新しい Dataproc マルチテナント クラスタでデータ サイエンスを加速
Chris Nauroth
Senior Staff Software Engineer, Google Cloud
※この投稿は米国時間 2025 年 9 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
AI/ML の急速な成長に伴い、データ サイエンス チームは、イノベーションを推進するために、その作業に対する需要と重要性の高まりに対応できるよう、より優れたノートブック エクスペリエンスを必要としています。さらに、データ サイエンス ワークロードをスケーリングすると、インフラストラクチャ管理に新たな課題が生じます。ユーザーごとにコンピューティング リソースを割り当てると、強力な分離(ワークロード、プロセス、データを互いに技術的に分離すること)が実現しますが、リソースがサイロ化されるため非効率になる可能性があります。コンピューティング リソースを共有すると、効率化の機会が増えますが、分離が犠牲になります。一方のメリットは他方のデメリットになります。もっと良い方法があるはず…
このたび、新しい Dataproc 機能であるマルチテナント クラスタがリリースされました。この新機能は、同時にノートブック ワークロードを実行する多くのデータ サイエンティストに適した Dataproc クラスタ デプロイモデルを提供します。共有クラスタモデルでは、インフラストラクチャ管理者は、Google Cloud Storage(GCS)バケットなどのデータリソースに対するユーザーごとのきめ細かい認可を損なうことなく、コンピューティング リソースの効率を向上させ、費用を最適化できます。
これはインフラストラクチャの最適化だけでなく、ビジネスの基盤となるイノベーションのサイクル全体を加速させることでもあります。データ サイエンス プラットフォームの摩擦が少ないほど、チームは仮説から分析情報、本番環境への移行をより迅速に行うことができます。これにより、組織はビジネス上の重要な質問に迅速に回答し、ML モデルをより頻繁に反復処理して、最終的にはデータを利用した機能と改善されたエクスペリエンスを競合他社よりも早く顧客に提供できます。これは、データ プラットフォームを、必要なコストセンターから成長のための戦略的エンジンへと進化させるのに役立ちます。
仕組み
この新機能は、Dataproc の以前に確立されたサービス アカウントのマルチテナンシーを基盤としています。この構成のクラスタでは、管理者が宣言した制限付きのユーザーのみがワークロードを送信できます。管理者は、ユーザーからサービス アカウントへのマッピングも宣言します。ユーザーがワークロードを実行すると、Google Cloud リソースへのすべてのアクセスは、マッピングされた特定のサービス アカウントとしてのみ認証されます。管理者は、Identity Access Management(IAM)で認証を制御します。たとえば、1 つのサービス アカウントに一連の Cloud Storage バケットへのアクセス権を付与し、別のサービス アカウントに別のバケットセットへのアクセス権を付与します。
