Telegraph Media Group が Google Cloud で Single Customer View を実現して分析情報を獲得
Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
昨今のデータドリブンな世界において、さまざまな業界の多くの組織が、自社の顧客について詳細に理解するための手法を模索しています。Single Customer View(SCV、360 度顧客ビューとも呼ばれます)は、データ エンジニアリングにおける強力なコンセプトとして登場したものであり、企業はこれを活用することで、サイロ化された複数のデータソースから顧客データを集めて一元化できるようになります。さまざまなデータポイントをただひとつの包括的なビューに統合することで、価値ある分析情報を獲得し、一人ひとりに合わせたエクスペリエンスを創出して、データに基づいた意思決定を行えるようになります。今回のブログ投稿では、Telegraph Media Group(TMG)が Google Cloud を使用してどのように SCV を構築したか、そして、私たちがこの経験から何を学んだかについてご紹介します。
TMG は、The Daily Telegraph、The Sunday Telegraph、The Telegraph Magazine、Telegraph.co.uk、Telegraph アプリを手掛けているパブリッシャーです。私たちは定期購入ベースのビジネスを運営しており、従来型の印刷メディアと、ウェブサイトや各種モバイルアプリなどを含むデジタル チャネルの両方を通じてニュース コンテンツを提供しています。TMG は当初、ユーザーが無料で利用できる、広告ベースの収益モデルを利用して運営していましたが、時が経つにつれて、このモデルの課題が徐々に浮き彫りになってきました。ニュース メディアを扱う他の多くのパブリッシャーと同じく、TMG も、紙媒体の読者数の低下、コンテンツ パブリッシャーの広告収益の下落、広告収入の不安定化などの長期傾向を目の当たりにしてきました。そのような状況のために収益の見通しが不明瞭になり、また、今後の成長がどうなるかわからない状況に陥りました。
