如果您在使用 Dataflow 流水线或作业时遇到问题,本页面列出了您可能会看到的错误消息,并提供了有关如何修复每个错误的建议。
日志类型 dataflow.googleapis.com/worker-startup、dataflow.googleapis.com/harness-startup 和 dataflow.googleapis.com/kubelet 中的错误表明作业存在配置问题。还可能表示存在导致正常日志记录路径无法正常使用的条件。
您的流水线在处理数据时可能会抛出异常。其中一些错误是暂时性的,例如暂时无法访问外部服务。其中一些错误是永久性的,例如因输入数据损坏或无法解析引发的错误,或者计算期间的 NULL 指针。
Dataflow 会处理任意软件包中的元素,并会在针对该软件包中的任何元素抛出错误时重试整个软件包。以批量模式运行时,含有失败项的软件包将重试四次。单个软件包失败四次后,流水线会完全失败。以流处理模式运行时,含有失败项的软件包会无限地重试,这可能会导致您的流水线永久性停滞。
Dataflow 监控界面会报告用户代码(例如 DoFn 实例)中的异常。
如果使用 BlockingDataflowPipelineRunner 运行流水线,您还可在控制台或终端窗口中看到输出的错误消息。
考虑通过添加异常处理程序来防止代码中的错误。例如,如果您因为某些元素未能通过在 ParDo 中执行的一些自定义输入验证而要舍弃它们,请在 ParDo 中使用 try/catch 块,以便处理异常并记录和舍弃这些元素。对于生产工作负载,请实现未处理的消息模式。如需跟踪错误计数,请使用聚合转换。
缺失日志文件
如果您没有看到作业的任何日志,请从所有 Cloud Logging 日志路由器接收器中移除任何包含 resource.type="dataflow_step" 的排除项过滤条件。
如需详细了解如何移除日志排除项,请参阅移除排除项指南。
输出中的重复项
运行 Dataflow 作业时,输出包含重复的记录。
当 Dataflow 作业使用“至少一次”流水线流处理模式时,可能会出现此问题。此模式可保证记录至少被处理一次。但是,此模式下可能存在重复的记录。
如果您的工作流不能容忍重复的记录,请使用“正好一次”流处理模式。此模式有助于确保在数据通过流水线时,系统不会删除或重复记录。
如需验证您的作业使用的是哪种流处理模式,请参阅查看作业的流处理模式。
如需详细了解流处理模式,请参阅设置流水线流处理模式。
流水线错误
以下部分介绍了您可能会遇到的常见流水线错误,以及解决或排查这些错误的步骤。
某些 Cloud API 需要启用
尝试运行 Dataflow 作业时,会发生以下错误:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
出现此问题的原因是项目中未启用某些必需的 API。
要解决此问题并运行 Dataflow 作业,请在项目中启用以下Google Cloud API:
- Compute Engine API (Compute Engine)
- Cloud Logging API
- Cloud Storage
- Cloud Storage JSON API
- BigQuery API
- Pub/Sub
- Datastore API
如需了解详细说明,请参阅有关启用 Google Cloud API 的“使用入门”部分。
“@*”和“@N”是预留的分片规范
尝试运行作业时,日志文件中会显示以下错误,并且作业会失败:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
如果临时文件(tempLocation 或 temp_location)的 Cloud Storage 路径文件名包含符号 (@) 后跟数字或星号 (*),则会发生此错误。
如需解决此问题,请更改文件名,使其在符号后跟支持的字符。
错误请求
当您运行 Dataflow 作业时,Cloud Monitoring 日志显示如下所示的一系列警告:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
如果工作器状态信息因处理延迟而过时或不同步,则会出现错误请求警告。通常情况下,尽管出现错误请求警告,Dataflow 作业仍会成功。如果出现这种情况,请忽略此类警告。
无法在不同位置执行读写操作
运行 Dataflow 作业时,您可能会在日志文件中看到以下错误:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
当来源和目标位于不同的区域时,会发生此错误。当暂存位置和目标位置位于不同区域时,也可能发生此错误。例如,如果作业从 Pub/Sub 读取数据,将数据写入 Cloud Storage temp 存储桶,然后再写入 BigQuery 表,则 Cloud Storage temp 存储桶和 BigQuery 表必须位于同一区域。
多区域和单区域被视为不同的位置,即使单区域位置在多区域位置范围内也是如此。例如,us (multiple regions in the United States) 和 us-central1 是不同的区域。
要解决此问题,请将目标位置、来源位置和暂存位置设置在同一区域。Cloud Storage 存储桶位置无法更改,因此您可能需要在正确的区域中创建新的 Cloud Storage 存储桶。
连接超时
运行 Dataflow 作业时,您可能会在日志文件中看到以下错误:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
当 Dataflow 工作器无法建立或维护与数据源或目标的连接时,就会出现此问题。
要解决此问题,请按以下问题排查步骤操作:
无此类对象
运行 Dataflow 作业时,您可能会在日志文件中看到以下错误:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
如果某些正在运行的 Dataflow 作业使用同一个 temp_location 来暂存流水线运行时创建的临时作业文件,则通常会发生这些错误。如果多个并发作业共享相同的 temp_location,则这些作业可能会互相执行临时数据,并且可能会出现竞态条件。为避免此问题,建议您为每个作业使用唯一的 temp_location。
Dataflow 无法确定积压
从 Pub/Sub 运行流式流水线时,会出现以下警告:
Dataflow is unable to determine the backlog for Pub/Sub subscription
当 Dataflow 流水线从 Pub/Sub 中拉取数据时,Dataflow 需要反复向 Pub/Sub 请求信息。此信息包括订阅的积压量以及最早的未确认消息的存在时间。有时,Dataflow 会因内部系统问题而无法从 Pub/Sub 中检索此信息,这可能会导致积压暂时累积。
如需了解详情,请参阅使用 Cloud Pub/Sub 进行流式传输。
DEADLINE_EXCEEDED 或服务器无响应
运行作业时,您可能会遇到 RPC 超时异常或以下错误之一:
DEADLINE_EXCEEDED
或:
Server Unresponsive
这些错误通常是由于以下某种原因造成的:
用于您的作业的 Virtual Private Cloud (VPC) 网络可能缺少防火墙规则。防火墙规则需要允许您在流水线选项中指定的 VPC 网络的虚拟机之间的所有 TCP 流量。如需了解详情,请参阅 Dataflow 的防火墙规则。
在某些情况下,工作器无法相互通信。当您运行不使用 Dataflow Shuffle 或 Streaming Engine 的 Dataflow 作业时,工作器需要使用 VPC 网络中的 TCP 端口
12345和12346相互通信。在这种情况下,错误包括工作器 harness 名称和被屏蔽的 TCP 端口。错误类似于以下示例之一:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)如需解决此问题,请使用
gcloud compute firewall-rules create规则标志来允许发送到端口12345和12346的网络流量。以下示例展示了 Google Cloud CLI 命令:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346请替换以下内容:
FIREWALL_RULE_NAME:防火墙规则的名称NETWORK:网络的名称
您的作业受 shuffle 限制。
如需解决此问题,请进行以下一项或多项更改。
Java
- 如果作业未使用基于服务的 Shuffle,请设置
