Le PCollection illimitate o le collection illimitate rappresentano i dati nelle pipeline di streaming. Una raccolta illimitata contiene dati di un'origine dati in continuo aggiornamento, come Pub/Sub.
Non puoi utilizzare solo una chiave per raggruppare gli elementi in una raccolta illimitata. Potrebbero esserci un numero infinito di elementi per una determinata chiave nei dati in streaming perché l'origine dati aggiunge costantemente nuovi elementi. Puoi utilizzare windows, watermark e trigger per aggregare elementi in collezioni illimitate.
Il concetto di finestre si applica anche alle PCollection limitate che rappresentano i dati nelle pipeline batch. Per informazioni sulle finestre nelle pipeline batch, consulta la documentazione di Apache Beam relativa alle finestre con PCollection limitate.
Se una pipeline Dataflow ha un'origine dati limitata, ovvero un'origine
che non contiene dati in aggiornamento continuo, e la pipeline viene passata alla modalità streaming
utilizzando il flag --streaming, quando l'origine limitata viene completamente utilizzata,
la pipeline smette di funzionare.
Usare la modalità di streaming
Per eseguire una pipeline in modalità di streaming, imposta il flag --streaming nella
riga di comando
quando esegui la pipeline. Puoi anche impostare la modalità di streaming
programmaticamente
durante la creazione della pipeline.
Le origini batch non sono supportate in modalità di streaming.
Quando aggiorni la pipeline con un pool di worker più grande, il job di streaming potrebbe non eseguire lo scaling come previsto. Per i job in streaming che non utilizzano Streaming Engine, non puoi eseguire lo scaling oltre il numero originale di worker e risorse di dischi permanenti allocati all'inizio del job originale. Quando aggiorni un job Dataflow e specifichi un numero maggiore di worker nel nuovo job, puoi specificare solo un numero di worker uguale al numero massimo di worker specificato per il job originale.
Specifica il numero massimo di worker utilizzando i seguenti flag:
Java
--maxNumWorkers
Python
--max_num_workers
Vai
--max_num_workers
Finestre e funzioni di finestra
Le funzioni finestra dividono le raccolte illimitate in componenti logici o finestre. Le funzioni di finestratura raggruppano le raccolte illimitate in base ai timestamp dei singoli elementi. Ogni finestra contiene un numero finito di elementi.
Con l'SDK Apache Beam imposti le seguenti finestre:
- Finestre a cascata (chiamate finestre fisse in Apache Beam)
- Finestre alternate (chiamate finestre scorrevoli in Apache Beam)
- Finestre sessione
Finestre a cascata
Una finestra con rotazione rappresenta un intervallo di tempo coerente e disgiunto nello stream di dati.
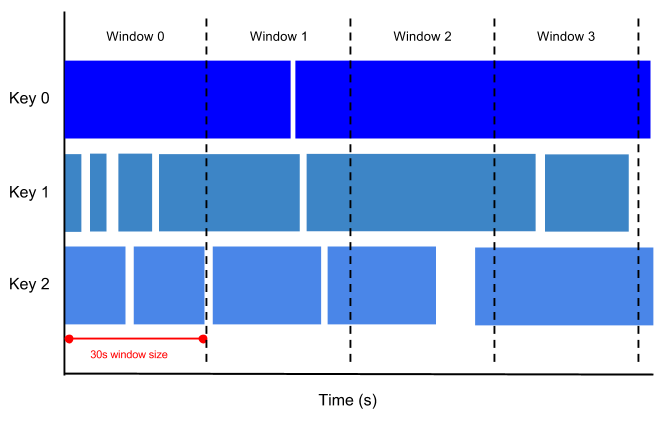
Ad esempio, se imposti una finestra di aggregazione di 30 secondi, gli elementi con valori di timestamp [0:00:00-0:00:30) si trovano nella prima finestra. Gli elementi con valori di timestamp [0:00:30-0:01:00) si trovano nella seconda finestra.
L'immagine seguente illustra come gli elementi vengono suddivisi in finestre con rotazione di 30 secondi.
Finestre di hopping
Una finestra di salto rappresenta un intervallo di tempo coerente nello stream di dati. Le finestre con salto possono sovrapporsi, mentre quelle con rotazione sono disgiunte.
Ad esempio, una finestra con salto può essere avviata ogni 30 secondi e acquisire un minuto di dati. La frequenza con cui iniziano le finestre di hopping è chiamata periodo. Questo esempio ha una finestra di un minuto e un periodo di trenta secondi.
L'immagine seguente mostra come gli elementi sono suddivisi in finestre di acquisto di un minuto con un periodo di 30 secondi.
