BigQuery admin reference guide: Tables & routines

Leigha Jarett
Developer Advocate, Looker at Google Cloud
Last week in our BigQuery Reference Guide series, we spoke about the BigQuery resource hierarchy - specifically digging into project and dataset structures. This week, we’re going one level deeper and talking through some of the resources within datasets. In this post, we’ll talk through the different types of tables available inside of BigQuery, and how to leverage routines for data transformation. Like last time, we’ll link out to the documentation so you can learn more about using these resources in practice.
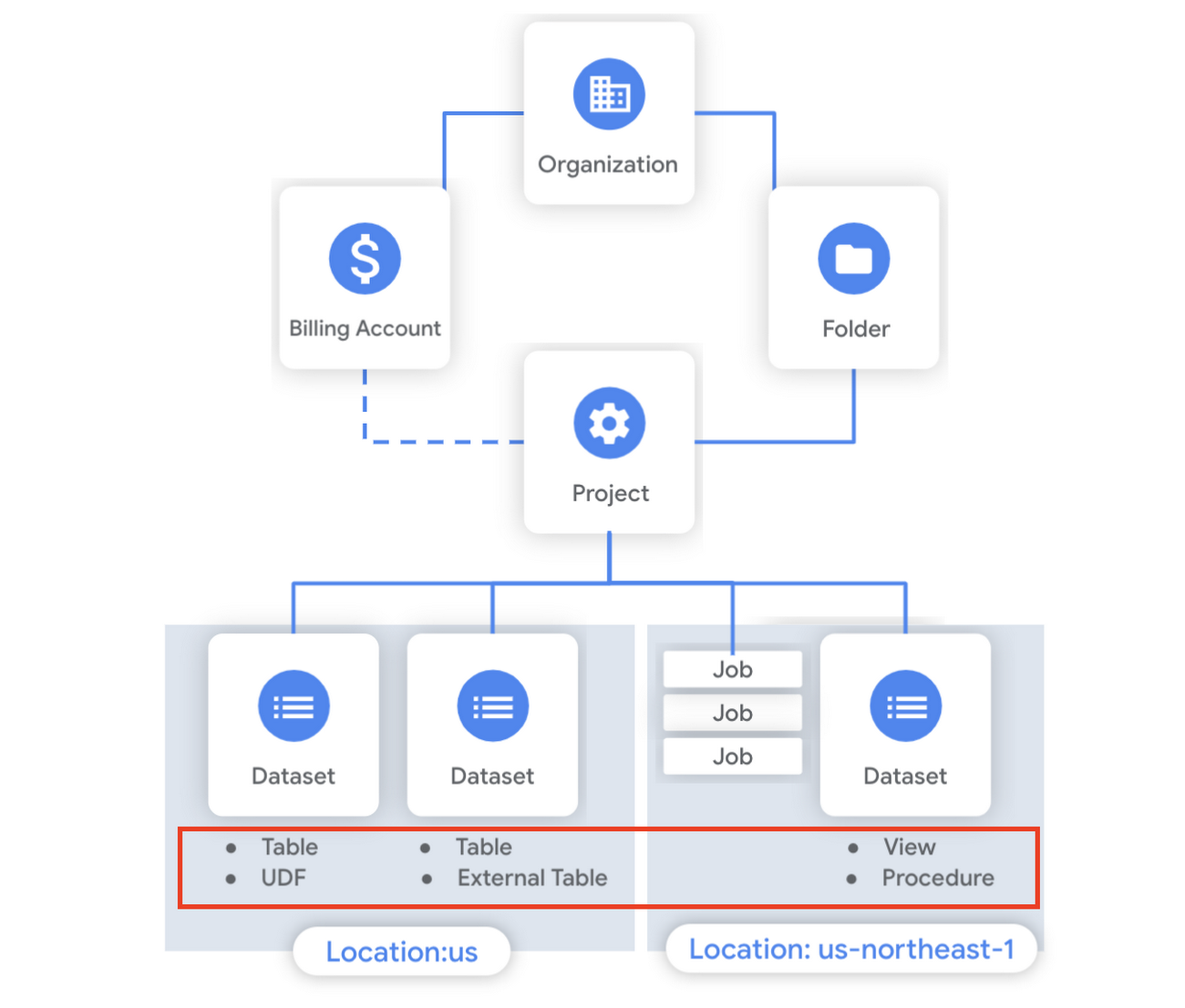
What is a table?