2018 年、私たちは、質の高いジャーナリズムの精神を忘れることなく、定期購入者を主軸に置いたビジネスにシフトして、定期購入者との深いつながりを大規模に構築するという大胆な目標を設定しました。TMG は定期購入の手法を重視することで、より安定した収益源を構築し、より大きな成果につながる広告サービスを実現することを試みました。目標は、5 年以内に 100 万人の定期購入を達成するというものでしたが、2023 年 8 月にこの目標を達成することができました。
私たちが構築した SCV プラットフォームでは、すべてのデジタル ドメインにおける顧客のデジタル上の行動に関するデータと、TMG の定期購入に関するデータの 2 つのデータリソースが主として活用されています。また、パートナーのショッピング ウェブサイトや、fantasy football や puzzles などといったエンゲージメント プロダクトなどのサードパーティ ソースから来るデータとも統合されています。このような多様性に富んだデータソースが、プラットフォームでオーディエンスを把握し、包括的なニュース エクスペリエンスを創出するためにきわめて重要となります。
SCV 構築の全体としてのプロセスは、次のように複数のステージに概念化することができます。
-
データの収集: 最初のステージでは、さまざまなソースからデータを集め、それをデータレイクとして機能する BigQuery に読み込みます。データは、データベース、API、ファイルなどのさまざまなソースから、複数の手法を用いて抽出され、BigQuery に取り込まれます。BigQuery に取り込まれたデータは一元的に管理され、その後の処理で使用されます。
-
データ変換: このステージでは、BigQuery から取得されたデータが処理され、定義されたビジネスルールに従って変換されます。このデータはクレンジング、標準化、拡充され、データの品質と整合性が維持されます。このデータは BigQuery 内の新しいデータセットに、SCV データモデルと呼ばれる構造化された形式で保存されるため、容易にアクセスと分析を行えます。