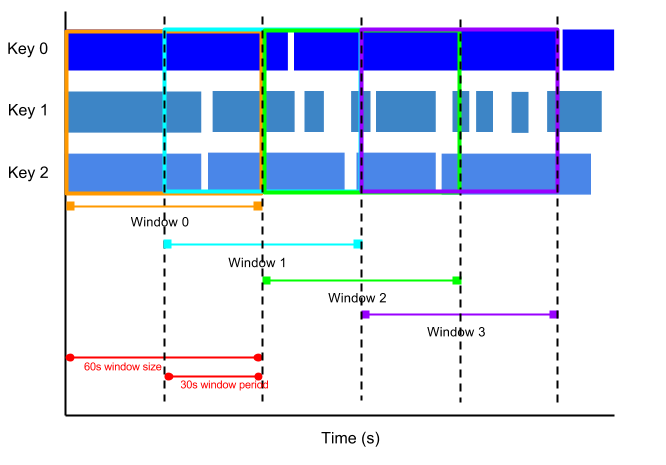
Per calcolare le medie correnti dei dati, utilizza le finestre di salto. Puoi utilizzare finestre di scambio di un minuto con un periodo di trenta secondi per calcolare una media in tempo reale di un minuto ogni trenta secondi.
Finestre di sessione
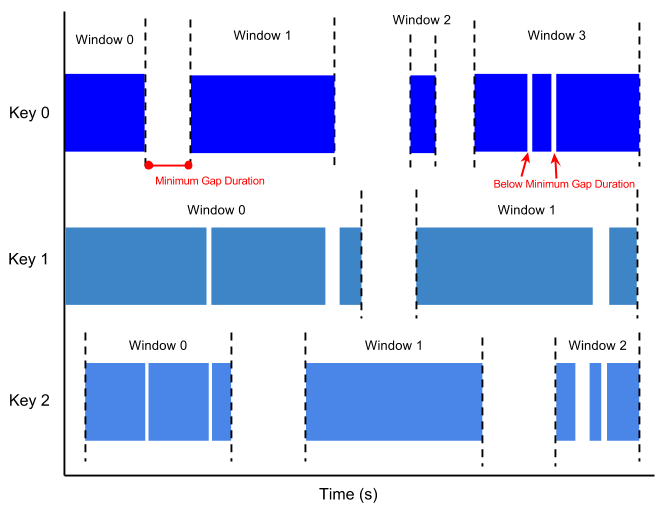
Una finestra di sessione contiene elementi all'interno di un intervallo di tempo di un altro elemento. La durata dell'intervallo è un intervallo tra i nuovi dati in uno stream di dati. Se i dati arrivano dopo la durata dell'intervallo, vengono assegnati a una nuova finestra.
Ad esempio, le finestre della sessione possono suddividere uno stream di dati che rappresenta l'attività del mouse dell'utente. Questo stream di dati potrebbe presentare lunghi periodi di inattività intervallati da molti clic. Una finestra della sessione può contenere i dati generati dai clic.
La suddivisione in finestre della sessione assegna finestre diverse a ogni chiave di dati. Le finestre di tumbling e hopping contengono tutti gli elementi nell'intervallo di tempo specificato, indipendentemente dalle chiavi di dati.
L'immagine seguente mostra come gli elementi vengono suddivisi in finestre di sessione.
Filigrane
Una soglia è una soglia che indica quando Dataflow si aspetta che tutti i dati in una finestra siano arrivati. Se la filigrana è andata oltre la fine della finestra e arrivano nuovi dati con un timestamp all'interno della finestra, questi dati sono considerati dati in ritardo. Per ulteriori informazioni, consulta Watermark e dati in ritardo nella documentazione di Apache Beam.
Dataflow monitora le filigrane per i seguenti motivi:
- Non è garantito che i dati arrivino in ordine cronologico o a intervalli prevedibili.
- Non è garantito che gli eventi di dati vengano visualizzati nelle pipeline nello stesso ordine in cui sono stati generati.
L'origine dati determina la filigrana. Puoi consentire i dati in ritardo con l'SDK Apache Beam.
Trigger
Gli attivatori determinano quando emettere i risultati aggregati man mano che arrivano i dati. Per impostazione predefinita, i risultati vengono emessi quando la filigrana supera la fine della finestra.
Puoi utilizzare l'SDK Apache Beam per creare o modificare gli attivatori per ogni raccolta in una pipeline di streaming.
L'SDK Apache Beam può impostare attivatori che operano su qualsiasi combinazione delle seguenti condizioni:
- Ora dell'evento, indicata dal timestamp su ogni elemento di dati.
- Tempo di elaborazione, ovvero il momento in cui l'elemento di dati viene elaborato in una determinata fase della pipeline.
- Il numero di elementi di dati in una raccolta.
Passaggi successivi
- Streaming 101: il mondo oltre il batch (post del blog)
- Streaming 102: il mondo oltre il batch (post del blog)