BigQuery のマネージド障害復旧により複数のリージョン間でビジネスの継続性を維持
Larry Henderson
Product Manager
Brian Welcker
Director, Product Management
※この投稿は米国時間 2024 年 5 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
地理冗長は、復元力に優れたクラウドベースのデータ戦略を構築するうえでの基盤となります。BigQuery は長年にわたり、単一の地理的リージョン内の可用性において、業界をリードする 99.99% の稼働時間のサービスレベル契約(SLA)を提供してきました。単一リージョン内にある 2 つのデータセンター間における完全な冗長性は、作成するすべての BigQuery データセットに含まれ、完全に透過的な方法で管理されます。
複数の広い地理的リージョン全体で冗長性を高めたいお客様に向けて、BigQuery にマネージド障害復旧が導入されることとなりました。この機能は、コンピューティングとストレージの自動フェイルオーバーを可能にし、ビジネス クリティカルなワークロードに合わせた新しいクロス リージョンの SLA を提供するもので、現在プレビュー版をご利用いただけます。この機能を利用すると、リージョン全体でのインフラストラクチャの停止という稀な状況が発生した場合でも、ビジネスの継続性を維持できます。マネージド障害復旧では、容量予約のためのフェイルオーバー構成も提供されているため、クエリとストレージのフェイルオーバー動作を管理できます。この機能は、BigQuery Enterprise Plus エディションでご利用いただけます。
仕組み
BigQuery Enterprise Plus エディションをご利用のお客様は、容量の予約を構成することで、異なる地理的リージョン間の自動フェイルオーバーを有効にできます。フェイルオーバー予約は、BigQuery のクロスリージョン データセット レプリケーションを拡張したもので、データリソースとコンピューティング リソースの両方のロケーションを障害復旧イベント中に確実に連携動作させます。
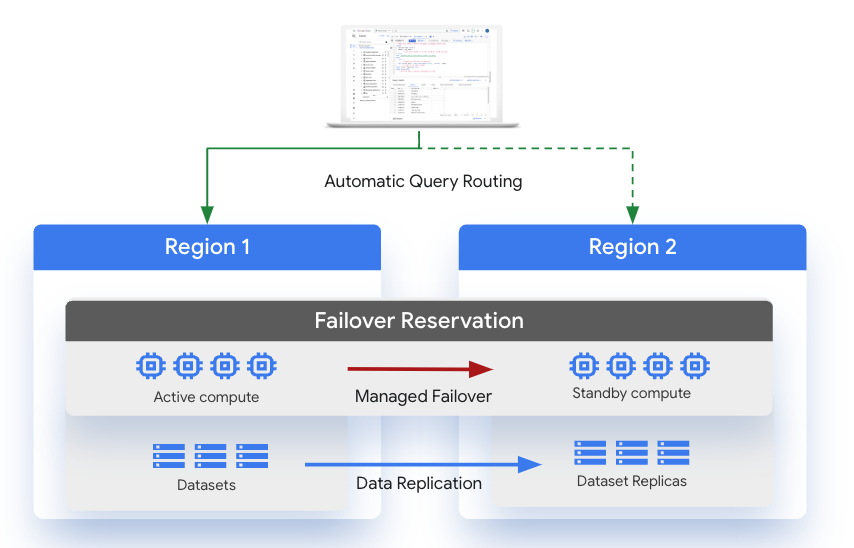
Enterprise Plus エディションの予約のセカンダリ リージョンにおけるスロット容量は、追加料金なしで自動的にプロビジョニングおよび管理されます。競合製品の中には、ユーザーがコンピューティング クラスタをセカンダリ ロケーションに複製しなければならないものもあります。
リージョン全体のサービスが停止した場合、コンピューティングとデータの両方に対して、セカンダリ リージョンをプライマリ ロールに昇格できます。BigQuery のクエリ ルーティング レイヤにより、フェイルオーバーは、エンドユーザーやツールによる操作なしで完全に透過的に行われます。
-
プライマリ リージョン: データセットの現在のプライマリ レプリカを含むリージョンです。これは、データセットのデータを変更(読み込み、DDL、DML など) 可能なリージョンでもあります。
-
セカンダリ リージョン: リージョンが停止した場合にフェイルオーバー予約のスタンバイ容量と複製されたデータセットが利用可能なリージョンです。
-
フェイルオーバー予約: プライマリ / セカンダリ リージョンのペアで構成される Enterprise Plus エディションの予約です。注: データセットはフェイルオーバー予約に関連付けられます。
プライマリ リージョンのデータセット レプリカがプライマリ レプリカ、セカンダリ リージョンのデータセット レプリカがセカンダリ レプリカとなります。これらのロールは、フェイルオーバーのプロセス中に入れ替えられます。
プライマリ レプリカは書き込み可能で、セカンダリ レプリカは読み取り専用です。プライマリ レプリカへの書き込みは、セカンダリ レプリカに非同期で複製されます。各リージョン内では、データが 2 つのゾーンに冗長的に保存されます。ネットワーク トラフィックが Google Cloud ネットワークの外部に出ることはありません。
リージョンペアとは
BigQuery のマネージド障害復旧のリージョンペアは、ターボ レプリケーションとコンピューティングの冗長性によって地理的にサポートされたリージョンのペアです。BigQuery は、定義されたリージョンペア内の 2 つのリージョン間でデータを複製し、セカンダリの利用可能な容量を管理します。このレプリケーションにより、BigQuery のマネージド障害復旧でデータの高い可用性と耐久性が提供されます。お客様は、フェイルオーバー予約で希望するリージョンペア(サポートされているリージョンに基づく)を定義できます。
