BigQuery に新しい ML モデルのモニタリング機能を導入
Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
本番環境での ML モデルのモニタリングは、BigQuery 関数の使用と同じくらい簡単になりました。本日は、BigQuery 内でモデルを直接モニタリングできる新たな一連の関数を紹介します。BigQuery ML モデルは、トレーニング データや推論データをプロファイルすることでモデル ワークフロー全体のデータを記述します。また、トレーニング データとサービング データ間のスキューをモニタリングするほか、SQL を使用して経時的な変化に伴うサービング データのドリフトをモニタリングすることも可能になりました。BigQuery を通じて機能のトレーニング データとサービング データを利用できるすべてのモデルも、同じことが行えるようになっています。これらの新機能を使用すると、本番環境モデルのモニタリングを簡素化しながら、確実に価値を提供し続けることができます。
このブログでは、これらの機能を実際に利用するために、関連する 2 つのノートブックを紹介します。
-
関連機能の概要 - すべての新機能を簡単に紹介します
-
関連するチュートリアル - Vertex AI エンドポイントの使用、モニタリング機能の属性、モニタリング指標の計算方法の概要など、新機能の多くの使用パターンについて説明した詳細なチュートリアルです
モデルの基盤: データ
モデルの性能は、学習するデータの質によって決まります。データを深く理解することは、効果的な特徴量エンジニアリング、モデルの選択、MLOps による品質の確保に不可欠です。BigQuery のテーブル値関数 ML.DESCRIBE_DATA は、このための強力なツールを提供し、単一のクエリでテーブル全体を要約して記述できるようにします。
例: データの問題を特定する
付属の入門ノートブックでは、ML.DESCRIBE DATA 関数を使用してトレーニング データ(ペンギンを分類するデータセット)をプロファイルし、データの問題を迅速に特定します。
以下が、生成された出力テーブルです。
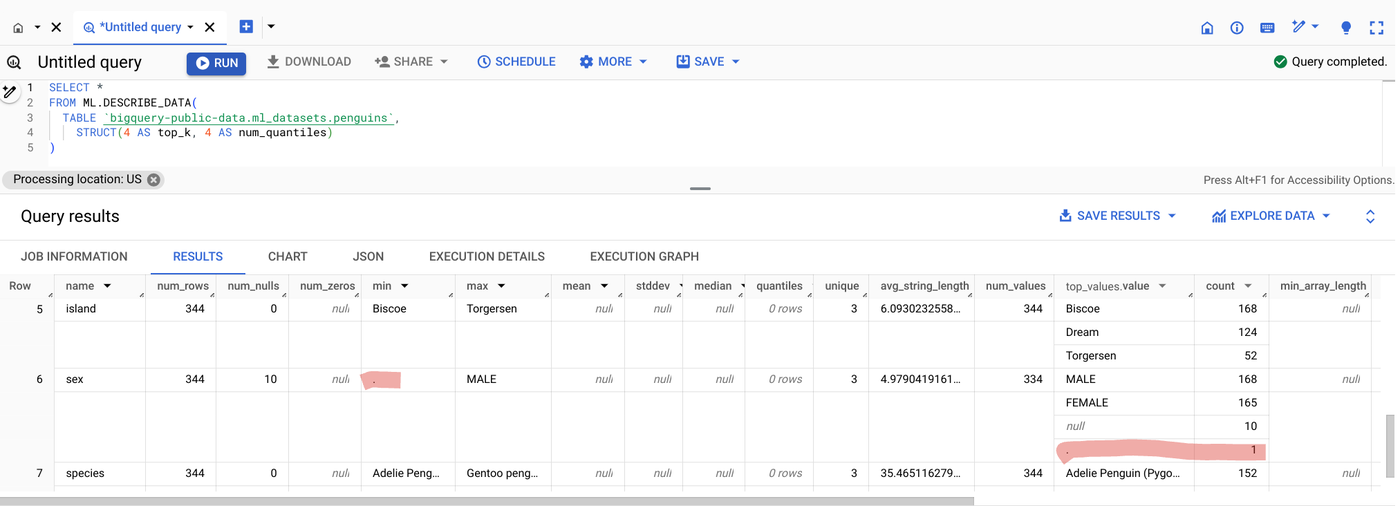
sex 列の min 値が「.」であることに注目してください。top_values.values 列に示されているように MALE、FEMALE、または null が表示されるのが理想的です。これは、10 の null 値(num_null 列で示される)に加えて、「.」値の文字列で示される null 値もいくつか存在することを意味しています。これは、トレーニング データとして使用する前に修正する必要があります。
この ML.DESCRIBE_DATA 関数は、各データ型を 1 つのテーブルにまとめているため、非常に便利です。また、オプション パラメータを指定して、さまざまな数値列タイプの変位値とカテゴリ列に返される上位値の数を制御することもできます。入力データは、テーブル ステートメントやクエリ ステートメントとして指定し、特定のデータ サブセット(トレーニング データ内のサービング時間やグループなど)を記述できます。この関数の柔軟性は ML タスクを超えて拡張されています。BigQuery 以外に保存されているデータを記述することもできるため、モデルの構築とより広範なデータ探索を目的とした分析を迅速に行いやすくなります。
スキューを一目で検出
トレーニングされたモデルは、サービング データの分布がトレーニング データと類似している場合にのみ機能します。モデルのモニタリングで、トレーニング データとサービング データのシフト(スキュー)を比較することで、これを確実なものにします。BigQuery の ML.VALIDATE_DATA_SKEW テーブル値関数は、このプロセスを効率化し、サービング データを BigQuery ML モデルのトレーニング データと直接比較できるようにします。