--experiments=shuffle_mode=service以切换到使用基于服务的 Dataflow Shuffle。如需了解详情和可用性,请参阅 Dataflow Shuffle。 - 添加更多工作器。在运行流水线时尝试设置具有更高值的
--numWorkers。 - 增加工作器挂接的磁盘的大小。在运行流水线时尝试设置具有更高值的
--diskSizeGb。 - 使用支持 SSD 的永久性磁盘。在运行流水线时尝试设置
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"。
Python
- 如果作业未使用基于服务的 Shuffle,请设置
--experiments=shuffle_mode=service以切换到使用基于服务的 Dataflow Shuffle。如需了解详情和可用性,请参阅 Dataflow Shuffle。 - 添加更多工作器。在运行流水线时尝试设置具有更高值的
--num_workers。 - 增加工作器挂接的磁盘的大小。在运行流水线时尝试设置具有更高值的
--disk_size_gb。 - 使用支持 SSD 的永久性磁盘。在运行流水线时尝试设置
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"。
Go
- 如果作业未使用基于服务的 Shuffle,请设置
--experiments=shuffle_mode=service以切换到使用基于服务的 Dataflow Shuffle。如需了解详情和可用性,请参阅 Dataflow Shuffle。 - 添加更多工作器。在运行流水线时尝试设置具有更高值的
--num_workers。 - 增加工作器挂接的磁盘的大小。在运行流水线时尝试设置具有更高值的
--disk_size_gb。 - 使用支持 SSD 的永久性磁盘。在运行流水线时尝试设置
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"。
- 如果作业未使用基于服务的 Shuffle,请设置
用户代码中的编码错误、IO 异常或意外行为
Apache Beam SDK 和 Dataflow 工作器依赖于常见的第三方组件。而这些组件又会导入其他依赖项。版本冲突可能导致服务出现意外行为。此外,某些库不向前兼容。因此您可能需要在执行过程的范围内固定使用列明的版本。SDK 和工作器依赖项包含依赖项及其所需版本的列表。
运行 LookupEffectiveGuestPolicies 时出错
运行 Dataflow 作业时,您可能会在日志文件中看到以下错误:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
如果为整个项目启用了 OS Configuration Management,则会发生此错误。
要解决此问题,请停用应用于整个项目的虚拟机管理器政策。如果无法为整个项目停用虚拟机管理器政策,您可以放心地忽略此错误并将其从日志监控工具中过滤掉。
Java 运行时环境检测到严重错误
工作器启动期间,系统会发生以下错误:
A fatal error has been detected by the Java Runtime Environment
如果流水线使用 Java 原生接口 (JNI) 运行非 Java 代码,并且该代码或 JNI 绑定包含错误,则系统会发生此错误。
googclient_deliveryattempt 属性键错误
您的 Dataflow 作业失败,并显示以下错误之一:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
或:
Invalid extensions name: googclient_deliveryattempt
如果您的 Dataflow 作业具有以下特征,则会出现此错误:
- Dataflow 作业使用 Streaming Engine。
- 流水线具有 Pub/Sub 接收器。
- 该流水线使用拉取订阅。
- 该流水线使用其中一个 Pub/Sub 服务 API 来发布消息,而不是使用内置的 Pub/Sub I/O 接收器。
- Pub/Sub 使用 Java 或 C# 客户端库。
- Pub/Sub 订阅具有死信主题。
发生此错误的原因是如果您使用 Pub/Sub Java 或 C# 客户端库并启用订阅的死信主题,则传送尝试会在 googclient_deliveryattempt 消息属性中,而不是在 delivery_attempt 字段中。如需了解详情,请参阅“处理消息失败”页面中的跟踪传送尝试。
如需解决此问题,请进行以下一项或多项更改。
- 停用 Streaming Engine。
- 使用内置的 Apache Beam
PubSubIO连接器,而不是 Pub/Sub 服务 API。 - 使用其他类型的 Pub/Sub 订阅。
- 移除死信主题。
- 请勿将 Java 或 C# 客户端库与 Pub/Sub 拉取订阅搭配使用。如需了解其他选项,请参阅客户端库代码示例。
- 在流水线代码中,当属性键以
goog开头时,请先清空消息属性,然后再发布消息。
检测到热键 ...
发生以下错误:
A hot key HOT_KEY_NAME was detected in...
如果您的数据包含热键,则会发生这些错误。热键是具有很多元素并对流水线性能造成不利影响的键。这些键会限制 Dataflow 并行处理元素的能力,从而增加执行时间。
如需在流水线中检测到热键时将简单易懂的键输出到日志,请使用热键流水线选项。
要解决此问题,请检查您的数据是否均匀分布。如果某个键具有异常多的值,请考虑执行以下操作流程:
- 重新生成数据键。应用
ParDo转换来输出新的键值对。 - 对于 Java 作业,请使用
Combine.PerKey.withHotKeyFanout转换。 - 对于 Python 作业,请使用
CombinePerKey.with_hot_key_fanout转换。 - 启用 Dataflow Shuffle。
如需在 Dataflow 监控界面中查看热键,请参阅排查批量作业中的 Straggler 问题。
Data Catalog 中的表规范无效
使用 Dataflow SQL 创建 Dataflow SQL 作业时,作业可能会失败,并且日志文件中会显示以下错误:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
如果 Dataflow 服务账号无权访问 Data Catalog API,则会发生此错误。
为解决此问题,请在您用于编写和运行查询的 Google Cloud项目中启用 Data Catalog API。
或者,将 roles/datacatalog.viewer 角色分配给 Dataflow 服务账号。
作业图过大
您的作业可能会失败,并显示以下错误:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
如果作业的图大小超过 10 MB,则会出现此错误。流水线中的某些情况可能会导致作业图超出此上限。常见情况包括:
- 包含大量内存数据的
Create转换。 - 大型
DoFn实例(进行序列化处理后传输给远程工作器)。 - 作为匿名内部类实例的
DoFn,该实例(可能无意中)引入了大量要序列化的数据。 - 在枚举大型列表的编程循环中使用有向无环图 (DAG)。
为了避免这些情况,请考虑重新构造您的流水线。
密钥提交过大
运行流处理作业时,工作器日志文件中会显示以下错误:
KeyCommitTooLargeException
如果在不使用 Combine 转换的情况下将大量数据分组,或者如果通过单个输入元素生成大量数据,则在流式传输场景中会发生此错误。
为了降低发生此错误的可能性,请使用以下策略:
- 确保处理单个元素不会导致输出或状态修改超出限制。
- 如果按一个键分组了多个元素,请考虑增加键空间以减少按键分组的元素。
- 如果某个键的元素在短时间内以高频率发出,这可能会导致在时间范围内产生该键的大量事件(以 GB 为单位)。请重新编写流水线以检测此类键,并仅发出指明相应键在时间范围中频繁出现的输出。
- 使用次线性空间
Combine转换执行交换和关联操作。如果一个组合器不能减少空间,请不要使用它。例如,没有必要使用只是将字符串连接起来的字符串组合器。
拒绝超过 7168K 的消息
当您运行通过模板创建的 Dataflow 作业时,该作业可能会失败,并显示以下错误:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
当写入死信队列的消息超过 7168 K 的大小限制时,会发生此错误。如需解决此问题,请启用 Streaming Engine,其大小限制更高。如需启用 Streaming Engine,请使用以下流水线选项。