A BigQuery table is a resource that lives inside a dataset. It contains individual records organized into rows, with each record composed of columns (also called fields) where a specified data type is enforced. BigQuery supports numerous different data types including GEOGRAPHY for geospatial data, STRUCT and ARRAY for more complex data, and new parameterized data types to add specific constraints like the number of characters in a string.
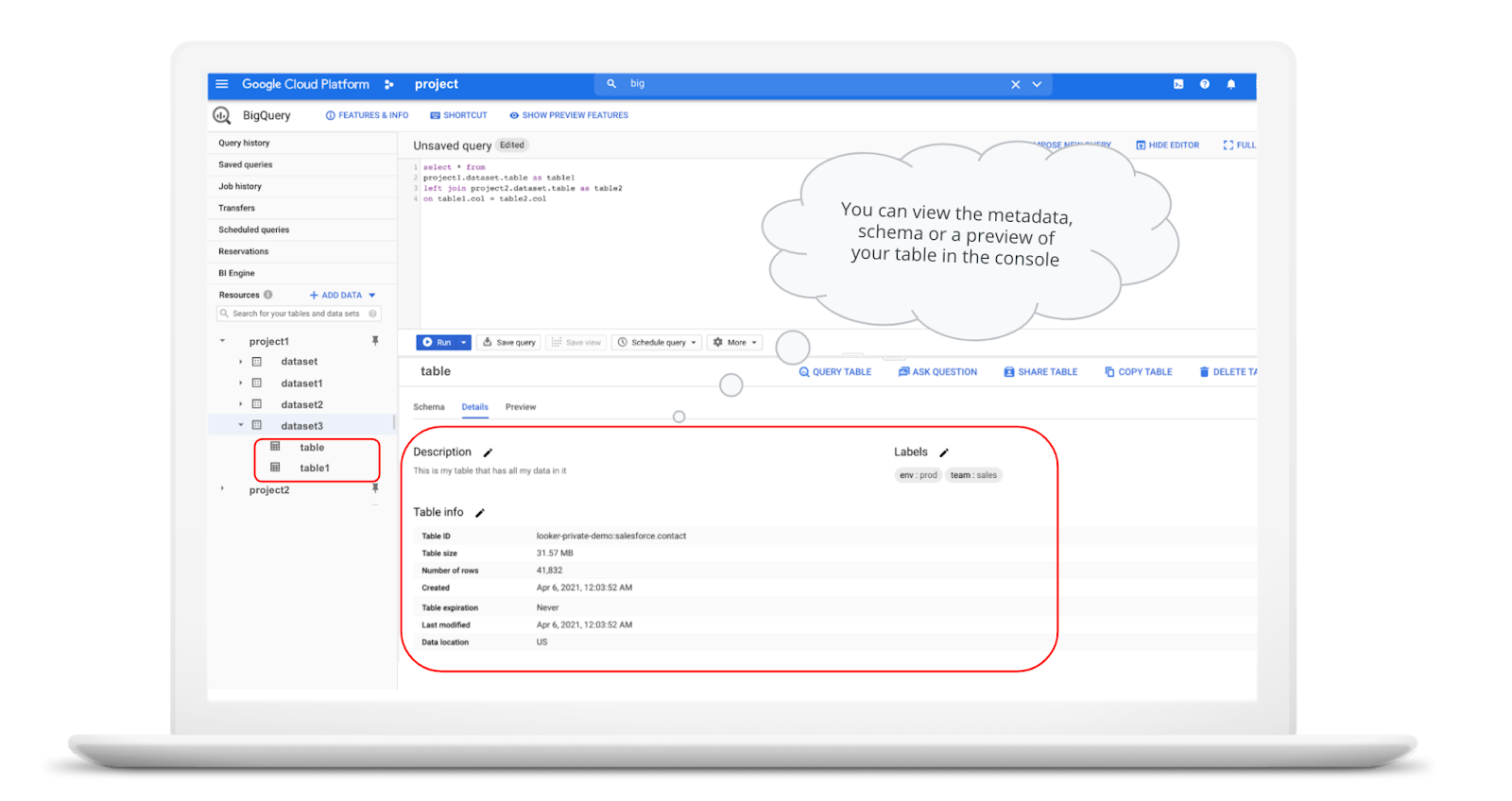
Data access can also be controlled at the table, row and column levels; more details on data governance will be covered later in the series. Metadata, such as descriptions and labels, can be used for surfacing information to end users and as tags for monitoring. You can create and manage a table directly in the UI, through the API / Client SDKs or in a SQL query using a DDL statement.