実際に動作を見ていきましょう。
このクエリは、サービング テーブルのデータを BigQuery ML モデル classify_species_logistic と直接比較します。付属の入門ノートブックでは、インタラクティブな例を挙げて完全なコードを記載しています。このノートブックでは、サービング データがシミュレートされ、body_mass_g と flipper_length_mm の 2 つの機能に変更が加えられます。ML.VALIDATE_SKEW 関数の結果には、次のそれぞれについて検出された異常が表示されます。
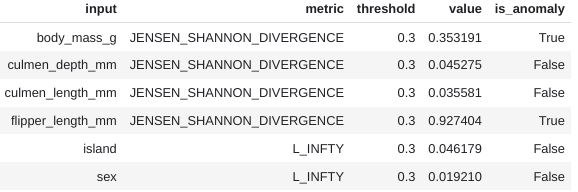
スキューの検出は、BigQuery のモデルとサービング データのテーブルを比較するのと同じように簡単です。トレーニング中、BigQuery ML モデルは関連する統計を自動的に計算して保存します。これにより、トレーニング データセット全体を再利用する必要がなくなるため、スキューのモニタリングが簡単になり、コスト効率も高くなります。重要なのは、この関数はモデルに存在する機能にインテリジェントに焦点を当て、効率とワークフローをさらに強化することです。オプション パラメータを使用すると、異常検出しきい値やカテゴリ特徴の指標タイプをカスタマイズしたり、特定の機能に異なるしきい値を設定したりすることもできます。後ほど、どのモデルに対するスキューも簡単にモニタリングできる方法を示します。
ドリフトの予防的モニタリング
サービング データとトレーニング データを比較するだけでなく、サービング データ内の経時的な変化に注目することも重要です。最近のサービング データと以前のサービング データを比較することは、ドリフト検出として知られる別タイプのモデル モニタリングです。これは、ベースライン データセットと比較データセット間の分布を比較し、設定されたしきい値を超える異常にフラグを立てる指標と同じ検出手法を使用しています。ML.VALIDATE_DATA_DRIFT テーブル値関数を使用すると、任意の 2 つのテーブルまたはクエリ ステートメントの結果を直接比較して検出できます。
ドリフト検出の動作:
ここでは、同じサービング テーブルがベースライン テーブルおよび比較テーブルとして使用されていますが、異なる WHERE ステートメントを使用して行をフィルタし、一例として今日と昨日とを比較しています。以下の結果は、検出値はしきい値を超えていないものの、変化をシミュレートした特徴量については、連続する 2 日間でしきい値に近づいていることがわかります。
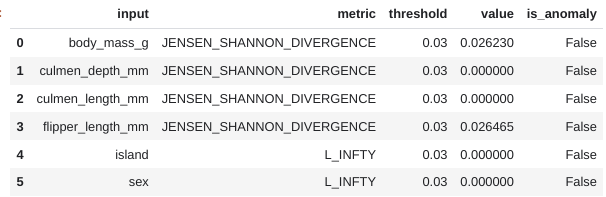
スキュー検出と同様に、異常検出に対するデフォルトの検出しきい値やカテゴリ特徴量に使用される指標タイプを調整したり、列や特徴タイプごとに異なるしきい値を指定したりすることもできます。数値特徴のビニングを制御する追加のパラメータがあり、これは指標計算に使用されます。
TFDV モニタリングを次のレベルに引き上げる
すでに TensorFlow データ検証(TFDV)ライブラリをご存じであれば、これらの新しい BigQuery 関数がモデル モニタリングのツールキットをどのように強化するかおわかりでしょう。TFDV の機能を BigQuery ワークフローに直接導入することで、豊富な統計情報の生成、異常の検出、TFDV の強力な可視化ツールの活用をすべて SQL で行うことができます。そして最も優れているのは、BigQuery のスケーラブルなサーバーレス コンピューティングを使用している点です。BigQuery のスケーラブルなサーバーレス コンピューティングを活用して、ほぼ瞬時に分析を行うことで、モデル モニタリングの分析情報に基づいて迅速に対応できるようになります。
この仕組みを詳しく見ていきましょう。