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
Request Entity Too Large
提交作业时,控制台或终端窗口中显示以下错误之一:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
如果在提交作业时出现有关 JSON 载荷的错误,则流水线的 JSON 表示法会超过 20 MB 的请求大小上限。
作业的大小与流水线的 JSON 表示法关联。流水线越大,意味着请求越大。Dataflow 的请求大小上限为 20 MB。
如需估算流水线的 JSON 请求大小,请使用以下选项运行流水线:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go 不支持以 JSON 格式输出作业。
此命令会将作业的 JSON 表示写入文件中。您最好根据序列化文件的大小来估算请求大小。由于请求中包含一些其他信息,实际大小将会略大一些。
流水线中的某些情况可能会导致 JSON 表示法超出限额。常见情况包括:
- 包含大量内存数据的
Create转换。 - 大型
DoFn实例(进行序列化处理后传输给远程工作器)。 - 作为匿名内部类实例的
DoFn,该实例(可能无意中)引入了大量要序列化的数据。
为了避免这些情况,请考虑重新构造您的流水线。
SDK 流水线选项或暂存文件列表超出大小限制
运行流水线时,发生以下错误之一:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
或:
Value for field 'resource.properties.metadata' is too large: maximum size
如果由于超出 Compute Engine 元数据限制而无法启动流水线,则会出现这些错误。这些限制不能更改。Dataflow 为流水线选项使用 Compute Engine 元数据。Compute Engine 自定义元数据限制中记录了此限制。
以下情况可能会导致 JSON 表示法超出限制:
- 要暂存的 JAR 文件过多。
sdkPipelineOptions请求字段过大。
如需估算流水线的 JSON 请求大小,请使用以下选项运行流水线:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go 不支持以 JSON 格式输出作业。
此命令的输出文件的大小必须小于 256 KB。错误消息中的 512 KB 是指输出文件的总大小和 Compute Engine 虚拟机实例的自定义元数据选项。
您可以通过项目中正在运行的 Dataflow 作业来粗略估计虚拟机实例的自定义元数据选项。选择任何正在运行的 Dataflow 作业。获取虚拟机实例,然后导航到该虚拟机的 Compute Engine 虚拟机实例详情页面,以检查自定义元数据部分。自定义元数据和文件的总长度应小于 512 KB。无法准确估计失败的作业,因为虚拟机不会为失败的作业启动。
如果您的 JAR 列表达到了 256-KB 的限制,请进行检查并减少任何不必要的 JAR 文件。如果该列表仍然过大,请尝试使用超级 JAR 运行 Dataflow 作业。如需查看演示如何创建和使用超级 JAR 的示例,请参阅构建和部署超级 JAR。
如果 sdkPipelineOptions 请求字段过大,请在运行流水线时包括以下选项。该流水线选项在 Java、Python 和 Go 中是相同的。
--experiments=no_display_data_on_gce_metadata
重排键过大
工作器日志文件中出现以下错误:
Shuffle key too large
在应用相应编码器后,如果发送到特定 (Co-)GroupByKey 的序列化键太大,则会出现此错误。Dataflow 对序列化 shuffle 键有限制。
如需解决此问题,请减小键的大小或使用更节省空间的编码器。
如需了解详情,请参阅 Dataflow 的生产限制。
BoundedSource 对象总数 ... 大于允许的限额
使用 Java 运行作业时,可能会发生以下错误之一:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
或:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
如果您使用经由导出的 TextIO、AvroIO、BigQueryIO 或其他一些基于文件的来源读取大量文件,则可能会出现此错误。特定的上限取决于来源的细节,但一个流水线中大约有数万个文件。例如,在 AvroIO.Read 中嵌入架构可允许较少的文件。
如果您为流水线创建了自定义数据源,并且数据源的 splitIntoBundles 方法返回了一个序列化后超过 20 MB 的 BoundedSource 对象的列表,则也会发生此错误。
自定义来源的 splitIntoBundles() 操作生成的 BoundedSource 对象总大小的允许限额为 20 MB。
如需规避此限制,请进行以下某项更改:
NameError
使用 Dataflow 服务执行流水线时,会发生以下错误:
NameError
本地执行时(例如使用 DirectRunner 执行时),不会发生此错误。
如果 DoFn 使用的全局命名空间中的值在 Dataflow 工作器上不可用,则会出现此错误。
默认情况下,在 Dataflow 作业序列化期间,系统不会保存在主会话中定义的全局导入项、函数和变量。
如需解决此问题,请使用以下方法之一。如果 DoFn 是在主文件中定义的,并且在全局命名空间中引用了导入项和函数,请将 --save_main_session 流水线选项设置为 True。此更改会将全局命名空间的状态 pickle 和加载到 Dataflow 工作器上。
如果全局命名空间中的对象无法进行 pickle,则会出现 pickling 错误。如果此错误与 Python 发行版中应提供的模块有关,请在使用该模块的位置本地导入该模块。
例如,您不应使用以下命令:
import re … def myfunc(): # use re module
而应使用以下命令:
def myfunc(): import re # use re module
或者,如果您的 DoFn 涵盖多个文件,请使用其他方法来封装工作流和管理依赖项。
对象受存储桶的保留政策约束
如果您有写入 Cloud Storage 存储桶的 Dataflow 作业,该作业会失败并显示以下错误:
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
您可能还会看到以下错误:
Unable to rename "gs://BUCKET"
在 Dataflow 作业写入的 Cloud Storage 存储桶上启用对象保留时,会发生第一个错误。如需了解详情,请参阅启用和使用对象保留配置。
为了解决这一问题,请使用以下解决方法之一:
写入
temp文件夹中没有保留政策的 Cloud Storage 存储桶。从作业写入的存储桶中移除保留政策。如需了解详情,请参阅设置对象的保留配置。
第二个错误可能表示在 Cloud Storage 存储桶上启用了对象保留,也可能表示 Dataflow 工作器服务账号无权写入 Cloud Storage 存储桶。
如果您看到第二个错误,并且 Cloud Storage 存储桶已启用对象保留,请尝试之前所述的解决方法。如果 Cloud Storage 存储桶未启用对象保留,请验证 Dataflow 工作器服务账号是否拥有对 Cloud Storage 存储桶的写入权限。如需了解详情,请参阅访问 Cloud Storage 存储桶。
处理停滞或操作正在进行
如果 Dataflow 执行 DoFn 的时间超过 TIME_INTERVAL 中指定的时间且未返回,则系统会显示以下消息。
Java
以下两条日志消息之一,具体取决于版本:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
此行为有两个可能的原因:
DoFn代码运行很慢,或在等待一些缓慢的外部操作完成。- 您的
DoFn代码可能被卡住、出现死锁或运行异常缓慢,难以完成处理。
如需确定是哪种情况,请展开 Cloud Monitoring 日志条目以查看堆栈轨迹。查找表明 DoFn 代码卡住或出现其他问题的消息。如果不存在消息,则可能是 DoFn 代码的执行速度有问题。请考虑使用 Cloud Profiler 或其他工具来调查代码的性能。
如果您的流水线是在 Java 虚拟机上构建的(使用 Java 或 Scala),您可以调查代码卡住的原因。按照以下步骤对整个 JVM(不仅仅是卡住的线程)进行完整的线程转储:
- 记下日志条目中的工作器名称。
