GCP 上のサーバーレス技術を活用することで最小限の人員で規模の拡大を可能に - Guesswork.co の事例
Google Cloud Japan Team
※この投稿は米国時間 2018 年 5 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: Mani Doraisamy 氏は Google Cloud Platform を基盤として 2 つのサービス(Guesswork.co と CommerceDNA)を構築しました。このブログ投稿では、拡大し続ける顧客基盤がもたらす需要の変化に対応しながらも高い費用対効果を維持するため、アプリケーション アーキテクチャをどのように進化させたか、同氏はその経験を語ります。
このようなワークロードをサポートできるスケーラブルなシステムを構築するのは簡単ではありません。顧客別に大量のデータ処理が発生するだけでなく、ユーザー数についても、毎月何億人分のデータに対応する必要があります。さらに、ショッピング シーズンのピーク時にはトラフィックが急増することもあります。
独立独歩のスタートアップである Guesswork は、システムを設計するにあたり 3 つの目標を掲げました。
少人数を維持する: デベロッパー 3 人という小さなチームだった Guesswork は、スケールアップして膨大な数のユーザーに対応する必要がある場合でも人員は増やしたくありませんでした。
利益体質を維持する: Guesswork の収益はレコメンデーション エンジンの性能で決まります。お客様企業は決まった料金を毎月支払うのではなく、Guesswork が提供したレコメンデーションを見たユーザーが商品を購入した場合に、その分のコミッションを支払います。このようなビジネスモデルを採用しているため、アプリケーション アーキテクチャとインフラストラクチャのコストは、利益を上げられるかどうかを左右する重要な要因となっています。
制約を受け入れる: 開発スピードを上げ、柔軟性を維持するために、自社で開発スタックを管理するのは諦め、マネージド クラウド サービスの利用に伴う制約を受け入れることにしました。
これら 3 つの目標は、「資金調達よりもコードの最適化」という標語になりました。ビジネスの目標をコーディングの問題に変えたことで、楽しさもはるかに増えました。弊社の経験を、皆さんが業務を改善するうえでの参考にしていただければ幸いです。
データベースの選択: 3 つのプロダクト
最初に注目したスタックはデータベース層です。マネージド サービス上にシステムを構築したかったため、Google Cloud Platform(GCP)を採用することにしました。スケーリングの点で GCP はクラス最高の選択肢だと私たちは考えています。
しかし、クラウド データベースは従来のデータベースとは異なり、汎用性がありません。それぞれ用途が決まっているのです。そのため、私たちはトランザクション、分析、機械学習の各ワークロード用に 3 つのデータベースを別々に選択しました。選択したプロダクトは次のとおりです。
Cloud Datastore: 大量の書き込みをサポートできるため、トランザクション データベースとして選択しました。Guessworkでは、発生するユーザー イベントが数十億件単位にも及び、それらの更新情報はリアルタイムに Cloud Datastore に書き込まれます。
BigQuery: ユーザー行動の分析に使用します。たとえば、ファッション ブログからの購入者のほとんどが、特定のタイプのフォーマルシューズを買っていることが BigQuery の分析によって判明しました。
Vision API: 商品画像を分析して商品を分類する処理に使用します。弊社は、さまざまな地域の e コマース企業と提携しているため、商品名や説明文の言語もさまざまです。テキストを分析するより画像で商品を分類するほうが効率的です。このデータを BigQuery と Cloud Datastore のユーザー行動データと組み合わせることで、商品レコメンデーションを作成します。
テイク 1: App Engine を使用したアプローチ
データベースの選択が終わったら、次はフロントエンド サービス選びです。e コマース企業のウェブサイトからユーザー イベントを受信して Cloud Datastore を更新する、という一連の処理を行います。これには App Engine を選択しました。マネージド サービスであることと、Guesswork ほどの処理量があっても優れたスケーラビリティを発揮することが、その理由です。Cloud Datastore 内のユーザー イベントを App Engine で更新したら、Cloud Dataflow を使用してこのデータを BigQuery とレコメンデーション エンジンに取り込んで同期します。Cloud Dataflow もマネージド サービスですが、こちらはさまざまなデータベースをリアルタイムに(ストリーミング モードで)オーケストレートします。