ML.TFDV_DESCRIBE を使用して統計情報を生成する
テーブル値関数 ML.TFDV_DESCRIBE を使用して、どのテーブルやクエリに対しても、TensorFlow tfdv.generate_statistics_from_csv() API と同じ形式で詳細な統計情報の概要を生成できます。
この ML.TFDV_DESCRIBE 関数は、TFDV: tfmd.proto.statistics_pb2.DatasetFeatureStatisticsList と直接的な互換性のある構造化データ形式(「proto」)で統計情報を出力します。
BigQuery ノートブックで短い Python コードを使用すると、TFDV パッケージと TensorFlow メタデータ パッケージをインポートし、データを適切な形式に変換しながら tfdv.visualize_statistics メソッドを呼び出すことができます。ML.TFDV_DESCRIBE の結果は、トレーニング データ用の train_describe と、当日のサービング データ用の today_describe として、Python に読み込まれました。詳細については、付属のチュートリアルをご覧ください。
これにより、以下に示す見事な可視化が生成され、この例のためにサービング データで意図的にシフトさせた 2 つのパラメータ body_mass_g および flipper_length_mm のシフトが直接的にハイライト表示されます。
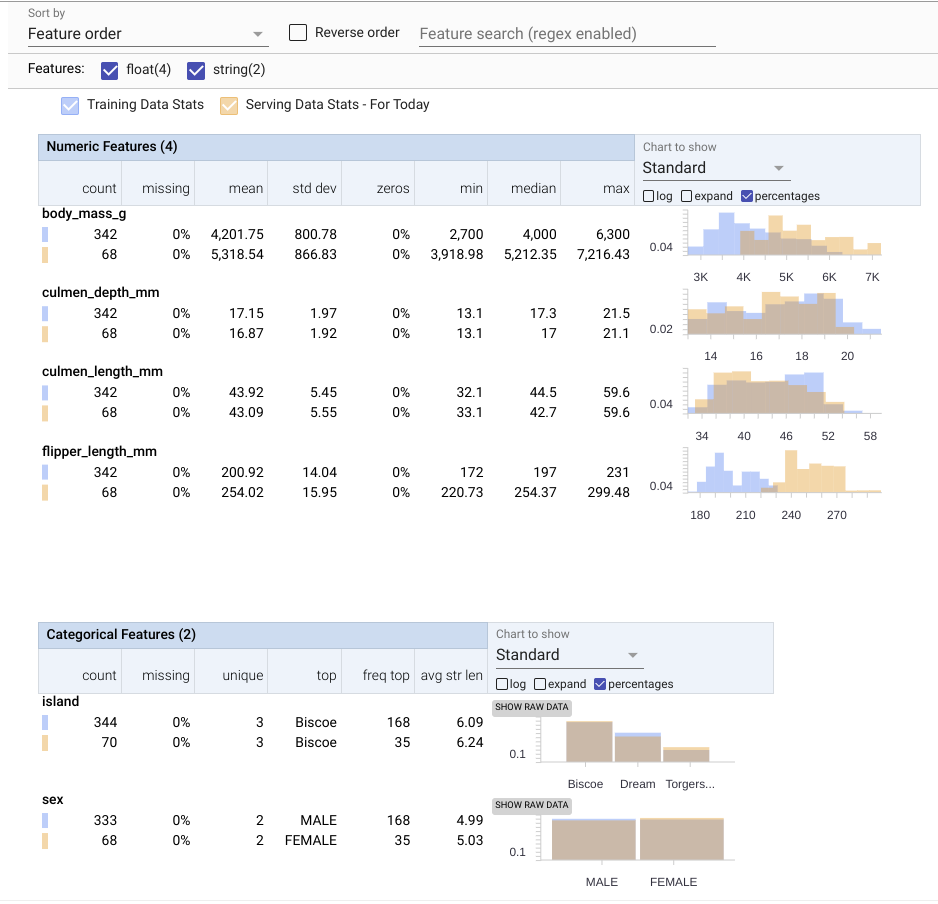
この効率的なワークフローにより、TensorFlow データ検証の能力と精度が BigQuery に直接導入され、データセットの違いを迅速に可視化できるようになります。これにより、モデルの健全性モニタリングに対するより深い分析情報が得られ、モデル トレーニングを反復して進める方法がわかります。
ML.TFDV_VALIDATE を使用して異常を検出する
スカラー関数 ML.TFDV_VALIDATE を使用して、スキューやドリフトの異常を正確に検出することもできます。この関数はテーブルやクエリを比較して、モデルを破壊する可能性のあるシフトを特定します。
例:
これらの結果は、TFDV の表示ツール tfmd.proto.anomalies_pbs2.Anomalies と特に互換性のある構造化データ形式(「proto」)でフォーマットされます。これを Python メソッド tfdv.display_anomalies の入力として渡すと、コード スニペットの後に示されているように、異常検出結果の読みやすいテーブルが表示されます。
数値データおよびカテゴリデータのデフォルトの検出方法としきい値は、上に示した他の関数の場合と同じです。精度の高いモニタリングのニーズに合わせて、関数内のパラメータを使用して検出をカスタマイズできます。詳細は、付属のチュートリアルのセクションをご覧ください。これらの指標を手動で計算する方法と、検証として手動計算結果と比較するためにこの関数を使用する方法を説明しています。
オンライン サービングとバッチ サービング: 統合モデルのモニタリング アプローチ
BigQuery のモデル モニタリング機能は、Vertex AI Prediction エンドポイントにデプロイされたモデルを操作している場合でも、BigQuery 内に保存されたバッチ サービング データを使用している場合でも、効率的なソリューションを提供します(上記参照)。手順は次のとおりです。
-
バッチ サービング: すでに保存されているか、BigQuery によるアクセスが可能なバッチ予測データに関しては、このブログで以前に示したように、モニタリング機能に簡単にアクセスできます。
-