- 在 Google Cloud 控制台的 Compute Engine 部分,使用您记下的工作器名称来寻找 Compute Engine 实例。
- 使用 SSH 连接到具有该名称的实例。
运行以下命令:
curl http://localhost:8081/threadz
程序包处理中
运行从 JdbcIO 读取的流水线时,从 JdbcIO 进行分区的读取速度较慢,并且工作器日志文件中会显示以下消息:
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
如需解决此问题,请对您的流水线进行以下一项或多项更改:
使用分区来提高作业并行度。使用更多且更小的分区进行读取,以便更好地进行扩缩。
检查分区列是来源中的索引列还是真正的分区列。在源数据库中对此列启用索引编制和分区,以实现最佳性能。
使用
lowerBound和upperBound参数可跳过查找边界。
Pub/Sub 配额错误
从 Pub/Sub 运行流处理流水线时,会出现以下错误:
429 (rateLimitExceeded)
或:
Request was throttled due to user QPS limit being reached
如果您的项目没有足够的 Pub/Sub 配额,则会出现这些错误。
要了解您的项目是否配额不足,请按照以下步骤检查客户端错误:
- 前往Google Cloud 控制台。
- 在左侧菜单中,选择 API 和服务。
- 在搜索框中,搜索 Cloud Pub/Sub。
- 点击用量标签页。
- 检查响应代码并查找
(4xx)客户端错误代码。
组织的政策禁止请求
运行流水线时,会发生以下错误:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
如果 Cloud Storage 存储桶位于服务边界外部,则会出现此错误。
如需解决此问题,请创建出站规则以允许访问服务边界外的存储桶。
暂存的软件包...无法访问
过去成功的作业可能会失败,并显示以下错误:
Staged package...is inaccessible
要解决此问题,请执行以下操作:
- 验证用于暂存的 Cloud Storage 存储桶是否没有导致暂存软件包被删除的 TTL 设置。
验证 Dataflow 项目的工作器服务账号有权访问用于暂存的 Cloud Storage 存储桶。权限不足可能是由以下原因造成的:
- 用于暂存的 Cloud Storage 存储桶位于其他项目中。
- 用于暂存的 Cloud Storage 存储桶已从精细访问权限迁移到统一存储桶级访问权限。 由于 IAM 政策与 ACL 政策存在不一致,因此使暂存存储桶改用统一存储桶级访问权限会禁止对 Cloud Storage 资源使用 ACL。ACL 包括 Dataflow 项目的工作器服务账号对暂存存储桶拥有的权限。
如需了解详情,请参阅跨 Google Cloud Platform 项目访问 Cloud Storage 存储桶。
一个工作项失败了 4 次
当批量作业失败时,会发生以下错误:
The job failed because a work item has failed 4 times.
如果批量作业中的单个操作导致工作器代码失败四次,则会出现此错误。Dataflow 使作业失败,并且系统会显示此消息。
以流处理模式运行时,含有失败项的软件包会无限地重试,这可能会导致您的流水线永久性停滞。
您无法配置此失败阈值。如需了解详情,请参阅流水线错误和异常处理。
如需解决此问题,请在作业的 Cloud Monitoring 日志中查看这四次失败情况。在工作器日志中,查找显示异常或错误的错误级别或严重级别日志条目。异常或错误应至少出现四次。如果日志仅包含与访问外部资源(例如 MongoDB)相关的一般性超时错误,请验证工作器服务账号是否有权访问该资源的子网。
轮询结果文件中超时
如需全面了解如何排查“轮询结果文件时超时”错误,请参阅排查 Flex 模板问题。
Write Correct File/Write/WriteImpl/PreFinalize 失败
运行作业时,作业会间歇性失败,并且会发生以下错误:
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
当将同一子文件夹用作并发运行的多个作业的临时存储位置时,会发生此错误。
如需解决此问题,请勿使用与多个流水线的临时存储位置相同的子文件夹。对于每个流水线,请提供一个唯一的子文件夹作为临时存储位置。
元素超出 protobuf 消息大小上限
运行 Dataflow 作业时,如果您的流水线包含大型元素,您可能会看到类似于以下示例的错误:
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
或:
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
您还可能会看到类似于以下示例的警告:
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
如果流水线包含大型元素,就会发生这些错误。
如需解决此问题,如果您使用的是 Python SDK,请升级到 Apache Beam 2.57.0 版或更高版本。Python SDK 2.57.0 及更高版本改进了对大型元素的处理,并添加了相关日志记录。
如果升级后错误仍然存在,或者您未使用 Python SDK,请确定作业中发生错误的步骤,并尝试缩减该步骤中的元素大小。
如果流水线中的 PCollection 对象包含大型元素,则流水线对 RAM 的要求会增加。大型元素也可能会导致运行时错误,尤其是当它们跨越融合阶段的边界时。
当流水线不慎物化大型可迭代对象时,可能会出现大型元素。例如,如果流水线将 GroupByKey 操作的输出传递到不必要的 Reshuffle 操作,则会将列表物化为单个元素。这些列表可能会包含每个键的大量值。
如果使用侧边输入的步骤发生该错误,请注意,使用侧边输入可能会引入融合屏障。检查生成大型元素的转换和使用该元素的转换是否属于同一阶段。
构建流水线时,请遵循以下最佳实践:
- 在
PCollections中,使用多个小元素,而不是单个大型元素。 - 将大型 blob 存储在外部存储系统中。您可以使用
PCollections传递元数据,也可以使用可缩减元素大小的自定义编码器。 - 如果您必须将超过 2 GB 的 PCollection 作为辅助输入传递,请使用可迭代视图,例如
AsIterable和AsMultiMap。
Dataflow 作业中单个元素的大小上限为 2 GB。如需了解详情,请参阅配额和限制。
Dataflow 无法处理托管式转换…
如果 Dataflow 无法将 I/O 转换自动升级至最新的受支持版本,那么使用受管理 I/O 的流水线可能会失败并显示此错误。错误中提供的 URN 和步骤名称应指明 Dataflow 未能升级的确切转换。
您可以在 Logs Explorer 中查看 Dataflow 日志名称 managed-transforms-worker 和 managed-transforms-worker-startup 下的其他详细信息。
如果 Logs Explorer 未提供足够的信息来排查错误,请与 Cloud Customer Care 联系。
归档作业错误
以下部分介绍了您尝试使用 API 归档 Dataflow 作业时可能会遇到的常见错误。
未提供值
尝试使用 API 归档 Dataflow 作业时,可能会发生以下错误:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
发生此错误是由以下某种原因造成的:
为
updateMask字段指定的路径未采用正确的格式。此问题可能是由拼写错误造成的。未正确指定
JobMetadata。在JobMetadata字段中,对于userDisplayProperties,请使用键值对"archived":"true"。
如需解决此错误,请验证您传递给 API 的命令匹配所需的格式。如需了解详情,请参阅归档作业。
API 无法识别值
尝试使用 API 归档 Dataflow 作业时,可能会发生以下错误:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
当归档作业键值对中提供的值不受支持时,就会发生此错误。归档作业键值对支持的值为 "archived":"true" 和 "archived":"false"。
如需解决此错误,请验证您传递给 API 的命令匹配所需的格式。如需了解详情,请参阅归档作业。
无法同时更新状态和掩码
尝试使用 API 归档 Dataflow 作业时,可能会发生以下错误:
Cannot update both state and mask.
