Cloud SQL for SQL Server で生成された監査レコードを BigQuery にアップロードする Cloud Data Fusion パイプラインの構築
Alexander Kolomeets
Software Engineer
※この投稿は米国時間 2024 年 5 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
Cloud SQL for SQL Server を使用すると、ログイン試行、DDL、DML などのイベントをキャプチャするように監査を構成できます。これらのイベントはローカルのインスタンスに最大 7 日間保存されますが、GCS バケットにはそれ以上保存できます。
お客様の中には、BigQuery や Tableau などの他のシステムで Cloud SQL for SQL Server の監査データにアクセスして分析したいとお考えの方もいらっしゃるでしょう。これを実現するために、カスタム構築のパイプラインを使用することもできますが、複雑さとメンテナンスの負担が生じます。また、サポートやモニタリング、監査レコードの紛失を防ぐために継続的な投資が必要になります。
このブログでは、最小限のコーディングで、内部シンクや外部シンクに監査レコードを出力する柔軟なパイプラインを構築する方法を紹介します。
前提条件
Cloud Data Fusion は、プライベート IP の Cloud SQL for SQL Server インスタンスを直接サポートしていません。これらのインスタンスに接続するには、Cloud Data Fusion と Cloud SQL for SQL Server インスタンス間のブリッジとして、Cloud SQL Auth Proxy を設定する必要があります。ただし、Cloud SQL for SQL Server インスタンスにパブリック IP がある場合は、特別な設定をすることなく直接接続できます。
また、プライベート IP の Cloud Data Fusion インスタンスも必要です。Cloud SQL Auth Proxy と Cloud Data Fusion インスタンス間の接続性を確保するには、それぞれのネットワーク間にネットワーク ピアリングを確立します。ピアリングされたプロジェクト ID は、Cloud Data Fusion インスタンスのページで確認できます。
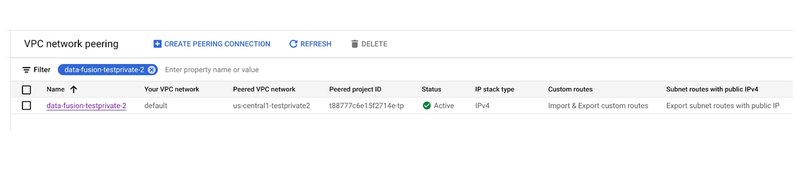
ワークフローを構築する
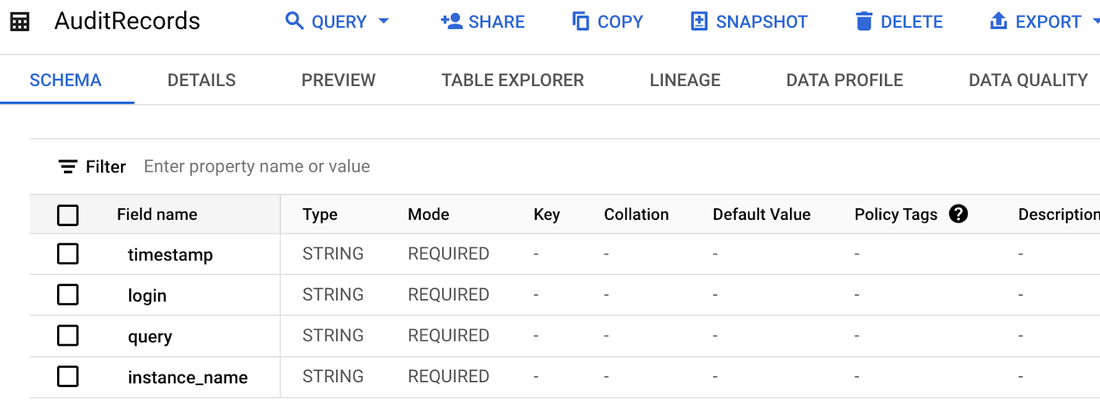
まず、宛先 BigQuery テーブルを作成します(ここでは一部のフィールドのみを格納しますが、より包括的な分析のために、利用可能なすべてのフィールドを格納する BigQuery テーブルを作成することも可能です)。
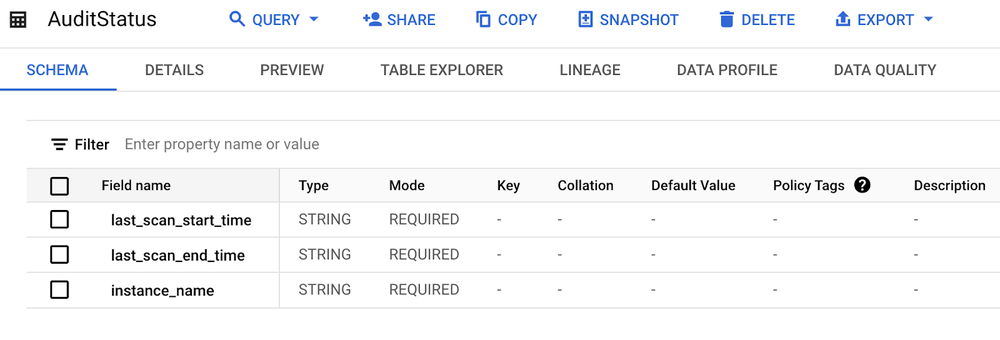
これに加えて、各インスタンスで最後に処理された監査レコードを追跡するテーブルが必要です。このテーブルは、Cloud SQL や BigQuery 内に作成できるほか、Google Cloud Storage バケット内のファイルとして扱うこともできます。ここでは、わかりやすくするため、このテーブルを BigQuery 内に作成します。これは、(Cloud SQL インスタンスが利用できないなどの理由で)監査レコードの取得が失敗した場合に、レコードの取りこぼしを防ぎ、再試行時に確実に取得できるようにする方法が必要なためです。last_scan_start_time フィールドと last_scan_end_time フィールドには STRING 型を使用します。これは、BigQuery の引数キャプチャは DATETIME 型をサポートしていないためです。
それでは、Data Fusion パイプラインを作成してみましょう。

Data Fusion パイプラインに追加されたすべてのブロックを確認します。
1. 監査ステータスの初期化
このブロックでは、このインスタンスの監査レコードがアップロードされたときの最新のタイムスタンプを BigQuery にクエリします。エントリが存在しない場合は、デフォルトのエントリが追加され、既存のすべての監査レコードが取得されます。
