습니다.
두 번째 오류가 표시되고 Cloud Storage 버킷에서 객체 보관이 사용 설정된 경우 이전에 설명된 해결 방법을 시도해 보세요. Cloud Storage 버킷에 객체 보관이 사용 설정되어 있지 않으면 Dataflow 작업자 서비스 계정에 Cloud Storage 버킷에 대한 쓰기 권한이 있는지 확인합니다. 자세한 내용은 Cloud Storage 버킷에 액세스를 참조하세요.
처리 중단 또는 작업 진행 중
Dataflow가 반환 없이 DoFn을 실행하는 데 TIME_INTERVAL에 지정된 시간보다 더 긴 시간을 소비하면 다음 메시지가 표시됩니다.
자바
버전에 따라 다음 두 로그 메시지 중 하나입니다.
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
이 동작의 가능한 원인은 두 가지입니다.
DoFn코드 자체가 느리거나, 속도가 느린 외부 작업이 완료되길 기다리고 있습니다.DoFn코드가 정체되거나, 교착 상태가 되거나, 처리 완료 속도가 비정상적으로 느릴 수도 있습니다.
어떤 경우인지 확인하려면 Cloud Monitoring 로그 항목을 확장하여 스택 트레이스를 확인합니다. DoFn 코드가 막혔거나 다른 문제가 발생했음을 나타내는 메시지가 있는지 확인합니다. 메시지가 없으면 DoFn 코드 실행 속도로 인해 문제가 발생했을 수 있습니다. Cloud Profiler 또는 다른 도구를 사용하여 코드 성능을 조사해 보는 것이 좋습니다.
파이프라인이 Java VM을 기반으로 구축된 경우 (Java 또는 Scala 사용) 중단된 코드의 원인을 조사할 수 있습니다. 다음 단계를 수행하여 정체된 스레드만이 아닌 전체 JVM의 전체 스레드 덤프를 가져옵니다.
- 로그 항목에서 작업자 이름을 기록합니다.
- Google Cloud 콘솔의 Compute Engine 섹션에서 기록한 작업자 이름의 Compute Engine 인스턴스를 찾습니다.
- SSH를 사용하여 해당 이름의 인스턴스에 연결합니다.
다음 명령어를 실행합니다.
curl http://localhost:8081/threadz
번들에서 작업 진행 중
JdbcIO에서 읽는 파이프라인을 실행하면 JdbcIO에서 파티션을 나눈 읽기가 느려지고 작업자 로그 파일에 다음 메시지가 표시됩니다.
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
이 문제를 해결하려면 파이프라인을 다음 중 하나 이상으로 변경합니다.
파티션을 사용하여 작업 동시 로드를 늘립니다. 확장성이 높아지도록 더 작고 더 많은 파티션으로 읽습니다.
파티션 나누기 열이 소스의 색인 열인지 또는 실제 파티션 나누기 열인지 확인합니다. 최적의 성능을 위해 소스 데이터베이스에서 이 열에서 색인 생성과 파티셔닝을 활성화합니다.
lowerBound및upperBound파라미터를 사용하여 경계 찾기를 건너뜁니다.
Pub/Sub 할당량 오류
Pub/Sub에서 스트리밍 파이프라인을 실행할 때 다음 오류가 발생합니다.
429 (rateLimitExceeded)
또는
Request was throttled due to user QPS limit being reached
이 오류는 프로젝트에 Pub/Sub 할당량이 부족하면 발생합니다.
프로젝트에 할당량이 부족한지 여부를 확인하려면 다음 단계를 따라 클라이언트 오류를 확인하세요.
- Google Cloud 콘솔로 이동합니다.
- 왼쪽의 메뉴에서 API 및 서비스를 선택합니다.
- 검색창에서 Cloud Pub/Sub를 검색합니다.
- 사용량 탭을 클릭합니다.
- 응답 코드를 확인하고
(4xx)클라이언트 오류 코드를 찾습니다.
조직의 정책에 따라 요청이 금지됨
파이프라인을 실행할 때 다음 오류가 발생합니다.
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
이 오류는 Cloud Storage 버킷이 서비스 경계 외부에 있는 경우 발생합니다.
이 문제를 해결하려면 서비스 경계 외부의 버킷에 액세스할 수 있는 이그레스 규칙을 만듭니다.
스테이징된 패키지... 액세스할 수 없음
성공 시 사용된 작업이 다음 오류와 함께 실패할 수 있습니다.
Staged package...is inaccessible
이 문제를 해결하려면 다음 안내를 따르세요.
- 스테이징에 사용된 Cloud Storage 버킷에 스테이징된 패키지 삭제 원인이 되는 TTL 설정이 없는지 확인합니다.
Dataflow 프로젝트의 작업자 서비스 계정에 스테이징에 사용된 Cloud Storage 버킷에 액세스하는 권한이 있는지 확인합니다. 다음과 같은 이유로 권한의 차이가 발생할 수 있습니다.
- 스테이징에 사용되는 Cloud Storage 버킷이 다른 프로젝트에 있습니다.
- 스테이징에 사용되는 Cloud Storage 버킷은 세분화된 액세스 권한에서 균일한 버킷 수준 액세스로 마이그레이션되었습니다. IAM 및 ACL 정책 사이의 불일치로 인해 스테이징 버킷을 균일한 버킷 수준의 액세스로 마이그레이션하면 Cloud Storage 리소스에 대한 ACL이 허용되지 않습니다. ACL에는 스테이징 버킷에 대한 Dataflow 프로젝트의 작업자 서비스 계정에 있는 권한이 포함됩니다.
자세한 내용은 Google Cloud Platform 프로젝트에서 Cloud Storage 버킷에 액세스를 참조하세요.
작업 항목 4번 실패
일괄 작업이 실패하면 다음 오류가 발생합니다.
The job failed because a work item has failed 4 times.
이 오류는 일괄 작업의 단일 작업으로 인해 작업자 코드가 4번 실패하는 경우에 발생합니다. Dataflow에서 작업을 실패하면 이 메시지가 표시됩니다.
스트리밍 모드에서 실행하는 경우 실패 항목이 포함된 번들은 무제한으로 재시도되므로 파이프라인이 영구 중단될 수 있습니다.
이 장애 기준점은 구성할 수 없습니다. 자세한 내용은 파이프라인 오류 및 예외 처리를 참조하세요.
이 문제를 해결하려면 작업의 Cloud Monitoring 로그에서 개별 실패 4개를 찾습니다. 작업자 로그에서 예외나 오류를 표시하는 Error-level 또는 Fatal-level 로그 항목을 찾으세요. 예외나 오류가 최소 4회 이상 나타나야 합니다. 로그에 MongoDB와 같은 외부 리소스 액세스와 관련된 일반 제한 시간 오류만 포함된 경우 작업자 서비스 계정에 리소스의 서브네트워크에 액세스할 수 있는 권한이 있는지 확인합니다.
