BigQuery 管理者リファレンス ガイド: テーブルとルーティン

Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
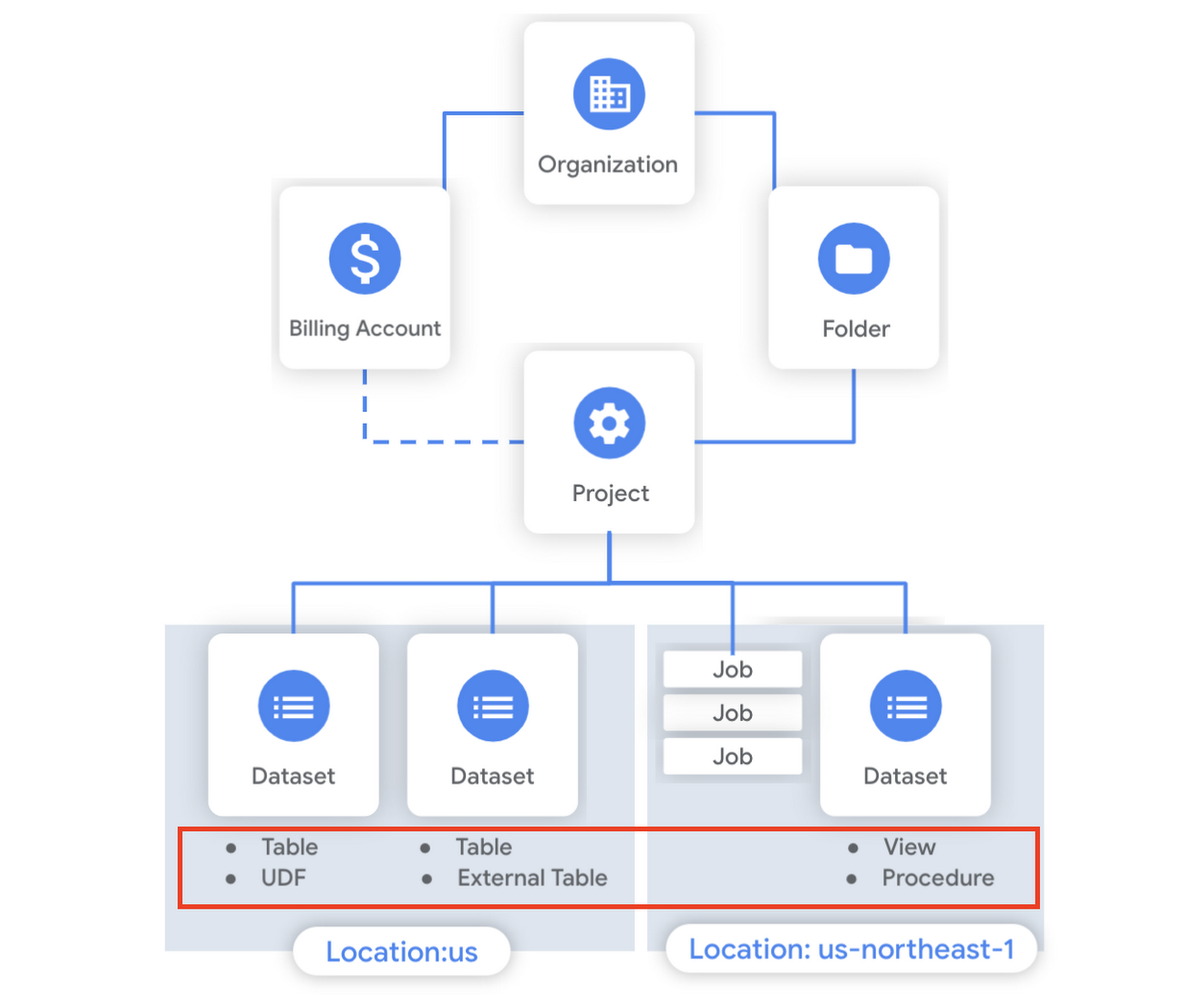
先週の BigQuery 管理者リファレンス ガイド シリーズでは、BigQuery のリソース階層について、特に、プロジェクトとデータセットの構造を掘り下げてお話ししました。今週はさらに深掘りして、データセット内のいくつかのリソースについてご説明します。この投稿では、BigQuery 内で使用できるさまざまなタイプのテーブルと、データの変換にルーティンを活用する方法について取り上げます。前回同様、該当ドキュメントへのリンクを掲載しておきますので、各リソースを実際に使用する方法の詳細を確認いただけます。
テーブルとは
BigQuery テーブルはデータセット内に存在するリソースの一つで、個々のレコードを行単位でまとめ、各列(フィールド)には指定したデータ型が適用されます。BigQuery では、さまざまなデータ型がサポートされています。たとえば、地理空間データ用の GEOGRAPHY 型や、より複雑なデータ向けの STRUCT 型と ARRAY 型に加え、文字列内の文字数などの特定の制約を追加するための新しいパラメータ化されたデータ型などに対応しています。
データアクセスはテーブルや行、列のレベルで制御することもできます。データ ガバナンスの詳細については、シリーズの次回以降で解説します。説明やラベルなどのメタデータは、エンドユーザーに情報を表示するために使用したり、モニタリング用のタグとして使用したりできます。テーブルの作成と管理は UI で直接行うか、API / クライアント SDK を介して、または DDL ステートメントを使用して SQL クエリで行うことができます。
マネージド テーブルと外部テーブル
マネージド テーブルは、ネイティブの BigQuery ストレージでサポートされるテーブルで、パーティションやクラスタのサポートなど、クエリのパフォーマンスを向上させる利点が多数あります。BigQuery ストレージの詳細については、このシリーズの次回以降で扱います。マネージド テーブルを使用するもう一つの利点は、BigQuery でタイムトラベルを使用して過去 7 日間の任意の時点のデータにアクセスし、更新済みや削除済み、期限切れのデータをクエリできることです。また、テーブルのスナップショットを作成して、その内容を特定の期間保持することもできます。
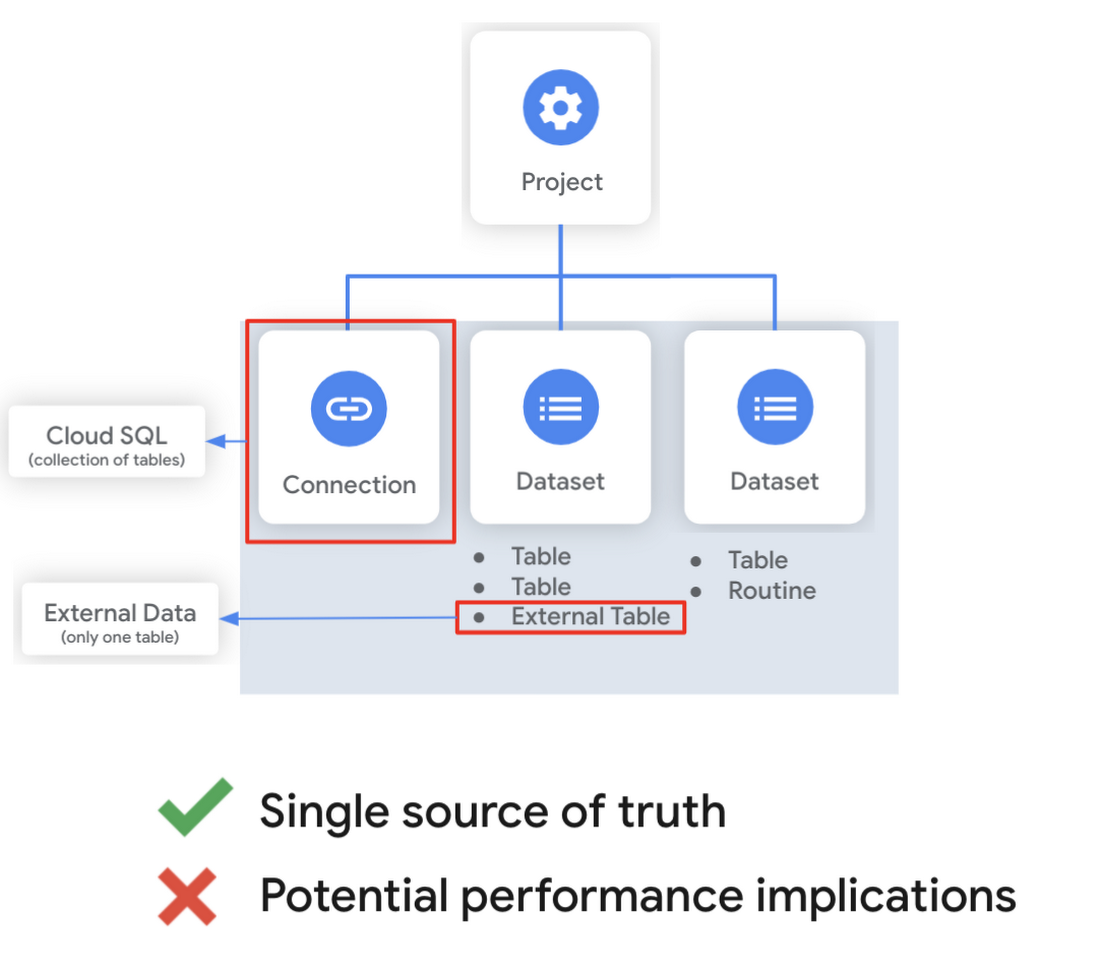
