Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
このチュートリアルでは、Cloud Composer で失敗した Airflow DAG のデバッグ、ワーカー リソース関連の問題(ワーカー リソースやストレージ スペースの不足など)の診断を、ログと環境モニタリングを使用して行う手順について説明します。
はじめに
このチュートリアルでは、リソース関連の問題に焦点を当てて、DAG のデバッグ方法を示します。
割り当てられたワーカー リソースがない場合、DAG が失敗します。Airflow タスクのメモリやストレージが不足すると、次のような Airflow の例外が表示されることがあります。
WARNING airflow.exceptions.AirflowException: Task received SIGTERM signal
INFO - Marking task as FAILED.
または
Task exited with return code Negsignal.SIGKILL
このような場合は、一般的に推奨されるのは、Airflow ワーカー リソースを増やすか、ワーカーあたりのタスク数を減らすことです。ただし、Airflow の例外は汎用的なものである可能性があるため、問題の原因となっている特定のリソースを特定することが難しい場合があります。
このチュートリアルでは、DAG の失敗の理由を診断し、ワーカーのメモリとストレージの不足により失敗する 2 つの DAG の例をデバッグすることで、問題の原因となるリソースのタイプを特定する方法について説明します。
目標
次の理由で失敗する DAG のサンプルを実行する
- ワーカーのメモリ不足
- ワーカーのストレージ不足
障害の原因を診断する
割り当てられたワーカー リソースを増やす
新しいリソース上限で DAG をテストする
費用
このチュートリアルでは、課金対象である次の Google Cloudコンポーネントを使用します。
このチュートリアルを終了した後、作成したリソースを削除すると、それ以上の請求は発生しません。詳しくは、クリーンアップをご覧ください。
準備
このセクションでは、チュートリアルを開始する前に必要な作業について説明します。
プロジェクトを作成して構成する
このチュートリアルでは Google Cloudプロジェクトが必要です。プロジェクトは、次のように構成します:
Google Cloud コンソールで、プロジェクトを選択または作成します。
プロジェクトに対して課金が有効になっていることを確認します。、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Google Cloud プロジェクト ユーザーに、必要なリソースを作成するための次のロールがあることを確認します。
- 環境とストレージ オブジェクトの管理者
(
roles/composer.environmentAndStorageObjectAdmin) - Compute 管理者(
roles/compute.admin) - Monitoring 編集者(
roles/monitoring.editor)
- 環境とストレージ オブジェクトの管理者
(
プロジェクトでAPI を有効にする
Enable the Cloud Composer API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Cloud Composer 環境を作成する
環境の作成の一環として、Cloud Composer v2 API サービス エージェント拡張機能(roles/composer.ServiceAgentV2Ext)のロールを Composer サービス エージェントに付与します。Cloud Composer は、このアカウントを使用して Google Cloud プロジェクトでオペレーションを実行します。
ワーカーのリソース上限を確認する
ご使用の環境で Airflow ワーカーのリソース上限を確認します。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[環境の設定] タブに移動します。
[リソース] > [ワークロードの構成] > [ワーカー] に移動します。
値が 0.5 vCPU、1.875 GB メモリ、1 GB ストレージであることを確認します。これらが、このチュートリアルの次のステップで使用する Airflow ワーカーのリソース上限です。
例: メモリ不足の問題を診断する
先ほどの手順で作成した環境に、次のサンプル DAG をアップロードします。このチュートリアルでは、この DAG の名前は create_list_with_many_strings です。
この DAG には、次のステップを実行する 1 つのタスクが含まれています。
- 空のリスト
sを作成します。 - サイクルを実行して、
More文字列をリストに追加します。 - リストが消費するメモリ量を出力し、1 分ごとのイテレーションにつき 1 秒待機します。
import time
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import sys
from datetime import timedelta
default_args = {
'start_date': airflow.utils.dates.days_ago(0),
'retries': 0,
'retry_delay': timedelta(minutes=10)
}
dag = DAG(
'create_list_with_many_strings',
default_args=default_args,
schedule_interval=None)
def consume():
s = []
for i in range(120):
for j in range(1000000):
s.append("More")
print(f"i={i}; size={sys.getsizeof(s) / (1000**3)}GB")
time.sleep(1)
t1 = PythonOperator(
task_id='task0',
python_callable=consume,
dag=dag,
depends_on_past=False,
retries=0
)
サンプル DAG をトリガーする
サンプル DAG(create_list_with_many_strings)をトリガーします。
Google Cloud コンソールで、[環境] ページに移動します。
[Airflow ウェブサーバー] 列で、ご使用の環境の [Airflow] リンクをクリックします。
Airflow ウェブ インターフェースの [DAG] ページで、DAG の [リンク] 列の [DAG をトリガー] ボタンをクリックします。
[トリガー] をクリックします。
[DAG] ページで、トリガーしたタスクをクリックし、出力ログを調べて DAG の実行が開始されていることを確認します。
タスクの実行中、出力ログには DAG で使用されているメモリサイズが GB 単位で出力されます。
数分後、Airflow ワーカーのメモリ上限(1.875 GB)を超えるため、タスクは失敗します。
失敗した DAG を診断する
障害発生時に複数のタスクを実行していた場合は、タスクを 1 つだけ実行し、その間にリソースの不足を診断して、リソース不足の原因となるタスクと増やす必要があるリソースを特定します。
Airflow タスクのログを確認する
create_list_with_many_strings DAG からのタスクが Failed 状態になっていることを確認します。
タスクのログを確認します。次のログエントリが表示されます。
```none
{local_task_job.py:102} INFO - Task exited with return code
Negsignal.SIGKILL
```
`Netsignal.SIGKILL` might be an indication of your task using more memory
than the Airflow worker is allocated. The system sends
the `Negsignal.SIGKILL` signal to avoid further memory consumption.