폴링 결과 파일 제한 시간
'결과 파일 폴링 제한 시간' 오류 문제 해결에 관한 자세한 내용은 Flex 템플릿 문제 해결을 참고하세요.
Write Correct File/Write/WriteImpl/PreFinalize 실패
작업을 실행할 때 작업이 간헐적으로 실패하고 다음 오류가 발생합니다.
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
이 오류는 동시 실행되는 여러 작업의 임시 스토리지 위치로 같은 하위 폴더가 사용될 때 발생합니다.
이 문제를 해결하려면 여러 파이프라인의 임시 스토리지 위치로 같은 하위 폴더를 사용하지 마세요. 파이프라인마다 임시 스토리지 위치로 사용할 고유한 하위 폴더를 제공합니다.
요소가 최대 protobuf 메시지 크기를 초과함
Dataflow 작업을 실행하고 파이프라인에 대규모 요소가 있으면 다음 예시와 유사한 오류가 표시될 수 있습니다.
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
또는
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
또는
Output element size exceeds the allowed limit. (... > 83886080) See https://cloud.google.com/dataflow/quotas#limits for more details.
다음 예시와 유사한 경고가 표시될 수도 있습니다.
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
이 오류는 파이프라인에 대규모 요소가 포함되어 있으면 발생합니다.
이 문제를 해결하려면 Python SDK를 사용하는 경우 Apache Beam 버전 2.57.0 이상으로 업그레이드합니다. Python SDK 버전 2.57.0 이상은 대규모 요소 처리를 향상시키고 관련 로깅을 추가합니다.
업그레이드 후에도 오류가 계속 발생하거나 Python SDK를 사용하지 않는 경우 작업에서 오류가 발생하는 단계를 파악하고 해당 단계의 요소 크기를 줄여 보세요.
파이프라인의 PCollection 객체에 대규모 요소가 있으면 파이프라인의 RAM 요구사항이 증가합니다.
대규모 요소는 특히 융합된 스테이지의 경계를 넘을 때 런타임 오류를 일으킬 수도 있습니다.
파이프라인이 실수로 반복 가능한 대규모 항목을 구체화하면 대규모 요소가 발생할 수 있습니다. 예를 들어 GroupByKey 작업의 출력을 불필요한 Reshuffle 작업에 전달하는 파이프라인은 목록을 단일 요소로 구체화합니다. 이러한 목록에는 각 키에 대한 값이 다수 포함될 수 있습니다.
부차 입력을 사용하는 단계에서 오류가 발생하는 경우 부차 입력을 사용하면 융합 장벽이 발생할 수 있습니다. 대규모 요소를 생성하는 변환과 이를 사용하는 변환이 같은 단계에 속하는지 확인합니다.
파이프라인을 구성할 때는 다음 권장사항을 따릅니다.
PCollections에서 대규모 요소 하나 대신 작은 요소 여러 개를 사용합니다.- 외부 저장소 시스템에 대용량 blob을 저장합니다.
PCollections를 사용하여 메타데이터를 전달하거나 요소 크기를 줄이는 커스텀 코더를 사용합니다. - 2GB를 초과할 수 있는 PCollection을 부차 입력으로 전달해야 하는 경우
AsIterable및AsMultiMap과 같은 반복 가능한 뷰를 사용합니다.
Dataflow 작업의 최대 단일 요소 크기는 2GB(Streaming Engine의 경우 80MB)로 제한됩니다. 자세한 내용은 할당량 및 제한을 참조하세요.
Dataflow에서 관리형 변환을 처리할 수 없음
Dataflow에서 I/O 변환을 지원되는 최신 버전으로 자동 업그레이드할 수 없는 경우 관리형 I/O를 사용하는 파이프라인이 이 오류로 인해 실패할 수 있습니다. 오류에 제공된 URN과 단계 이름은 Dataflow가 업그레이드에 실패한 정확한 변환을 지정해야 합니다.
로그 탐색기의 Dataflow 로그 이름 managed-transforms-worker 및 managed-transforms-worker-startup에서 이 오류에 관한 추가 세부정보를 확인할 수 있습니다.
로그 탐색기에서 오류를 해결하기에 충분한 정보를 제공하지 않는 경우 Cloud Customer Care에 문의하세요.
보관 작업 오류
다음 섹션에는 API를 사용해서 Dataflow 작업 보관처리를 시도할 때 발생할 수 있는 일반적인 오류가 포함되어 있습니다.
값이 제공되지 않음
API를 사용해서 Dataflow 작업을 보관처리하려고 시도할 때 다음 오류가 발생할 수 있습니다.
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
이 오류는 다음 이유 중 하나로 발생합니다.
updateMask필드에 지정된 경로가 올바른 형식을 따르지 않습니다. 이 문제는 오타로 인해 발생할 수 있습니다.JobMetadata가 올바르게 지정되지 않았습니다.JobMetadata필드에서userDisplayProperties에 대해 키-값 쌍"archived":"true"를 사용합니다.
이 오류를 해결하려면 API에 전달하는 명령어가 필요한 형식과 일치하는지 확인합니다. 자세한 내용은 작업 보관처리를 참조하세요.
API가 값을 인식하지 못함
API를 사용해서 Dataflow 작업을 보관처리하려고 시도할 때 다음 오류가 발생할 수 있습니다.
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
이 오류는 보관처리 작업 키-값 쌍에 제공된 값이 지원되는 값이 아닐 때 발생합니다. 보관처리 작업 키-값 쌍에 지원되는 값은 "archived":"true" 및 "archived":"false"입니다.
이 오류를 해결하려면 API에 전달하는 명령어가 필요한 형식과 일치하는지 확인합니다. 자세한 내용은 작업 보관처리를 참조하세요.
상태와 마스크를 업데이트할 수 없음
API를 사용해서 Dataflow 작업을 보관처리하려고 시도할 때 다음 오류가 발생할 수 있습니다.
Cannot update both state and mask.
이 오류는 동일한 API 호출에서 작업 상태 및 보관처리 상태를 업데이트하려고 시도할 때 발생합니다. 동일한 API 호출로 작업 상태 및 updateMask 쿼리 파라미터를 모두 업데이트할 수는 없습니다.
이 오류를 해결하려면 별개의 API 호출로 작업 상태를 업데이트합니다. 작업 보관처리 상태를 업데이트하기 전에 작업 상태를 업데이트합니다.
워크플로 수정 실패
API를 사용해서 Dataflow 작업을 보관처리하려고 시도할 때 다음 오류가 발생할 수 있습니다.
Workflow modification failed.
이 오류는 일반적으로 실행 중인 작업을 보관처리하려고 시도할 때 발생합니다.
