BigQuery RAG による LLM 機能の強化
Luis Velasco
Data and AI Specialist
Firat Tekiner
Product Management
データ ウェアハウス内からのよりスマートな AI アプリケーション構築が可能に
※この投稿は米国時間 2024 年 5 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI の台頭により、興味深い未来の AI 活用法が多く語られていますが、一方で限界もあります。生成 AI の主力である大規模言語モデル(LLM)は、特定のデータやリアルタイムの情報を活用できないことが多いため、特定のシナリオで効果を十分発揮できないことがあります。検索拡張生成(RAG)は、自然言語処理における手法で、2 段階のプロセスによって、より有益で正確なレスポンスを提示します。まず、提示された質問との類似性に基づき、より大規模なデータセットから関連するドキュメントまたはデータポイントを検索します。次に、生成言語モデルがこの検索された情報を使用してレスポンスを作成します。このように、RAG はデータ分析において非常に便利であり、BigQuery のようなデータストアのベクトル検索を活用して LLM の機能を強化します。それに加えて、BigQuery ML にある機能を使用することで、データを移動することなく、1 つのプラットフォームからこのすべてを行えます。
このブログ記事では、LLM と RAG がどのようにその結果を改善できるのか、RAG が基本的にどのように機能するのかについて詳しく説明します。その後、BigQuery 内で RAG とベクトル検索を使用する例を挙げ、これらのテクノロジーが連携して力を発揮することをお見せします。
LLM の問題点
LLM は多くの一般的知識を持っており、通常は一般公開データの膨大なコーパスを使用してトレーニングされているため、一般的な質問に答えることができます。しかし、LLM は、特定の分野や領域についてトレーニングされていない限り、限られた専門知識しか持ちません。このため、専門的な文脈で適切かつ正確なレスポンスを生成する能力が限定されます。さらに、LLM は静的データセットでトレーニングされるため、リアルタイムの情報が不足しており、最近の出来事や更新情報を認識できません。そのため、情報の古い、不正確なレスポンスを出すことがあります。さらに、
多くの企業ユースケースでは、LLM がレスポンスを生成するために使用する情報源を把握することが非常に重要です。LLM は、自身の出力に関する引用情報を提供しづらいことが多く、その精度と信頼性を検証するのが困難です。
RAG の仕組み
簡単に言うと、RAG は大規模言語モデル(LLM)に外部の情報源を実装します。LLM は、トレーニング データのみに依存するのではなく、データベースやナレッジグラフのような外部ソースから関連情報にアクセスし、これを参照できます。これにより、より正確で信頼性が高く、文脈に即したレスポンスが可能になります。
RAG は、膨大なデータセットを扱う場合、特に長さの制限により標準的な言語モデルのコンテキスト ウィンドウにコーパス全体を収めることができない場合に威力を発揮します。RAG は、複数種類のソースからのデータを活用し、プロンプトに補足情報を取り込んで、情報検索システムを使用して LLM を効果的に補強します。RAG の鍵は検索クエリにあります。このクエリにより、LLM が外部情報源からどのように関連情報を取得するかが決まります。