ワークロードを確認する
ワークロードを確認して、Pod が実行されているノードがメモリ消費上限を超過していないことを確かめます。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[環境の設定] タブに移動します。
[リソース] > [GKE クラスタ] > [ワークロード]で、[クラスタ ワークロードの表示] をクリックします。
一部のワークロード Pod のステータスが次のようになっているかどうかを確認します。
Error with exit code 137 and 1 more issue. ContainerStatusUnknown with exit code 137 and 1 more issueExit code 137は、コンテナまたは Pod が許可されているよりも多くのメモリを使用しようとしていることを意味します。メモリ使用量を防ぐために、プロセスが終了します。
環境の健全性とリソース消費のモニタリングを確認する
環境の健全性とリソース消費のモニタリングを確認します。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[Monitoring] タブに移動し、[概要] を選択します。
[環境の概要] パネルで、[環境健全性(Airflow Monitoring DAG)] グラフを見つけます。これには、ログがエラーの出力を開始した時刻に対応する赤色の領域が含まれています。
[ワーカー] を選択し、[ワーカーの合計メモリ使用量] グラフを見つけます。タスクの実行中に [メモリ使用量] の線に急増が見られることを確認します。
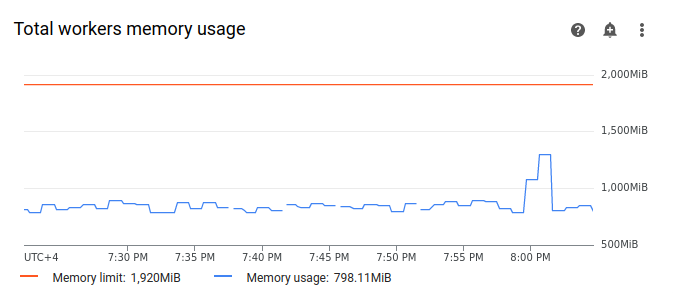
グラフ上のメモリ使用量の線が上限に達していない場合でも、失敗の原因を診断するときは、個々のワーカーによるメモリ使用量を考慮する必要があります。各ワーカーは、メモリの一部を使用して、環境のバケットとの DAG ファイルの同期など、ワーカーの動作に必要なアクションを実行する他のコンテナを実行します。Airflow タスクの実行にワーカーが使用できる実際のメモリ容量が、メモリ上限よりも少ない。ワーカーが使用可能な実際のメモリの上限に達すると、ワーカーメモリの不足により実行されたタスクが失敗する可能性があります。このような場合、ワーカーの合計メモリ使用量のグラフの線がメモリ上限に達していなくても、タスクの失敗を確認できます。
ワーカーのメモリ上限を増やす
サンプル DAG を成功させるために、追加のワーカーメモリを割り当てます。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[環境の設定] タブに移動します。
[リソース] > [ワークロード] 構成から、[編集] をクリックします。
[ワーカー] セクションの [メモリ] フィールドで、Airflow ワーカーの新しいメモリ上限を指定します。このチュートリアルでは、3 GB を使用します。
変更を保存し、Airflow ワーカーが再起動するまで数分待ちます。
新しいメモリ上限で DAG をテストする
DAG(create_list_with_many_strings)を再度トリガーし、実行が完了するまで待ちます。
DAG 実行の出力ログに
Marking task as SUCCESSが表示され、タスクの状態が Success と示されます。[Monitoring] タブの [環境の概要] セクションを確認し、赤い領域がないことを確認します。
[ワーカー] セクションをクリックして、[ワーカーの合計メモリ使用量] グラフを見つけます。[メモリ上限] ラインにはメモリ上限の変更が反映されており、[メモリ使用量] の線は実際の割り当て可能なメモリ上限をはるかに下回っていることが確認できます。
例: ストレージ不足の問題を診断する
このステップでは、大きなファイルを作成する 2 つの DAG をアップロードします。最初の DAG は大きなファイルを作成します。2 番目の DAG は、大きなファイルを作成し、長時間実行オペレーションを模倣します。
両方の DAG 内のファイルのサイズがデフォルトの Airflow ワーカーのストレージ上限の 1 GB を超えていますが、2 番目の DAG には期間を人為的に延長する追加の待機タスクがあります。
次の手順では、両方の DAG の動作の違いを調べます。
大きなファイルを作成する DAG をアップロードする
先ほどの手順で作成した環境に、次のサンプル DAG をアップロードします。このチュートリアルでは、この DAG の名前は create_large_txt_file_print_logs です。