이 오류를 해결하려면 작업이 완료될 때까지 기다린 후 보관처리를 시도합니다. 완료된 작업의 작업 상태는 다음 중 하나입니다.
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
자세한 내용은 Dataflow 작업 완료 감지를 참조하세요.
컨테이너 이미지 오류
다음 섹션에서는 오류를 해결하기 위해 커스텀 컨테이너와 단계를 사용할 때 발생할 수 있는 일반적인 오류를 설명합니다. 이러한 오류는 일반적으로 다음 메시지에서 프리픽스로 추가됩니다.
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
"containeranalysis.occurrences.list" 권한 거부됨
로그 파일에 다음 오류가 표시됩니다.
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
취약점 스캔을 위해 Container Analysis API가 필요합니다.
자세한 내용은 Artifact Analysis 문서에서 OS 스캔 개요 및 액세스 제어 구성을 참조하세요.
포드 동기화 중 오류 ... 'StartContainer' 실패
작업자 시작 중에 다음 오류가 발생합니다.
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
포드는 Dataflow 작업자에서 실행되는 Docker 컨테이너의 공동 배치 그룹입니다. 이 오류는 포드에 있는 Docker 컨테이너 중 하나가 시작하지 않을 때 발생합니다. 오류를 복구할 수 없으면 Dataflow 작업자가 시작할 수 없으며 Dataflow 일괄 작업이 다음과 같은 오류와 함께 실패합니다.
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
이 오류는 일반적으로 컨테이너 중 하나가 시작 중에 지속적으로 비정상 종료될 때 발생합니다.
근본 원인을 파악하려면 오류 직전에 캡처된 로그를 찾습니다. 로그를 분석하려면 로그 탐색기를 사용합니다. 로그 탐색기에서 로그 파일을 컨테이너 시작 오류가 있는 작업자가 내보낸 로그 항목으로 제한합니다. 로그 항목을 제한하려면 다음 단계를 완료합니다.
- 로그 탐색기에서
Error syncing pod로그 항목을 찾습니다. - 로그 항목과 연관된 라벨을 보려면 로그 항목을 확장합니다.
resource_name과 연결된 라벨을 클릭한 후 일치하는 항목 표시를 클릭합니다.
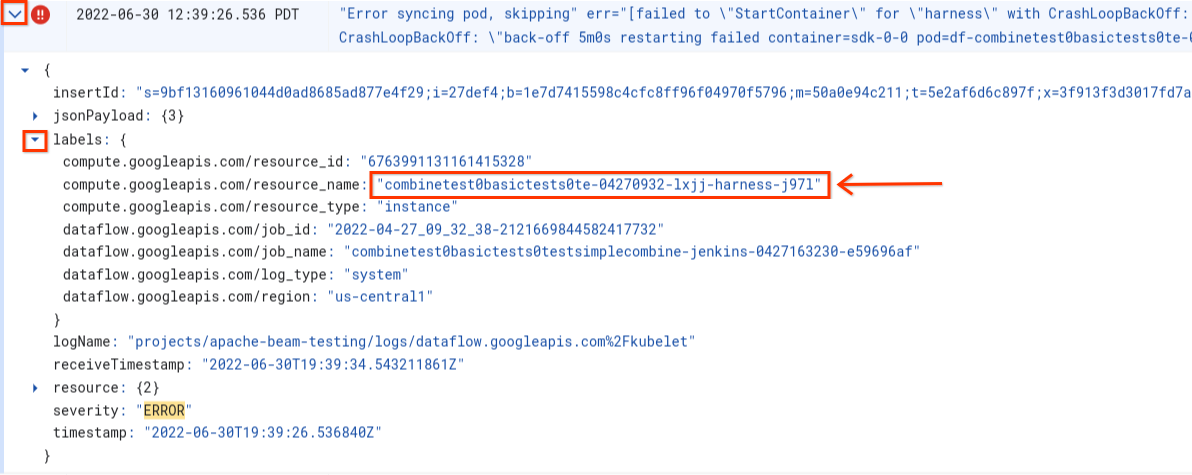
로그 탐색기에서 Dataflow 로그는 로그 스트림 여러 개로 구성됩니다. Error syncing pod 메시지는 kubelet이라는 로그에 표시됩니다. 하지만 실패 컨테이너의 로그는 다른 로그 스트림에 포함될 수 있습니다. 컨테이너마다 이름이 있습니다. 다음 표를 사용하여 실패 컨테이너와 관련된 로그가 포함될 수 있는 로그 스트림을 확인합니다.
| 컨테이너 이름 | 로그 이름 |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0 등 | docker |
| harness | harness, harness-startup |
| python, java-batch, java-streaming | worker-startup, worker |
| artifact | artifact |
로그 탐색기를 쿼리할 때는 쿼리 빌더 인터페이스에서 쿼리에 관련 로그 이름이 포함되어 있는지 또는 로그 이름에 제한이 없는지 확인합니다.
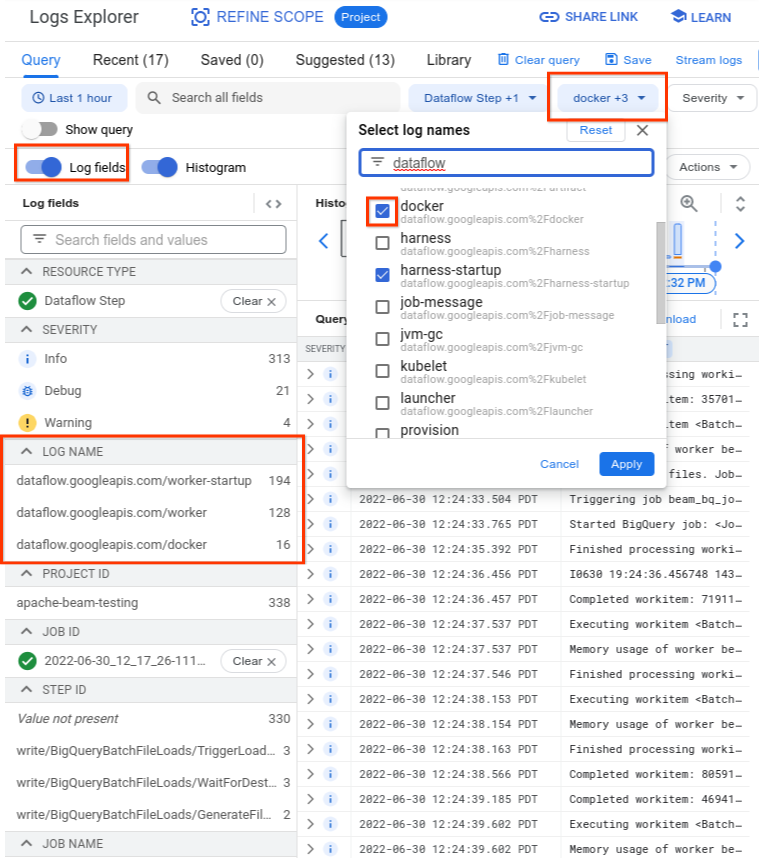
관련 로그를 선택한 후 다음 예시와 같은 쿼리 결과가 표시될 수 있습니다.