オンライン サービング: Vertex AI Prediction エンドポイントにデプロイされたモデルを直接モニタリングします。BigQuery へのロギング リクエストとレスポンスを構成することで、BigQuery ML モデルのモニタリング機能を簡単に適用してスキューとドリフトを検出できます。
付属のチュートリアルでは、エンドポイントの作成、モデルのデプロイ、ロギングのセットアップ(Vertex AI から BigQuery へ)、BigQuery 内のオンライン データとバッチ サービング データの両方をモニタリングする方法を段階的に説明します。
スケーリングを自動化する
シフトとドリフトのスケーラブルなモニタリングを確実に実現するには、自動化が必須です。BigQuery の手続き型言語は、入門ノートブックの SQL クエリで示されているように、このプロセスを効率化する強力な方法を提供します。この自動化はモニタリングに限らず、継続的なモデルの再トレーニングへと拡張できます。本番環境では、継続的なトレーニングに加え、データ品質の問題を積極的に特定し、現実世界の変化に適応し、組織のニーズに合わせた厳密なデプロイ戦略を維持する必要があります。
どのような結果になるか見てみましょう。
スキューの異常が検出され、モデルの再トレーニングが正常にトリガーされ、データ変更後に精度が回復しました。これは、動的な本番環境でモデルのパフォーマンスを維持するための自動モニタリングと再トレーニングの値を示しています。
このプロセスを効率化するために、Google Cloud はいくつかの強力な自動化オプションを提供しています。
実践的なデモをご希望の場合は、付属のチュートリアルで、履歴のバックフィル、毎日のモニタリング、検出されたシフトとドリフトに対するメール通知アラートの設定など、BigQuery のスケジュールされたクエリについて詳しく説明しています。今後、他の自動化ツールについてのチュートリアルもリリースする予定です。
BigQuery による簡単で強力なモデル モニタリング
信頼できる ML システムを構築するには、継続的なモニタリングが必要です。BigQuery の新しいモデル モニタリング機能は、これをわずかな SQL 関数で行えるよう効率化しています。
-
データを深く理解する: ML.DESCRIBE_DATA はデータセットの包括的なビューを提供するほか、特徴量エンジニアリングと品質チェックに役立ちます。
-
トレーニング データとサービング データ間のスキューを検出する: ML.VALIDATE_DATA_SKEW は、BigQuery ML モデルをそのサービング データと直接比較します。
-
経時的なデータのドリフトをモニタリングする: ML.VALIDATE_DATA_DRIFT は、サービング データの変更を追跡し、モデルのパフォーマンスに一貫性を持たせます。
-
TFDV ワークフローの強化: ML.TFDV_DESCRIBE および ML.TFDV_VALIDATE は、TensorFlow データ検証の精度を BigQuery に直接導入し、BigQuery のスケーラブルで効率的なコンピューティングを活用しながら、より詳細な可視化と異常検出を実現します。
スタートガイド
BigQuery ML モデルから Vertex AI モデルに拡張し、BigQuery のスケジュールされたクエリ、Dataform、Workflows、Cloud Composer、Vertex AI Pipelines などの Google Cloud サービスを使用して、これらの新しい機能を自動化します。実践的なノートブックを使用して、今日から始めましょう。
-
関連機能の概要 - すべての新機能を簡単に紹介します
- 関連するチュートリアル - Vertex AI エンドポイントの使用、モニタリング機能の属性、モニタリング指標の計算方法の概要など、新機能の多くの使用パターンについて説明した詳細なチュートリアルです。
ー カスタマー エンジニア Mike Henderson
ー ソフトウェア エンジニア Ian Zhao