MERGE dataset.AuditStatus AS targetUSING (SELECT '${instance_name}' as instance_name) AS source ON target.instance_name = source.instance_nameWHEN NOT MATCHED THEN INSERT (last_scan_start_time, last_scan_end_time, instance_name) VALUES ('2000-01-01 01:01:01', '2000-01-01 01:01:01', '${instance_name}')
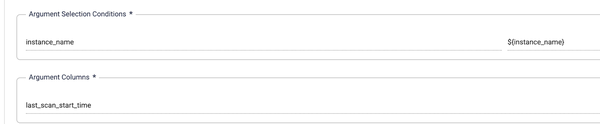
2. 最終スキャン時刻の設定
このブロックでは last_scan_start_time 変数を設定します。この値はインスタンス名に基づいて条件付きで選択されます。
3. 監査レコードの読み取り
パラメータ ${ip} および ${port} を渡します。これらがどのように決定されるかについては、次のセクションで説明します。

このクエリを使用して、インスタンスから新しい監査レコードを取得します。最後の処理時刻から開始します。このクエリには、パラメータが 3 つ追加されていることに注意してください。
-
${last_scan_start_time} は、前のステップで設定したもの。
-
${logicalStartTime} は、Data Fusion が自動的に指定したもの。
-
${instance_name} については、次のセクションで説明します。
SELECT event_time, server_principal_name, statement,' ${instance_name}' AS instance_name FROM msdb.dbo.gcloudsql_fn_get_audit_file('/var/opt/mssql/audit/*', NULL, NULL) WHERE CONVERT(datetime2, '${logicalStartTime(yyyy-MM-dd HH:mm:ss)}', 20) >= event_time AND CONVERT(datetime2, '${last_scan_start_time}', 20) < event_time
4. 監査レコードの変換
このオプションのブロックでは、ソースとシンクの間でフィールド名と型を変換します。すでに名前と型が一致している場合は、このステップは省略できます。

5. 監査レコードの書き込み
このブロックでは、監査レコードを宛先 BigQuery テーブルに書き込みます。フィールドは前のステップで変換されているため、宛先テーブル以外に構成をさらに行う必要はありません。
6. 最終スキャン時刻の更新
この最後のブロックでは、前回の実行による監査レコードを再度処理しないように、最終スキャン時刻を更新します。また、終了時刻も記録します。これは、主にパフォーマンスを追跡するためです。
MERGE dataset.AuditStatus AS targetUSING (SELECT '${instance_name}' as instance_name) AS source ON target.instance_name = source.instance_nameWHEN MATCHED THENUPDATE SET last_scan_start_time = '${logicalStartTime(yyyy-MM-dd HH:mm:ss)}', last_scan_end_time = CAST(CURRENT_DATETIME() AS STRING)
ワークフローのスケジュールを設定する
これで、gcloud を使用して、このワークフローを(たとえば、cron ジョブから)開始できます。
WORKFLOW_NAME="AuditPipeline"CDAP_ENDPOINT=`gcloud beta data-fusion instances describe --location <<DATA_FUSION_INSTANCE_LOCATION>> --format="value(apiEndpoint)" <<DATA_FUSTION_INSTANCE_NAME>>`PIPELINE_URL="${CDAP_ENDPOINT}/v3/namespaces/default/apps/${WORKFLOW_NAME}/workflows/DataPipelineWorkflow/start"AUTH_TOKEN=$(gcloud auth print-access-token)