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
컨테이너 오류 증상을 보고하는 로그가 INFO로 보고되는 경우도 있으므로 분석에 INFO 로그를 포함합니다.
컨테이너 오류의 일반적인 원인은 다음과 같습니다.
- Python 파이프라인에 런타임에 설치된 추가 종속 항목이 있고 설치가 성공하지 않았습니다.
pip install failed with error와 같은 오류가 표시될 수 있습니다. 이 문제는 요구사항 충돌 또는 Dataflow 작업자가 인터넷을 통해 공개 저장소에서 외부 종속 항목을 가져오지 못하게 하는 제한된 네트워킹 구성으로 인해 발생할 수 있습니다. 메모리 부족 오류로 인해 파이프라인 실행 중에 작업자가 실패합니다. 다음 중 하나와 같은 오류가 표시될 수 있습니다.
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
메모리 부족 문제를 디버깅하려면 Dataflow 메모리 부족 오류 문제 해결을 참조하세요.
Dataflow가 컨테이너 이미지를 가져올 수 없습니다. 자세한 내용은 이미지 pull 요청 실패 오류를 참조하세요.
사용된 컨테이너가 작업자 VM의 CPU 아키텍처와 호환되지 않습니다. 하네스 시작 로그에서
exec /opt/apache/beam/boot: exec format error와 같은 오류가 표시될 수 있습니다. 컨테이너 이미지의 아키텍처를 확인하려면docker image inspect $IMAGE:$TAG를 실행하고Architecture키워드를 찾습니다.Error: No such image: $IMAGE:$TAG가 표시되면 먼저docker pull $IMAGE:$TAG를 실행하여 이미지를 가져와야 할 수 있습니다. 멀티아키텍처 이미지 빌드 방법에 대한 자세한 내용은 멀티아키텍처 컨테이너 이미지 빌드를 참조하세요.
컨테이너 오류의 원인이 파악되면 오류 해결을 시도한 후 파이프라인을 다시 제출합니다.
이미지 pull 요청 실패 오류
작업자 시작 중 다음 오류 중 하나가 작업자 또는 작업 로그에 표시됩니다.
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
이러한 오류는 작업자가 Docker 컨테이너 이미지를 가져올 수 없어서 시작할 수 없는 경우에 발생합니다. 이 문제는 다음 시나리오에서 발생합니다.
- 커스텀 SDK 컨테이너 이미지 URL이 잘못됨
- 작업자에게 사용자 인증 정보 또는 원격 이미지에 대한 네트워크 액세스가 부족함
이 문제를 해결하려면 다음 안내를 따르세요.
- 작업에 커스텀 컨테이너 이미지를 사용하는 경우 이미지 URL이 올바르고 이 URL에 올바른 태그나 다이제스트가 있는지 확인합니다. Dataflow 작업자도 이미지에 액세스해야 합니다.
- 인증되지 않은 머신에서
docker pull $image를 실행하여 공개 이미지를 로컬로 가져올 수 있는지 확인합니다.
비공개 이미지 또는 비공개 작업자의 경우 다음 단계를 따르세요.
- Container Registry를 사용하여 컨테이너 이미지를 호스팅할 때는 대신 Artifact Registry를 사용하는 것이 좋습니다. 2023년 5월 15일부터 Container Registry가 지원 중단됩니다. Container Registry를 사용 중이면 Artifact Registry로 전환할 수 있습니다. 이미지가 Google Cloud Platform 작업을 실행하는 데 사용되는 것과 다른 프로젝트에 있으면 기본 Google Cloud Platform 서비스 계정에 대해 액세스 제어를 구성합니다.
- 공유 Virtual Private Cloud(VPC)를 사용하는 경우 작업자가 커스텀 컨테이너 저장소 호스트에 액세스할 수 있는지 확인합니다.
ssh를 사용하여 실행 중인 작업의 작업자 VM과 연결하고docker pull $image를 실행하여 작업자가 올바르게 구성되었는지 확인합니다.
이 오류로 인해 작업자가 연속으로 여러 번 실패하고 작업이 시작된 경우 작업이 실패하고 다음과 유사한 오류를 반환할 수 있습니다.
Job appears to be stuck.
작업이 실행되는 동안 이미지 자체를 삭제하거나 이미지에 액세스할 수 있는 Dataflow 작업자 서비스 계정 사용자 인증 정보나 인터넷 액세스를 취소하여 이미지에 대해 액세스 권한을 삭제한 경우 Dataflow에서 오류만 로깅합니다. Dataflow가 작업에 오류를 발생시키지 않습니다. 또한 Dataflow는 파이프라인 상태 손실이 방지되도록 장기 실행 스트리밍 파이프라인 오류를 방지합니다.
다른 가능한 오류도 저장소 할당량 문제 또는 서비스 중단으로부터 발생할 수 있습니다. 공개 이미지 가져오기에 대한 Docker Hub 할당량을 초과하는 문제 또는 일반 타사 저장소 서비스 중단이 발생하면 Artifact Registry를 이미지 저장소로 사용하는 것이 좋습니다.
SystemError: 알 수 없는 명령 코드
작업을 제출한 직후에 Python 커스텀 컨테이너 파이프라인이 다음 오류와 함께 실패할 수 있습니다.
SystemError: unknown opcode
또한 스택 트레이스에는 다음이 포함될 수 있습니다.
apache_beam/internal/pickler.py
이 문제를 해결하려면 로컬에서 사용 중인 Python 버전이 컨테이너 이미지의 버전과 주 버전 및 마이너 버전까지 일치하는지 확인합니다. 3.6.7과 3.6.8처럼 패치 버전의 차이는 호환성 문제를 일으키지 않습니다. 3.6.8과 3.8.2처럼 마이너 버전의 차이는 파이프라인 오류를 일으킬 수 있습니다.
스트리밍 파이프라인 업그레이드 오류
병렬 바꾸기 작업 실행과 같은 기능을 사용하여 스트리밍 파이프라인을 업그레이드할 때 오류를 해결하는 방법은 스트리밍 파이프라인 업그레이드 문제 해결을 참조하세요.
Runner v2 하네스 업데이트
Runner v2 작업의 작업 로그에 다음 정보 메시지가 표시됩니다.
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
즉, 메시지가 처음 전송된 후 7일이 지나면 실행기 하네스 프로세스 버전이 자동으로 업데이트되어 처리가 잠시 일시중지됩니다. 이 일시중지가 발생하는 시점을 제어하려면 기존 파이프라인 업데이트를 참고하여 최신 버전의 실행기 하네스가 있는 교체 작업을 시작하세요.
