BigQuery のベクター検索と LLM でログ分析を強化
Roy Arsan
Cloud Solutions Architect, Google
Omid Fatemieh
Senior Engineering Manager, Google Cloud
※この投稿は米国時間 2024 年 6 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
Google はこのたび、BigQuery でのセマンティック類似検索を可能にする、BigQuery のベクター検索をリリースしました。このパワフルな機能は、BigQuery テーブルに保存されているログやアセットのメタデータの分析に使用できます。たとえば、疑わしいログエントリがある場合、サイト信頼性エンジニアリング(SRE)チームやインシデント対応(IR)チームは、意味的に類似したログを検索して、それが真の異常かどうかを検証できます。この検索をプロアクティブに行えば、そうした異常を自動的にトリアージして、通常は長くかかる調査時間を節約できます。さらに、こうした関連性の高い検索結果は、より完全なコンテキストを大規模言語モデル(LLM)に提供するため、従来のスキーマベースのクエリだけでは捉えにくい関係性、パターン、ニュアンスを識別することができます。これにより、脅威の検出や調査からネットワーク フォレンジック、ビジネス分析情報、アプリケーションのトラブルシューティングまで、多くのユーザー ワークフローを加速できます。
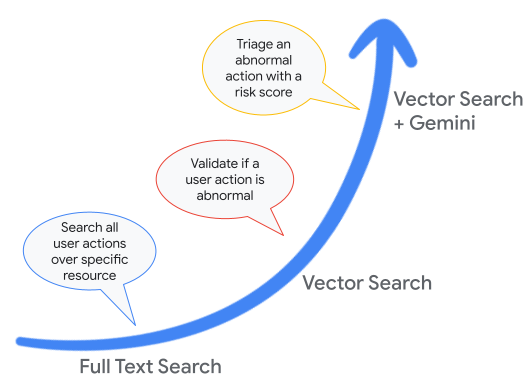
Faster time-to-insights using BigQuery over audit logs
このブロク投稿では、ログやアセットのメタデータに対して BigQuery の新しいベクター検索機能を使用する方法の概要をご紹介します。まず、このソリューションの主要コンポーネントを示します。次に、ログやアセットに対して BigQuery のベクター検索を利用する方法について、実際のお客様のユースケースをいくつか見ていきます。また、これを大規模に、費用対効果に優れた方法でデプロイするためのヒントも説明します。
ベクター検索とテキスト検索
従来のテキスト検索は、単語またはトークンの正確な一致に依存していますが、ベクター検索は、一致度の高いベクター エンベディングを検索することで、意味的に類似したレコードを識別します。ベクター エンベディングは、特定のデータレコード(テキスト、画像、音声、動画ファイル)のセマンティックな意味をカプセル化する高次元の数値ベクターです。ログやアセットの場合、データレコードはログエントリ(監査、ネットワーク、アプリケーションなど)またはリソース メタデータ(アセットまたはポリシー構成の変更など)のいずれかです。
BigQuery ユーザーは、検索インデックスとベクター インデックスを構成、管理して、高速かつ効率的な検索を行うことができます。全文検索インデックスでは決定的な結果(完全な再現率)が生成されますが、ベクター インデックスを使用したベクター検索では近似結果が返されます。これは近似最近傍探索(ANN)という検索手法を使用しているためで、パフォーマンスを向上させて費用を削減できる代わりに再現率は低くなります。