今回のリリースの一環として、サービス アカウントのマルチテナンシーのユーザビリティを向上させるための重要な改善がいくつか行われました。以前は、ユーザーとサービス アカウントのマッピングはクラスタの作成時に確立され、変更できませんでした。実行中のクラスタのマッピングを変更できるようになり、管理者は組織の要件の変化に迅速に対応できるようになりました。また、マッピングを YAML ファイルに外部化する機能も追加し、大規模なユーザーベースをより簡単に管理できるようにしました。
Jupyter ノートブックは、Jupyter Kernel Gateway を介してクラスタに接続します。ゲートウェイは、クラスタのワーカーノードに分散された各ユーザーの Jupyter カーネルを起動します。管理者は、ワーカーノードの数を手動で調整するか、自動スケーリング ポリシーを使用して、エンドユーザーの需要に合わせてワーカーノードを水平方向にスケーリングできます。
ノートブック ユーザーは、Vertex AI Workbench を使用して Google Cloud のフルマネージド環境を利用するか、サードパーティの JupyterLab デプロイを独自に持ち込むことができます。どちらのモデルでも、BigQuery JupyterLab 拡張機能は Dataproc クラスタ リソースと統合されます。Vertex AI Workbench インスタンスは拡張機能を自動的にデプロイできます。また、ユーザーはサードパーティの JupyterLab デプロイで手動でインストールすることもできます。
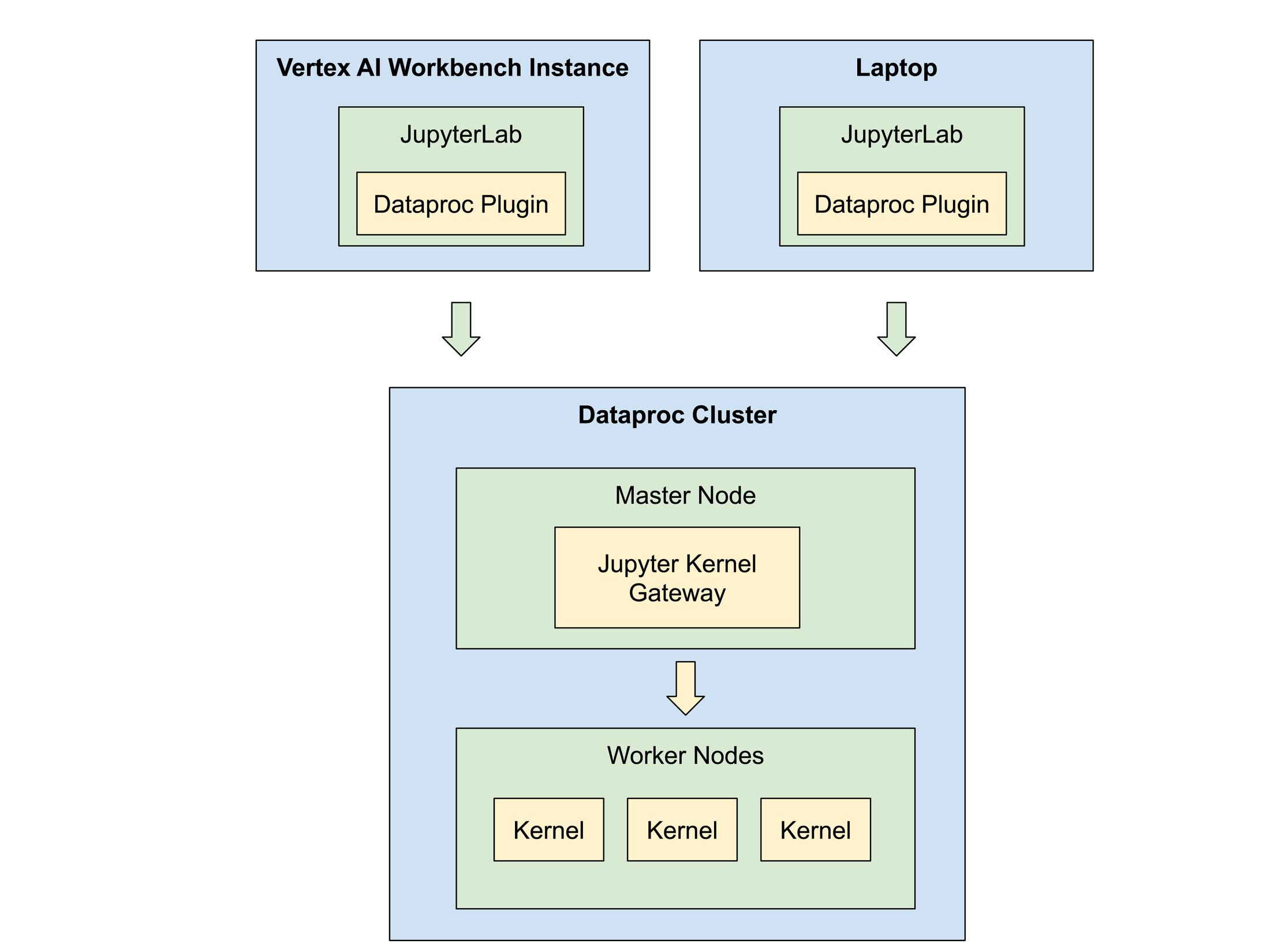
仕組み
Dataproc マルチテナント クラスタは、独立したユーザー ワークロードを分離するために、追加のセキュリティ強化が自動的に構成されます。
-
YARN によって起動されたすべてのコンテナは、認証された Google Cloud ユーザーと一致する専用のオペレーティング システム ユーザーとして実行されます。
-
各 OS ユーザーには、YARN などの Hadoop ベースのリモート プロシージャ コール(RPC)サービスに対する認証用の専用の Kerberos プリンシパルもあります。
-
各 OS ユーザーは、マッピングされたサービス アカウントの Google Cloud 認証情報にのみアクセスできます。クラスタのコンピューティング サービス アカウントの認証情報は、エンドユーザーのノートブック ワークロードからはアクセスできません。
-
管理者は、IAM ポリシーを使用して、マッピングされた各サービス アカウントの最小権限アクセス認証を定義します。
使い方
ステップ 1: サービス アカウントのマルチテナンシー マッピングを作成するユーザー サービス アカウントのマッピングを含む YAML ファイルを準備し、Cloud Storage バケットに保存します。例:
ステップ 2: Dataproc マルチテナント クラスタを作成するユーザー マッピング ファイルと新しい JUPYTER_KERNEL_GATEWAY オプション コンポーネントを使用して、新しいマルチテナント Dataproc クラスタを作成します。
