Scale big while staying small with serverless on GCP — the Guesswork.co story
Mani Doraisamy
Founder, Guesswork.co
[Editor’s note: Mani Doraisamy built two products—Guesswork.co and CommerceDNA—on top of Google Cloud Platform. In this blog post he shares insights into how his application architecture evolved to support the changing needs of his growing customer base while still staying cost-effective.]
Guesswork is a machine learning startup that helps e-commerce companies in emerging markets recommend products for first-time buyers on their site. Large and established e-commerce companies can analyze their users' past purchase history to predict what product they are most likely to buy next and make personalized recommendations. But in developing countries, where e-commerce companies are mostly focused on attracting new users, there’s no history to work from, so most recommendation engines don’t work for them. Here at Guesswork, we can understand users and recommend them relevant products even if we don’t have any prior history about them. To do that, we analyze lots of data points about where a new user is coming from (e.g., did they come from an email campaign for t-shirts, or a fashion blog about shoes?) to find every possible indicator of intent. Thus far, we’ve worked with large e-commerce companies around the world such as Zalora (Southeast Asia), Galeries Lafayette Group (France) and Daraz (South Asia).
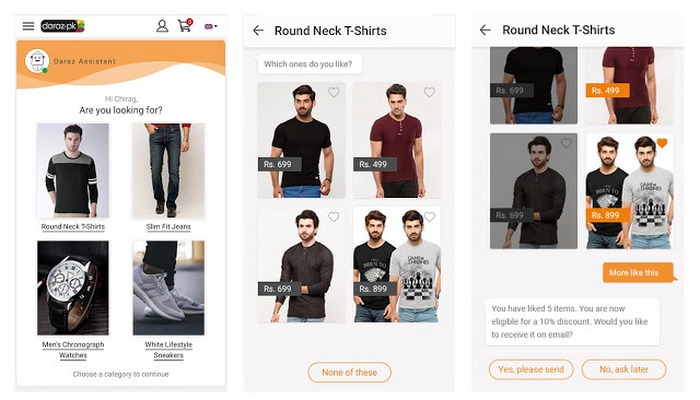
Building a scalable system to support this workload is no small feat. In addition to being able to process high data volumes per each customer, we also need to process hundreds of millions of users every month, plus any traffic spikes that happen during peak shopping seasons.
As a bootstrapped startup, we had three key goals while designing the system:
- Stay small. As a small team of three developers, we didn’t want to add any additional personnel even if we needed to scale up for a huge volume of users.
- Stay profitable. Our revenue is based on the performance of our recommendation engine. Instead of a recurring fee, customers pay us a commission on sales to their users that come from our recommendations. This business model made our application architecture and infrastructure costs a key factor in our ability to turn a profit.
- Embrace constraints. In order to increase our development velocity and stay flexible, we decided to trade off control over our development stack and embrace constraints imposed by managed cloud services.
Choosing a database: The Three Musketeers
The first stack we focused was the database layer. Since we wanted to build on top of managed services, we decided to go with Google Cloud Platform (GCP)—a best-in-class option when it comes to scaling, in our opinion.
But, unlike traditional databases, cloud databases are not general purpose. They are specialized. So we picked three separate databases for transactional, analytical and machine learning workloads. We chose:
- Cloud Datastore for our transactional database, because it can support high number of writes. In our case, the user events are in the billions and are updated in real time into Cloud Datastore.
- BigQuery to analyze user behaviour. For example, we understand from BigQuery that users coming from a fashion blog usually buy a specific type of formal shoes.
- Vision API to analyze product images and categorize products. Since we work with e-commerce companies across different geographies, the product names and descriptions are in different languages, and categorizing products based on images is more efficient than text analysis. We use this data along with user behaviour data from BigQuery and Cloud Datastore to make product recommendations.
First take: the App Engine approach
Once we chose our databases, we moved on to selecting the front-end service to receive user events from e-commerce sites and update Cloud Datastore. We chose App Engine, since it is a managed service and scales well at our volumes. Once App Engine updates the user events in Cloud Datastore, we synchronized that data into BigQuery and our recommendation engine using Cloud Dataflow, another managed service that orchestrates different databases in real time (i.e., streaming mode).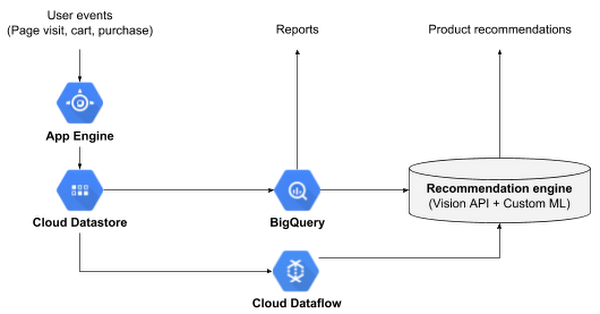
This architecture powered the first version of our product. As our business grew, our customers started asking for new features. One feature request was to send alerts to users when the price of a product changed. So, in the second version, we began listening to price changes in our e-commerce sites and triggered events to send alerts. The product’s price is already recorded as a user event in Cloud Datastore, but to detect change:
- We compare the price we receive in the user event with the product master and determine if there is a difference.