テキスト検索は膨大なデータの中から必要な情報を見つけるタイプの検索に役立ちますが、ベクター検索は類似性や外れ値タイプの検索に役立ちます。これらの検索手法のどちらも、ログ分析では次のような質問に回答するためによく使用されます。
このブログ投稿の残りの部分では、検索拡張生成(RAG)など、ログデータに対してベクター検索を使用する方法について、いくつか具体例を挙げて紹介します。
半構造化データから非構造化データへ
従来のビッグデータの課題(特にデータの 4 つの V、つまり量、多様性、速さ、可変性)に加えて、ログの分析では、その複雑な半構造化形式を理解することも課題の一つです。ログは、多くの場合、深くネストされたフィールドと、JSON のような不均一なペイロードで構成されています。一般的な組織では、数十億のログエントリがあり、ログペイロードの形式は数百から数千種類に上ります。
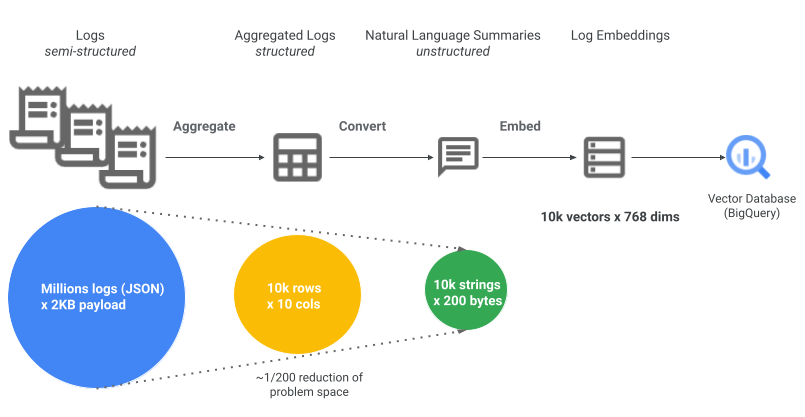
膨大な量のログを処理し、埋め込みやすくするために、このソリューションでは上記のアーキテクチャ図に示される、次の 2 つの重要なステップを採用しています。
-
集計: 複数のログエントリを 1 つにまとめることで、データ量を削減します。つまり、個々のログエントリを分析するのではなく、ユーザー アクションを 1 時間または 1 日ごとに 1 つのエントリにグループ化します。たとえば、ある特定の日に 1 人のユーザーによって特定のアクションが 20 回実行された場合(したがって 20 回ログに記録されます)、このアクションを 1 つのレコードにまとめて、スペースを 20 分の 1 に削減できます。
-
NL 変換: さらに、詳細な半構造化 JSON ログペイロードを単純な自然言語ログサマリーに変換すると、データ量をさらに削減できます。この変換により、テキスト データからエンベディングを生成し、後でベクター検索でクエリを実行するのが容易になります。たとえば、2 KB の監査ログエントリを 200 文字の文章に集約して、この監査ログエントリが意味するものを意味的に説明することで、スペースをさらに 10 分の 1 に削減できます。
例として、Cloud Audit Logs を処理するための SQL のサンプル(Dataform SQLX 形式)を次に示します。
-
これらのログサマリーのエンベディングを生成する SQL クエリ。このクエリは、エンベディング列に対するベクター インデックスも設定します。
自然言語のログサマリーとそのエンべディングにより、その後の LLM アプリケーションは、構造化または半構造化の元データのみを使用して表現するのが難しいニュアンスを、より適切に理解して捉えられるようになります。これについては次のセクションで説明します。未加工のログは、ソース ログバケットまたは BigQuery データセットに保持されており、参照できます。
ここで重要なのは、集計や変換のパラメータそのものは、最終的にはログタイプやユースケースごとに異なることです。たとえば、集計の間隔(10 分、1 時間、1 日など)は、検索のタイムラグの要件と許容される時間精度の損失によって異なります。同様に、変換ステップでは、最も関連性の高いログフィールドを慎重に選択して抽出する必要があります。これは通常、その特定のログタイプに精通している対象分野のエキスパートによって行われます。集計と変換の両方のステップを慎重に計画して構成することで、ログボリュームの削減と、意味のあるパターンと分析情報を識別する機能の維持との間で適切なバランスをとることができます。
