BigQuery 管理者リファレンス ガイド: リソース階層

Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
今週から BigQuery スポットライト YouTube シリーズに新しいコンテンツが追加されます。この夏を通じて、BigQuery の新しいアーキテクトと管理者が基本をマスターできるよう支援することに焦点を当てた動画やブログ投稿を新たに追加していきます。BigQuery の公式ドキュメントで扱っているトピックに関する補足資料をご用意していますので、下のリンクをご確認ください。まずは、BigQuery リソースモデルについて取り上げます。
BigQuery はその他の Google Cloud リソースと同様に、階層的に編成されています。組織ノードが階層のルートノードで、プロジェクトは組織の子ノード、データセットはプロジェクトの子孫になります。この投稿では、BigQuery リソースモデルについて詳しく見ていき、ビジネスニーズに基づいてデプロイメントを設計するための重要な考慮事項をご説明します。
BigQuery コア リソース モデル
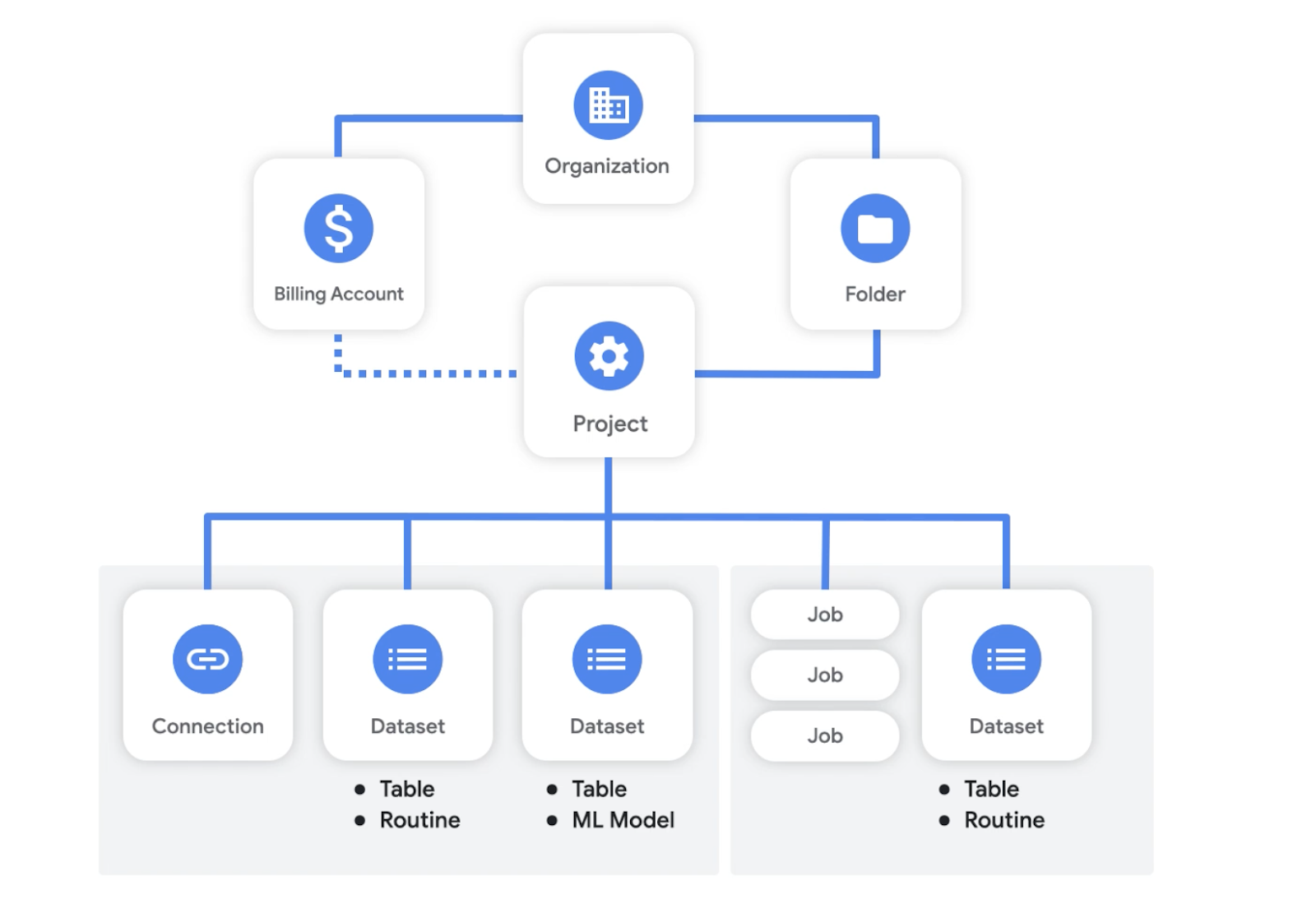
組織、フォルダ、請求先アカウント
組織リソースは Google Cloud リソース階層のルートノードです。これは会社を表し、Google Workspace アカウントまたは Cloud Identity アカウントにリンクされていることで、会社のドメインと密接に関連しています。BigQuery の使用を開始するのに組織は必須ではありませんが、作成することをおすすめします。組織リソースを使用する場合、プロジェクトはそれを作成した従業員ではなく組織に属します。また、組織管理者はすべてのリソースを集中的に管理できます。
フォルダは、プロジェクトの上位にあるグループ化メカニズムです。組織内ではサブ組織とみなすことができます。フォルダは、異なる法人、部門、社内チームのモデル化に使用できます。フォルダはポリシーの継承ポイントとして機能します。フォルダに付与された IAM ロールは、そのフォルダ内のすべてのプロジェクトとフォルダに自動的に継承されます。BigQuery をフラットレートで利用しているお客様の場合、スロット(CPU の単位)は、組織、フォルダ、プロジェクトに割り当てることができ、ジョブのワークロードを処理するためにプロジェクト間で均等に分配できます。
BigQuery を使用するには、BigQuery サンドボックスを使用していない限り、請求先アカウントが必要です。多くの場合、お客様は、消費した Google Cloud のリソースに対する請求がチームごとに行われることを希望しています。そのため、請求グループごとに請求先アカウントが用意されて Google お支払いプロファイルに関連付けられ、1 つの請求書が作成されます。