curl -X POST \ -H "Authorization: Bearer ${AUTH_TOKEN}" \ -H "Content-Type: application/json" \ "${PIPELINE_URL}"
ただし、ここでは、Cloud Scheduler を使用した別のアプローチを紹介します。これはフルマネージドのエンタープライズ グレード cron ジョブ スケジューラです。
まず、以下のことを行う Cloud Functions の関数を作成します。
-
プロジェクト内の Cloud SQL インスタンスの列挙
-
監査が有効になっている SQL Server インスタンスの特定
-
対象となるインスタンスごとに、先ほど作成した Data Fusion パイプラインをトリガーし、インスタンス名と IP アドレスをパラメータとして渡す
Cloud Functions の関数のトリガーに使用するサービス アカウントが、Cloud SQL と Cloud Data Fusion の両方のインスタンスにアクセスできる権限があることを確認してください。
import functions_frameworkimport requestsimport json
# この関数は、Cloud SQL for SQL Server インスタンスをリストし、作成されたパイプラインをトリガーするために必要なアクセス トークンを取得します。def get_access_token():
METADATA_URL = 'http://metadata.google.internal/computeMetadata/v1/' METADATA_HEADERS = {'Metadata-Flavor':'Google'} SERVICE_ACCOUNT = 'default' url = '{}instance/service-accounts/{}/token'.format(METADATA_URL, SERVICE_ACCOUNT) r = requests.get(url, headers=METADATA_HEADERS) access_token = r.json()['access_token'] return access_token
# この関数は Cloud SQL Proxy の認証アドレスと IP を取得します。簡単にするため、Proxy Auth インスタンスは 1 つだけと仮定します。ポートは、対象となる Cloud SQL for SQL Server インスタンスの IP アドレスの最後のオクテットに 1433 を加えたものとして計算されます。def get_proxy_address_and_port(ip): PROXY_ADDRESS = '10.128.0.5' PROXY_BASE_PORT = 1433 port = int(ip.split('.')[-1]) + PROXY_BASE_PORT return (PROXY_ADDRESS, port)
# これは Cloud Functions の関数のエントリ ポイントです。@functions_framework.httpdef process_audit_http(request): token = get_access_token() WORKFLOW_NAME = "AuditPipeline" # この値を決定する方法については、このセクションの冒頭を参照してください。 CDAP_ENDPOINT = "<<YOUR_CDAP_ENDPOINT>>" PIPELINE_URL = "{}/v3/namespaces/default/apps/{}/workflows/DataPipelineWorkflow/start".format(CDAP_ENDPOINT, WORKFLOW_NAME)
# 監査が有効になっているプライベート IP の Cloud SQL for SQL Server インスタンスをリストします。 r = requests.get("https://sqladmin.googleapis.com/v1/projects/<<PROJECT_NAME>>/instances?filter=settings.sqlServerAuditConfig.bucket:\"gs://<<BUCKET_NAME>>\"%20settings.ipConfiguration.privateNetwork:projects/<<PROJECT_NAME>>/global/networks/default", headers={"Authorization":"Bearer {}".format(token)}) json_object = json.loads(r.text)
# Cloud SQL Auth Proxy の IP とアドレスを見つけ、Data Fusion パイプラインを開始します。 