- データ プレゼンテーション: データを変換して BigQuery データレイクに保存すると、そのデータをデータマートと呼ばれる小規模で特殊なデータセットに整理できます。このデータマートは、特定のユーザー グループや部門のために役立てられるものです。メール マーケティング システムなどのサードパーティのアクティベーション ツールで、調整済みで事前に集計された状態のデータを、内部の意思決定プロセスに役立てられるレポートおよび可視化ツールとともに使用できるようになります。
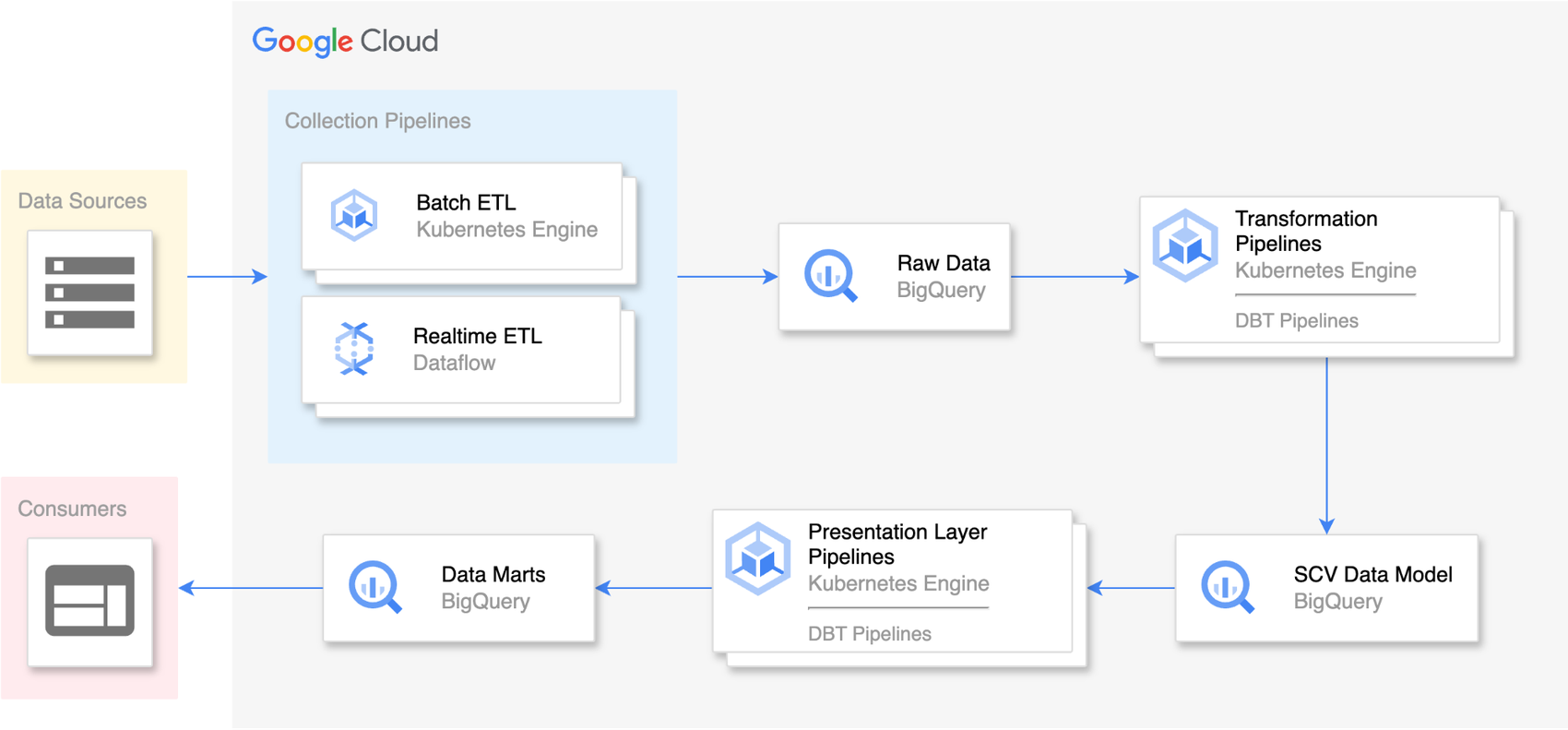
ステージ 1: データの収集
TMG の定期購入に関するデータはすべて Salesforce に保存されています。私たちは、このデータを集めて BigQuery に保存する合理化されたプロセスを実装しました。
まず、Apache Airflow(正確には Cloud Composer)上で毎分実行される、コンテナ化された Python アプリケーションから構成されるパイプラインを使用します。このパイプラインが最新のデータを Salesforce API から取得し、これを Google Cloud 内のメッセージ サービスである Pub/Sub に転送します。
次に、DataFlow を使用して、Pub/Sub からデータを読み取り、BigQuery 内の各種テーブルを即座に更新するリアルタイム パイプラインを作成して、データに関するリアルタイムの分析情報を取得できるようにしました。
また、日次で実行される、Salesforce からデータを取り込むバッチ処理を実行して、データの整合性が維持されるようにしています。このようにすることで、包括的で完全なデータのビューを維持できるようになるため、リアルタイムの取り込み時に発生する可能性があるデータの損失を補完できます。