プロジェクト
BigQuery を使用するにはプロジェクトが必要です。プロジェクトは、すべての Google Cloud サービスを使用するための基礎となります。プロジェクトは他のシステムにおけるデータベースに似ています。
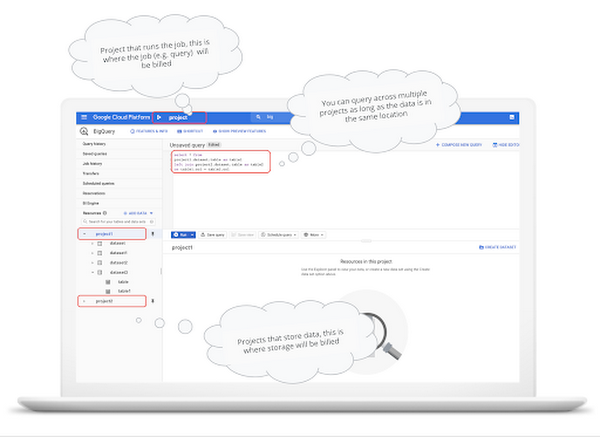
プロジェクトは、データの保存と、データに対するジョブまたはクエリの実行の両方に使用されます。ストレージとコンピューティングは分離されているため、同じプロジェクトにする必要はありません。1 つのプロジェクトでデータを保存して、別のプロジェクトでデータをクエリできます。複数のプロジェクトで保存されたデータを 1 つのクエリに統合することもできます。1 つのプロジェクトに設定できる請求先アカウントは 1 つだけです。そのプロジェクト内で保存されたデータと実行されたジョブに対して、プロジェクトに請求が行われます。プロジェクトあたりの上限と割り当てにご注意ください。
データセット
データセットはプロジェクト内の最上位のコンテナで、テーブル、ビュー、ルーチン、機械学習モデルへのアクセスを整理、管理するために使用されます。テーブルはデータセットに属していなければなりません。したがって、データを BigQuery に読み込む前に、1 つ以上のデータセットを作成する必要があります。
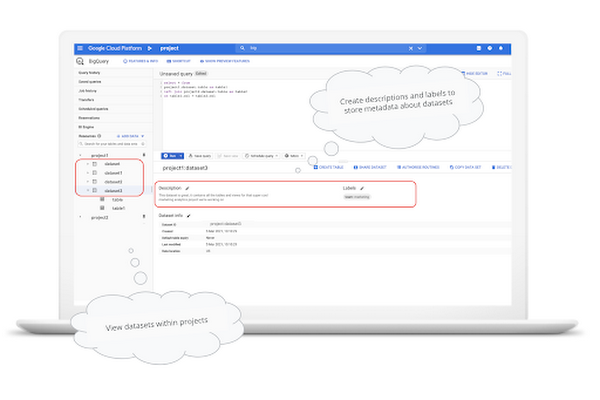
データは、データセットの作成時に選択した地理的なロケーションに保存されます。データセットの作成後はロケーションを変更できません。重要な考慮事項として、複数のロケーションをまたいでクエリを実行できないという点が挙げられます。詳しくはロケーションに関する考慮事項をお読みください。多くのユーザーがマルチリージョンのロケーションにデータを保存することを選択していますが、オンプレミスのデータベースや ETL ジョブに近い特定のリージョンを設定することを選択するユーザーもいます。
アクセス制御
BigQuery 内でのデータへのアクセスは、リソースモデルの異なるレベル(プロジェクト、データセット、テーブル、さらには列など)で管理できます。ただし、管理をシンプルにするには、階層の上位でアクセスを管理するほうが一般的には簡単です。
一般的な BigQuery プロジェクト構造の例
ここまでで、プロジェクト構造の決定が、データ ガバナンス、請求、さらにクエリの効率に大きく影響する可能性があることにお気づきかと思います。多くのお客様が、さまざまなプロジェクト階層を活用することで、データレイクやデータマートの概念を導入しています。これは主に、廉価なデータ ストレージ、ELT ワークロードとデータベース内変換を可能にする高度な SQL 機能に加えて、BigQuery 内でストレージとコンピューティングが分離されていることによります。