サポートされているリージョンペア
BigQuery のマネージド障害復旧機能では、特定のリージョンペア間(Cloud Storage と同様に、地理的エリア内の複数のリージョン)でのフェイルオーバー予約がサポートされます。ペアのどちらのリージョンも、初期のプライマリ リージョンまたはセカンダリ リージョンとして指定できます。
セカンダリ リージョンの容量
BigQuery では、フェイルオーバーの 5 分以内に、プライマリ リージョンの容量がセカンダリ リージョンで利用可能になることが保証されます。この保証は、使用されているかどうかにかかわらず、予約のベースラインに適用されます。また、プライマリで提供されるのと同じレベルの自動スケーリングも提供されます。
料金について
BigQuery のマネージド障害復旧は、Enterprise Plus エディションでご利用いただけます。セカンダリ リージョンのスタンバイ コンピューティング容量は、スロット時間あたりの料金に含まれており、スタンバイ容量を個別に購入する必要はありません。オプションとして、読み取り専用クエリ用に、セカンダリ リージョンに追加の Enterprise Plus 予約をプロビジョニングすることも可能です。
マネージド障害復旧をご利用のお客様への請求は、プライマリ リージョンとセカンダリ リージョンの関連付けられたデータセットの複製されたストレージに対して行われます。一般提供時には、この機能はリージョン間のデータ転送に自動的にターボ レプリケーションを使用します。
* ターボ レプリケーションはプレビュー期間中はご利用いただけませんが、一般提供(GA)時に自動的に有効になります。
目標復旧時間(RTO)
プライマリ リージョンが停止した場合でも、セカンダリの予約と、関連付けられたデータセットの昇格が 5 分以内に行われます。実行中のクエリはすべてキャンセルされ、RTO タイムライン中は拒否されます。
目標復旧時点(RPO)
サポートされているリージョンペア間でフェイルオーバー予約で構成されているセカンダリ データセット レプリカのデータは、ターボ レプリケーションが有効で、初期レプリケーションが完了している場合、最長でも 15 分前のものです(バックフィルとも呼ばれます)。
注: ターボ レプリケーションと SLA での RPO / RPO は、プレビュー期間中は適用されません。
構成の実例
プレビュー期間中は、マネージド障害復旧の構成は BigQuery コンソール(UI)と SQL でサポートされます。次のワークフローは、BigQuery でマネージド障害復旧を設定および管理する方法を示しています。
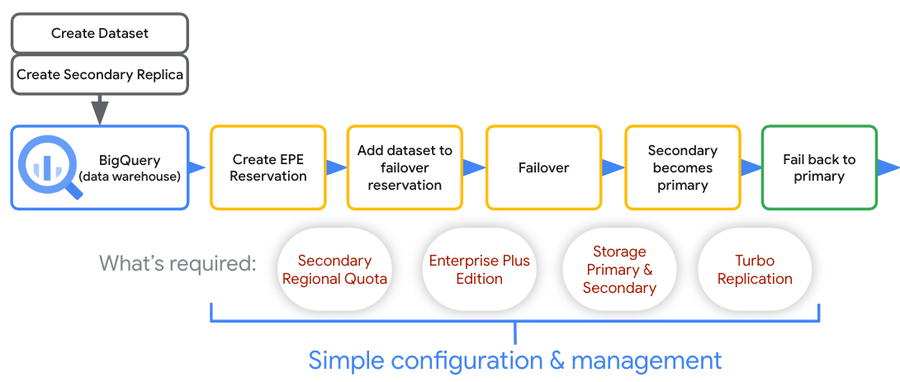
特定のデータセットのレプリカを作成する
データセットを複製するには、ALTER SCHEMA ADD REPLICA DDL ステートメントを使用します。
レプリカを追加した後、最初のコピー オペレーションが完了するまで時間がかかります。データの複製中も、プライマリ レプリカを参照するクエリを実行できます。クエリの処理能力が低下することはありません。
フェイルオーバー予約を構成し、データセットを関連付ける
まず、フェイルオーバー予約を作成し、そのセカンダリ ロケーションを指定します。セカンダリ ロケーションは、既存の Enterprise Plus 予約にも指定できます。
次に、1 つ以上のデータセットをフェイルオーバー予約に関連付けます。データセットは、予約で指定されたプライマリ / セカンダリ リージョンに複製される必要があります。
フェイルオーバー予約とセカンダリのデータセットを昇格させる
予約と、関連付けられたデータセットをフェイルオーバーします。これは、セカンダリ リージョンから実行する必要があります。
元のプライマリにフェイルバックする
予約と、関連付けられたデータセットをフェイルバックします(新しいセカンダリ / 古いプライマリから実行)。
使ってみる
ミッション クリティカルなデータ環境を運用する企業にとって、ビジネスの継続性は最重要事項です。BigQuery のマネージド障害復旧機能のプレビュー版をぜひお試しください。マネージド障害復旧の詳細と BigQuery で使用を開始する方法については、マネージド障害復旧クイックスタートをご覧ください。
-プロダクト マネージャー Larry Henderson
-プロダクト管理担当ディレクター Brian Welcker