TMG ウェブサイトとアプリにおけるユーザーの行動をモニタリングする Adobe Analytics と、コミュニケーション チャネルにおけるユーザーの行動を追跡する Adobe Campaign の両方から来るデータの取り込みにも、同様の手法を採用しています。これらのデータセットでリアルタイムの可用性はさほど重要ではないため、取り込みと処理を行う手段としては、バッチ処理で十分です。また、類似の取り込み方法は他のデータソースにも応用されており、一貫性のある単一のデータ パイプラインの実現に役立てられています。
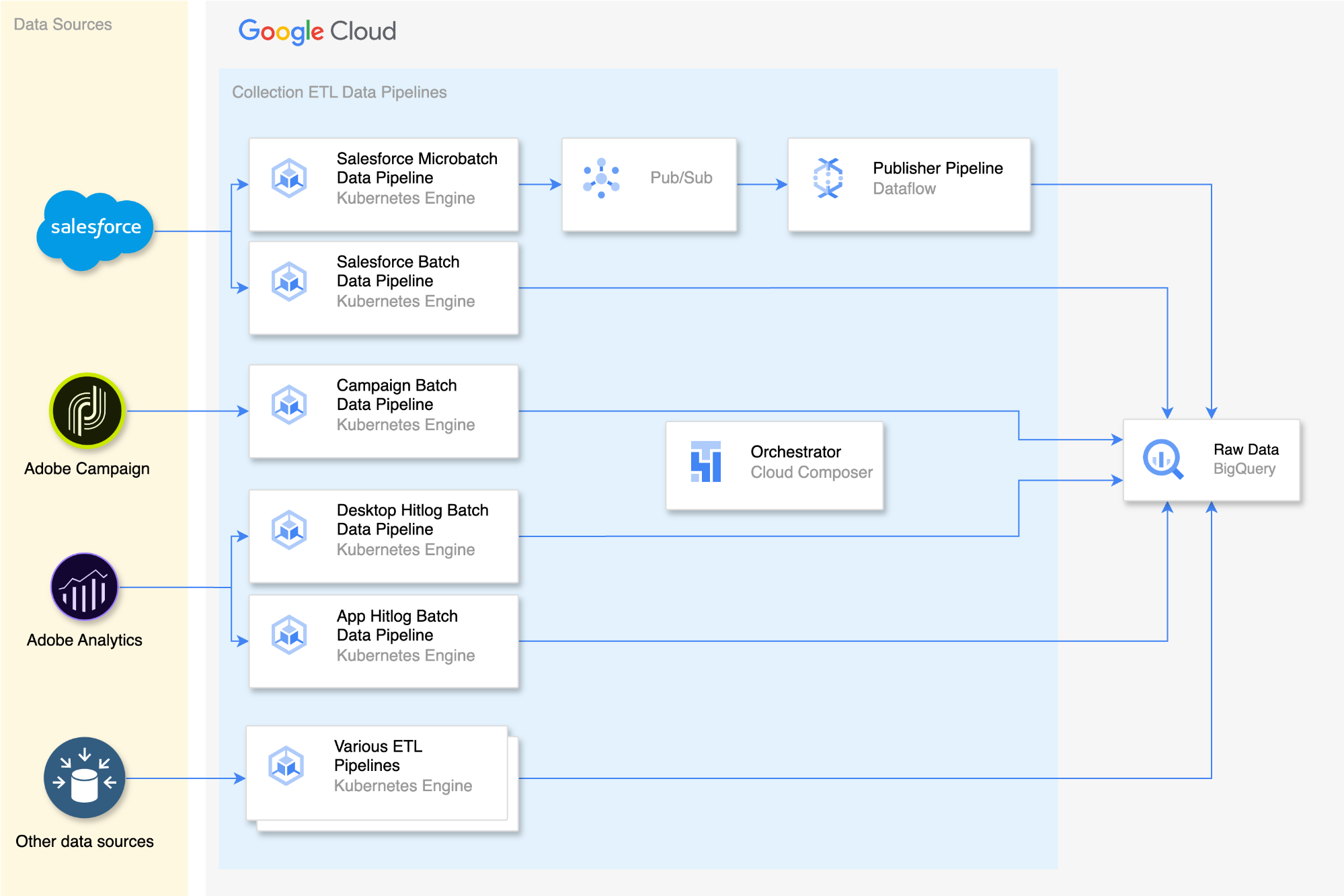
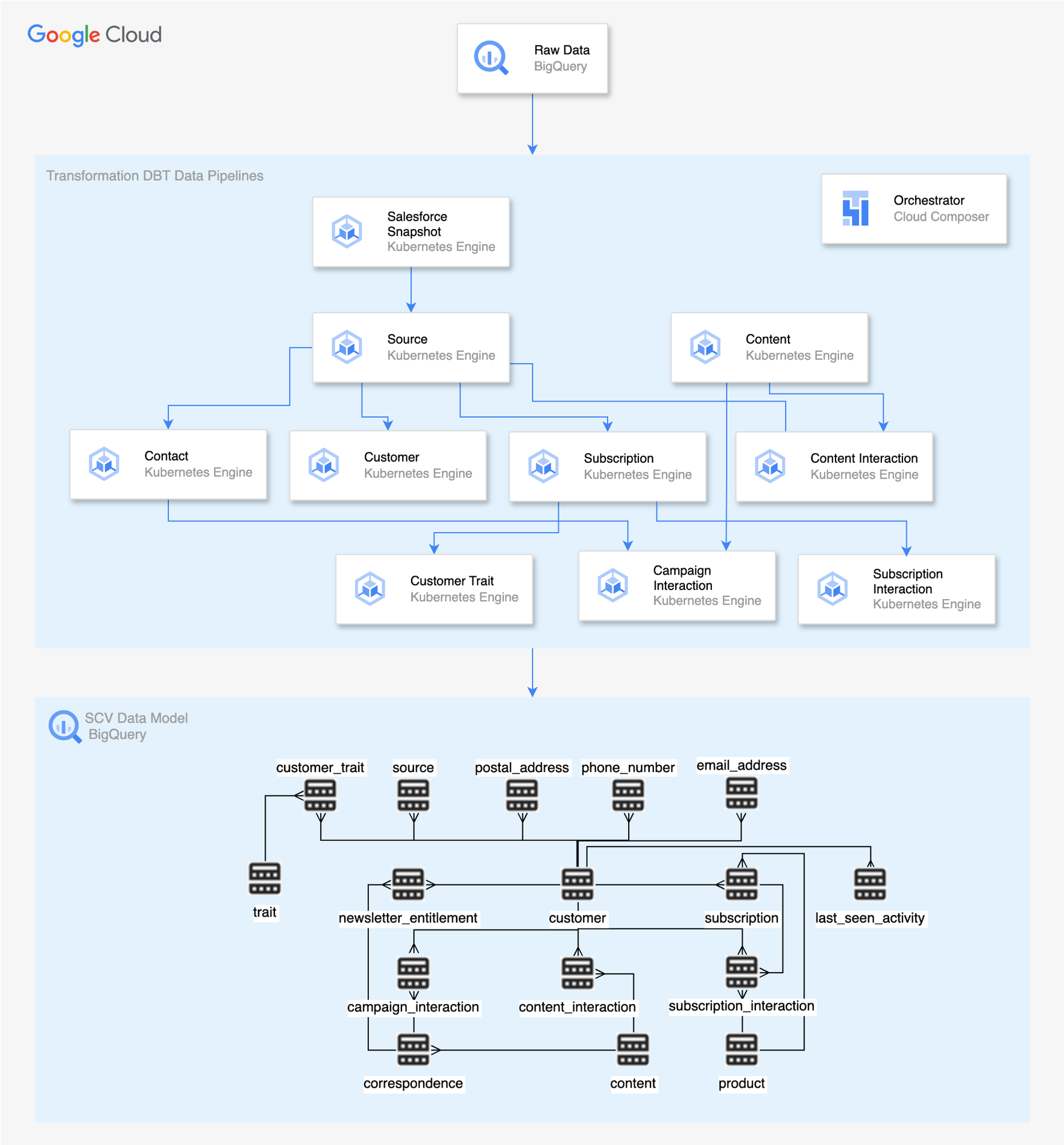
ステージ 2: データの変換
私たちはオープンソースの Data Build Tool(DBT)を使用して、BigQuery の機能を SQL を介して活用してデータを変換しています。私たちは DBT を活用することで、すべてのビジネスルールを SQL に翻訳し、効率的なデータ変換を実現しています。DBT パイプラインは、1 時間ごとに実行されるコンテナ化されたアプリケーションであり、Apache Airflow 上に構築された Cloud Composer を使用してオーケストレーションされます。その結果、これらのデータ パイプラインの出力としてリレーショナル モデルが BigQuery 内に作成されます。これは、さらなる分析や処理のための合理化、整理されたデータとして使用することが可能です。私たちはデータの変換に際して、以下に示す各種の重要なパイプラインを使用しています。
-
Salesforce Snapshot: このパイプラインは、リアルタイム テーブルとバッチテーブルの両方から、Salesforce データのスナップショットを生成します。このスナップショットは、Salesforce 内の利用可能な最新のデータを反映するものであり、変換プロセスの他のパイプラインの重要なソースとして機能します。
-
Source: このパイプラインは、ソースのオリジナルの顧客 ID や新しい顧客 ID などのソースデータを保存するテーブルを作成します。この情報は、オリジナルのデータソースの顧客を識別するための重要な手がかりになります。
-
