BigQuery の整数検索やタイムスタンプ検索のパフォーマンスを向上させ、クエリ費用を削減する
Jing Mao
Software Engineer
Huong Phan
Engineering Lead, BigQuery Search
※この投稿は米国時間 2024 年 5 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery における最初のバージョンの検索インデックスでは、スタンドアロンの STRING スカラー列の STRING データ要素、または ARRAY、STRUCT、JSON 列の STRING データ要素に対する高速で効率的な検索に重点が置かれていました。以前のブログ投稿では、SEARCH 関数などの関数や演算子を使用することで、桁違いのパフォーマンスの向上が見込めることをご紹介しました。
そしてこのたび、数値検索インデックスの公開プレビュー版がリリースされることになりましたのでお知らせします。数値検索インデックスでは、INT64 データ型と TIMESTAMP データ型の検索が最適化されます。この変更により、これら 2 つのデータ型の EQUAL(=) および IN 演算で検索インデックスを利用できるようになり、バイト スキャンの削減と、パフォーマンスの向上につながります。アカウント ID、トランザクション ID、ログ タイムスタンプの検索もより高速かつより安価なものになるでしょう。
このブログ投稿では、実際のデータから得られるメリットをご紹介します。それにあたっては、Google の社内テスト プロジェクト向けの Google Cloud Logging データを含む log_table という 100 TB のログテーブルにインデックスを作成し、クエリを実行する例を使用します。
ベーステーブルの詳細は次のとおりです。
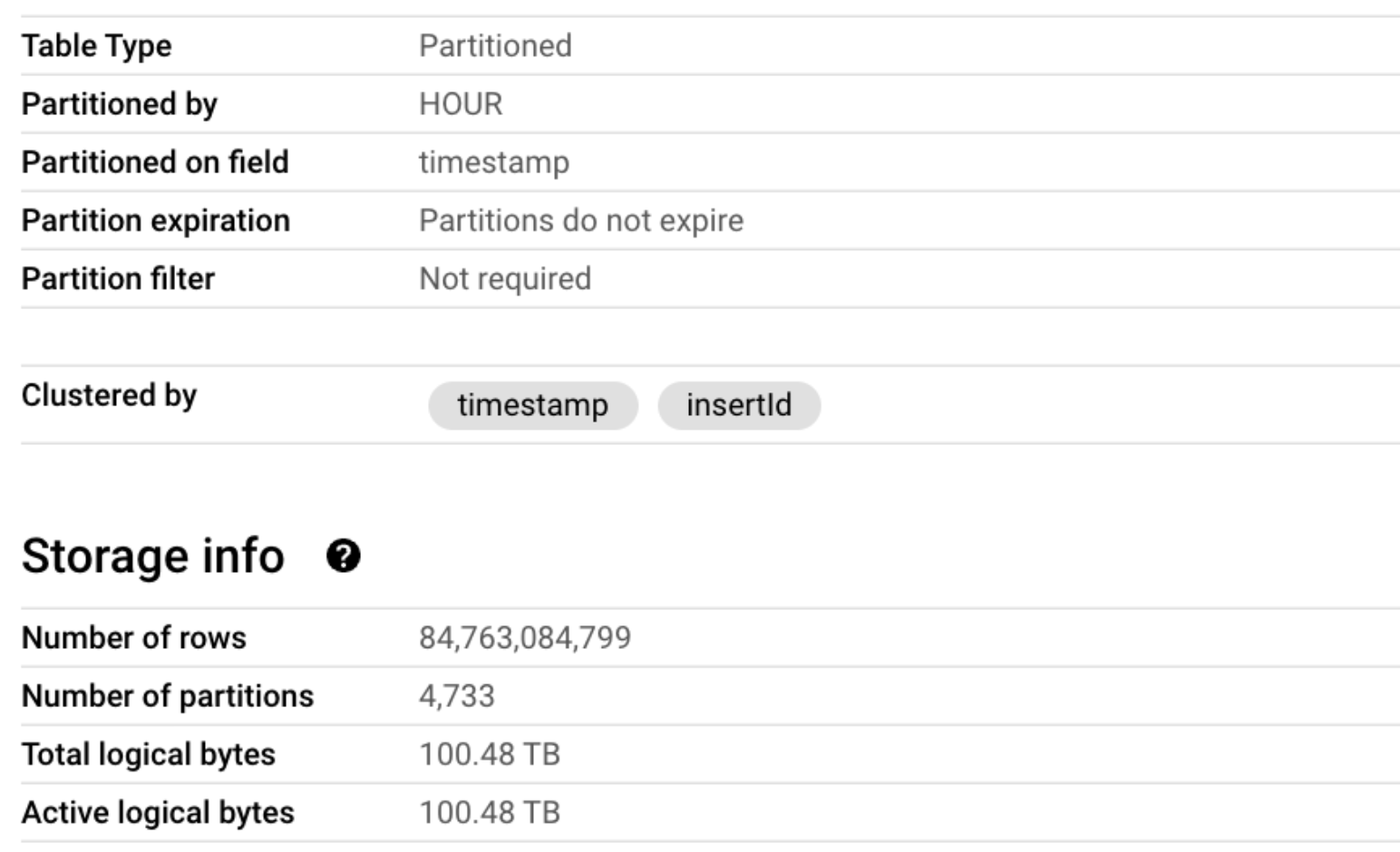
テーブルには関連する次のような列があります。
-
jsonPayload: JSON 型 -
この jsonPayload には、JSON 数値型の
threadIdという名前のリーフ フィールドがあります。 -
sourceLocation: 関連する 2 つのサブフィールドを持つ RECORD(または STRUCT)型: -
file: ログエントリを生成するファイルの名前を含む STRING 型 -
line: ログエントリが生成されたファイル内の行番号を含む INT64 型
検索インデックスを使用する