작업자 오류
다음 섹션에서는 발생할 수 있는 일반적인 작업자 오류와 오류 해결 단계를 설명합니다.
Java 작업자 하네스에서 Python DoFn으로 전송한 호출이 오류와 함께 실패
Java 작업자 하네스에서 Python DoFn으로 전송한 호출이 실패하면 관련 오류 메시지가 표시됩니다.
오류를 조사하려면 Cloud Monitoring 오류 로그 항목을 확장하여 오류 메시지와 역추적을 살펴봅니다. 어떤 코드가 실패했는지 나타나므로 필요한 경우 수정할 수 있습니다. 오류가 Apache Beam 또는 Dataflow의 버그라고 생각되면 버그를 신고하세요.
EOFError: 마셜 데이터가 너무 짧음
작업자 로그에 다음 오류가 표시됩니다.
EOFError: marshal data too short
이 오류는 일부 경우에 Python 파이프라인 작업자에 디스크 공간이 부족할 때 발생합니다.
이 문제를 해결하려면 기기에 남아 있는 공간이 없음을 참조하세요.
디스크를 연결할 수 없음
Persistent Disk에서 C3 VM을 사용하는 Dataflow 작업을 실행하려고 하면 다음 오류 중 하나 또는 모두가 발생하면서 작업이 실패합니다.
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
이러한 오류는 지원되지 않는 Persistent Disk 유형으로 C3 VM을 사용할 때 발생합니다. 자세한 내용은 C3에 지원되는 디스크 유형을 참조하세요.
Dataflow 작업에 C3 VM을 사용하려면 pd-ssd 작업자 디스크 유형을 선택합니다. 자세한 내용은 작업자 수준 옵션을 참조하세요.
자바
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
기기에 남아 있는 공간이 없음
작업을 실행하는 데 디스크 공간이 부족하면 작업자 로그에 다음 오류가 표시될 수 있습니다.
No space left on device
이 오류는 다음 이유 중 하나로 인해 발생할 수 있습니다.
- 작업자 영구 스토리지의 공간 부족은 다음과 같은 이유 중 하나로 인해 발생할 수 있습니다.
- 작업이 런타임에 대용량 종속 항목을 다운로드하는 경우
- 작업이 대용량 커스텀 컨테이너를 사용하는 경우
- 작업에서 많은 임시 데이터를 로컬 디스크에 기록하는 경우
- Dataflow Shuffle을 사용할 때 Dataflow가 낮은 기본 디스크 크기를 설정하는 경우. 결과적으로 이 오류는 작업자 기반 셔플에서 이동하는 작업에서 발생할 수 있습니다.
- 항목을 초당 50개 넘게 로깅하므로 작업자 부팅 디스크가 채워지는 경우
이 문제를 해결하려면 다음 문제 해결 단계를 따르세요.
단일 작업자와 연결된 디스크 리소스를 보려면 VM 인스턴스 세부정보에서 작업과 연결된 작업자 VM을 찾습니다. 디스크 공간의 일부는 운영체제, 바이너리, 로그, 컨테이너에서 사용됩니다.
영구 디스크 또는 부팅 디스크 공간을 늘리려면 디스크 크기 파이프라인 옵션을 조정합니다.
Cloud Monitoring을 사용하여 작업자 VM 인스턴스에서 디스크 공간 사용량을 추적합니다. 설정 방법은 Monitoring 에이전트에서 작업자 VM 측정항목 수신을 참조하세요.
작업자 VM 인스턴스의 직렬 포트 출력 보기에서 부팅 디스크 공간 문제를 찾고 다음과 같은 메시지를 찾습니다.
Failed to open system journal: No space left on device
작업자 VM 인스턴스가 많으면 모든 인스턴스에서 gcloud compute instances get-serial-port-output을 한 번에 실행하는 스크립트를 만들 수 있습니다.
대신 이 출력을 검토할 수 있습니다.
작업자 활동이 없으면 1시간 후에 Python 파이프라인 실패
CPU 코어가 많은 작업자 머신에서 Python용 Apache Beam SDK를 Dataflow Runner V2와 함께 사용하는 경우 Apache Beam SDK 2.35.0 이상을 사용합니다. 작업이 커스텀 컨테이너를 사용하는 경우 Apache Beam SDK 2.46.0 이상을 사용합니다.
Python 컨테이너를 사전 빌드하는 것이 좋습니다. 이 단계는 VM 시작 시간 및 수평 자동 확장 성능을 개선할 수 있습니다. 이 기능을 사용하려면 프로젝트에서 Cloud Build API를 사용 설정하고 다음 파라미터로 파이프라인을 제출합니다.
‑‑prebuild_sdk_container_engine=cloud_build.
자세한 내용은 Dataflow Runner V2를 참조하세요.
모든 종속 항목이 사전 설치되어 있는 커스텀 컨테이너 이미지를 사용할 수도 있습니다.
RESOURCE_POOL_EXHAUSTED
Google Cloud Platform 리소스를 만들면 다음 오류가 발생합니다.
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
이 오류는 특정 영역의 특정 리소스에 대한 일시적 재고 부족 조건에서 발생합니다.
이 문제를 해결하려면 기다리거나 다른 영역에 같은 리소스를 만들면 됩니다.
해결 방법으로 작업에 재시도 루프를 구현합니다. 그러면 재고 부족 오류가 발생한 경우 리소스를 사용할 수 있을 때까지 작업이 자동으로 재시도됩니다. 재시도 루프를 만들려면 다음 워크플로를 구현합니다.
- Dataflow 작업을 만들고 작업 ID를 가져옵니다.
- 작업 상태가
RUNNING또는FAILED가 될 때까지 작업 상태를 폴링합니다.- 작업 상태가
RUNNING이면 재시도 루프를 종료합니다. - 작업 상태가
FAILED이면 Cloud Logging API를 사용하여 작업 로그에서ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS문자열을 쿼리합니다. 자세한 내용은 파이프라인 로그 작업을 참조하세요.- 로그에 문자열이 포함되어 있지 않으면 재시도 루프를 종료합니다.
- 로그에 문자열이 포함되어 있으면 Dataflow 작업을 만들고 작업 ID를 가져와 재시도 루프를 다시 시작합니다.
- 작업 상태가
권장사항은 서비스 중단을 톨러레이션(toleration)할 수 있도록 여러 영역과 리전에 리소스를 분산하는 것입니다.
런타임 종속 항목 오류
언어 간 변환과 함께 Python용 Apache Beam SDK를 사용하는 Dataflow 작업을 실행하면 Maven Central에서 JAR 파일을 다운로드할 때 HTTP Error
403: Forbidden 오류와 함께 작업이 실패할 수 있습니다.