Customer: このパイプラインは、詳細情報を取得して表示するテーブルを作成します。これは、顧客の属性や特徴を把握できる包括的なビューとして機能します。
-
Contact: このパイプラインは、顧客の各種連絡先情報を保存する複数のテーブルを作成します。
-
Content Interaction: このパイプラインは、各種コンテンツをどのように操作したかなど、顧客のデジタル上の行動を取得するテーブルを生成します。これは、顧客エンゲージメントや顧客の好みの詳細な分析に役立てられます。
-
Subscription Interaction: このパイプラインは、定期購入に関連するイベントとそれに関連する詳細情報を追跡して保存するテーブルを作成します。定期購入に関連した顧客の行動やそのパターンに関する分析情報を把握できます。
- Campaign Interaction: このパイプラインは、異なる複数のチャネル内におけるコミュニケーションの行動に関連するイベントに関する詳細情報を保存するテーブルを作成します。これは、キャンペーンやマーケティング活動に対する顧客エンゲージメントの分析に役立てることが可能です。
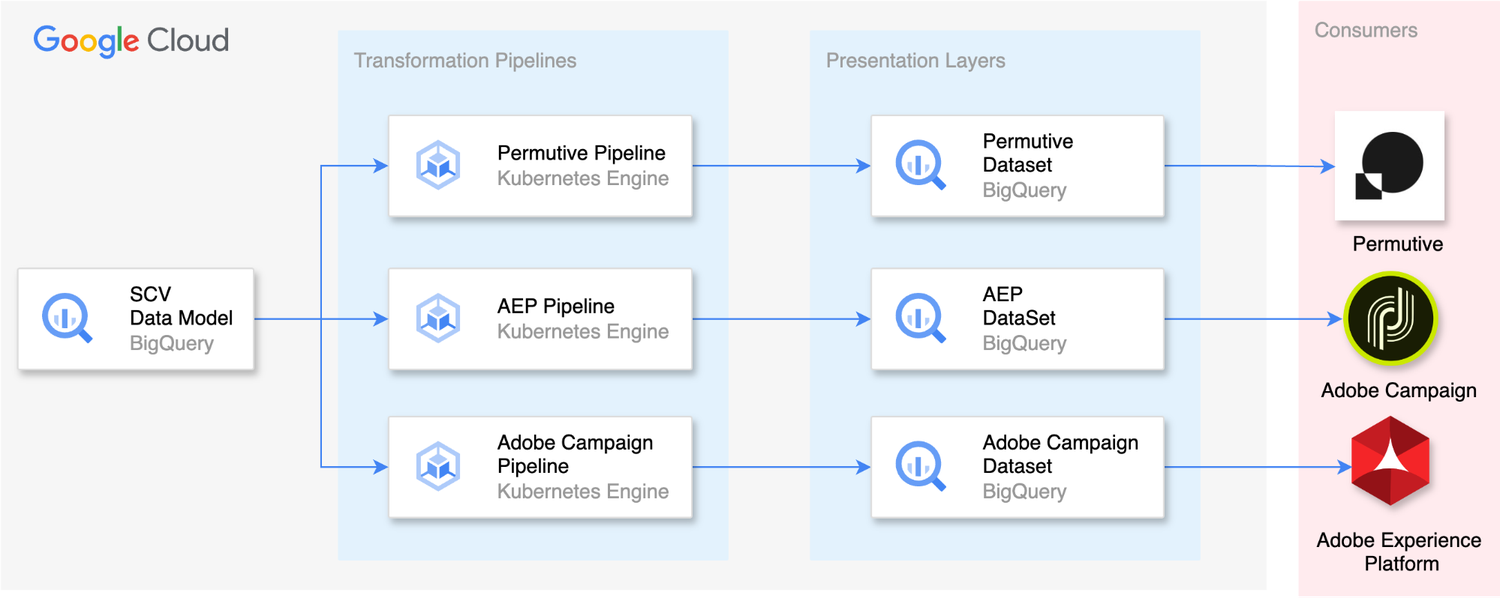
ステージ 3: データ プレゼンテーション
変換レイヤと同様で、SCV データモデルから異なるデータマートにデータを変換するに際して、DBT パイプラインが重要な役割を果たします。このデータマートはさらなる分析のための重要なリソースとして機能するものであり、サードパーティ アプリケーションによっても使用されます。現在、SCV データの主なコンシューマーは、Adobe Campaign、Adobe Experience Platform、Permutive の 3 つです。
Adobe Campaign は SCV データを使用して、関連性の高いキャンペーンや一人ひとりに合わせたオファーを送信することにより、顧客のターゲティングを効果的に実施します。Adobe Campaign は、このデータをもとに生成された包括的な顧客の分析情報を活用して、顧客エンゲージメントを最適化し、ターゲット マーケティングの取り組みを促進します。