Managed and external tables
Managed tables are tables that are backed by native BigQuery storage, which has many benefits that improve query performance including support for partitions and clusters. We’ll cover more details on BigQuery storage later in this series. Another advantage of using a managed table is that BigQuery allows you to use time travel to access data from any point within the last seven days and query data that was updated, expired or deleted. And now you can even create a snapshot of your table, to preserve its contents at a given time.
While managed tables store data inside BigQuery storage, external tables are backed by storage external to BigQuery. BigQuery currently supports creating an external table from Cloud Storage, Cloud Bigtable and Google Drive. Besides an external table, you can create a connection to Cloud SQL, which is somewhat analogous to an external dataset. Here, you can leverage federated queries to send a query that executes in Cloud SQL but returns the results to be used within BigQuery.
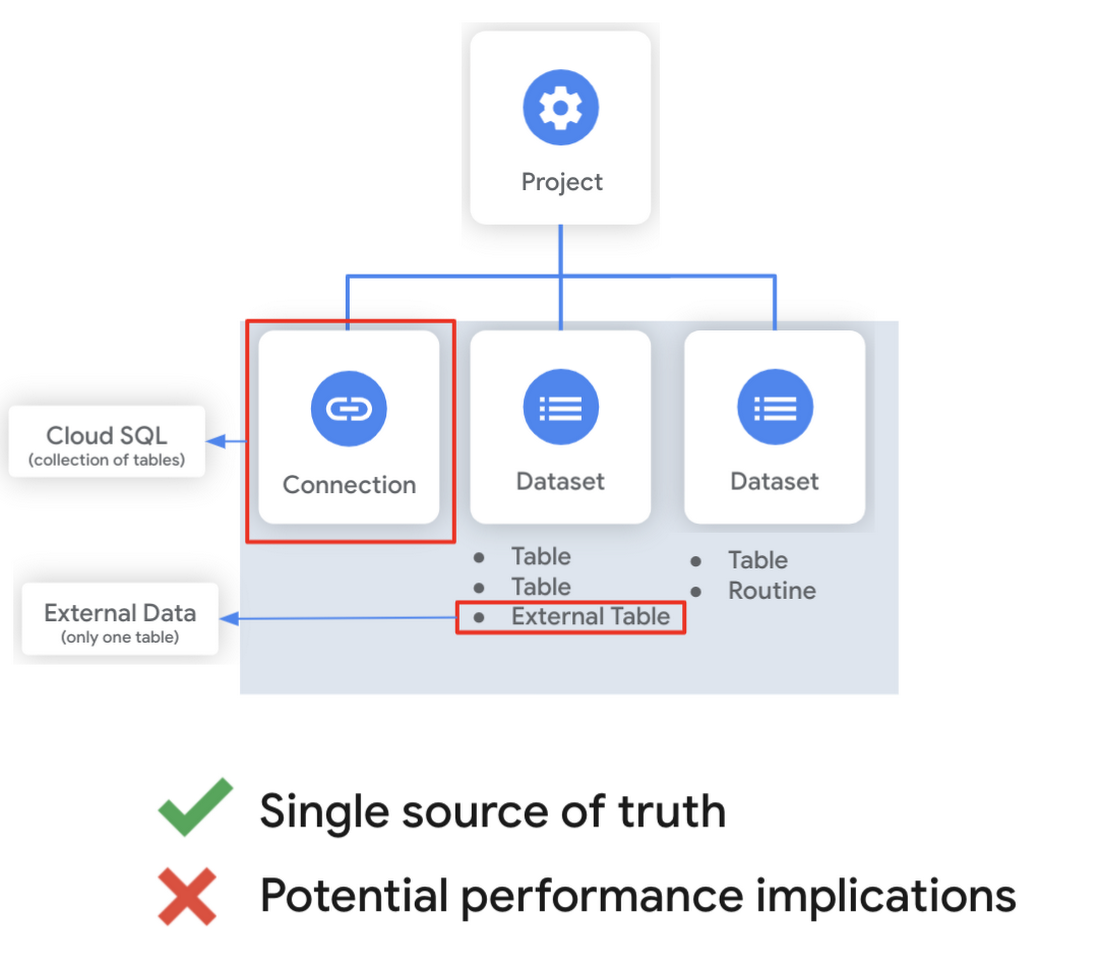
Using external tables or federated queries may result in queries that aren’t as fast as if the data had been stored in BigQuery itself. However, they can be useful for some data transformation patterns - for example, you may want to schedule a DDL/DML query that hydrates a managed table using a federated query, which selects and transforms data from Cloud SQL. An external table might also be useful for multi-consumer workflows where BQ storage isn’t the source of truth. Like, if you have a dataproc cluster accessing data in a Cloud Storage bucket that you’re not quite ready to port into BigQuery (although I do recommend taking a look at our connector if you need some convincing). You can learn more about querying external data in this video.