如果您尝试在同一 API 调用中同时更新作业状态和归档状态,则会发生此错误。您不能在同一 API 调用中同时更新作业状态和 updateMask 查询参数。
如需解决此错误,请在另一个 API 调用中更新作业状态。请先更新作业状态,然后再更新作业归档状态。
工作流修改失败
尝试使用 API 归档 Dataflow 作业时,可能会发生以下错误:
Workflow modification failed.
此错误通常在您尝试归档正在运行的作业时发生。
如需解决此错误,请等待作业完成后再将它归档。已完成的作业具有以下作业状态之一:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
如需了解详情,请参阅检测 Dataflow 作业的完成情况。
容器映像错误
以下部分介绍了使用自定义容器时您可能会遇到的常见错误,以及解决或排查这些错误的步骤。这些错误通常前面带有以下消息:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
“containeranalysis.occurrences.list”权限遭拒
日志文件中会显示以下错误:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
漏洞扫描需要使用 Container Analysis API。
如需了解详情,请参阅 Artifact Analysis 文档中的操作系统扫描概览和配置访问权限控制。
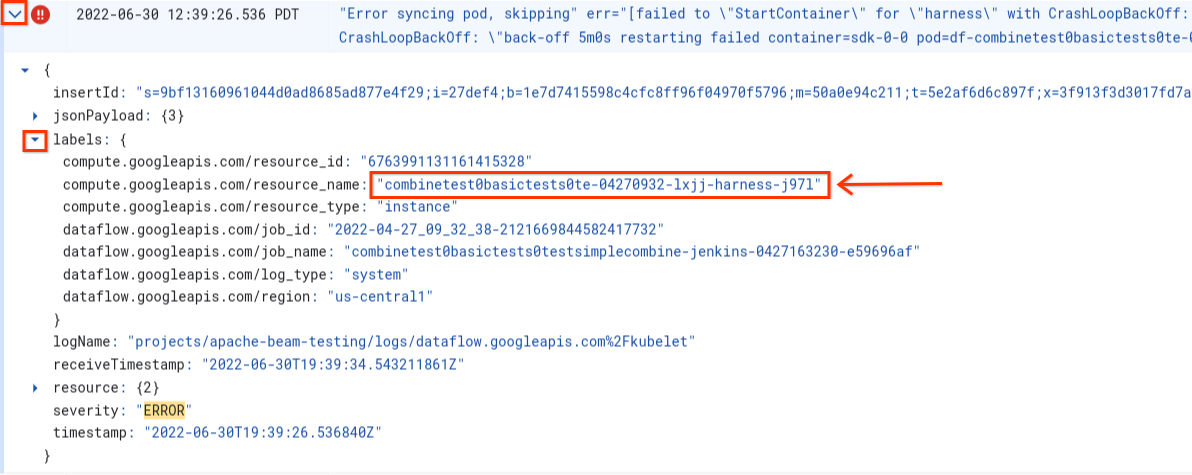
同步 pod 时出错 ...“StartContainer”失败
工作器启动期间,系统会发生以下错误:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
pod 是 Dataflow 工作器上运行的位于同一位置的 Docker 容器组。当 pod 中的一个 Docker 容器无法启动时,会发生此错误。如果故障不可恢复,则 Dataflow 工作器将无法启动,并且 Dataflow 批量作业最终会失败,并显示如下错误:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
某个容器在启动期间连续崩溃时通常会出现此错误。
如需了解根本原因,请查找在失败前立即捕获的日志。如需分析日志,请使用日志浏览器。 在日志浏览器中,将日志文件限制为发生容器启动错误的工作器发出的日志条目。如需限制日志条目,请完成以下步骤:
- 在 Logs Explorer 中,找到
Error syncing pod日志条目。 - 如需查看与日志条目关联的标签,请展开日志条目。
- 点击与
resource_name关联的标签,然后点击显示匹配条目。
在日志浏览器中,Dataflow 日志被整理到多个日志流中。Error syncing pod 消息在名为 kubelet 的日志中发出。但是,来自故障容器的日志可能位于不同的日志流中。每个容器都有一个名称。请使用下表确定哪个日志流可能包含与故障容器相关的日志。
| 容器名称 | 日志名称 |
|---|---|
| sdk、sdk0、sdk1、sdk-0-0 等 | docker |
| harness | harness、harness-startup |
| python、java-batch、java-streaming | worker-startup、worker |
| 工件 | 工件 |
查询日志浏览器时,请确保查询在查询构建器界面中包含相关日志名称,或者对日志名称没有限制。
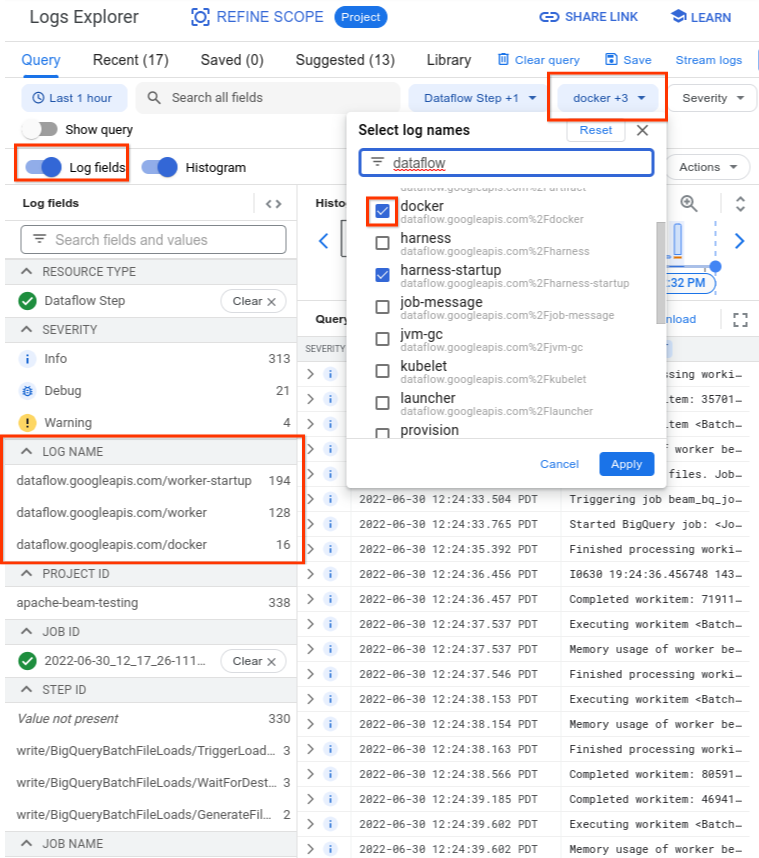
选择相关日志后,查询结果可能如以下示例所示:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
由于报告容器故障症状的日志有时报告为 INFO,因此请在分析中包含 INFO 日志。
容器故障的典型原因包括:
- Python 流水线在运行时安装了其他依赖项,并且安装失败。您可能会看到
pip install failed with error等错误。出现此问题的原因可能是要求存在冲突,或者网络配置受限而导致 Dataflow 工作器无法通过互联网从公共代码库拉取外部依赖项。 由于内存不足错误,工作器在流水线运行过程中失败。您可能会看到如下错误:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
如需调试内存不足问题,请参阅排查 Dataflow 内存不足错误。
Dataflow 无法拉取容器映像。如需了解详情,请参阅映像拉取请求因错误而失败。
使用的容器与工作器虚拟机的 CPU 架构不兼容。在自动化测试框架启动日志中,您可能会看到如下错误:
exec /opt/apache/beam/boot: exec format error。如需查看容器映像的架构,请运行docker image inspect $IMAGE:$TAG并查找Architecture关键字。如果系统显示Error: No such image: $IMAGE:$TAG,您可能需要先运行docker pull $IMAGE:$TAG来拉取映像。 如需了解如何构建多架构映像,请参阅构建多架构容器映像。
在确定导致容器失败的错误后,请尝试解决该错误,然后重新提交流水线。
映像拉取请求失败,发生错误
在工作器启动期间,工作器或作业日志中显示以下错误之一:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
如果工作器因无法拉取 Docker 容器映像而无法启动,则会发生这些错误。此问题发生在以下情况:
- 自定义 SDK 容器映像网址不正确
- 工作器缺少凭据或对远程映像的网络访问权限
要解决此问题,请执行以下操作:
- 如果您为作业使用自定义容器映像,请验证映像网址正确且具有有效的标记或摘要。Dataflow 工作器还需要访问该映像。
- 通过从未经身份验证的机器运行
docker pull $image,验证是否可以在本地拉取公共映像。
对于私有映像或私有工作器:
- 如果您使用 Container Registry 托管容器映像,建议您改为使用 Artifact Registry。自 2023 年 5 月 15 日起,Container Registry 已弃用。如果您使用 Container Registry,则可以转换到 Artifact Registry。如果您的映像所在的项目与用于运行 Google Cloud Platform 作业的项目不同,请为默认 Google Cloud Platform 服务账号配置访问权限控制。
- 如果使用共享 Virtual Private Cloud (VPC),请确保工作器可以访问自定义容器代码库主机。
- 使用
ssh连接到正在运行的作业工作器虚拟机,并运行docker pull $image以直接确认工作器已正确配置。
如果工作器由于错误在行中多次失败,并且在作业上启动了工作,则作业可能会因如下所示的消息而失败:
Job appears to be stuck.
如果您在作业运行时移除了对映像的访问权限(通过移除映像本身,或撤消 Dataflow 工作器服务账号凭据或映像的互联网访问权限),则 Dataflow 仅会记录错误。Dataflow 不会使作业失败。Dataflow 还会避免使长时间运行的流式流水线失败,以避免丢失流水线状态。
其他错误可能是由代码库配额问题或服务中断造成的。 如果您遇到拉取公共映像时超出 Docker Hub 配额或常规第三方仓库服务中断问题,请考虑使用 Artifact Registry 作为映像仓库。
SystemError:未知操作码
您的 Python 自定义容器流水线可能会在作业提交后立即失败,并出现以下错误:
SystemError: unknown opcode