この DAG には、次のステップを実行する 1 つのタスクが含まれています。
- 1.5 GB の
localfile.txtファイルを Airflow ワーカーのストレージに書き込みます。 - Python
osモジュールを使用して、作成されたファイルのサイズを出力します。 - DAG 実行時間を 1 分ごとに出力します。
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import os
from datetime import timedelta
import time
default_args = {
'start_date': airflow.utils.dates.days_ago(0),
'retries': 0,
'retry_delay': timedelta(minutes=10)
}
dag = DAG(
'create_large_txt_file_print_logs',
default_args=default_args,
schedule_interval=None)
def consume():
size = 1000**2 # bytes in 1 MB
amount = 100
def create_file():
print(f"Start creating a huge file")
with open("localfile.txt", "ab") as f:
for j in range(15):
f.write(os.urandom(amount) * size)
print("localfile.txt size:", os.stat("localfile.txt").st_size / (1000**3), "GB")
create_file()
print("Success!")
t1 = PythonOperator(
task_id='create_huge_file',
python_callable=consume,
dag=dag,
depends_on_past=False,
retries=0)
長時間実行オペレーションで大きなファイルを作成する DAG をアップロードする
長時間実行される DAG を模倣して、タスク期間が終了状態に及ぼす影響を調査するには、2 つ目のサンプル DAG を環境にアップロードします。このチュートリアルでは、この DAG の名前は long_running_create_large_txt_file_print_logs です。
この DAG には、次のステップを実行する 1 つのタスクが含まれています。
- 1.5 GB の
localfile.txtファイルを Airflow ワーカーのストレージに書き込みます。 - Python
osモジュールを使用して、作成されたファイルのサイズを出力します。 - ファイルの操作(ファイルからの読み取りなど)に必要な時間を模倣するために 1 時間 15 分待機します。
- DAG 実行時間を 1 分ごとに出力します。
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import os
from datetime import timedelta
import time
default_args = {
'start_date': airflow.utils.dates.days_ago(0),
'retries': 0,
'retry_delay': timedelta(minutes=10)
}
dag = DAG(
'long_running_create_large_txt_file_print_logs',
default_args=default_args,
schedule_interval=None)
def consume():
size = 1000**2 # bytes in 1 MB
amount = 100
def create_file():
print(f"Start creating a huge file")
with open("localfile.txt", "ab") as f:
for j in range(15):
f.write(os.urandom(amount) * size)
print("localfile.txt size:", os.stat("localfile.txt").st_size / (1000**3), "GB")
create_file()
for k in range(75):
time.sleep(60)
print(f"{k+1} minute")
print("Success!")