後でユーザー サービス アカウントのマッピングを変更する必要がある場合は、クラスタを更新することで変更できます。
ステップ 3: Dataproc カーネルが有効になっている Vertex AI Workbench インスタンスを作成するVertex AI Workbench のユーザーは、Dataproc カーネルが有効になっているインスタンスを作成します。これにより、BigQuery JupyterLab 拡張機能が自動的にインストールされます。
ステップ 4: サードパーティのデプロイで BigQuery JupyterLab 拡張機能をインストールするローカルのノートパソコンで実行するなど、サードパーティの JupyterLab デプロイを使用している場合は、BigQuery JupyterLab 拡張機能を手動でインストールします。
ステップ 5: Dataproc クラスタでカーネルを起動するVertex AI Workbench インスタンスまたはローカルマシンから JupyterLab アプリケーションを開きます。
ブラウザで JupyterLab の [Launcher] タブが開きます。Jupyter のオプション コンポーネントまたは Jupyter カーネル ゲートウェイ コンポーネントがインストールされた Dataproc クラスタにアクセスできる場合は、[Dataproc クラスタ ノートブック] セクションが表示されます。

リージョンとプロジェクトを変更するには:
-
[Settings] > [Cloud Dataproc Settings] を選択します。
-
[Setup Config] タブの [Project Info] で、[Project ID] と [Region] を変更して、[Save] をクリックします。
-
変更を反映させるために JupyterLab を再起動します。
マルチテナント クラスタに対応するカーネル仕様を選択します。カーネルスペックが選択されると、カーネルが起動し、カーネルが初期化状態からアイドル状態になるまで約 30 ~ 50 秒かかります。カーネルがアイドル状態になったら、実行の準備は完了です。
マルチテナント クラスタを使ってみる
セキュリティと効率性のどちらかを選ぶ必要はもうありません。Dataproc の新しいマルチテナント クラスタを使用すると、データサイエンス チームは高速で共同作業が可能な環境を利用できるようになり、中央制御を維持しながら費用を最適化できます。この新機能は、単なるインフラストラクチャの更新ではなく、イノベーション ライフサイクルを加速させる方法です。
この機能は現在、公開プレビュー版でご利用いただけます。技術ドキュメントを確認して、最初のマルチテナント クラスタを作成し、今すぐ始めましょう。プラットフォームの進化を続けるうえで、皆様からのフィードバックは非常に重要です。ご意見やご感想を dataproc-feedback@google.com までお寄せください。
-Google Cloud、シニア スタッフ ソフトウェア エンジニア Chris Nauroth