ベクトル検索は、キーワードの完全一致ではなく、その意味論的意味に基づいて大規模なデータセット内の類似項目を見つけるための便利な手法です。ベクトル検索は、ML モデルを活用して、データ(テキスト、画像、音声など)をエンベディングと呼ばれる高次元の数値ベクトルに変換します。これらのエンベディングは、データの意味的本質を捉え、それにより BigQuery がベクトル間の距離を測定して、類似項目を効率的に検索できるようになります。結果として、ベクトル検索は、関連情報を効率的に検索するうえで重要な役割を果たします。テキストやデータをベクトルに変換することで、ベクトル空間(テキスト、画像、音声といった各データポイントが数値ベクトルとしてエンコードされた高次元数学表現で、エンベディングとも呼ばれます)における近接性に基づいて、類似した情報を見つけることができます。これらのベクトルにはデータポイント間の意味論的意味と関係が含まれているため、BigQuery は、この空間内のベクトルの近接性に基づいて類似検索を実行できます。これにより、LLM がユーザーのクエリに関連する最も適切なドキュメントまたはナレッジグラフ ノードを迅速に特定し、より正確で信頼性が高く、文脈に合ったレスポンスを導き出します。
RAG の基礎
前述のとおり、RAG は自然言語処理における手法であり、2 段階プロセスによってナレッジベースから関連情報を検索してから、この情報に基づいてレスポンスを合成する生成モデルによって、より有益で正確なレスポンスを提示します。RAG システムは通常、2 つの主要部に分けられ、各主要部は以下の 2 つの要素で構成されます。
検索と選択: セマンティック検索を採用して、クエリに基づいて大規模なデータセットから最も関連性の高い部分を正確に特定します。これは、以下によって行うことができます。
1. ベクトル検索:
-
- ユーザーのデータ(文書、記事など)が、その意味論的意味を捉えた数学的表現であるベクトルに変換されます。
- このベクトルが、ベクトル類似性検索に合わせて最適化された BigQuery のような専用データベースに保存されます。
2. クエリ:
-
- ユーザーがクエリを送信すると、そのクエリもベクトルに変換されます。
- 次に、ベクトル検索エンジンが、このクエリベクトルと保存されているドキュメント ベクトルを比較し、意味的な近さに基づいて最も類似したドキュメントを特定します。
拡張とレスポンス: 抽出された関連部分を言語モデルに送り込み、言語モデルのレスポンス生成プロセスを強化します。
3. プロンプトの拡張:
-
- ベクトル検索によって検索された最も関連性の高いドキュメントが元のユーザークエリに追加され、拡張プロンプトが作成されます。
- ユーザークエリと関連するコンテキスト情報の両方を含むこの拡張プロンプトが LLM に送り込まれます。
4. レスポンス生成の強化:
-
-
追加のコンテキストにアクセスできるようになったことで、LLM がより正確で、適切で、十分な情報に基づいたレスポンスを生成できるようになりました。
-
さらに、検索されたドキュメントは、生成されたアウトプットの引用元を示し、ソースの透明性を保証するために使用できます。
-
RAG の課題
流動的要素の多さを考えると、RAG システムは、従来から多くのフレームワークやアプリケーションを併用する必要があります。多くの RAG 実装がありますが、上述のすべての課題に対応することがかなり困難なことから、これら RAG 実装のほとんどは POC または MVP にとどまっています。多くの場合、ソリューションがあまりに複雑で管理しにくくなるため、組織が企業システム内で安心して本番環境へ移行しづらくなりがちです。あるチーム全体で、それぞれオーナーが異なったりする複数のシステムにまたがって RAG を管理しなければならなくなることもあります。