이 문제는 Apache Beam SDK에서 사용하는 Python urllib 라이브러리의 요청을 차단하는 Maven Central의 CDN 제공업체 변경으로 인해 발생합니다.
이 문제를 해결하려면 Apache Beam 버전 2.69.0 이상으로 업그레이드하세요. 업그레이드할 수 없는 경우 이 섹션의 해결 방법을 참고하세요.
Apache Beam 2.69.0 이상의 수정사항
Apache Beam 2.69.0 이상에는 다음과 같은 수정사항이 포함되어 있습니다.
맞춤 Maven 저장소 URL:
--maven_repository_url파이프라인 옵션을 사용하여 맞춤 Maven 저장소를 지정할 수 있습니다. 예를 들면 다음과 같습니다.--maven_repository_url https://maven-central.storage-download.googleapis.com/maven2/User-Agent 식별: Apache Beam SDK는 요청이 차단되지 않도록 특정
User-Agent헤더를 전송합니다.
이전 SDK의 해결 방법
Apache Beam 2.69.0 이상으로 업그레이드할 수 없는 경우 다음 해결 방법 중 하나를 사용하세요.
- 맞춤 컨테이너에 JAR 사전 패키징(권장): 필요한 JAR 파일을 맞춤 컨테이너 이미지에 사전 패키징합니다. 런타임에 SDK가 JAR를 다운로드하지 않도록 Apache Beam 캐시 디렉터리(
/root/.apache_beam/cache/jars/)에 JAR를 배치합니다. Google의 Maven 미러 사용:
--expansion_service파이프라인 옵션을 사용하여 Apache Beam SDK가 Maven Central의 Google 미러에서 필요한 JAR를 다운로드하도록 지시합니다. 예를 들면 다음과 같습니다.--expansion_service https://maven-central.storage-download.googleapis.com/maven2/org/apache/beam/beam-sdks-java-extensions-schemaio-expansion-service/BEAM_VERSION/beam-sdks-java-extensions-schemaio-expansion-service-BEAM_VERSION.jarCloud Storage에 JAR 스테이징: 필요한 JAR을 다운로드하고 Cloud Storage 버킷에 스테이징한 다음
--expansion_service파이프라인 옵션에 JAR의 Cloud Storage 경로를 제공합니다.
게스트 가속기가 있는 인스턴스는 라이브 마이그레이션을 지원하지 않습니다.
다음 오류와 함께 작업 제출 시 Dataflow 파이프라인이 실패합니다.
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
이 오류는 하드웨어 가속기가 있는 작업자 머신 유형을 요청했지만 가속기를 사용하도록 Dataflow를 구성하지 않은 경우 발생할 수 있습니다.
--worker_accelerator Dataflow 서비스 옵션 또는 accelerator
리소스 힌트를 사용하여 하드웨어 가속기를 요청합니다.
Flex 템플릿을 사용하는 경우 --additionalExperiments 옵션을 사용하여 Dataflow 서비스 옵션을 제공할 수 있습니다. 올바르게 완료되면Google Cloud 콘솔의 작업의 작업 정보 패널에서 worker_accelerator 옵션을 확인할 수 있습니다.
프로젝트 할당량 또는 액세스 제어 정책으로 인해 작업이 차단됨
다음 오류가 발생합니다.
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
이 오류는 다음 이유 중 하나로 발생합니다.
- Dataflow 작업자 생성에서 사용하는 Compute Engine 할당량 중 하나를 초과했습니다.
- 현재 사용 중인 계정 또는 타겟팅 영역과 같은 VM 인스턴스 생성 프로세스의 일부를 금지하는 제약조건이 조직에 있습니다.
이 문제를 해결하려면 다음 문제 해결 단계를 따르세요.
VM 인스턴스 로그 검토
- Cloud Logging 뷰어로 이동합니다.
- 감사를 받은 리소스 드롭다운 목록에서 VM 인스턴스를 선택합니다.
- 모든 로그 드롭다운 목록에서 compute.googleapis.com/activity_log를 선택합니다.
- 로그에서 VM 인스턴스 생성 실패와 관련된 항목을 검색합니다.
Compute Engine 할당량 사용량 확인
타겟팅 중인 영역의 Dataflow 할당량과 비교하여 Compute Engine 리소스 사용량을 보려면 다음 명령어를 실행합니다.
gcloud compute regions describe [REGION]다음 리소스의 결과를 검토하여 할당량이 초과되었는지 확인합니다.
- CPUS
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
필요한 경우 할당량 변경을 요청합니다.
조직 정책 제약조건 검토
- 조직 정책 페이지로 이동합니다.
- 사용 중인 계정(기본적으로 Dataflow 서비스 계정) 또는 대상 영역의 VM 인스턴스 생성을 제한할 수 있는 제약 조건을 검토합니다.
- 외부 IP 주소 사용을 제한하는 정책이 있는 경우 이 작업에 외부 IP 주소를 사용 중지합니다. 외부 IP 주소를 사용 중지하는 방법에 대한 자세한 내용은 인터넷 액세스 및 방화벽 규칙 구성을 참조하세요.
작업자의 업데이트를 기다리는 동안 타임아웃됨
Dataflow 작업이 실패하면 다음 오류가 발생합니다.
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
이 오류는 다음과 같은 여러 가지 원인으로 인해 발생할 수 있습니다.
작업자 과부하
때때로 타임아웃 오류는 작업자의 메모리 또는 스왑 공간이 부족할 때 발생합니다. 이 문제를 해결하려면 첫 번째 단계로 작업을 다시 실행해 봅니다. 작업이 계속 실패하고 같은 오류가 발생하면 메모리와 디스크 공간이 더 많은 작업자를 사용해 봅니다. 예를 들어 다음 파이프라인 시작 옵션을 추가합니다.
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
작업자 유형을 변경하면 청구 비용이 영향을 받을 수 있습니다. 자세한 내용은 Dataflow의 메모리 부족 오류 문제 해결을 참조하세요.
이 오류는 데이터에 단축키가 포함되어 있을 때도 발생할 수 있습니다. 이 시나리오에서는 대부분의 작업 기간 동안 일부 작업자의 CPU 사용률이 높습니다. 하지만 작업자 수가 최대 허용 수에 도달하지 않습니다. 단축키와 가능한 해결책에 대한 자세한 내용은 확장성을 염두에 둔 Dataflow 파이프라인 작성을 참조하세요.
이 문제에 대한 추가 해결책은 단축키가 감지됨을 참조하세요.