Adobe Experience Platform は SCV データを活用して、ウェブサイトを訪問する顧客に応じたエクスペリエンスを創出します。Adobe Experience Platform は利用できる豊富な顧客情報を活用して、顧客それぞれの好みに合わせてウェブサイト エクスペリエンスをカスタマイズして、顧客満足度とエンゲージメントの向上につなげます。
Permutive は、SCV のユーザー属性データを主に使用して顧客のターゲティングを行い、Telegraph のウェブサイトやアプリを利用するユーザーに応じた広告を表示します。Permutive では顧客セグメントを作成することが可能であり、Google アド マネージャーと統合してパーソナライズド広告を提供できます。
SCV の導入前は、これらのコンシューマーが複数のデータソースに依存する状態であり、数日前の古いデータが使用されるということがしばしば発生していました。このような遅延が発生していたために、1 日で複数回の顧客ターゲティングを行う能力が制限されていました。しかし、SCV の統合のおかげで、準リアルタイムのデータに直接アクセスできるようになり、30 分ごとの頻度でデータを活用できます。このようにデータの更新速度が大幅に改善されたため、TMG はタイムリーで関連性の高いエクスペリエンスをターゲット オーディエンスに届けられるようになりました。
SCV の構築における課題
Single Customer View の構築にはさまざまな課題がつきものであり、特に、現時点での要件を満たすと同時に、将来のニーズにも引き続き対応できるデータモデルを構築する場合はなおさらです。これに対処するために私たちは、データモデルを慎重に拡張することに優先的に取り組み、既存のフレームワーク内に新しい要件が可能な限り組み込まれるようにしました。また、SCV に含める適切なデータを決定することもきわめて重要になります。顧客データのすべてを含めたいと考える会社もあるでしょうが、私たちは、ノイズを回避して関連性のある価値の高いデータのみを含めるようにして、煩わしさのない SCV を維持することが重要であると考えています。