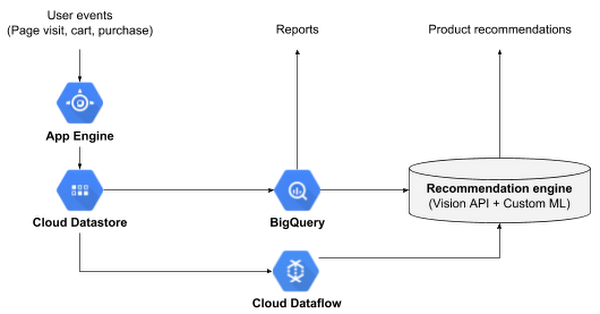
このアーキテクチャは Guesswork のサービスの最初のバージョンで使用したものです。ビジネスが成長するにつれて、お客様は新しい機能を求めるようになりました。そのうちの 1 つとして、商品価格が変更されたらアラートを送って欲しい、という要望がありました。そのため、次回のバージョンでは、e コマースサイトでの価格変更のリスニングを開始し、価格変更が検知されたらアラートを送信するイベントをトリガーするようにしました。商品の価格はユーザー イベントとして Cloud Datastore にすでに記録されていますが、変更を検知するには次のような処理が必要でした。
ユーザー イベントで受信した価格を商品マスターと比較し、変更があったかどうかを判断する。
変更があった場合は分析データベースと機械学習データベースに変更内容を伝播し、アラートをトリガーして変更内容を商品レコメンデーションに反映する。
毎日、数百万件のユーザー イベントが発生します。すべてのユーザー イベント データを商品マスターと比較するため、データストアに対する読み取り件数が激増しました。Cloud Datastore の読み取り 1 件 1 件が GCP の毎月の料金に加算されるため、持続不能なレベルまでコストが増大してしまいました。
テイク 2: Cloud Functions を使ったアプローチ
コストを下げるためにシステムを設計し直すことにしましたが、選択肢は 2 つありました。
Memcache を使用して商品マスターをメモリに読み込み、各ユーザー イベントの価格と在庫を比較する方法: この方法を選択した場合、Memcache のメモリにこれほど大量の商品情報を保持できるという保証はありませんでした。そのため、価格変更が検知されず、不正確な商品価格が表示されてしまうおそれがありました。
Cloud Firestore を使用してユーザー イベントと商品データを記録する方法: Firestore には、エンティティの値が変化したら Cloud Functions をトリガーするオプションがあります。弊社では、価格と在庫の変更に応じて、分析データベースと機械学習データベースを更新するクラウド ファンクションが自動的にトリガーされるようにしました。
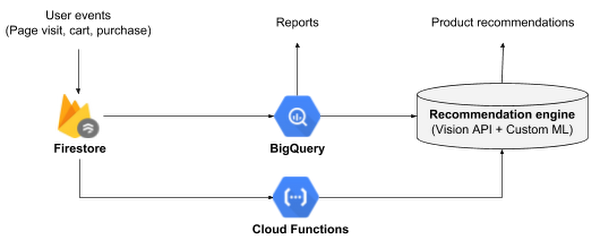
私たちが設計を見直しているとき、Firestore と Cloud Functions はアルファ版でしたが、シンプルですっきりしたアーキテクチャになるため、この 2 つを使用することに決めました。
App Engine と Datastore は両方とも Firestore に置き換えました。Firestore を使用すると、App Engine のようなフロントエンド サービスがなくても、ユーザー リクエストをブラウザから直接受け取ることができます。また、Datastore のようにスケーラビリティも優れています。
Cloud Functions は、価格と在庫に関するアラートをトリガーするための手段としてだけでなく、Firestore と BigQuery とレコメンデーション エンジンの三者間でデータを同期するオーケストレーション ツールとしても使用しました。
Cloud Functions のスケーラビリティはアルファ版であっても非常に優れていたため、これは結果的に良い判断となりました。たとえば、ブラック フライデーにはユーザー数が 100 万人から 2,000 万人へと急増します。この新しいアーキテクチャでは、Dataflow のストリーミング機能を Cloud Functions のトリガー機能に置き換え、Dataflow のパイプライン変換よりもわかりやすい言語(JavaScript)を使用しました。Cloud Functions は最終的に、すべてのコンポーネントを結合させる接着剤の役目を果たしました。
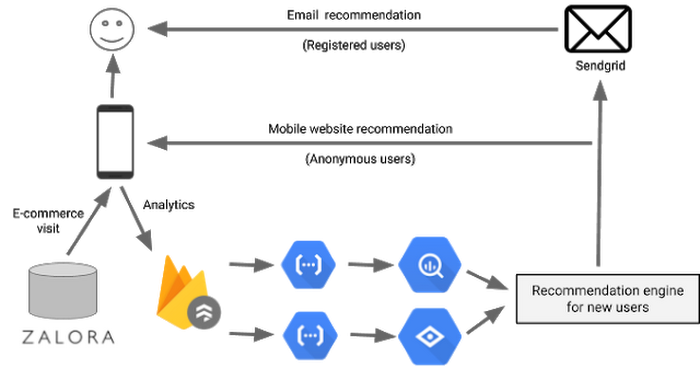
達成した成果
サーバーレスなマイクロサービス指向アーキテクチャは柔軟性に優れているため、ビジネスニーズの変化に合わせてコンポーネントの置き換えとアップグレードができ、システム全体を設計し直す必要がありませんでした。利益体質を維持するという重要な目標は、マネージド サービスを適切に組み合わせて使用することと、インフラコストを収益よりかなり低く抑えることで達成しました。また、サーバーを管理する必要がなかったため、小さなエンジニアリング チームでビジネスを拡大でき、夜も安心して眠れました。