BigQuery で問題解決
BigQuery は、ベクトル検索の実行、データとベクトルに対するクエリの実行、プロンプトの拡張、レスポンス生成の拡張など、さまざまな処理をすべて同じデータ プラットフォームで行うことで RAG を簡素化します。同じアクセスルールを RAG システム全体に適用することも、異なる部分に適用することも簡単に行えます。BigQuery などの企業向けのコア データ プラットフォームからのデータであろうと、BigQuery と LLM を介したベクトル検索によって得られるデータであろうと、データを結合できます。言い換えると、セキュリティとガバナンスが維持され、アクセス ポリシーが管理できなくなることはありません。さらに、BigQuery ML で補完すれば、50 行未満のコードで本番環境に移行できます。
つまり、RAG を BigQuery ベクトル検索および BigQuery ML で使用すると、以下のようないくつかの利点があります。
-
精度と関連性の向上: RAG は、LLM に関連コンテキストを提供することで、生成されるレスポンスの精度と関連性を大幅に向上させます。ユーザーは、データを操作しているシステムに留めたまま、LLM 内の知識を企業データで拡張できます。
-
リアルタイム情報へのアクセス: ベクトル検索により、LLM がリアルタイム情報にアクセスしてこれを利用し、レスポンスが最新の知識を反映するようになります。
-
ソースの透明性: 検索されたドキュメントを引用元と出典情報の提示に使用でき、LLM の出力の信頼性と検証可能性が高まります。
-
スケーラビリティと効率性: BigQuery は、ベクトル化された大量のデータを保存、検索するためのスケーラブルで効率的なプラットフォームを提供するため、RAG のワークフローのサポートに最適です。
RAG の実例
以前のデモで使用した架空のコーヒー フランチャイズである Data Beans の商品レビューから共通のテーマを抽出するパイプラインと BigQuery 内の RAG およびベクトル検索とのインテグレーションを紹介します。このプロセスには、主に以下の 3 つの段階があります。
-
エンベディングの生成: BigQuery ML のテキスト エンベディング モデルにより、各購入者レビューのベクトル表現が生成されます。
-
ベクトル インデックスの作成: 効率的な検索のために、エンベディング列にベクトル インデックスが作成されます。
-
BigQuery のストアド プロシージャ内のランタイムによる RAG パイプラインの実行
3.1 クエリ エンベディング: 「カプチーノ」のようなユーザーのクエリも、同じエンベディング モデルを使用してベクトル表現に変換されます。
3.2 ベクトル検索: BigQuery のベクトル検索機能により、ベクトル表現に基づき、クエリと最も類似している Top-K のレビューが特定されます。
3.3 Gemini によるテーマ抽出: 検索されたレビューが Gemini に送られ、Gemini が共通のテーマを抽出して、ユーザーに提示します。
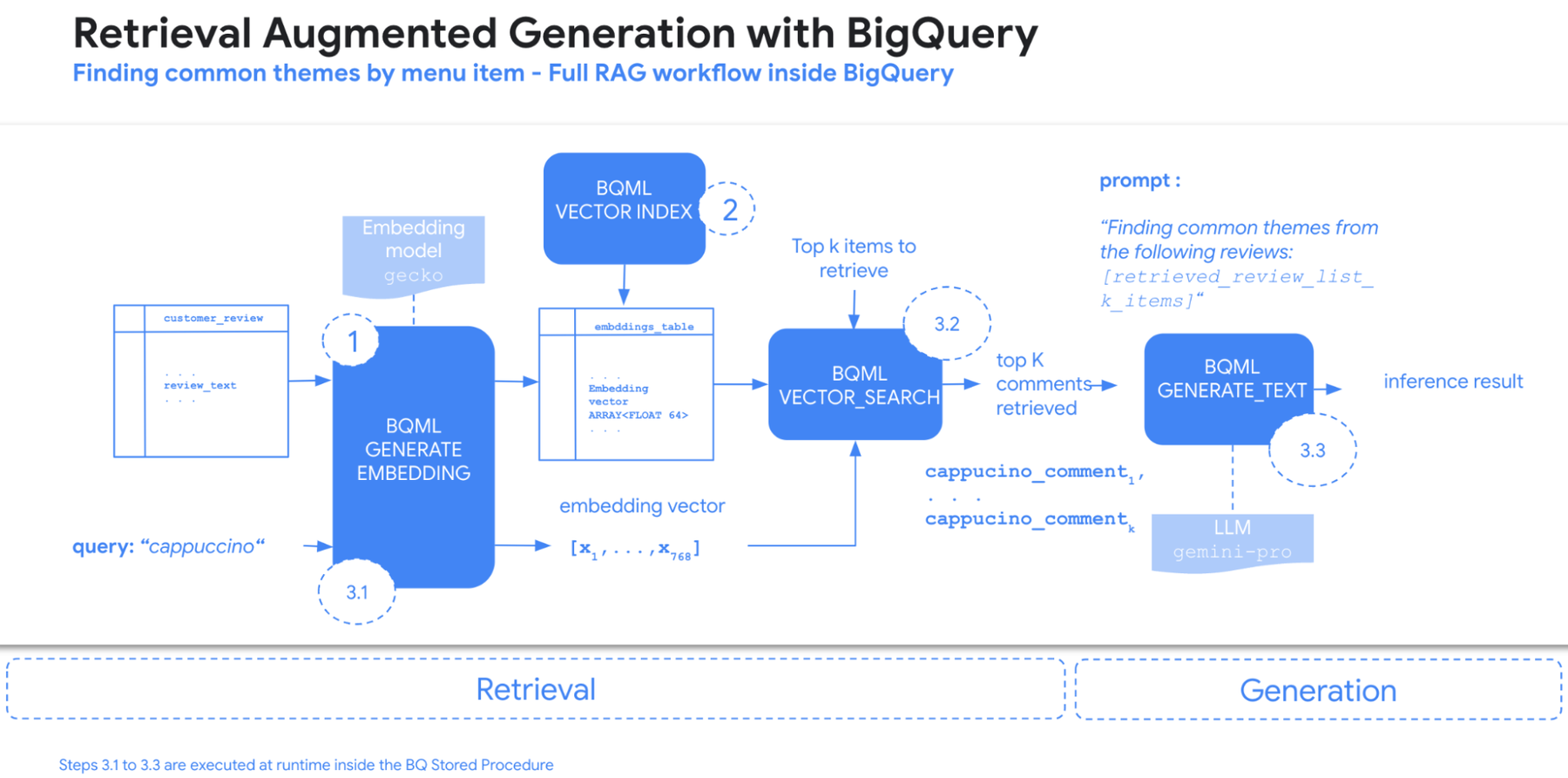
Data Beans のデモの詳細は、こちらでご確認いただけます。
下の例では、購入者レビューが BigQuery テーブル内にテキスト形式で保存されています。購入者レビューは定義上自由テキストですが、たとえば、カプチーノやエスプレッソに関する共通のフィードバックなど、各メニュー項目に共通するテーマを抽出しようとしたらどうなるでしょうか?