顧客が好むコミュニケーションの手段を管理することも、解決すべき大きな課題です。たとえば、SCV 内では、TMG が顧客と接触するための手段は、顧客の好みに応じて決定されます。ただ、その好みがチャネルごとに、たとえばサードパーティ プラットフォームとの間で異なり、ファーストパーティ データに保存されている好みと相反するものになっている場合があります。これを軽減するために、各コミュニケーション チャネルの権限を慎重に定義する階層ルールを設けてこれを実装することで、コンプライアンスを維持して、法的に重大な影響が及ぶことを回避できるようにしました。
サードパーティ データから来る顧客データを TMG のファーストパーティ データと効率的に照合させることも、複数のソースから来る顧客データを一元化するうえで重要になります。私たちは、完全一致とファジー一致の手法を組み合わせて使用することで、この課題に対処しました。BigQuery のユーザー定義関数(UDF)を使用してファジー一致の手法を導入し、さまざまなアルゴリズムを適用できるようにしました。ただ、大規模なデータ ボリュームに対してファジー一致を処理すると、多大な時間を要することになる場合があります。私たちはさまざまな手法を試し、精度と処理時間をうまく両立できるように積極的に取り組んでおり、照合のプロセスを最適化してさらに効率的な顧客データの統合を実現しようとしています。
最後に、TMG は Google Cloud に SCV を導入することで顧客データの効果的な活用を達成し、成長の促進、顧客満足度の向上、競争力の維持につなげることができました。SCV によりもたらされる豊富な分析情報を活用することで、データに基づいた意思決定を行い、顧客の共感を得られる、一人ひとりに合わせたエクスペリエンスを創出できるようになります。SCV 構築に固有の課題を克服することで、データの可能性を最大限に引き出し、目に見える成果を達成できるようになります。
ー Telegraph Media Group、プリンシパル データ エンジニア Amir Zareian 氏