実世界のアプリケーション
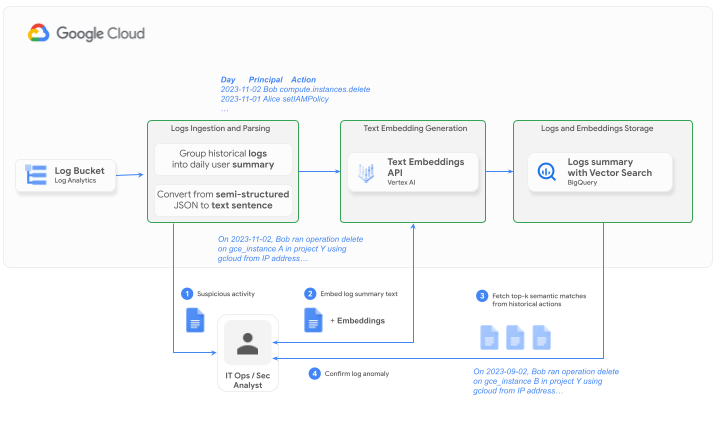
では、SQL クエリで BigQuery の SQL 関数 VECTOR_SEARCH を使用する方法をご紹介しましょう。これはご自身で試すことができます。以下の例では、こちらのサンプル Dataform リポジトリで実装されているように、ログがすでに前処理(集計、変換、埋め込み)されて actions_summary_embeddings と呼ばれる履歴ログのテーブルに入れられていることを前提としています。
-
例 1 では、ベクター検索を使用して、履歴ログに対して潜在的な異常を検証します。テスト データセット(潜在的な異常)は、テーブル
actions_summary_embeddings_suspectedに保存されます。 -
例 2 では、ベクター検索を使用して、履歴ログ全体でルール違反を検索します。ルールが自然言語で表現されて、動的に埋め込まれる点に注目してください。
-
例 3 と 4 は、より複雑なベクター検索の使用法です。例 3 では、後続のロジックを使用して、一致の数や距離などの最近傍結果に基づいて異常をトリアージします。一方、例 4 では、最近傍結果を使用してコンテキストに沿った LLM プロンプト(RAG)を強化し、Gemini などの LLM に推論させて異常をトリアージします。
注: エンべディング、ベクター検索、LLM 推論に基づいて構築されたソリューションは、本質的に確率的かつ近似的です。上位レベルのタスクの目的とリスク許容度に基づいて、ベクター検索やその他の指標の再現率を評価することを検討してください。
1)ベクター検索(外れ値検出)を使用して異常を検証する
結果の例:
2)ベクター検索(類似検索)を使用してポリシー違反を検索する
結果の例:
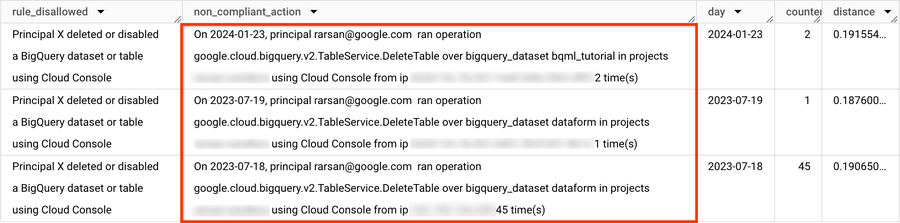
3)ルールベースのロジックによるベクター検索を使用して異常をトリアージする
結果の例:
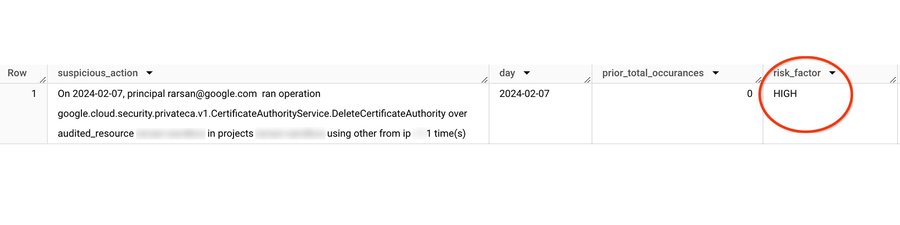
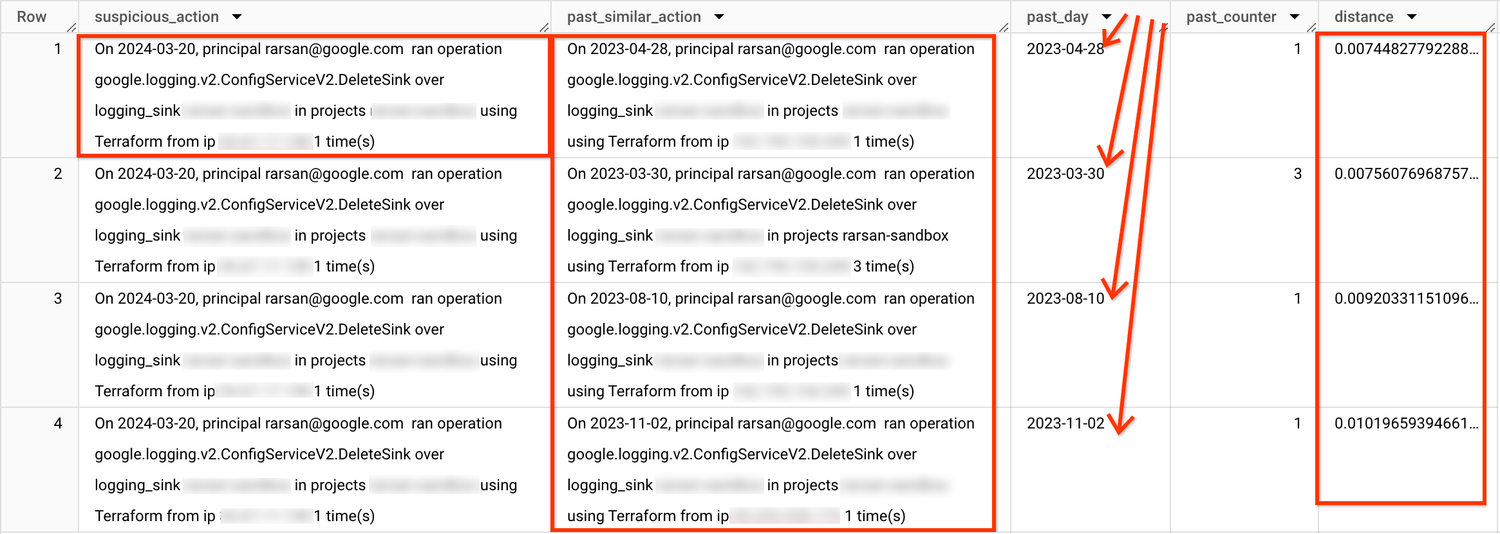
4)LLM 推論(RAG)によるベクター検索を使用して異常をトリアージする
ベクター検索結果を含めたプロンプトと生成された LLM レスポンスを示す出力例(Google スプレッドシートにエクスポート)

見やすいように、生成された LLM レスポンスのコピーを以下に示します。
**Low risk.**
- The principal (rarsan@google.com) has performed the same operation (google.logging.v2.ConfigServiceV2.DeleteSink) on the same logging sink (<redacted>) in the same project (<redacted>) multiple times in the past using Terraform.