Logical and materialized views
In BigQuery, you can create a virtual table with a logical view or a materialized view. With logical views, BigQuery will execute the SQL statement to create the view at run time, it will not save the result anywhere. Additionally, you can grant users access to an authorized view to share query results without giving them access to the underlying tables.
On the other hand, materialized views are re-computed in the background when the base data changes. No user action is required - they are always fresh! Better yet, if a query, or part of a query, against the source table can be resolved by querying the materialized view, BigQuery will reroute for improved performance. However, materialized views use a restricted SQL syntax and a limited set of aggregation functions. You can find details on limitations here.
Temporary and cached results tables
Aside from the tables we’ve mentioned so far, you can also create a temporary managed table using the TEMP or TEMPORARY keyword. This table is saved in BigQuery storage and can be referenced for the duration of the script. Temporary tables can be a good alternative to WITH clauses because the defining query is only executed once as opposed to being inlined every place the alias is referenced.Original code | Optimized |
with a as ( select ... ), b as ( select ... from a ... ), c as ( select ... from a ... ) select b.dim1, c.dim2 from b, c; | create temp table a as select …; with b as ( select ... from a ... ), c as ( select ... from a ... ) select b.dim1, c.dim2 from b, c; |
It’s also important to mention that BigQuery writes all query results to a table - one either explicitly identified by the user or to a cached results table. Temporary, cached results tables are maintained per-user, per-project. There are no storage costs for temporary tables.
User defined functions & procedures
In BigQuery, a routine is either a user defined function (UDF) or a procedure. Routines allow you to re-use logic and handle your data in a unique way. A UDF is a function that is created using either SQL or Javascript, it takes arguments as input and returns a single value as an output. UDFs are often used for cleaning or re-formatting data. For example, extracting parameters from a URL string, restructuring nested data, or cleaning up strings:
We even have a community driven open-source repository of BigQuery UDFs! Just like logical views, you can create an authorized UDF that protects aspects of the underlying data. For more details on UDFs checkout our video here. You might also want to take a look at table functions - a preview feature where you can create a SQL UDF that returns a table instead of a scalar value.
Procedures, on the other hand, are blocks of SQL statements that can be called from other queries. Unlike UDFs, stored procedures can return multiple values or no values - which means you can run them to create or modify tables. In BigQuery, you can also leverage scripting capabilities within procedures to control execution flow with IF and WHILE statements. Plus, you can call your UDFs within your procedure! These aspects make procedures great for extract-load-transform (ELT) driven workflows.
To ensure consistent analytics across your organization, I recommend that you create a library dataset to house UDFs and procedures. You can easily grant everyone in your organization the BigQuery Data Viewer role to the library dataset so that all analysts use consistent and up-to-date logic in their queries.
Stay tuned!
We hope this gave you an understanding of how to leverage some of the different resources inside of a BigQuery dataset, and to help you make decisions like using native versus external storage, logical versus materialized views, and user defined functions or procedures.
Next up we’ll be talking about workload management in BigQuery by taking a look at jobs and the reservation model. Be sure to keep an eye out for more in this series by following me on LinkedIn and Twitter, and subscribing to our Youtube channel.