- If there is a difference, we propagate it to the analytical and machine learning databases to trigger an alert and reflect that change in the product recommendation.
Take two: the Cloud Functions approach
To bring down our costs, we had two options for redesigning our system:- Use memcache to load the product master in memory and compare the price/stock for every user event. With this option, we had no guarantee that memcache would be able to hold so many products in memory. So, we might miss a price change and end up with inaccurate product prices.
- Use Cloud Firestore to record user events and product data. Firestore has an option to trigger Cloud Functions whenever there’s a change in value of an entity. In our case, the price/stock change automatically triggers a cloud function that updates the analytical and machine learning databases.
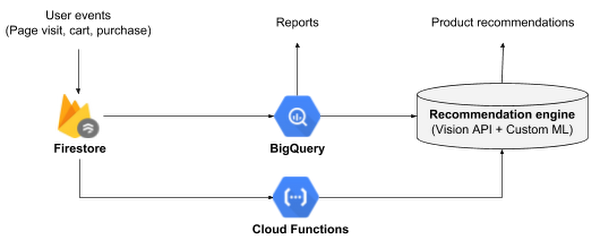
During our redesign, Firestore and Cloud Functions were in alpha, but we decided to use them as it gave us a clean and simple architecture:
- With Firestore, we replaced both App Engine and Datastore. Firestore was able to accept user requests directly from a browser without the need for a front-end service like App Engine. It also scaled well like Datastore.
- We used Cloud Functions not only as a way to trigger price/stock alerts, but as an orchestration tool to synchronize data between Firestore, BigQuery and our recommendation engine.
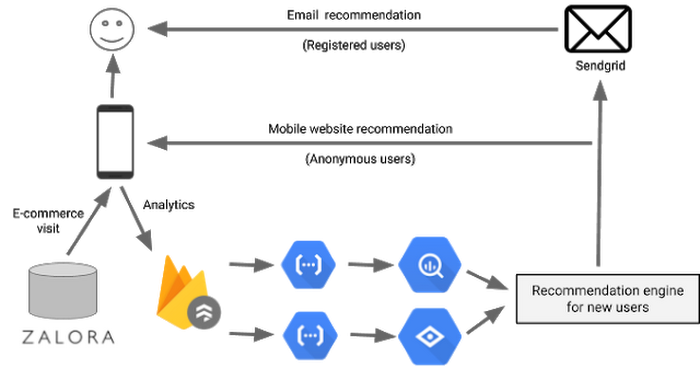
What we gained
Thanks to the flexibility of our serverless microservice-oriented architecture, we were able to replace and upgrade components as the needs of our business evolved without redesigning the whole system. We achieved the key goal of being profitable by using the right set of managed services and keeping our infrastructure costs well below our revenue. And since we didn't have to manage any servers, we were also able to scale our business with a small engineering team and still sleep peacefully at night.Additionally, we saw some great outcomes that we didn't initially anticipate:
- We increased our sales commissions by improving recommendation accuracy
The best thing that happened in this new version was the ability to A/B test new algorithms. For example, we found that users who browse e-commerce sites with an Android phone are more likely to buy products that are on sale. So, we included user’s device as a feature in the recommendation algorithm and tested it with a small sample set. Since, Cloud Functions are loosely coupled (with Cloud Pub/Sub), we could implement a new algorithm and redirect users based on their device and geography. Once the algorithm produced good results, we rolled it out to all users without taking down the system. With this approach, we were able to continuously improve the accuracy of our recommendations, increasing revenue.
- We reduced costs by optimizing our algorithm
As counter intuitive it may sound, we also found that paying more money for compute didn't improve accuracy. For example, we analyzed a month of a user’s events vs. the latest session’s events to predict what the user was likely to buy next. We found that the latest session was more accurate even though it had less data points. The simpler and more intuitive the algorithm, the better it performed. Since Cloud Functions are modular by design, we were able to refactor each module and reduce costs without losing accuracy.
- We reduced our dependence on external IT teams and signed more customers
We work with large companies and depending on their IT team, it can take a long time to integrate our solution. Cloud Functions allowed us to implement configurable modules for each of our customers. For example, while working with French e-commerce companies, we had to translate the product details we receive in the user events into English. Since Cloud Functions supports Node.js, we enabled scriptable modules in JavaScript for each customer that allowed us to implement translation on our end, instead of waiting for the customer’s IT team. This reduced our go-live time from months to days, and we were able to sign up new customers who otherwise might not have been able to invest the necessary time and effort up-front.