t1 = PythonOperator(
task_id='create_huge_file',
python_callable=consume,
dag=dag,
depends_on_past=False,
retries=0)
サンプル DAG をトリガーする
最初の DAG(create_large_txt_file_print_logs)をトリガーします。
Google Cloud コンソールで、[環境] ページに移動します。
[Airflow ウェブサーバー] 列で、ご使用の環境の [Airflow] リンクをクリックします。
Airflow ウェブ インターフェースの [DAG] ページで、DAG の [リンク] 列の [DAG をトリガー] ボタンをクリックします。
[トリガー] をクリックします。
[DAG] ページで、トリガーしたタスクをクリックし、出力ログを調べて DAG の実行が開始されていることを確認します。
create_large_txt_file_print_logsDAG で作成したタスクが完了するまで待ちます。これには数分かかることがあります。[DAG] ページで、DAG 実行をクリックします。ストレージの上限を超えている場合でも、タスクの状態は
Successになります。
タスクの Airflow ログを確認します。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[ログ] タブに移動してから、[すべてのログ] > [Airflow ログ] > [ワーカー] > [ログ エクスプローラで表示] に移動します。
タイプ別にログをフィルタし、[エラー] メッセージのみを表示します。
ログには、次のようなメッセージが表示されます。
Worker: warm shutdown (Main Process)
または
A worker pod was evicted at 2023-12-01T12:30:05Z with message: Pod ephemeral
local storage usage exceeds the total limit of containers 1023Mi.
これらのログは、Pod の「ウォーム シャットダウン」プロセスが開始したことを示しています。これは、使用されているストレージが上限を超え、1 時間以内に強制排除されたためです。ただし、このチュートリアルでは、Kubernetes の終了猶予期間内に DAG 実行が完了したため、DAG の実行は失敗しませんでした。
終了猶予期間のコンセプトを説明するために、2 番目のサンプル DAG(long_running_create_large_txt_file_print_logs)の結果を確認してください。
2 つ目の DAG(long_running_create_large_txt_file_print_logs)をトリガーします。
Google Cloud コンソールで、[環境] ページに移動します。
[Airflow ウェブサーバー] 列で、ご使用の環境の [Airflow] リンクをクリックします。
Airflow ウェブ インターフェースの [DAG] ページで、DAG の [リンク] 列の [DAG をトリガー] ボタンをクリックします。
[トリガー] をクリックします。
[DAG] ページで、トリガーしたタスクをクリックし、出力ログを調べて DAG の実行が開始されていることを確認します。
long_running_create_large_txt_file_print_logsDAG の実行が失敗するまで待ちます。これには約 1 時間かかります。
DAG 実行の結果を確認します。
[DAG] ページで、
long_running_create_large_txt_file_print_logsDAG 実行をクリックします。タスクの状態がFailedであること、実行時間が正確に 1 時間 5 分で、タスクの待機時間である 1 時間 15 分より短いことが確認できます。タスクのログを確認します。DAG によって Airflow ワーカーのコンテナに
localfile.txtファイルが作成されると、DAG が待機を開始したことがログに出力され、実行時間が 1 分ごとにタスクログに出力されます。この例では、DAG はlocalfile.txt size:ログを出力し、localfile.txtファイルのサイズが 1.5 GB になります。
Airflow ワーカーのコンテナに書き込まれたファイルがストレージの上限を超えると、DAG の実行は失敗します。ただし、タスクはすぐには失敗せず、実行時間が 1 時間 5 分に達するまで実行され続けます。これは、Kubernetes がタスクをすぐに強制終了せず、1 時間の復元時間(「終了猶予期間」とも呼ばれます)が経過するまで実行し続けることで発生します。ノードでリソースの不足が発生しても、Kubernetes はすぐには停止のために Pod を停止しないため、エンドユーザーへの影響を最小限に抑えます。
終了猶予期間はタスクの失敗後にファイルを復旧するのに役立ちますが、DAG を診断する際に混乱を招く可能性があります。Airflow ワーカーのストレージ上限を超えると、終了タスクの状態は DAG の実行時間によって異なります。
DAG の実行がワーカーのストレージ上限を超えても、1 時間未満で完了すると、終了猶予期間内に完了するため、タスクは
Successステータスが表示されて完了します。ただし、Kubernetes は Pod を終了し、書き込まれたファイルはコンテナからすぐに削除されます。DAG がワーカーのストレージ上限を超え、1 時間以上実行される場合、DAG が 1 時間実行され続けた後に Kubernetes が Pod を削除し、Airflow がタスクを
Failedとしてマークする前に、ストレージの上限が数千パーセントを超える可能性があります。
失敗した DAG を診断する
障害発生時に複数のタスクを実行していた場合は、タスクを 1 つだけ実行し、その間にリソースの不足を診断して、リソース不足の原因となるタスクと増やす必要があるリソースを特定します。
2 番目の DAG long_running_create_large_txt_file_print_logs のタスクログを確認します。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[ログ] タブに移動してから、[すべてのログ] > [Airflow ログ] > [ワーカー] > [ログ エクスプローラで表示] に移動します。
タイプ別にログをフィルタし、[エラー] メッセージのみを表示します。
ログには、次のようなメッセージが表示されます。
Container storage usage of worker reached 155.7% of the limit.