此外,堆栈轨迹可能包括
apache_beam/internal/pickler.py
要解决此问题,请验证您在本地使用的 Python 版本是否与容器映像中的版本匹配(主要版本和次要版本均匹配)。补丁程序版本不同(如 3.6.7 与 3.6.8)不会导致兼容性问题。次要版本不同(例如 3.6.8 与 3.8.2)可能导致流水线失败。
升级流处理流水线错误
如需了解如何解决在升级流处理流水线时(使用运行并行替换作业等功能)出现的错误,请参阅排查流处理流水线升级问题。
Runner v2 自动化测试框架更新
Runner v2 作业的日志中会显示以下信息
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
这意味着,在首次传送消息 7 天后的某个时间点,Runner 自动化测试框架进程的版本将自动更新,导致处理短暂暂停。如果您想控制暂停发生的时间,请参阅更新现有流水线,以启动将包含最新版 Runner 自动化测试框架的替换作业。
工作器错误
以下部分介绍了您可能会遇到的常见工作器错误,以及解决或排查这些错误的步骤。
Java 工作器自动化测试框架对 Python DoFn 的调用失败并显示错误
如果 Java 工作器自动化测试框架对 Python DoFn 的调用失败,则会显示相关错误消息。
如需调查错误,请展开 Cloud Monitoring 错误日志条目并查看错误消息和回溯。它会显示失败的代码,以便您根据需要进行更正。如果您确定错误是 Apache Beam 或 Dataflow 中的错误,请报告错误。
EOFError:编组数据太短
工作器日志中会显示以下错误:
EOFError: marshal data too short
当 Python 流水线工作器的磁盘空间不足时,有时会发生此错误。
要解决此问题,请参阅设备上已没有剩余空间。
未能挂接磁盘
当您尝试启动将 C3 虚拟机与永久性磁盘搭配使用的 Dataflow 作业时,作业会失败并显示以下一个或全部两个错误:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
当您将 C3 虚拟机与不受支持的永久性磁盘类型搭配使用时,会发生这些错误。如需了解详情,请参阅 C3 支持的磁盘类型。
如需将 C3 虚拟机与 Dataflow 作业搭配使用,请选择 pd-ssd 工作器磁盘类型。如需了解详情,请参阅工作器级选项。
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
设备上已没有剩余空间
当作业的磁盘空间用尽时,工作器日志中可能会出现以下错误:
No space left on device
此错误可能是由以下某种原因造成的:
- 工作器永久性存储的可用空间用尽,这可能是由于以下某个原因造成的:
- 作业在运行时下载大型依赖项
- 作业使用大型自定义容器
- 作业将许多临时数据写入本地磁盘
- 使用 Dataflow Shuffle 时,Dataflow 会设置较低的默认磁盘大小。因此,从基于工作器的 shuffle 迁移的作业可能会发生此错误。
- 工作器启动磁盘已满,因为它每秒记录的条目超过 50 个。
要解决此问题,请按以下问题排查步骤操作:
如需查看与单个工作器关联的磁盘资源,请查找与作业关联的工作器虚拟机的虚拟机实例详情。部分磁盘空间供操作系统、二进制文件、日志和容器使用。
要增加永久性磁盘或启动磁盘空间,请调整磁盘大小流水线选项。
使用 Cloud Monitoring 跟踪工作器虚拟机实例上的磁盘可用空间使用情况。如需了解如何进行此设置,请参阅从 Monitoring 代理接收工作器虚拟机指标。
通过在工作器虚拟机实例上查看串行端口输出并查找如下消息来查找启动磁盘空间问题:
Failed to open system journal: No space left on device
如果您有许多工作器虚拟机实例,则可以创建一个脚本,以便同时对所有这些实例运行 gcloud compute instances get-serial-port-output。
您可以改为查看该输出。
Python 流水线在工作器处于非活跃状态一小时后失败
在具有许多 CPU 核心的工作器机器上将 Python 版 Apache Beam SDK 与 Dataflow Runner V2 搭配使用时,请使用 Apache Beam SDK 2.35.0 或更高版本。如果您的作业使用自定义容器,请使用 Apache Beam SDK 2.46.0 或更高版本。
请考虑预构建 Python 容器。此步骤可以缩短虚拟机启动时间和横向自动扩缩性能。如需使用此功能,请在项目上启用 Cloud Build API,并使用以下参数提交流水线:
‑‑prebuild_sdk_container_engine=cloud_build。
如需了解详情,请参阅 Dataflow Runner V2。
您还可以使用预安装了所有依赖项的自定义容器映像。
RESOURCE_POOL_EXHAUSTED
创建 Google Cloud Platform 资源时,会发生以下错误:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
特定可用区中的特定资源的临时缺乏情况会发生此错误。
为解决此问题,您可以等待资源,也可以在另一个可用区创建相同的资源。
作为权宜解决方法,您可以为作业实现重试循环,以便在发生缺货错误时,作业会自动重试,直到资源可用为止。如需创建重试循环,请实现以下工作流:
- 创建 Dataflow 作业并获取作业 ID。
- 轮询作业状态,直到作业状态为
RUNNING或FAILED。- 如果作业状态为
RUNNING,则退出重试循环。 - 如果作业状态为
FAILED,请使用 Cloud Logging API 查询作业日志,查找字符串ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS。如需了解详情,请参阅使用流水线日志。- 如果日志不包含该字符串,则退出重试循环。
- 如果日志包含该字符串,请创建 Dataflow 作业,获取作业 ID,然后重启重试循环。
- 如果作业状态为
我们建议的最佳实践是,将资源分布到多个可用区和区域,以应对服务中断情况。
包含客户机加速器的实例不支持实时迁移
在提交作业时,Dataflow 流水线失败,并显示以下错误:
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
如果您请求了具有硬件加速器的工作器机器类型,但尚未将 Dataflow 配置为使用加速器,则可能会发生此错误。
使用 --worker_accelerator Dataflow 服务选项或 accelerator
资源提示请求硬件加速器。
如果您使用的是 Flex 模板,可以使用 --additionalExperiments 选项来提供 Dataflow 服务选项。如果操作正确,您可以在Google Cloud 控制台的作业信息面板中找到 worker_accelerator 选项。
项目配额 ... 或访问控制政策阻止了操作
发生以下错误:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
发生此错误是由以下某种原因造成的:
- 已超出创建 Dataflow 工作器所依赖的其中一个 Compute Engine 配额。
- 您的组织已设置限制,以禁止虚拟机实例创建过程的某些方面,例如使用账号或以可用区为目标。
要解决此问题,请按以下问题排查步骤操作:
查看虚拟机实例日志
- 转到 Cloud Logging 查看器
- 在已审核的资源下拉列表中,选择虚拟机实例。
- 在所有日志下拉列表中,选择 compute.googleapis.com/activity_log。
- 扫描日志以查找与虚拟机实例创建失败相关的任何条目。