デフォルトでは、検索インデックスは STRING データに対してのみ作成されます。INT64 または TIMESTAMP をインデックス化する場合は、data_types というインデックス オプションでそれらを指定する必要があります。次の例では、log_table テーブル内の STRING 型と INT64 型のすべてのデータがインデックス化されます。
JSON フィールド検索
この 1 つ目の例では、jsonPayload のスレッド ID が 12104 のログエントリを検索します。
検索インデックスがある場合とない場合を比較します。このスレッド ID のログエントリは非常にまれであるため、結果は 3 つのすべての指標で劇的な改善を示しています。
STRUCT ネスト フィールド検索
2 番目の例では、特定のコード行(ファイル borg/borgletlib/borgletlib.cc の行 813)から生成されるログエントリの数をカウントします。
sourceLocation.file が STRING フィールドである点に注意してください。以下に示すように、STRING データ型のみの検索インデックスでもクエリ パフォーマンスに向上が見られます。ただし、INT64 データ型にもインデックスを施せば、パフォーマンスはさらに向上します。
パーティショニング / クラスタリングを使用する場合のインデックス作成の要否
パーティショニングとクラスタリングはフィルタリングと検索を最適化できますが、一定の制限があります。たとえば、パーティショニングは 1 つの列にしか実行できませんが、クラスタリングは 1 テーブルにつき最大 4 つの列に実行できます。ただし、2 番目の列以降ではプルーニング(枝刈り)の効果が最小限に抑えられることが多いため、クラスタリングは最初のクラスタリング列でフィルタリングする場合に最も効果的です。さらに、パーティショニングとクラスタリングはどちらも最上位の列に制限されてしまいます。
INT64 または TIMESTAMP の検索インデックスは任意の数の列について検索の最適化を可能にするという意味で、上述の BigQuery 機能を補完するものです。さらに、上に示したとおり、STRUCT ネスト フィールド、配列要素、JSON リーフ フィールドもカバーしています。
この機能は現在、プレビュー版です。詳細については、数値述語を使用した最適化を参照してください。
ー ソフトウェア エンジニア Jing Mao
ー エンジニアリング リード Huong Phan