そのうえ、当初は予想していなかったすばらしい成果もありました。
レコメンデーションの精度向上によりコミッションが増加
この新しいバージョンで得られた一番の収穫は、新しいアルゴリズムの A/B テスト機能です。たとえば、Android スマートフォンで e コマースサイトを閲覧するユーザーのほうが特売商品を購入する確率が高いことがわかりました。そこで、ユーザーのデバイスを特徴としてレコメンデーション アルゴリズムに含め、少人数のユーザーを対象にしてこのアルゴリズムをテストしました。Cloud Functions は(Cloud Pub/Sub で)ゆるやかに結合されているため、新しいアルゴリズムを実装し、ユーザーをデバイスと地域に基づいてリダイレクトすることができました。アルゴリズムで良い結果が出たら、システムを停止せずにすべてのユーザーにアルゴリズムを展開しました。この方法で絶えずレコメンデーションの精度を改善することで、収益を増やすことができました。
アルゴリズムの最適化によりコストを削減
直感に反するようですが、コンピューティングにかける費用を増やせば精度が向上するというわけではないこともわかりました。たとえば、1 か月間のユーザー イベントと最新のセッションのイベントを対比させて分析を行い、ユーザーが次に購入する可能性が高い商品を予測しました。その結果わかったのは、データポイントは少なくても最新のセッションのほうが精度は高いということでした。アルゴリズムは、シンプルかつ直感的であればあるほど、パフォーマンスが向上するのです。Cloud Functions はモジュール構造であるため、モジュールごとにリファクタリングし、精度を損なわずにコストを削減できました。
外部の IT チームへの依存度を抑え、より多くの顧客と契約を締結
大企業と提携した場合はその企業の IT チームと連携することになるため、ソリューションの統合に時間がかかる場合があります。Cloud Functions を使用すると、顧客ごとに構成可能なモジュールを実装できます。たとえば、フランスの e コマース企業と提携しているときは、ユーザー イベントで受信した商品詳細情報を英語に翻訳する必要がありました。Cloud Functions は Node.js をサポートしているため、スクリプトで操作できるモジュールを JavaScript で各顧客に対して有効にすることで、お客様の IT チームの対応を待つのではなく、Guesswork 側で翻訳を実装できるようになりました。そのため、本稼働までの期間が数か月から数日に短縮され、そうでなければ必要な時間と労力を先行投資できなかったかもしれない新しいお客様と契約できました。
Cloud Functions は当時アルファ版であったため、ヘッドレス Chrome を実行するといった規格外の機能を実装するときに複数の課題に直面しました。そのような場合は App Engine フレキシブル環境と Compute Engine にフォールバックしました。それでも、必要な機能の大半は Cloud Functions プロダクト チームが徐々にマネージド環境に戻してくれたため、メンテナンスが簡素化され、機能の開発に取り組む時間が増えました。
活発な開発に期待
この事例に学べることが 1 つあるとすれば、「1,000 万人のユーザーにサービスを提供する独立独歩のスタートアップを 3 人のデベロッパーで運営している例など、ほんの 5 年前には聞いたことがなかった」ということでしょう。複数のクラウド プラットホームにおける抽象化が絶えず追求されてきたおかげで、これが現実になりました。サーバーレス コンピューティングとは、この抽象化の最先端で進化を続けているコンセプトです。さまざまなサーバーレス コンピューティング サービスがありますが、Cloud Functions は GCP のデータ プロダクトとそれらが持つ無限ともいえるスケールを土台にしたサービスであるため、競合サービスより優位に立っていると思います。シンプルさとスケールを併せ持つ Cloud Functions を統合ポイントにすることで、GCP はコンポーネントの単なる集合体ではなくなります。独立独歩のスタートアップが Gmail や Salesforce のような大規模なアプリケーションを構築できる日がやって来ました。今回ご紹介したのは、そのような事例の 1 つです。今後、新たな活用事例が公開されることを楽しみにしております。
-by Mani Doraisamy, Guesswork.co の創業者