检查 Compute Engine 配额的使用情况
如需查看 Compute Engine 资源使用情况与目标区域的 Dataflow 配额的对比情况,请运行以下命令:
gcloud compute regions describe [REGION]查看以下资源的结果,了解是否有任何资源超出配额:
- CPUS
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
如果需要,请申请更改配额。
查看组织政策限制
- 转到“组织政策”页面
- 查看可能会限制以下行为的限制:限制为您使用的账号(默认为 Dataflow 服务账号)或在您设为目标的可用区中创建虚拟机实例。
- 如果您的政策限制使用外部 IP 地址,请为此作业关闭外部 IP 地址。如需详细了解如何关闭外部 IP 地址,请参阅配置互联网访问权限和防火墙规则。
等待工作器更新时超时
当 Dataflow 作业失败时,会发生以下错误:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
导致此错误的原因有很多,包括:
工作器过载
有时,当工作器的内存或交换空间不足时,会发生超时错误。如需解决此问题,首先请尝试再次运行该作业。如果该作业仍然失败,并且发生相同的错误,请尝试使用内存和磁盘空间更大的工作器。例如,添加以下流水线启动选项:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
更改工作器类型可能会影响结算费用。如需了解详情,请参阅排查 Dataflow 内存不足错误。
如果您的数据包含热键,也可能会发生此错误。在这种情况下,某些工作器的 CPU 利用率在作业的大部分持续时间内都较高。 但是,工作器数量没有达到允许的最大值。如需详细了解热键和可能的解决方案,请参阅编写 Dataflow 流水线时将可伸缩性考虑在内。
如需了解此问题的其他解决方案,请参阅检测到热键...。
Python:全局解释器锁 (GIL)
如果您的 Python 代码使用 Python 扩展程序机制调用 C/C++ 代码,请检查扩展程序代码是否在不访问 Python 状态的计算密集型代码部分中释放 Python 全局解释器锁定 (GIL)。 如果 GIL 长时间未发布,您可能会看到如下错误消息:Unable to retrieve status info from SDK harness <...> within allowed time 和 SDK worker appears to be permanently unresponsive. Aborting the SDK。
辅助与 Cython 和 PyBind 等扩展程序交互的库具有用于控制 GIL 状态的原语。您还可以使用 Py_BEGIN_ALLOW_THREADS 和 Py_END_ALLOW_THREADS 宏,手动释放 GIL 并重新获取它,然后再将控制权返还给 Python 解释器。如需了解详情,请参阅 Python 文档中的线程状态和全局解释器锁定。
可以检索正在运行的 Dataflow 工作器上持有 GIL 的线程的堆栈轨迹,如下所示:
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
在 Python 流水线的默认配置中,Dataflow 假定工作器上运行的每个 Python 进程都高效使用一个 vCPU 核心。如果流水线代码绕过 GIL 限制(例如使用通过 C++ 实现的库),则处理元素可能会使用来自多个 vCPU 核心的资源,并且工作器可能无法获取足够的 CPU 资源。如需解决此问题,请在工作器上减少线程数。
长时间运行的 DoFn 设置
如果您未使用 Runner v2,对 DoFn.Setup 的长时间运行调用可能会导致以下错误:
Timed out waiting for an update from the worker
一般而言,请避免在 DoFn.Setup 中执行耗时的操作。
发布到主题时出现暂时性错误
当流处理作业使用“至少一次”流处理模式并发布到 Pub/Sub 接收器时,作业日志中会显示以下错误:
There were transient errors publishing to topic
如果作业正确运行,则此错误是良性的,您可以忽略它。Dataflow 会自动重试发送 Pub/Sub 消息,并使用退避延迟。
由于密钥的令牌不匹配,无法提取数据
以下错误表示正在处理的工作项已重新分配给其他工作器:
Unable to fetch data due to token mismatch for key
这种情况最常发生在自动扩缩期间,但随时都有可能发生。所有受影响的工作都将重试。您可以忽略此错误。
Java 依赖项问题
不兼容的类和库可能会导致 Java 依赖项问题。如果您的流水线存在 Java 依赖项问题,则可能会发生以下错误之一:
NoClassDefFoundError:如果在运行时整个类都不可用,就会出现此错误。 这可能是由于常规配置问题或 Beam 的 protobuf 版本与客户端生成的 proto 之间的不兼容导致的(例如,此问题)。NoSuchMethodError:如果类路径中的类使用不包含正确方法的版本或者方法签名发生变化,就会出现此错误。NoSuchFieldError:如果类路径中的类在运行时使用没有必需字段的版本,就会出现此错误。FATAL ERROR in native method:当无法正确加载内置依赖项时,会发生此错误。 使用超级 JAR(阴影)时,请勿在同一 JAR 中包含使用签名的库(如 Conscrypt)。
如果您的流水线包含特定于用户的代码和设置,则代码不能包含混合版本的库。如果您使用的是依赖项管理库,我们建议您使用 Google Cloud Platform 库 BOM。
如果您使用的是 Apache Beam SDK,如需导入正确的库 BOM,请使用 beam-sdks-java-io-google-cloud-platform-bom:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
如需了解详情,请参阅在 Dataflow 中管理流水线依赖项。
JDK 17 及更高版本中的 InaccessibleObjectException
使用 Java Platform, Standard Edition Development Kit (JDK) 17 版及更高版本运行流水线时,工作器日志文件中可能会出现以下错误:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
出现此问题的原因是,从 Java 9 版开始,需要开放模块 Java 虚拟机 (JVM) 选项才能访问 JDK 内部内容。在 Java 16 及更高版本中,始终需要开放模块 JVM 选项才能访问 JDK 内部内容。
如需解决此问题,请在将模块传递给要打开的 Dataflow 流水线时,结合使用 MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* 格式和 jdkAddOpenModules 流水线选项。此格式允许访问必要的库。
例如,如果错误是 module java.base does not "opens java.lang" to unnamed module @...,则在运行流水线时添加以下流水线选项:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
如需了解详情,请参阅 DataflowPipelineOptions 类文档。
报告工作项进度时出错
对于 Java 流水线,如果您未使用 Running V2,可能会看到以下错误:
Error reporting workitem progress update to Dataflow service: ...