外部テーブルや連携クエリを使用すると、データが BigQuery 自体に保存されている場合ほどクエリが高速でなくなる可能性があります。ただし、一部のデータ変換パターンには有効な場合があります。たとえば、Cloud SQL からデータを選択して変換する連携クエリを使ってマネージド テーブルをハイドレートするように DDL / DML クエリをスケジュールできます。外部テーブルは、BQ ストレージが信頼できる情報源ではないマルチコンシューマ向けワークフローにも役立つ場合があります。たとえば、Cloud Storage バケット内のデータにアクセスする Dataproc クラスタがあり、BigQuery に移植する準備が済んでいない場合です(ただし、説得力が必要な場合はコネクタを確認することをおすすめします)。外部データのクエリについて詳しくは、こちらの動画をご覧ください。
論理ビューとマテリアライズド ビュー
BigQuery では、論理ビューやマテリアライズド ビューを使用して仮想テーブルを作成できます。論理ビューを使用すると、BigQuery で SQL ステートメントを実行して実行時にビューを作成できます。結果はどこにも保存されません。また、ユーザーに承認済みビューへのアクセスを許可してクエリ結果を共有でき、基になるテーブルへのアクセスを許可せずに済みます。
一方、マテリアライズド ビューは、基本データが変更されるとバックグラウンドで再計算されます。ユーザーの操作が不要で、常に最新の状態になっています。さらに、ソーステーブルに対するクエリまたはクエリの一部がマテリアライズド ビューへのクエリによって解決できる場合は、BigQuery によってクエリの宛先が変更され、パフォーマンスが向上します。ただし、マテリアライズド ビューは、制限付き SQL 構文と一部の集計関数を使用します。制限事項の詳細はこちらをご参照ください。
一時テーブルとキャッシュ結果テーブル
ここまでご説明したテーブルとは別に、TEMP まはた TEMPORARY というキーワードを使用して一時的なマネージド テーブルを作成することもできます。このテーブルは BigQuery ストレージに保存され、スクリプトの存続期間中に参照できます。一時テーブルは、エイリアスが参照されるすべての場所にインライン化されるものと違い、定義クエリが 1 回だけ実行されるため、WITH 句の適切な代わりになります。
元のコード | 最適化 |
with a as ( select ... ), b as ( select ... from a ... ), c as ( select ... from a ... ) select b.dim1, c.dim2 from b, c; | create temp table a as select …;
with b as ( select ... from a ... ), c as ( select ... from a ... ) select b.dim1, c.dim2 from b, c; |