for item in json_object["items"]: for ip in item["ipAddresses"]: if ip["type"] == "PRIVATE": proxy_and_port = get_proxy_address_and_port(ip["ipAddress"]) param = {"ip" : proxy_and_port[0], "port": proxy_and_port[1], "instance_name" : item["connectionName"]} r = requests.post(PIPELINE_URL, json=param, headers={"Authorization":"Bearer {}".format(token)}) return "done"
次に、先ほど作成した Cloud Functions の関数をターゲットとする Cloud Scheduler ジョブを作成します。必要に応じて実行間隔を設定します。たとえば、以下の例では 15 分ごとに実行するようにスケジュールされています。

このパイプラインは、複数のインスタンスを同時に処理するように簡単に変更できます。これは、Cloud Functions の関数内またはパイプライン内で行えるため、処理速度を向上できる可能性があります。
ワークフローを実行する
次に、Cloud SQL for SQL Server インスタンスを作成し、監査を有効にして、簡単な監査ルールを設定します。
CREATE SERVER AUDIT ServerAudit1 TO FILE (FILEPATH ='/var/opt/mssql/audit', MAXSIZE=2MB)CREATE SERVER AUDIT SPECIFICATION ServerAuditSpec1 FOR SERVER AUDIT ServerAudit1 ADD (DATABASE_CHANGE_GROUP) WITH (STATE = ON)ALTER SERVER AUDIT ServerAudit1 WITH (STATE = ON)
次に、以下のようにデータベースを 2 つ作成します。
CREATE DATABASE db1CREATE DATABASE db2
ここでは、次にスケジュールされている Cloud Scheduler の実行を待つか、手動でトリガーします。実行したら、先ほど作成した 2 つの BigQuery テーブルを確認します。AuditRecords テーブルには、2 つの「create database」イベントが含まれているはずです。
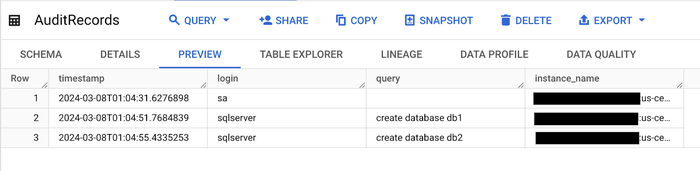
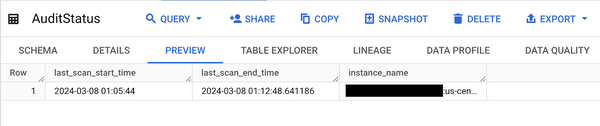
AuditStatus テーブルには、以下のように最終実行時刻が表示されているはずです。
試しに、以下のようにして、先ほど作成したデータベースの 1 つを削除してみましょう。
DROP DATABASE db1
ここでは、次にスケジュールされている Cloud Scheduler の実行を待つか、手動でトリガーします。その後、AuditRecords テーブルにイベントが 1 つ追加されていることを確認します。
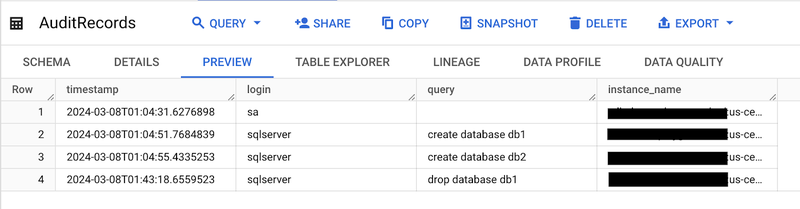
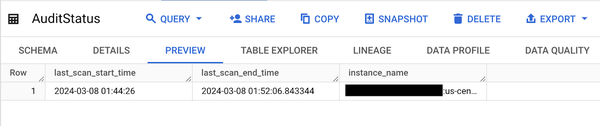
AuditStatus テーブルにも、更新された最終実行時刻が反映されているはずです。
次のステップ
Cloud Data Fusion には高度な通知機能があり、たとえば、パイプラインが失敗した時にメールを送信するように設定できます。詳しい設定方法については、https://cloud.google.com/data-fusion/docs/how-to/create-alerts をご覧ください。
また、BigQuery でアラートを設定して、特定の状況をモニタリングすることもできます。詳しい設定方法については、https://cloud.google.com/bigquery/docs/scheduling-queries をご覧ください。
-ソフトウェア エンジニア Alexander Kolomeets