Python: 전역 인터프리터 잠금(GIL)
Python 코드가 Python 확장 프로그램 메커니즘을 사용하여 C/C++ 코드를 호출하는 경우 확장 프로그램 코드가 Python 상태에 액세스하지 않는 컴퓨팅 집약적인 코드 부분에서 Python 전역 인터프리터 잠금(GIL)을 해제하는지 확인합니다. GIL이 장시간 출시되지 않으면 Unable to retrieve status info from SDK harness <...> within allowed time 및 SDK worker appears to be permanently unresponsive. Aborting the SDK 같은 오류 메시지가 표시될 수 있습니다.
Cython 및 PyBind 같은 확장 프로그램과의 상호작용을 용이하게 하는 라이브러리에는 GIL 상태를 제어하는 기본 요소가 있습니다. 또한 Py_BEGIN_ALLOW_THREADS 및 Py_END_ALLOW_THREADS 매크로를 사용하여 Python 인터프리터에 제어 권한을 반환하기 전에 GIL을 수동으로 해제하고 다시 획득할 수도 있습니다.
자세한 내용은 Python 문서의 스레드 상태 및 전역 인터프리터 잠금을 참조하세요.
다음과 같이 실행 중인 Dataflow 작업자에서 GIL을 보유하고 있는 스레드의 스택 트레이스를 검색할 수 있습니다.
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
Python 파이프라인의 기본 구성에서 Dataflow는 작업자에서 실행되는 각 Python 프로세스가 vCPU 코어 하나를 효율적으로 사용한다고 가정합니다. 파이프라인 코드가 C++에서 구현된 라이브러리를 사용하여 GIL 제한을 우회하는 경우 처리 요소는 2개 이상의 vCPU 코어의 리소스를 사용할 수 있으며 작업자의 CPU 리소스가 충분하지 않을 수 있습니다. 이 문제를 해결하려면 작업자의 스레드 수를 줄이세요.
장기 실행 DoFn 설정
Runner v2를 사용하지 않는 경우 DoFn.Setup에 대한 장기 실행 호출로 인해 다음 오류가 발생할 수 있습니다.
Timed out waiting for an update from the worker
일반적으로 DoFn.Setup 내부에서 시간이 오래 걸리는 작업은 피하세요.
주제에 게시할 때 일시적인 오류가 발생함
스트리밍 작업이 최소 1회 스트리밍 모드를 사용하고 Pub/Sub 싱크에 게시하는 경우 작업 로그에 다음 오류가 표시되었습니까?
There were transient errors publishing to topic
작업이 올바르게 실행된다면 이 오류는 무해하므로 무시해도 됩니다. Dataflow는 백오프 지연을 사용하여 Pub/Sub 메시지 전송을 자동으로 재시도합니다.
키의 토큰이 일치하지 않아 데이터를 가져올 수 없음
다음 오류는 처리 중인 작업 항목이 다른 작업자에게 재할당되었음을 의미합니다.
Unable to fetch data due to token mismatch for key
이 문제는 자동 확장 중에 가장 흔하게 발생하지만 언제든지 발생할 수 있습니다. 영향을 받는 모든 작업은 재시도됩니다. 이 오류는 무시해도 됩니다.
Java 종속 항목 문제
호환되지 않는 클래스 및 라이브러리는 Java 종속 항목 문제를 일으킬 수 있습니다. 파이프라인에 Java 종속 항목 문제가 있으면 다음 오류 중 하나가 발생할 수 있습니다.
NoClassDefFoundError: 이 오류는 런타임 중에 전체 클래스를 사용할 수 없을 때 발생합니다. 일반적인 구성 문제 또는 Beam의 protobuf 버전과 클라이언트에서 생성된 프로토콜 간의 비호환성(예: 이 문제)으로 인해 발생할 수 있습니다.NoSuchMethodError: 이 오류는 클래스 경로의 클래스가 올바른 메서드를 포함하지 않는 버전을 사용하거나 메서드 서명이 변경되었을 때 발생합니다.NoSuchFieldError: 이 오류는 클래스 경로의 클래스가 런타임 중에 필수 필드가 없는 버전을 사용할 때 발생합니다.FATAL ERROR in native method: 이 오류는 기본 제공 종속 항목을 제대로 로드할 수 없을 때 발생합니다. Uber JAR(음영 처리)을 사용할 때는 서명을 사용하는 라이브러리(예: Conscrypt)가 동일한 JAR에 포함되지 않도록 합니다.
파이프라인에 사용자별 코드 및 설정이 포함된 경우 코드에 라이브러리의 여러 버전을 포함할 수 없습니다. 종속 항목 관리 라이브러리를 사용하는 경우 Google Cloud Platform 라이브러리 BOM을 사용하는 것이 좋습니다.
Apache Beam SDK를 사용하는 경우 올바른 라이브러리 BOM을 가져오려면 beam-sdks-java-io-google-cloud-platform-bom을 사용합니다.
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
자세한 내용은 Dataflow에서 파이프라인 종속 항목 관리를 참조하세요.
JDK 17 이상의 InaccessibleObjectException
Java 플랫폼, 표준 에디션 개발 키트(JDK) 버전 17 이상으로 파이프라인을 실행할 때는 작업자 로그 파일에 다음 오류가 표시될 수 있습니다.
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
이 문제는 Java 버전 9부터 시작하여 JDK 내부 요소에 액세스하기 위해 개방형 모듈 Java 가상 머신(JVM) 옵션이 필요하기 때문에 발생합니다. Java 16 이상 버전에서는 JDK 내부 요소에 액세스하기 위해 항상 개방형 모듈 JVM 옵션이 필요합니다.
이 문제를 해결하기 위해서는 Dataflow 파이프라인으로 모듈을 전달할 때 jdkAddOpenModules 파이프라인 옵션과 함께 MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* 형식을 사용합니다. 이 형식을 사용하면 필요한 라이브러리에 액세스할 수 있습니다.
예를 들어 오류가 module java.base does not "opens java.lang" to unnamed module @...이면 파이프라인을 실행할 때 다음 파이프라인 옵션을 포함합니다.
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
자세한 내용은 DataflowPipelineOptions 클래스 문서를 참조하세요.
작업 항목 진행률 오류 보고
Java 파이프라인의 경우 Runner V2를 사용하지 않으면 다음 오류가 표시될 수 있습니다.
Error reporting workitem progress update to Dataflow service: ...
이 오류는 소스 분할과 같은 작업 항목 진행률 업데이트 중에 처리되지 않은 예외로 인해 발생합니다. 대부분의 경우 Apache Beam 사용자 코드가 처리되지 않은 예외를 발생시키면 작업 항목이 실패하여 파이프라인이 실패합니다. 하지만 Source.split의 예외는 코드의 해당 부분이 작업 항목 외부에 있기 때문에 억제됩니다. 따라서 오류 로그만 기록됩니다.
이 오류는 간헐적으로만 발생하는 경우 일반적으로 무해합니다. 하지만 Source.split 코드 내에서 예외를 적절하게 처리하는 것이 좋습니다.