また、BigQuery がすべてのクエリ結果をテーブルに書き込む点も重要です。このテーブルは、ユーザーが明示的に指定したテーブルまたはキャッシュ結果テーブルです。一時的なキャッシュ結果テーブルは、ユーザー別、プロジェクト別に保持されます。一時的なテーブルにはストレージの費用がかかりません。
ユーザー定義関数とプロシージャ
BigQuery のルーティンは、ユーザー定義関数(UDF)またはプロシージャです。ルーティンを使用すれば、ロジックを再利用してデータを独自の方法で処理できます。UDF は SQL または JavaScript を使用して作成される関数で、入力として引数を取り、出力として単一の値を返します。UDF はデータのクリーニングや再フォーマットに使用されることが少なくありません。たとえば、URL 文字列からのパラメータ抽出、ネストされたデータの再構築、文字列のクリーンアップに使用されます。
BigQuery UDF のコミュニティ主導オープンソース リポジトリも用意されています。論理ビューと同様、基になるデータの側面を保護する承認済み UDF を作成できます。UDF の詳細については、こちらの動画をご覧ください。また、テーブル関数(スカラー値の代わりにテーブルを返す SQL UDF を作成できるプレビュー機能)も確認することをおすすめします。
一方、プロシージャは他のクエリから呼び出せる SQL ステートメントのブロックです。UDF とは異なり、ストアド プロシージャは複数の値を返すことも、値を返さないことも可能です。つまり、テーブルの作成や変更のために実行できます。BigQuery では、プロシージャ内のスクリプト機能を活用して、IF ステートメントと WHILE ステートメントで実行フローを制御することもできます。さらに、プロシージャ内で UDF を呼び出すことも可能です。こうした特徴により、プロシージャは抽出、ロード、変換(ELT)に基づくワークフローに最適です。
組織全体で一貫性のある分析を確保するには、UDF とプロシージャを格納するライブラリ データセットを作成することをおすすめします。ライブラリ データセットに対する BigQuery データ閲覧者ロールを組織内の全員に簡単に付与して、すべてのアナリストがクエリで一貫性のある最新のロジックを使用するようにできます。
今後の情報にご注目ください
今回の投稿が、BigQuery データセット内のさまざまなリソースを活用する方法を理解し、ネイティブ ストレージと外部ストレージ、論理ビューとマテリアライズド ビュー、ユーザー定義関数とプロシージャのどちらを使用するかを決定するために、お役に立てば幸いです。
次回は、ジョブと予約モデルを確認して、BigQuery のワークロード管理について説明します。このシリーズの最新情報を見逃さないように、ぜひ LinkedIn と Twitter で私をフォローしてください。また、YouTube チャンネルの登録もお願いいたします。
-デベロッパー アドボケイト Leigha Jarett