この問題に対処するには、企業向けデータ プラットフォーム、プロダクトからのある程度のデータを取得し、それを顧客とのやり取りから直接得られるテキスト情報と組み合わせる必要があります。各メニュー項目は BigQuery テーブルに格納されています。この問題は、BigQuery 内の RAG の候補に適しており、わずか 3 つのステップで解決できます。
ステップ 1 - まずは ML.GENERATE_TEXT_EMBEDDING 関数を使用して、BigQuery 内でエンベディングを直接生成します。これにより、BigQuery テーブルに保存されているテキストを埋め込むことができます。言い換えると、あるひと塊のテキストの密なベクトル表現を作成します。たとえば、2 つのテキストが意味的に類似している場合、それぞれのエンベディングはエンベディング ベクトル空間内で互いに近接しています。
ステップ 2 - エンベディング テーブルを取得したら、BigQuery で CREATE OR REPLACE VECTOR INDEX 文を使用して、ベクトル インデックスを生成できます。
ステップ 3 - 最後に、RAG ロジックを記述して、すべてを BigQuery のストアド プロシージャにラップします。ベクトル検索、クエリ エンベディング、テーマ抽出を 1 つのストアド プロシージャにまとめることで、RAG を 20 行未満の SQL に実装できます。これにより、以下のとおり 1 回の関数呼び出しで、希望の検索条件を BigQuery に渡すことができます。
これで、以下のとおりプロシージャを呼び出して、結果を再取得できます。
この手法では、データが常に単一の環境内にとどまるため、チームは、複数のアプリケーション フレームワークを管理する必要がありません。
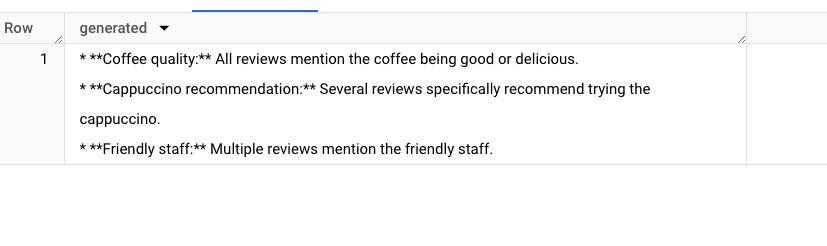
この例では、BigQuery に組み込まれているテキスト エンベディング、ベクトル検索、生成 AI 機能を活用して、RAG 全体を BigQuery 内で実行する方法を示します。このデモの技術的な側面を要約すると、以下のようになります。
-
テキスト エンベディング: BigQuery ML の ML.GENERATE_TEXT_EMBEDDINGS が、購入者レビューのテキスト エンベディング ベクトルの生成に使用されました。
-
ベクトル インデックス: 効率よく類似性検索を行うため、エンベディング列にベクトル インデックスを作成しました。
-
RAG の実装: クエリ エンベディング、ベクトル検索、Gemini を使用した生成などの RAG プロセス全体をカプセル化するため、ストアド プロシージャが使用されました。
要点
-
BigQuery は、RAG を実装するための優れた統合プラットフォームを備えているため、複雑なマルチサービス アーキテクチャが必要なくなります。
-
ベクトル インデックスにより、BigQuery 内での効率的な類似性検索が可能となり、関連情報の効果的な検索が行いやすくなります。
-
ストアド プロシージャを使用すると、BigQuery 内の複雑な AI プロセスを合理化、自動化できます。
まとめとリソース
RAG をベクトル検索および BigQuery と組み合わせることで、LLM の限界を克服するための便利なソリューションを利用できるようになり、分野固有の知識とリアルタイムの情報を使用でき、ソースの透明性が保証され、より正確で、適切で、信頼できる生成 AI アプリケーションを実現できるようになります。企業は、この優れたトリオを活用することで、生成 AI の可能性を最大限に引き出し、さまざまな分野で革新的なソリューションを開発できます。
また、Gemini のような LLM ではコンテキスト ウィンドウがより大きいことで、場合によっては RAG の必要性が薄れることもありますが、RAG は、膨大なまたは特殊なデータセットを扱い、最新の情報を提供するためには今後も必要となります。両方を組み合わせたハイブリッド アプローチにより、ユースケースや費用対効果面の理由によっては、両方の長所を生かせる可能性もあります。
BigQuery の新しい RAG 機能およびベクトル検索機能の詳細については、こちらのドキュメントをご覧ください。こちらのチュートリアルを使用すると、Google の最高水準の AI モデルをデータに適用し、BigQuery からデータを移動することなく、モデルをデプロイし、ML ワークフローを運用化できます。Gemini のような高度なモデルの可能性を引き出しつつ、エンドツーエンドのデータ分析や AI アプリケーションを BigQuery から直接構築する方法について説明したデモもご覧いただけます。
このブログ投稿の執筆には、Google 社員である Adam Paternostro、Navjot Singh、Skander Larbi、Manoj Gunti に協力して頂きました。多くの Google 社員の尽力によって、これらの機能が実現しています。
-データ / AI スペシャリスト Luis Velasco
-Google Cloud、シニア スタッフ プロダクト マネージャー Firat Tekiner