- The IP address (<redacted>) used in the suspected administrative action is not significantly different from the IP addresses (<redacted> and <redacted>) used in previous administrative actions.
- The frequency of the suspected administrative action (1 time) is consistent with the frequency of previous administrative actions (1 time, 3 times, 1 time, and 1 time).
規模、費用、パフォーマンスに関する注意事項
ベクター検索では、全文検索と同様に、パフォーマンスを向上させるための特殊なインデックスが使用されます。ベクター インデックスを使用すると、ベクター検索クエリでエンべディングを効率的に検索できるため、レスポンス タイムが短縮され、データスキャンやスロット使用量が削減されます。ただし、この効率性の向上には、返される結果の精度が低下する可能性があるというトレードオフが伴います。
たとえば、過去 12 か月間に 50 GB 分の監査ログが作成されたプロジェクトについて考えてみましょう。監査ログエントリの平均ペイロードが 2 KB と仮定すると、これは約 2,500 万件のログレコードに相当します。前述したログボリュームの削減手法を採用することで、2 桁から 3 桁のボリューム削減を実現できます。
-
2,500 万件のログエントリ(1 件あたり 2 KB)→ 125 万件(集計)のログ(1 件あたり 200 バイト)
-
50 GB の未加工のログ → ~240 MB のログのエンべディング
これは、ベクター インデックスのサイズとほぼ同じです。つまり、12 か月間のルックバックに対して、高速(1~2 秒)で費用対効果の高いセマンティック検索が実現します。
ここで、50 GB のログが毎日取り込まれると仮定します。1 年間の保持期間では、未加工のログデータの合計は 17 TB になりますが、ログのエンべディングでは 81.72 GB のみです。これは、BigQuery に保存してフルマネージドのベクター インデックスを使用して検索するには、かなり少ないデータ量です。
今すぐ BigQuery のベクター検索をお試しください
まとめると、BigQuery は、堅牢なデータ分析だけでなく、全文検索とベクター検索も統合した包括的なプラットフォームに進化しました。これは、異常の検出と調査を含むログ分析のコンテキストで特に有用です。ベクター検索を活用したセマンティック検索により、データに対して可能な質問の種類が広がり、分析情報を得るまでの時間が短縮されます。さらに、RAG アーキテクチャ内で情報検索にベクター検索を活用することで、増加するログの量と潜在的なセキュリティ脅威に対応する、洗練された LLM を活用したアプリケーションを開発できます。
監査ログに対する BigQuery のベクター検索を試すには、こちらの Log Anomaly Detection & Investigation(ログの異常検出と調査)ノートブックをお試しください。ログの準備、クエリ、可視化の方法を詳しく解説しています。このブログ記事で説明したソリューションをデプロイするには、エンドツーエンドのデータ パイプラインを自動化するこちらの BigQuery Dataform リポジトリをご利用ください。ログの集計、変換、エンべディングの生成などのすべての手順は、SQL クエリでコード化され、スケジュールされた Dataform ワークフローを使用して定期的に実行されます。ユースケースまたはログ分析や BigQuery のログに合わせてこのソリューションをカスタマイズ、デプロイ、評価するには、Dataform を使用するのが最速です。
-Google、クラウド ソリューション アーキテクト、Roy Arsan
-Google Cloud、エンジニアリング リード、Omid Fatemieh