中央データレイク、部門データマート
この構造では、BigQuery に元データを保存する共通のプロジェクト(統合ストレージ プロジェクト)があります。これはデータレイクとも呼ばれます。一元化されたデータ プラットフォームのチームが、このプロジェクト内でさまざまなソースから BigQuery にデータを実際に取り込むパイプラインを作成するケースがよく見られます。そして各部門またはチームが、それぞれのデータマート プロジェクト(例: 部門 A コンピューティング)で、データのクエリ、結果の保存、集計ビューの作成などを行っています。
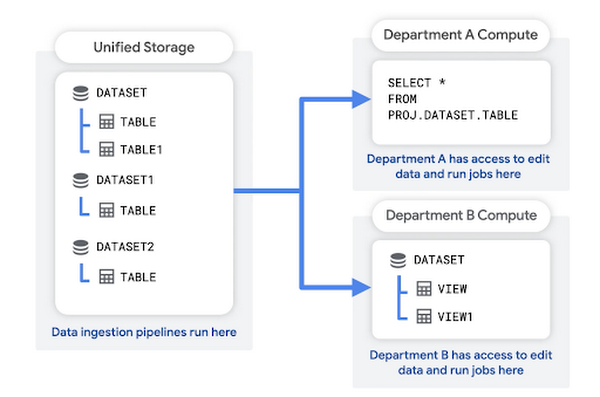
仕組み:
中央データ エンジニアリング チームに、ストレージ プロジェクト内でデータの取り込みと編集を行う権限が与えられます
部門アナリストに、統合ストレージ プロジェクト内の特定のデータセットに対する BigQuery データ閲覧者ロールが与えられます
部門アナリストには、所属部門のコンピューティング プロジェクトに対する BigQuery データ編集者ロールと BigQuery ジョブ ユーザー ロールも与えられます
各コンピューティング プロジェクトはチームの請求先アカウントに接続されます
これは次の場合に特に役立ちます。
クエリに対する請求を各ビジネス ユニットが個別に受け取りたい
一元化されたプラットフォームまたはデータ エンジニアリング チームが、ビジネス ユニット全体のデータを BigQuery に取り込んでいる
さまざまなビジネス ユニットが独自のツールで、またはコンソールで直接、自分たちのデータにアクセスしている
同じプロジェクト内であまりにも多くのクエリが同時実行されるのを避ける必要がある(プロジェクトあたりの割り当てがあるため)
部門データレイク、1 つの共通のデータ ウェアハウス プロジェクト
このオプションでは、各部門のデータが個別のプロジェクトに取り込まれます。そのため基本的に、各部門にそれぞれのデータレイクが提供されます。アナリストは、中央データ ウェアハウス プロジェクトでこれらのデータセットのクエリまたは集計ビューの作成を行うことができます。またこれらは、ビジネス インテリジェンス ツールに簡単に接続可能です。
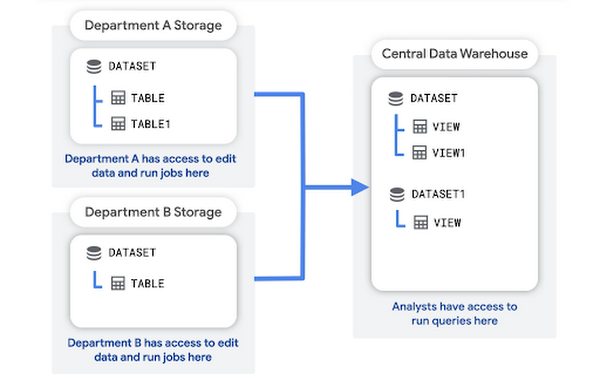
仕組み:
特定のデータソースの取り込みを担当するデータ エンジニアに、担当部門のストレージ プロジェクトでの BQ データ編集者ロールと BQ ジョブ ユーザー ロールが与えられます
アナリストに、プロジェクト レベルの基礎データに対する BQ データ閲覧者ロールが与えられます(たとえば、HR アナリストには、HR ストレージ プロジェクト全体に対するデータ閲覧者アクセス権を与えることができます)