This likely means that the total size of local files generated by your DAGs is
close to the storage limit of worker.
You may need to decrease the storage usage or increase the worker storage limit
in your Cloud Composer environment configuration.
または
Pod storage usage of worker reached 140.2% of the limit.
A worker pod was evicted at 2023-12-01T12:30:05Z with message: Pod ephemeral
local storage usage exceeds the total limit of containers 1023Mi.
This eviction likely means that the total size of dags and plugins folders plus
local files generated by your DAGs exceeds the storage limit of worker.
Please decrease the storage usage or increase the worker storage limit in your
Cloud Composer environment configuration.
このメッセージは、タスクが進行するにつれて、DAG によって生成されたファイルのサイズがワーカーのストレージ上限を超えたタイミングで Airflow ログがエラーを出力し始め、終了猶予期間が開始したことを示しています。終了猶予期間中にストレージの消費量が制限量に戻らなかったため、終了猶予期間が経過した後に Pod が強制排除されました。
環境の健全性とリソース消費のモニタリングを確認します。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[Monitoring] タブに移動し、[概要] を選択します。
[環境の概要] パネルで、[環境健全性(Airflow Monitoring DAG)] グラフを見つけます。これには、ログがエラーの出力を開始した時刻に対応する赤色の領域が含まれています。
[ワーカー] を選択し、[ワーカーの合計ディスク使用量] グラフを見つけます。タスクの実行中に、[ディスク使用量] の線に急増があり、[ディスク上限] ラインを超えていることを確認します。
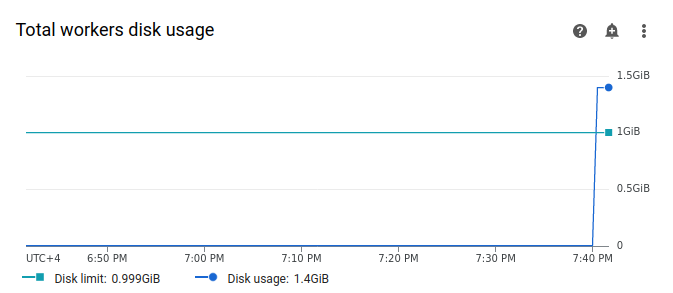
ワーカーのストレージ上限を増やす
サンプル DAG を成功させるために、追加のワーカー ストレージを割り当てます。
Google Cloud コンソールで、[環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[環境の設定] タブに移動します。
[リソース] > [ワークロード] 構成から、[編集] をクリックします。
[ワーカー] セクションの [ストレージ] フィールドで、Airflow ワーカーの新しいストレージ上限を指定します。このチュートリアルでは、2 GB に設定します。
変更を保存し、Airflow ワーカーが再起動するまで数分待ちます。
新しいストレージ上限で DAG をテストする
DAG(long_running_create_large_txt_file_print_logs)を再度トリガーし、実行が完了するまで 1 時間 15 分待ちます。
DAG 実行の出力ログに
Marking task as SUCCESSが表示され、タスクの状態が Success と示されます。持続時間は 1 時間 15 分で、これは DAG コードに設定されている待機時間と同じです。[Monitoring] タブの [環境の概要] セクションを確認し、赤い領域がないことを確認します。
[ワーカー] セクションをクリックして、[ワーカーの合計ディスク使用量] グラフを見つけます。ストレージ制限の変更が [ディスクの上限] ラインに反映され、[ディスク使用量] の線が許容範囲内であることがわかります。
概要
このチュートリアルでは、DAG の失敗の理由を診断し、ワーカーメモリとストレージの不足により失敗する 2 つの DAG の例をデバッグすることで、不足の原因となるリソースのタイプを特定しました。ワーカーに追加のメモリとストレージを割り当てた後、DAG を正常に実行しました。ただし、最初の段階ではワーカーのリソース消費量を削減するために DAG(ワークフロー)を最適化することをおすすめします。これは、特定のしきい値を超えてリソースを増やすことができないためです。
クリーンアップ
このチュートリアルで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトの削除
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
リソースを個別に削除する
複数のチュートリアルとクイックスタートを実施する予定がある場合は、プロジェクトを再利用すると、プロジェクトの割り当て上限を超えないようにできます。
Cloud Composer 環境を削除します。この手順で環境のバケットも削除します。