此错误是由工作项进度更新期间(例如在拆分来源期间)的未处理异常引起的。在大多数情况下,如果 Apache Beam 用户代码抛出未处理的异常,则工作项会失败,导致流水线失败。不过,Source.split 中的异常会被抑制,因为该代码部分不在工作项中。因此,系统仅会记录错误日志。
如果此错误仅偶尔发生,通常不会造成任何影响。不过,请考虑在 Source.split 代码中优雅地处理异常。
BigQuery 连接器错误
以下部分介绍了您可能会遇到的常见 BigQuery 连接器错误,以及解决或排查这些错误的步骤。
quotaExceeded
使用 BigQuery 连接器通过流式插入将数据写入 BigQuery 时,写入吞吐量低于预期,并且可能会发生以下错误:
quotaExceeded
此吞吐量可能由于您的流水线超出可用的 BigQuery 流式插入配额。如果是这样,来自 BigQuery 的配额相关错误消息会显示在 Dataflow 工作器日志中(查找 quotaExceeded 错误)。
如果出现 quotaExceeded 错误,请执行以下操作解决此问题:
- 如果使用 Java 版 Apache Beam SDK,请设置 BigQuery 接收器选项
ignoreInsertIds()。 - 如果使用 Python 版 Apache Beam SDK,请使用
ignore_insert_ids选项。
这些设置让您可以为每个项目每秒处理 1 GB 的 BigQuery 流式插入吞吐量。如需详细了解与自动删除重复消息相关的注意事项,请参阅 BigQuery 文档。如需将 BigQuery 流式插入配额增加到 1 GBps 以上,请通过 Google Cloud 控制台提交请求。
如果您在工作器日志中没有看到与配额相关的错误,则问题在于,默认捆绑或批处理相关参数无法提供足够的并行度供流水线进行扩缩。使用流式插入功能将数据写入 BigQuery 时,您可以调整多个 Dataflow BigQuery 连接器相关的配置以实现预期的性能。例如,对于 Java 版 Apache Beam SDK,调整 numStreamingKeys 以匹配最大工作器数量,并考虑增加 insertBundleParallelism 以将 BigQuery 连接器配置为使用更多并行线程来将数据写入 BigQuery。
如需获取 Java 版 Apache Beam SDK 中提供的配置,请参阅 BigQueryPipelineOptions;如需获取 Python 版 Apache Beam SDK 中提供的配置,请参阅 WriteToBigQuery 转换。
rateLimitExceeded
使用 BigQuery 连接器时,会发生以下错误:
rateLimitExceeded
如果 BigQuery 在短时间内发送的 API 请求过多,则会发生此错误。BigQuery 具有短期配额限制。
Dataflow 流水线可能会暂时超出此类配额。在这种情况下,从 Dataflow 流水线到 BigQuery 的 API 请求都可能会失败,这可能会导致工作器日志出现 rateLimitExceeded 错误。
Dataflow 会重试此类失败,因此您可以放心地忽略这些错误。如果您确信流水线受到 rateLimitExceeded 错误的影响,请与 Cloud Customer Care 联系。
其他错误
以下部分介绍了您可能会遇到的各种错误,以及解决或排查这些错误的步骤。
无法分配 sha384
作业运行正常,但您在作业日志中看到以下错误:
ima: Can not allocate sha384 (reason: -2)
如果作业正确运行,则此错误是良性的,您可以忽略它。工作器虚拟机基础映像有时会生成此消息。Dataflow 会自动响应并解决根本问题。
有一个功能请求,旨在将此消息的级别从 WARN 更改为 INFO。如需了解详情,请参阅将 Dataflow 系统启动错误日志级别降低到 WARN 或 INFO。
初始化动态插件探测器时出错
作业运行正常,但您在作业日志中看到以下错误:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
如果作业正确运行,则此错误是良性的,您可以忽略它。如果 Dataflow 作业尝试在没有必要写入权限的情况下创建目录,并且任务失败,则会发生此错误。如果作业成功,则不需要目录,或者 Dataflow 解决了根本问题。
有一个功能请求,旨在将此消息的级别从 WARN 更改为 INFO。如需了解详情,请参阅将 Dataflow 系统启动错误日志级别降低到 WARN 或 INFO。
无此类对象:pipeline.pb
使用 JOB_VIEW_ALL 选项列出作业时,会出现以下错误:
No such object: BUCKET_NAME/PATH/pipeline.pb
如果您从作业的暂存文件中删除 pipeline.pb 文件,则可能会出现此错误。
跳过 pod 同步
作业运行正常,但您在作业日志中看到以下错误之一:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
或:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
如果作业正确运行,则这些错误是良性的,您可以忽略它们。当 Kubernetes kubelet 跳过 pod 同步时,会出现消息 container runtime status check may not have completed yet,因为它正在等待容器运行时初始化。发生这种情况的原因有很多,例如容器运行时最近启动过或正在重启。
当消息包含 PLEG is not healthy: pleg has yet to be successful 时,kubelet 会等待 pod 生命周期事件生成器 (PLEG) 变为健康状况良好,然后再同步 pod。PLEG 负责生成 kubelet 用于跟踪 Pod 状态的事件。
有一个功能请求,旨在将此消息的级别从 WARN 更改为 INFO。如需了解详情,请参阅将 Dataflow 系统启动错误日志级别降低到 WARN 或 INFO。
建议
如需查看有关 Dataflow 数据分析生成的建议的指导,请参阅数据分析。