BigQuery を外部のビジネス インテリジェンス ツールに接続するために使用されるサービス アカウントに、可視化に使用されるデータセットを含む特定のプロジェクトに対するデータ閲覧者アクセス権が与えられる場合もあります
アナリストとサービス アカウントに、中央データ ウェアハウス プロジェクトでの BQ ジョブ ユーザー ロールと BQ データ編集者ロールが与えられます
これは次の場合に特に役立ちます。
プロジェクト レベルや部門レベルで元データへのアクセスを管理するほうが簡単である
中央分析チームが、1 つのプロジェクトでコンピューティングを行って、クエリのモニタリングをシンプルにしたいと考えている
ユーザーが、一元化されたビジネス インテリジェンス ツールからデータにアクセスしている
スロットをデータ ウェアハウス プロジェクトに割り当てて、アナリストや外部ツールからのすべてのクエリを処理できる
この構造では多数の同時クエリが生じる可能性があります。そのためプロジェクトあたりの上限に注意してください。この構造は、同時実行数の上限を解除した、フレアレートのお客様に最適です。
部門データレイクと部門データマート
この構造では、前述のアプローチを組み合わせて、各部門のデータレイクまたはストレージのプロジェクトを作成します。さらに、各部門では、アナリストがクエリを実行できる独自のデータマート プロジェクトを作成することもできます。
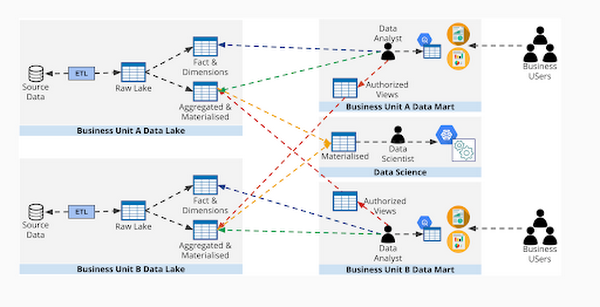
仕組み:
部門のデータ エンジニアに、部門のデータレイク プロジェクトの BQ データ編集者ロールと BQ ジョブ ユーザー ロールが与えられます
部門データ アナリストに、部門のデータレイク プロジェクトの BQ 閲覧者ロールが与えられます
部門データ アナリストに、部門のデータマート プロジェクトの BQ データ編集者ロールと BQ ジョブ ユーザー ロールが与えられます
許可されたビューと許可されたユーザー定義関数を活用して、アクセス権のないプロジェクトのデータにデータ アナリストがアクセスできるようにすることが可能です
これは次の場合に特に役立ちます。
データ ストレージとコンピューティングの両方に対する請求を、各ビジネス ユニットが個別に受け取りたい
さまざまなビジネス ユニットが独自のツールで、またはコンソールで直接、自分たちのデータにアクセスしている
同じプロジェクト内であまりにも多くのクエリが同時実行されるのを避ける必要がある
プロジェクト レベルや部門レベルで元データへのアクセスを管理するほうが簡単である
これで、BigQuery データ ウェアハウスの設計を始める準備が整いました。このシリーズの最新情報を見逃さないように、ぜひ LinkedIn と Twitter で私をフォローしてください。
-デベロッパー アドボケイト Leigha Jarett