BigQuery 커넥터 오류
다음 섹션에서는 발생할 수 있는 일반적인 BigQuery 커넥터 오류와 오류 해결 단계를 설명합니다.
quotaExceeded
스트리밍 삽입을 사용하여 BigQuery에 쓰기 위해 BigQuery 커넥터를 사용 중이며 쓰기 처리량이 예상보다 적으면 다음 문제가 발생할 수 있습니다.
quotaExceeded
파이프라인이 사용 가능한 BigQuery 스트리밍 삽입 할당량을 초과하여 처리량이 느려질 수 있습니다. 이 경우 BigQuery의 할당량 관련 오류 메시지가 Dataflow 작업자 로그에 표시됩니다(quotaExceeded 오류 확인).
quotaExceeded 오류가 표시되는 경우 이 문제를 해결하려면 다음 안내를 따르세요.
- Java용 Apache Beam SDK를 사용하는 경우 BigQuery 싱크 옵션
ignoreInsertIds()를 설정합니다. - Python용 Apache Beam SDK를 사용하는 경우
ignore_insert_ids옵션을 사용합니다.
이 설정을 사용하면 프로젝트당 1GB/초의 BigQuery 스트리밍 삽입 처리량을 사용할 수 있습니다. 자동 메시지 중복 제거와 관련된 주의사항에 대한 자세한 내용은 BigQuery 문서를 참조하세요. BigQuery 스트리밍 삽입 할당량을 1GBps 이상으로 늘리려면 Google Cloud 콘솔을 통해 요청을 제출하세요.
작업자 로그에 할당량 관련 오류가 표시되지 않는 경우 기본 번들링 또는 일괄 처리 관련 파라미터가 파이프라인을 확장하기에 충분한 동시 로드를 제공하지 못하는 것일 수 있습니다. 스트리밍 삽입을 사용하여 BigQuery에 작성할 때 예상되는 성능을 얻으려면 몇 가지 Dataflow BigQuery 커넥터 관련 구성을 조정하면 됩니다. 예를 들어 Java용 Apache Beam SDK의 경우 최대 작업자 수에 맞게 numStreamingKeys를 조정하고 insertBundleParallelism을 늘려서 BigQuery 커넥터가 더 많은 병렬 스레드를 사용하여 BigQuery에 작성하도록 구성하는 것이 좋습니다.
Java용 Apache Beam SDK에서 사용할 수 있는 구성은 BigQueryPipelineOptions를 참조하고 Python용 Apache Beam SDK에서 사용할 수 있는 구성은 WriteToBigQuery 변환을 참조하세요.
rateLimitExceeded
BigQuery 커넥터를 사용하면 다음 오류가 발생합니다.
rateLimitExceeded
이 오류는 짧은 기간 동안 BigQuery에 너무 많은 API 요청이 전송되는 경우에 발생합니다. BigQuery에는 단기 할당량 한도가 있습니다.
Dataflow 파이프라인이 이러한 할당량을 일시적으로 초과할 수 있습니다. 이 시나리오에서 Dataflow 파이프라인에서 BigQuery로의 API 요청이 실패할 수 있으며 이로 인해 작업자 로그에 rateLimitExceeded 오류가 발생할 수 있습니다.
Dataflow는 이러한 실패에 대해 다시 시도하므로 이 오류를 무시해도 됩니다. 파이프라인이 rateLimitExceeded 오류의 영향을 받는다고 생각되면 Cloud Customer Care에 문의하세요.
기타 오류
다음 섹션에는 발생 가능한 기타 오류와 오류 해결 또는 문제 해결을 위한 단계가 포함되어 있습니다.
sha384를 할당할 수 없음
작업이 올바르게 실행되지만 작업 로그에 다음 오류가 표시됩니다.
ima: Can not allocate sha384 (reason: -2)
작업이 올바르게 실행된다면 이 오류는 무해하므로 무시해도 됩니다. 작업자 VM 기본 이미지에서 이 메시지가 표시되는 경우가 있습니다. Dataflow는 근본 문제에 자동으로 대응하고 해결합니다.
이 메시지 수준을 WARN에서 INFO로 변경하는 기능 요청이 있습니다. 자세한 내용은 Dataflow 시스템 실행 오류 로그 수준을 WARN 또는 INFO로 낮추기를 참조하세요.
동적 플러그인 프로버 초기화 오류
작업이 올바르게 실행되지만 작업 로그에 다음 오류가 표시됩니다.
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
작업이 올바르게 실행된다면 이 오류는 무해하므로 무시해도 됩니다. 이 오류는 Dataflow 작업에서 필요한 쓰기 권한 없이 디렉터리를 만들려고 하여 태스크가 실패할 때 발생합니다. 작업이 성공하면 디렉터리가 필요하지 않았거나 Dataflow에서 근본 문제를 해결한 것입니다.
이 메시지 수준을 WARN에서 INFO로 변경하는 기능 요청이 있습니다. 자세한 내용은 Dataflow 시스템 실행 오류 로그 수준을 WARN 또는 INFO로 낮추기를 참조하세요.
해당 객체 없음: pipeline.pb
JOB_VIEW_ALL 옵션을 사용하여 작업을 나열하면 다음 오류가 발생합니다.
No such object: BUCKET_NAME/PATH/pipeline.pb
이 오류는 작업의 스테이징 파일에서 pipeline.pb 파일을 삭제하면 발생할 수 있습니다.
포드 동기화 건너뛰기
작업이 올바르게 실행되지만 작업 로그에 다음 오류 중 하나가 표시됩니다.
Skipping pod synchronization" err="container runtime status check may not have completed yet"
또는
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
작업이 올바르게 실행되면 이러한 오류는 무해하므로 무시해도 됩니다.
container runtime status check may not have completed yet 메시지는 Kubernetes kubelet에서 컨테이너 런타임이 초기화될 때까지 기다림으로 인해 포드 동기화를 건너뛰는 경우에 발생합니다. 이 시나리오는 컨테이너 런타임이 최근에 시작되었거나 다시 시작되는 경우와 같이 다양한 이유로 발생합니다.
PLEG is not healthy: pleg has yet to be successful이 포함된 메시지인 경우, kubelet은 포드를 동기화하기 전에 포드 수명 주기 이벤트 생성기(PLEG)가 정상이 될 때까지 기다립니다. PLEG는 Kubelet에서 포드 상태를 추적하는 데 사용하는 이벤트를 생성합니다.
이 메시지 수준을 WARN에서 INFO로 변경하는 기능 요청이 있습니다. 자세한 내용은 Dataflow 시스템 실행 오류 로그 수준을 WARN 또는 INFO로 낮추기를 참조하세요.
권장사항
Dataflow Insights에서 생성하는 권장사항에 대한 안내는 Insights를 참조하세요.